文章目录
-
- 概要
- Tokenizer(分词器)的功能讲解:
-
- [1. 三种粒度](#1. 三种粒度)
- [2. 主流算法](#2. 主流算法)
- [3. 核心 API(HuggingFace 范式)](#3. 核心 API(HuggingFace 范式))
- [4. 必记 4 个张量](#4. 必记 4 个张量)
- [5. 特殊 Token](#5. 特殊 Token)
- 整体架构流程
-
- [Step1 加载与保存](#Step1 加载与保存)
- [Step2 句子分词](#Step2 句子分词)
- [Step3 查看词典](#Step3 查看词典)
- [Step4 索引转换](#Step4 索引转换)
- [Step5 填充与截断](#Step5 填充与截断)
- 小结
概要
Tokenizer 和词向量(word embedding)的区别:Tokenizer 负责"切分",词向量负责"表示"
Tokenizer 的角色:将文本切分成"符号"(tokens),即把原始文本拆分成模型能处理的最小单元(词、子词、字符等)。
- 输出:一串离散的符号(tokens),例如:输入句子:"我喜欢自然语言处理",
- 中文分词结果:"我", "喜欢", "自然语言", "处理"
- 子词(如 BPE)结果:"我", "喜欢", "自然", "##语言", "处理"(## 表示子词片段)
在"预训练模型"时代到来之前,传统 NLP 的文本预处理是一条"手工流水线",分词(Tokenization) 、构建词典(Vocab Building) 、数字映射(Numericalize)、填充与截断(Padding / Truncation)。每一步都需自己操刀,稍有不慎就会埋下数据泄漏或 OOV 的隐患。下面用"四步曲"帮你把流程讲透,同时给出可直接落地的代码范式(PyTorch 代码)。
Tokenizer(分词器)的功能讲解:
连接自然语言 ↔ 模型数字 的桥梁。下面用 "一条文本 → 一串 ID" 的完整链路。
- 在"无预训练"年代,文本 → 分词 → 词典 → ID → 对齐长度 必须亲手完成 ,而进入预训练时代后,这些步骤被一个
AutoTokenizer一行代码搞定。
1. 三种粒度
| 粒度 | 例子 | 优点 | 缺点 |
|---|---|---|---|
| 词级 (word) | "ChatGPT"→[ChatGPT] |
直观、语义完整 | 词典大、OOV* |
| 子词级 (subword) | "ChatGPT"→[Chat, G, PT] |
平衡词典大小与语义 | 需要算法 |
| 字符级 (char) | "Chat"→[C, h, a, t] |
无 OOV | 序列长、语义弱 |
*OOV:Out-of-Vocabulary,词典外单词。
2. 主流算法
- BPE(Byte-Pair Encoding):从字符开始,高频合并。
- WordPiece:带似然阈值的 BPE。
- SentencePiece:把空格也当 token(跨语言友好)。
- BBPE / Unigram :更细粒度或概率式。
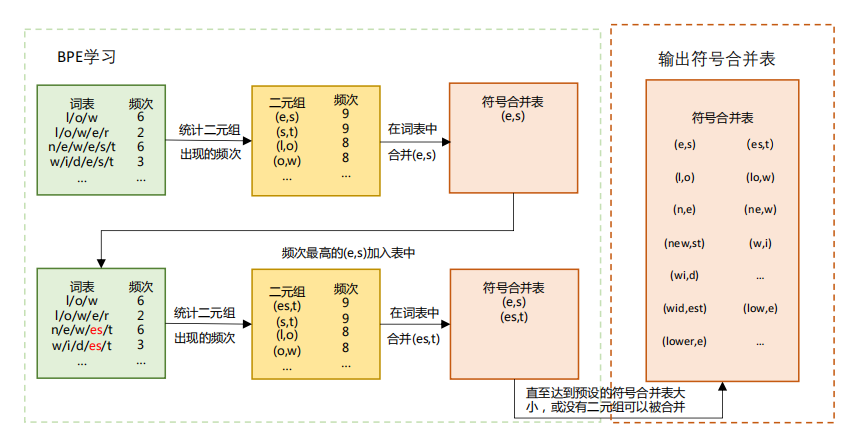
3. 核心 API(HuggingFace 范式)
python
from transformers import AutoTokenizer
tok = AutoTokenizer.from_pretrained("gpt2")
tok("Hello world!") # {'input_ids':[15496,995,0], 'attention_mask':[1,1,1]}
tok.decode([15496,995,0]) # 'Hello world!'4. 必记 4 个张量
| 名称 | 含义 | 示例 |
|---|---|---|
input_ids |
词汇表索引 | [15496,995,0] |
attention_mask |
1 保留 0 忽略 | [1,1,1,0,0] |
token_type_ids |
区分句子 A/B | [0,0,0,1,1] |
position_ids |
位置索引 | [0,1,2,3,4] |
5. 特殊 Token
| Token | 记号 | 作用 |
|---|---|---|
[PAD] |
填充到统一长度 | 训练 batch |
[UNK] |
未知词 | 兜底 |
[CLS] / [SEP] |
句子开始/结束 | BERT 系列 |
| `< | endoftext | >` |
Tokenizer = 把"Hello world!"切成 [15496, 995, 0],再把 [15496, 995, 0] 翻译成"Hello world!"------双向可逆、粒度可调、算法可换。
整体架构流程
Step1 加载与保存
导入分词器
python
from transformers import AutoTokenizer加载与保存
python
# 从HuggingFace加载,输入模型名称,即可加载对于的分词器
#加载分词器:AutoTokenizer.from_pretrained()会自动加载与预训练模型对应的分词器
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# tokenizer 保存到本地
tokenizer.save_pretrained("./gpt2_tokenizer")
# 从本地加载tokenizer
tokenizer = AutoTokenizer.from_pretrained("./gpt2_tokenizer/")Step2 句子分词
文本编码(Encoding)
tokenizer(text)会执行以下操作:
- 将文本分割为子词(subwords)
- 为每个子词分配一个唯一的 ID
- 生成注意力掩码(attention mask),用于指示哪些 token 是实际内容
特殊标记:大多数分词器会添加特殊标记,如 BERT 的CLS(句首)和SEP(句尾)
python
tokens = ["[CLS]", "hello", ",", "world", "!", "[SEP]"]
input_ids = [101, 7592, 1010, 2088, 999, 102]文本解码(Decoding)
将模型输出的 ID 序列转换回可读文本,自动忽略特殊标记(如填充标记):
批量处理文本
支持同时处理多条文本,并提供灵活的长度控制
- padding=True:自动填充短文本至批量中最长文本的长度
- truncation=True:截断过长文本
- max_length:指定最大序列长度
适配多种模型架构
兼容几乎所有 Hugging Face 支持的模型(BERT、GPT、T5、XLNet 等),统一了不同模型的分词接口,降低了切换模型的学习成本。
Step3 查看词典
tokenizer.vocab 是 Hugging Face transformers 库中分词器(Tokenizer)的一个属性,它本质上是一个字典(dictionary) ,存储了分词器所使用的词汇表(vocabulary) 信息。
具体来说:
-
核心内容 :
字典的键(key) 是分词后的文本单位(如单词、子词或特殊标记,例如
"hello"、"##ing"、"[CLS]"等),值(value) 是该文本单位对应的整数 ID(与input_ids中的数字一一对应)。示例(BERT分词器的部分 vocab):
python{ "[PAD]": 0, "[CLS]": 101, "[SEP]": 102, "hello": 7592, "##ing": 1045, "world": 2088, # ... 更多词汇 } -
作用:
- 是分词器将文本转换为
input_ids的"映射表":编码时,分词器通过查询这个字典,将文本单位转换为对应的 ID。 - 也是解码的基础:
tokenizer.decode()本质上是反向查询这个字典,将 ID 转换回文本。
- 是分词器将文本转换为
-
注意点:
- 不同预训练模型的
vocab内容不同(词汇量和具体映射关系由模型训练时的词汇表决定)。 - 词汇量大小因模型而异:例如 BERT-base 约有 30,000 个词汇,而一些大模型的词汇量可能超过 100,000。
- 可以通过
len(tokenizer.vocab)查看词汇表的大小。
- 不同预训练模型的
简单说,tokenizer.vocab 就是分词器的"词典",记录了所有模型能识别的文本单位及其对应的数字编码,是文本与模型可理解的数字之间的桥梁。
Step4 索引转换
python
#分词列表(tokens)转换为对应的整数 ID 列表(ids)
ids = tokenizer.convert_tokens_to_ids(tokens)
#整数 ID 列表(ids)转换回对应的分词列表(tokens)
tokens = tokenizer.convert_ids_to_tokens(ids)
#分词列表(tokens)转换为连贯的字符串文本
tokenizer.convert_tokens_to_string(tokens)
#便捷方案
# 将字符串转换为id序列,又称之为编码
ids = tokenizer.encode(sen, add_special_tokens=True)
# 将id序列转换为字符串,又称之为解码
str_sen = tokenizer.decode(ids, skip_special_tokens=False)ids = tokenizer.convert_tokens_to_ids(tokens) 是分词器的一个方法,用于将分词列表(tokens)转换为对应的整数 ID 列表(ids)。
-
功能定位 :
这是编码过程中的一个中间步骤。完整的编码流程通常是:
原始文本 → 分词(
tokenizer.tokenize())→ 转换为 ID(convert_tokens_to_ids())→ 生成最终输入格式而
tokenizer(text)其实是自动完成了这一系列步骤,convert_tokens_to_ids()则是将其中的"分词转ID"步骤单独暴露出来,方便手动控制流程。 -
参数与返回值:
- 参数
tokens:是一个字符串列表,表示分词后的结果(如["[CLS]", "hello", "world", "[SEP]"])。 - 返回值
ids:是一个整数列表,表示每个分词对应的 ID(如[101, 7592, 2088, 102])。
- 参数
-
示例演示:
pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") # 1. 先分词得到tokens text = "Hello world" tokens = tokenizer.tokenize(text) print("tokens:", tokens) # 输出: ['hello', 'world'] # 2. 手动将tokens转换为ids ids = tokenizer.convert_tokens_to_ids(tokens) print("ids:", ids) # 输出: [7592, 2088] # 3. 对比直接编码的结果(完全一致) encoded = tokenizer(text) print("encoded input_ids:", encoded["input_ids"]) # 输出: [101, 7592, 2088, 102] # (注:直接编码多了[CLS]和[SEP]等特殊标记的ID) -
实际用途:
- 用于手动控制分词和编码过程,适合需要自定义分词逻辑的场景。
- 可以单独查看某个分词对应的 ID,方便调试(例如检查特殊标记或子词的映射关系)。
tokens = tokenizer.convert_ids_to_tokens(ids) 是分词器的一个方法,用于将整数 ID 列表(ids)转换回对应的分词列表(tokens) ,是 convert_tokens_to_ids() 的反向操作。
-
功能定位 :
它是解码过程中的一个基础步骤,作用是根据分词器的词汇表(
tokenizer.vocab),将数字 ID 映射回原始的文本分词单位。完整的解码流程可以理解为:整数 ID 列表 → 转换为分词列表(
convert_ids_to_tokens())→ 拼接为完整文本(tokenizer.decode()内部包含此步骤) -
参数与返回值:
- 参数
ids:是一个整数列表(如[101, 7592, 2088, 102]),通常是input_ids的内容。 - 返回值
tokens:是一个字符串列表,表示每个 ID 对应的分词(如["[CLS]", "hello", "world", "[SEP]"])。
- 参数
-
示例演示:
pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") # 假设我们有一组ID ids = [101, 7592, 1010, 2088, 999, 102] # 对应 "[CLS] hello, world! [SEP]" # 将ID转换为分词 tokens = tokenizer.convert_ids_to_tokens(ids) print("tokens:", tokens) # 输出: ['[CLS]', 'hello', ',', 'world', '!', '[SEP]'] -
与
decode()的区别:convert_ids_to_tokens(ids):返回分词列表 (保留每个分词的独立状态,包括子词标记如##ing)。tokenizer.decode(ids):返回拼接后的完整文本 (会自动处理子词合并,例如将["play", "##ing"]合并为 "playing")。
示例对比:
pythonids = [2331, 1045] # 对应 "play" + "##ing" print(tokenizer.convert_ids_to_tokens(ids)) # 输出: ['play', '##ing'] print(tokenizer.decode(ids)) # 输出: "playing" -
实际用途:
- 用于精细查看每个 ID 对应的具体分词,适合调试(例如分析模型对某个子词的关注程度)。
- 当需要保留分词的原始结构(而非合并后的文本)时,比
decode()更实用。
tokenizer.convert_tokens_to_string(tokens) 是分词器的一个方法,用于将分词列表(tokens)转换为连贯的字符串文本。
-
功能定位 :
它是连接分词列表和自然语言文本的桥梁,主要作用是将分词后的零散单元(如子词、特殊标记等)拼接成人类可直接阅读的完整句子。
-
参数与返回值:
- 参数
tokens:是一个字符串列表(如["hello", "##ing", "world", "!"]),通常是tokenizer.tokenize()或convert_ids_to_tokens()的输出。 - 返回值
str_sen:是一个完整的字符串(如"helloing world!")。
- 参数
-
核心特点 :
会智能处理模型分词时产生的特殊标记,例如:
- 对于 BPE 分词中的子词标记(如
##),会自动去除标记并合并子词(如["play", "##ing"]→"playing")。 - 对于空格相关的分词(如某些模型会将
"don't"分为["don", "'", "t"]),会自动处理标点与单词的连接。
- 对于 BPE 分词中的子词标记(如
-
示例演示:
pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") # 示例1:处理子词 tokens1 = ["play", "##ing", "is", "fun"] str1 = tokenizer.convert_tokens_to_string(tokens1) print(str1) # 输出: "playing is fun" # 示例2:处理特殊标记和标点 tokens2 = ["[CLS]", "don", "'", "t", "go", "!", "[SEP]"] str2 = tokenizer.convert_tokens_to_string(tokens2) print(str2) # 输出: "don't go!"(自动忽略了[CLS]和[SEP]) -
与
decode()的区别:convert_tokens_to_string(tokens):输入是分词列表,专注于将分词拼接为文本。tokenizer.decode(ids):输入是ID列表 ,内部会先调用convert_ids_to_tokens()得到分词,再拼接为文本(相当于convert_tokens_to_string(convert_ids_to_tokens(ids))的组合操作)。
ids = tokenizer.encode(sen, add_special_tokens=True) 是分词器的一个方法,用于把原始字符串 编码成 模型可直接使用的整数 ID 序列 ,并在首尾自动插入所需的特殊标记(如 [CLS]、[SEP])。它完成的是「文本 → 词表索引」的转换。
-
功能定位 :
将原始字符串
sen编码成模型可直接接收的整数 ID 序列,并在需要时自动添加特殊标记(如[CLS]、[SEP]),完成「文本 → 模型输入」的第一步转换。 -
参数与返回值:
- 参数
sen:待编码的字符串,如"Hello world"。add_special_tokens=True:在序列首尾自动插入所需的特殊标记(BERT 为[CLS]与[SEP])。
- 返回值
ids:Python 列表或 PyTorch 张量,形如[101, 8667, 1362, 102],每个整数对应词汇表中的一个 token。
- 参数
-
核心特点:
- 自动完成分词 + 查词表 + 插入特殊标记三步合一。
- 若
add_special_tokens=False,则仅返回纯文本分词对应的 ID,不包含额外标记。 - 与
tokenizer(sen, ...)的区别在于:encode直接给出一维 ID 列表,而tokenizer(...)返回包含input_ids、attention_mask等字段的字典。
-
示例演示:
pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") ids = tokenizer.encode("Hello world", add_special_tokens=True) print(ids) # [101, 8667, 1362, 102] print(tokenizer.decode(ids)) # [CLS] Hello world [SEP] -
常见搭配 :
编码后的
ids可直接送入模型,或与decode()组合用于快速验证 tokenizer 行为。
Step5 填充与截断
代码:
python
##填充
ids = tokenizer.encode(sen, padding="max_length", max_length=15)
# 截断
ids = tokenizer.encode(sen, max_length=5, truncation=True)-
功能定位
tokenizer.encode(或tokenizer.__call__)的padding与truncation参数,直接在编码阶段完成"填充/截断",生成固定长度的 ID 列表,无需手动循环。 -
参数与返回值
- 参数
sen:待编码的单个字符串。max_length:允许的最大长度。padding="max_length":长度不足时在尾部补[PAD],直到max_length。truncation=True:长度超过max_length时从头截断。
- 返回值
ids:Python 列表,长度恒等于max_length,元素为对应 token ID。
- 参数
-
核心特点
- 一步完成:分词、查表、填充、截断、特殊标记插入一次性完成。
- 右填充 :默认在尾部补
[PAD](ID=0)。 - 前向截断:超长时丢弃尾部 token(与手写示例一致)。
-
示例演示
pythonfrom transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased") sen = "this is a very long sentence" # 填充到 15 ids_pad = tokenizer.encode(sen, padding="max_length", max_length=15) print(ids_pad) # [101, 2023, 2003, 1037, 2200, 2151, 6251, 102, 0, 0, 0, 0, 0, 0, 0] # 截断到 5 ids_trunc = tokenizer.encode(sen, max_length=5, truncation=True) print(ids_trunc) # [101, 2023, 2003, 1037, 2200] -
与
tokenizer(sen, ...)的区别encode只返回一维input_ids列表。tokenizer(sen, ...)返回字典,可同时获得attention_mask、token_type_ids等。
小结
-
Tokenizer 的核心定位
一句话:Tokenizer 是"自然语言 ↔ 模型数字"的双向可逆桥梁。
• 把文本切成最小可处理单元(token)。
• 把 token 映射成唯一的整数 ID。
• 反向再映射回人类可读文本。
-
三大粒度
词级、子词级、字符级------粒度越细,OOV 风险越低,但序列越长。
-
四大主流算法
BPE、WordPiece、SentencePiece、BBPE/Unigram。
→ 本质都是"高频合并"或"概率裁剪",在词典大小与语义完整度之间做权衡。
-
HuggingFace 范式四件套
张量 含义 记忆口诀 input_ids 词汇表索引 "我是谁" attention_mask 1 保留 0 忽略 "看不看" token_type_ids 区分句子 A/B "哪一句" position_ids 位置索引 "排第几" -
特殊 Token 一览
PAD 填充、UNK 兜底、CLS/SEP 句子边界、<|endoftext|> 生成终止。
-
调用AutoTokenizer的API 自动完成分词的功能
pythonfrom transformers import AutoTokenizer tok = AutoTokenizer.from_pretrained("模型名") out = tok("Hello world!", padding=True, truncation=True, max_length=128) # out 中已含 input_ids、attention_mask 等全部所需张量 -
本地保存/加载
pythontok.save_pretrained("./本地目录") AutoTokenizer.from_pretrained("./本地目录") -
一键编解码
• 编码:
ids = tok.encode("文本", add_special_tokens=True)• 解码:
text = tok.decode(ids, skip_special_tokens=True) -
填充与截断
padding="max_length" + truncation=True 两步合一,不再手写循环。
-
调试三板斧
•
tok.convert_tokens_to_ids查 ID•
tok.convert_ids_to_tokens查 token•
tok.convert_tokens_to_string拼回原文