文章目录
5.SpringBoot集成ElasticSearch7.x
1.添加依赖
本文使用springboot版本为2.7
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
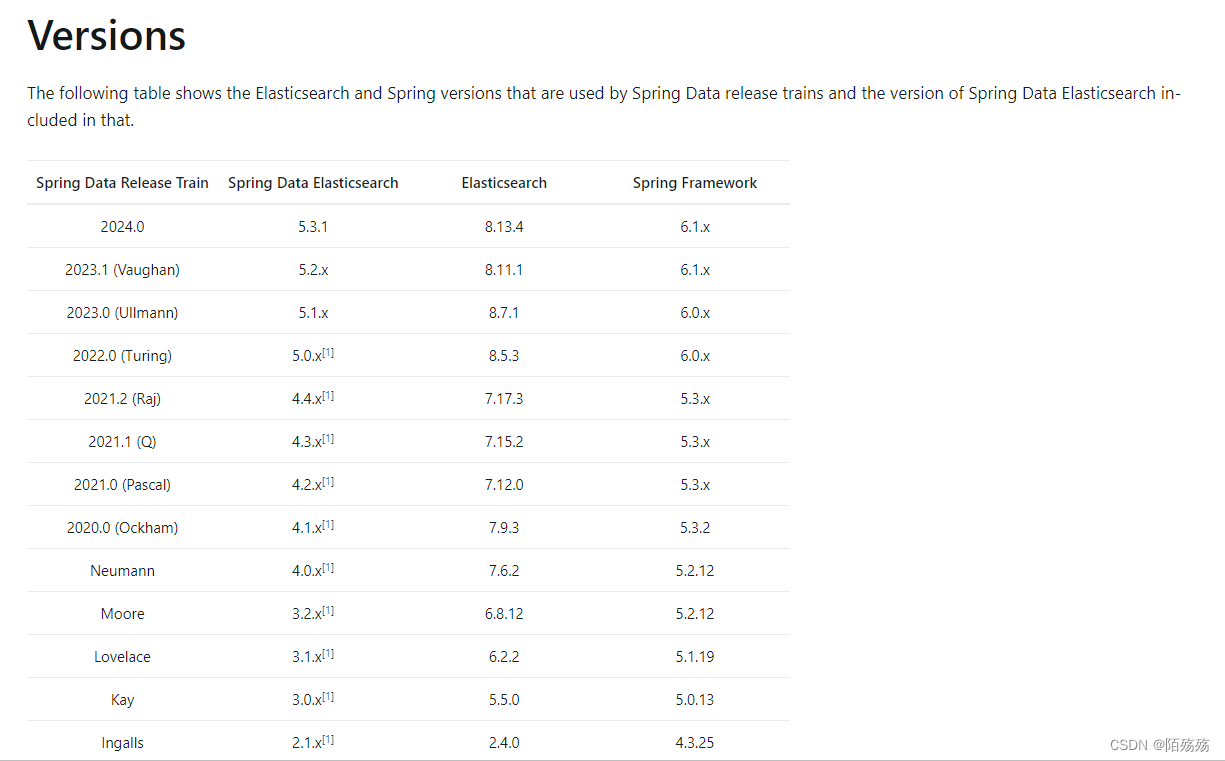
</dependency>spring官网es对应版本关系 https://docs.spring.io/spring-data/elasticsearch/reference/elasticsearch/versions.html
2.yml配置
yml
spring:
data:
elasticsearch:
repositories:
enabled: true #打开elasticsearch仓库,默认true
elasticsearch:
#username:
#password:
#path-prefix:
uris: http://127.0.0.1:9200
connection-timeout: 60000 #连接elasticsearch超时时间
socket-timeout: 300003.创建文档对象
java
/**
* @author moshangshang
* createIndex默认为true自动创建索引
*/
@Data
@AllArgsConstructor
@Document(indexName ="books",createIndex = true)
@Setting(replicas = 1, shards = 1)
public class Books implements Serializable {
@Id
private Integer id;
//指定字段类型和分词器
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String describe;
}
java
public enum FieldType {
Auto("auto"),
Text("text"),
Keyword("keyword"),
Long("long"),
Integer("integer"),
Short("short"),
Byte("byte"),
Double("double"),
Float("float"),
Half_Float("half_float"),
Scaled_Float("scaled_float"),
Date("date"),
Date_Nanos("date_nanos"),
Boolean("boolean"),
Binary("binary"),
Integer_Range("integer_range"),
Float_Range("float_range"),
Long_Range("long_range"),
Double_Range("double_range"),
Date_Range("date_range"),
Ip_Range("ip_range"),
Object("object"),
Nested("nested"),
Ip("ip"),
TokenCount("token_count"),
Percolator("percolator"),
Flattened("flattened"),
Search_As_You_Type("search_as_you_type"),
Rank_Feature("rank_feature"),
Rank_Features("rank_features"),
Wildcard("wildcard"),
Dense_Vector("dense_vector");
}
java
@GeoPointField //地理位置类型字段
private GeoPoint location;
java
@Field(index = false) //不进行索引
java
//定义排序字段时,使用 Java 属性的名称 ,而不是 Elasticsearch 定义的名称
//sortModes、sortOrders和sortMissingValues是可选的,但如果设置了它们,则条目数必须与sortFields元素数匹配
@Setting(
replicas = 1, shards = 1, refreshInterval = "1s", indexStoreType = "fs",
sortFields = { "age", "id" },
sortModes = { Setting.SortMode.max, Setting.SortMode.min },
sortOrders = { Setting.SortOrder.desc, Setting.SortOrder.asc },
sortMissingValues = { Setting.SortMissing._last, Setting.SortMissing._first })- useServerConfiguration不发送任何设置参数,因此 Elasticsearch 服务器配置决定它们。
- settingPath指定义必须在类路径中可解析的设置的 JSON 文件
- shards要使用的分片数量,默认为1
- replicas副本数,默认1
- refreshIntervall,默认为"1s"
- indexStoreType,默认为"fs"
4.继承ElasticsearchRepository
java
/**
* @author moshangshang
*/
public interface BookMapper extends ElasticsearchRepository<Books,String> {
}自定义接口查询方法
java
List<Book> findByNameAndPrice(String name, Integer price);等同于
shell
{
"query": {
"bool" : {
"must" : [
{ "query_string" : { "query" : "?", "fields" : [ "name" ] } },
{ "query_string" : { "query" : "?", "fields" : [ "price" ] } }
]
}
}
}详细接口方法命名见官方文档:
5.注入ElasticsearchRestTemplate
java
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;建议通过elasticsearchRestTemplate进行es操作,ElasticsearchRepository也可直接操作,但多数方法已过时,不建议用
6.SpringBoot操作ElasticSearch
1.ElasticsearchRestTemplate索引操作
java
/**
* 操作文档索引
* 如果文档的createIndex设置为true自动创建,则可以直接创建映射会自动创建索引
* 如果为false,直接创建映射会返回Document的json,但索引并未创建
*/
@GetMapping("/create/index")
public Document createIndex(){
// 获取操作的索引文档对象
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Books.class);
//判断索引是否存在
log.info("exists:{}",indexOperations.exists());
//删除索引文档
log.info("delete:{}",indexOperations.delete());
//创建索引,如果存在则会抛异常
log.info("create:{}",indexOperations.create());
//创建映射,返回Document
log.info("createMapping:{}",indexOperations.createMapping());
indexOperations.delete();
//创建索引同时创建映射,如果存在索引则会抛异常
log.info("createWithMapping{}",indexOperations.createWithMapping());
//更新映射mapping
log.info("putMapping:{}",indexOperations.putMapping());
// 配置映射
return indexOperations.createMapping();
}2.ElasticsearchRepository文档操作
java
/**
* 发送保存数据,会自动创建索引文档并保存数据
* 如果文档的createIndex设置为false,该方法会创建索引
*/
@GetMapping("/data/{id}")
public String data(@PathVariable Integer id){
//新增数据,等同于PUT/POST方式发送数据
bookMapper.save(new Books(id,"四大名著西游记111","著名的神话小说"));
//查所有数据
bookMapper.findAll().forEach(System.out::println);
bookMapper.findAllById(Arrays.asList("1", "10")).forEach(System.out::println);
bookMapper.findById(id.toString()).ifPresent(System.out::println);
//查所有数据按id排序
bookMapper.findAll(Sort.by("id")).forEach(System.out::println);
//删除指定id数据
bookMapper.deleteById(String.valueOf(id));
//分页查询
Page<Books> booksPage = bookMapper.findAll(Pageable.ofSize(2));
//效果等同于booksPage2.getContent().forEach()
log.info("总页数:{}",booksPage.getTotalPages());
System.out.println("第1页");
booksPage.forEach(System.out::println);
int i = 1;
//判断是否有下一页,hasPrevious方法判断是否有前一页
while (booksPage.hasNext()){
i++;
booksPage = bookMapper.findAll(booksPage.nextPageable());
log.info("第{}页",i);
booksPage.forEach(System.out::println);
}
return "success";
}3.ElasticsearchRestTemplate文档操作
注意:直接执行可能会删除时更新操作还未执行完,全部删除时会导致更新的数据还在
java
@GetMapping("/data1/{id}")
public UpdateResponse data1(@PathVariable Integer id){
//添加
elasticsearchRestTemplate.save(new Books(id,"四大名著西游记111","著名的神话小说"));
elasticsearchRestTemplate.save(
new Books(1,"四大名著西游记111","著名的神话小说"),
new Books(2,"四大名著西游记111","著名的神话小说"),
new Books(3,"四大名著西游记111","著名的神话小说"));
/**
* 修改 跟新增是相同。若id已存在,覆盖其他所有字段,
* 若某个字段没有值,则为null。无法修改单个字段
*/
elasticsearchRestTemplate.save(new Books(3,"四大名著西游记222",null));
//修改部分字段
Document document = Document.create();
document.put("name", "三国演义");
document.put("describe", "著名的小说");
//需要修改的id和参数
UpdateQuery updateQuery = UpdateQuery.builder(String.valueOf(id))
.withDocument(document).build();
UpdateResponse response = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("books"));
//批量修改部分字段
List<UpdateQuery> updateQueryList = new ArrayList<>();
for (int i = 1; i <= 3; i++) {
Document bulkDocument = Document.create();
bulkDocument.put("name", "三国演义"+i);
bulkDocument.put("describe", "著名的小说"+i);
//索引i数据不存在会报错
UpdateQuery updateQueryBulk = UpdateQuery.builder(Long.toString(i))
.withDocument(bulkDocument).build();
updateQueryList.add(updateQueryBulk);
}
elasticsearchRestTemplate.bulkUpdate(updateQueryList, IndexCoordinates.of("books"));
//查询
Books books = elasticsearchRestTemplate.get(id.toString(), Books.class, IndexCoordinates.of("books"));
log.info("查询数据:{}",books);
//删除
String delete = elasticsearchRestTemplate.delete(id.toString(), Books.class);
log.info("删除数据id:{}",delete);
//条件删除
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("name", "三国"))
.build();
ByQueryResponse queryResponse = elasticsearchRestTemplate.delete(nativeSearchQuery, Books.class, IndexCoordinates.of("books"));
log.info("删除queryResponse数据数量:{}",queryResponse.getDeleted());
//全部删除
//直接执行可能会删除时更新操作还未执行完,全部删除时会导致更新的数据还在
ByQueryResponse queryResponse1 = elasticsearchRestTemplate.delete(
new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).build(),
Books.class, IndexCoordinates.of("books"));
log.info("删除queryResponse1数据数量:{}",queryResponse1.getDeleted());
return response;
}4.ElasticsearchRestTemplate数据检索
1.ElasticsearchRestTemplate基础及高亮查询
java
@GetMapping("/query")
public void query() {
// 构建查询条件(NativeSearchQueryBuilder更接近原生查询)
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//查询
queryBuilder.withQuery(QueryBuilders.matchQuery("username","lisi")).withSort(Sort.by("age").ascending());
//高亮查询
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("username");
//多个匹配项高亮关闭
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
//设置高亮
queryBuilder.withHighlightBuilder(highlightBuilder);
SearchHits<News> searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), News.class);
searchHits.forEach(e -> {
log.info("全文检索{}", e.getContent());
Map<String, List<String>> highlightFields = e.getHighlightFields();
List<String> list = highlightFields.get("username");
if (list != null) {
list.forEach(ex -> log.info("高亮{}", ex));
}
});
}2.NativeSearchQueryBuilder方式条件构建
java
// 构建查询条件(NativeSearchQueryBuilder更接近原生查询)
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//查询全部 match_all
queryBuilder.withQuery(QueryBuilders.matchAllQuery());
//查询全部 过滤时间范围
queryBuilder.withQuery(QueryBuilders.matchAllQuery())
.withFilter(QueryBuilders.rangeQuery("time")
.timeZone("+08:00")
.format("yyyy-MM-dd HH:mm:ss")
.gt("2024-06-27 14:22:22")
.lt("2024-06-27 14:22:28"));
//查询全部 match_all 并按age升序
queryBuilder.withQuery(QueryBuilders.matchAllQuery()).withSort(Sort.by("age").ascending());
//查询全部 match_all 并按age升序 并分页
queryBuilder.withQuery(QueryBuilders.matchAllQuery()).withSort(Sort.by("age").ascending()).withPageable(PageRequest.of(2, 10));
//term精确查询,整体匹配
// 查询内容只是为数字时 推荐使用term 进行检索,但是当使用term中进行文本内容的全量检索时term不会检索任何内容
queryBuilder.withQuery(QueryBuilders.termQuery("age", "2"));
//多匹配值查询
queryBuilder.withQuery(QueryBuilders.termsQuery("age", "2", "3"));
//全文检索 match_query
queryBuilder.withQuery(QueryBuilders.matchQuery("address", "Beijing"));
//or 只要有一个词存在则就符合条件,and表示每个词都需存在
queryBuilder.withQuery(QueryBuilders.matchQuery("address", "Beijing shanghai").operator((Operator.OR)));
//短语匹配 match_phrase
queryBuilder.withQuery(QueryBuilders.matchPhraseQuery("address", "Beijing aaa"));
//短语匹配 match_phrase_prefix 它允许文本中最后一项使用前缀匹配
queryBuilder.withQuery(QueryBuilders.matchPhrasePrefixQuery("address", "Beijing a"));
//多字段匹配 multi_match
queryBuilder.withQuery(QueryBuilders.multiMatchQuery("Beijing aaa", "address", "username"));
queryBuilder.withQuery(QueryBuilders.multiMatchQuery("Beijing aaa", "address", "username")
//提升该字段查询匹配权重
.field("address", 10));
//match_bool_prefix 允许文本中最后一项使用前缀匹配 其它都是term query。
queryBuilder.withQuery(QueryBuilders.matchBoolPrefixQuery("address", "b"));
//id查询
queryBuilder.withQuery(QueryBuilders.idsQuery().addIds("1", "2"));
//区间查询
queryBuilder.withQuery(QueryBuilders.rangeQuery("age").gte(2).lte(3));
//bool复合查询
//must必须 mustNot必须不
//should 条件可以满足也可以不满足,在查询中如果有满足should的条件就会增加相关性得分
QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("address", "Beijing"))
.must(QueryBuilders.matchQuery("username", "lisi"))
.mustNot(QueryBuilders.matchQuery("age", "1"))
.should(QueryBuilders.matchQuery("age", "2"))
//minimumShouldMatch 最小匹配度,必须 匹配的should子句的数量或百分比。
.minimumShouldMatch("50%");
//filter结果过滤
QueryBuilders.boolQuery()
.filter(QueryBuilders.rangeQuery("age").gte(1).lte(2));
//与上面结果相等
QueryBuilders.boolQuery()
.must(QueryBuilders.rangeQuery("age").gte(1).lte(2));3.Criteria方式条件构建
java
Criteria criteria = new Criteria("username").is("lisi")
.and("age").is("2");
Query query = new CriteriaQuery(criteria);
SearchHits<News> searchHits = elasticsearchRestTemplate.search(query, News.class);
searchHits.forEach(e -> log.info("全文检索{}", e.getContent()));5.ElasticsearchRepository数据检索
java
/**
* @author moshangshang
*/
public interface BookMapper extends ElasticsearchRepository<Books,String> {
List<Books> findByName(String name);
@Query("{ \"match\": { \"name\": { \"query\": \"西游记\" } } } ")
List<Books> findBooksByQuery();
/**
* 注解实现高亮查询
*/
@Highlight(fields = {@HighlightField(name = "name"), @HighlightField(name = "describe")},
parameters = @HighlightParameters(preTags = "<span style='color:red'>", postTags = "</span>"))
SearchHits<Books> findByName(String name);
}
java
@GetMapping("/query/string")
public void stringQuery() {
//等同于自定义接口加 @Query("{ \"match\": { \"address\": { \"query\": \"Beijing\" } } } ")
Query query = new StringQuery("{ \"match\": { \"address\": { \"query\": \"Beijing\" } } } ");
SearchHits<News> searchHits = elasticsearchRestTemplate.search(query, News.class);
searchHits.forEach(e -> log.info("全文检索{}", e.getContent()));
//注解形式
List<Books> booksByQuery = bookMapper.findBooksByQuery();
booksByQuery.forEach(System.out::println);
//高亮
SearchHits<Books> name = bookMapper.findByName("西游记");
name.forEach(e -> {
log.info("全文检索{}", e.getContent());
Map<String, List<String>> highlightFields = e.getHighlightFields();
List<String> list = highlightFields.get("name");
if (list != null) {
list.forEach(ex -> log.info("高亮{}", ex));
}
});
}6.完整测试代码
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.0</version>
</parent>
<groupId>com.example</groupId>
<artifactId>test</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>test</name>
<properties>
<java.version>8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
java
/**
* 使用 Spring Data Elasticsearch 创建 Elasticsearch 索引时,可以使用注解定义不同的索引@Setting。可以使用以下参数:
* useServerConfiguration不发送任何设置参数,因此 Elasticsearch 服务器配置决定它们。
* settingPath指定义必须在类路径中可解析的设置的 JSON 文件
* shards要使用的分片数量,默认为1
* replicas副本数,默认1
* refreshIntervall,默认为"1s"
* indexStoreType,默认为"fs"
* 也可以定义索引排序(检查链接的 Elasticsearch 文档以了解可能的字段类型和值):
* @author moshangshang
*/
@Data
@AllArgsConstructor
@Document(indexName ="news")
// 定义排序字段时,使用 Java 属性的名称 ,而不是可能为 Elasticsearch 定义的名称
//sortModes、sortOrders和sortMissingValues是可选的,但如果设置了它们,则条目数必须与sortFields元素数匹配
@Setting(
replicas = 1, shards = 1, refreshInterval = "1s", indexStoreType = "fs",
sortFields = { "age", "id" },
sortModes = { Setting.SortMode.max, Setting.SortMode.min },
sortOrders = { Setting.SortOrder.desc, Setting.SortOrder.asc },
sortMissingValues = { Setting.SortMissing._last, Setting.SortMissing._first })
public class News implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String address;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String username;
@Field(type = FieldType.Long)
private Integer age;
}
java
/**
* @author moshangshang
*/
@Data
@AllArgsConstructor
@Document(indexName ="books")
public class Books implements Serializable {
@Id
private Integer id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String name;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String describe;
}
java
/**
* @author moshangshang
*/
public interface BookMapper extends ElasticsearchRepository<Books,String> {
@Query("{ \"match\": { \"name\": { \"query\": \"西游记\" } } } ")
List<Books> findBooksByQuery();
/**
* 注解实现高亮查询
*/
@Highlight(fields = {@HighlightField(name = "name"), @HighlightField(name = "describe")},
parameters = @HighlightParameters(preTags = "<span style='color:red'>", postTags = "</span>"))
SearchHits<Books> findByName(String name);
}
java
/**
* @author moshangshang
*/
@Slf4j
@RestController
@RequestMapping("/es")
public class BookController {
@Autowired
private BookMapper bookMapper;
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
/**
* 操作文档索引
* 如果文档的createIndex设置为true自动创建,则可以直接创建映射会自动创建索引
* 如果为false,直接创建映射会返回Document的json,但索引并未创建
*/
@GetMapping("/create/index")
public Document createIndex() {
// 获取操作的索引文档对象
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(Books.class);
//判断索引是否存在
log.info("exists:{}", indexOperations.exists());
//删除索引文档
log.info("delete:{}", indexOperations.delete());
//创建索引,如果存在则会抛异常
log.info("create:{}", indexOperations.create());
//创建映射,返回Document
log.info("createMapping:{}", indexOperations.createMapping());
indexOperations.delete();
//创建索引同时创建映射,如果存在索引则会抛异常
log.info("createWithMapping{}", indexOperations.createWithMapping());
//更新映射mapping
log.info("putMapping:{}", indexOperations.putMapping());
// 配置映射
return indexOperations.createMapping();
}
/**
* 发送保存数据,会自动创建索引文档并保存数据
* 如果文档的createIndex设置为false,该方法会创建索引
*/
@GetMapping("/data/{id}")
public String data(@PathVariable Integer id) {
//新增数据
bookMapper.save(new Books(id, "四大名著西游记111", "著名的神话小说"));
//查所有数据
bookMapper.findAll().forEach(System.out::println);
bookMapper.findAllById(Arrays.asList("1", "10")).forEach(System.out::println);
bookMapper.findById(id.toString()).ifPresent(System.out::println);
//查所有数据按id排序
bookMapper.findAll(Sort.by("id")).forEach(System.out::println);
//删除指定id数据
//bookMapper.deleteById(String.valueOf(id));
//删除匹配的数据
bookMapper.delete(new Books(null, "四大名著西游记111", "著名的神话小说"));
//删除所有数据
//bookMapper.deleteAll();
//分页查询
Page<Books> booksPage = bookMapper.findAll(Pageable.ofSize(2));
//效果等同于booksPage2.getContent().forEach()
log.info("总页数:{}", booksPage.getTotalPages());
System.out.println("第1页");
booksPage.forEach(System.out::println);
int i = 1;
//判断是否有下一页,hasPrevious方法判断是否有前一页
while (booksPage.hasNext()) {
i++;
booksPage = bookMapper.findAll(booksPage.nextPageable());
log.info("第{}页", i);
booksPage.forEach(System.out::println);
}
return "success";
}
@GetMapping("/data1/{id}")
public UpdateResponse data1(@PathVariable Integer id) {
//添加
elasticsearchRestTemplate.save(new Books(id, "四大名著西游记111", "著名的神话小说"));
elasticsearchRestTemplate.save(
new Books(1, "四大名著西游记111", "著名的神话小说"),
new Books(2, "四大名著西游记111", "著名的神话小说"),
new Books(3, "四大名著西游记111", "著名的神话小说"));
/**
* 修改 跟新增是相同。若id已存在,覆盖其他所有字段,
* 若某个字段没有值,则为null。无法修改单个字段
*/
elasticsearchRestTemplate.save(new Books(3, "四大名著西游记222", null));
//修改部分字段
Document document = Document.create();
document.put("name", "三国演义");
document.put("describe", "著名的小说");
//需要修改的id和参数
UpdateQuery updateQuery = UpdateQuery.builder(String.valueOf(id))
.withDocument(document).build();
UpdateResponse response = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("books"));
//批量修改部分字段
List<UpdateQuery> updateQueryList = new ArrayList<>();
for (int i = 1; i <= 3; i++) {
Document bulkDocument = Document.create();
bulkDocument.put("name", "三国演义" + i);
bulkDocument.put("describe", "著名的小说" + i);
//索引i数据不存在会报错
UpdateQuery updateQueryBulk = UpdateQuery.builder(Long.toString(i))
.withDocument(bulkDocument).build();
updateQueryList.add(updateQueryBulk);
}
elasticsearchRestTemplate.bulkUpdate(updateQueryList, IndexCoordinates.of("books"));
//查询
Books books = elasticsearchRestTemplate.get(id.toString(), Books.class, IndexCoordinates.of("books"));
log.info("查询数据:{}", books);
//删除
String delete = elasticsearchRestTemplate.delete(id.toString(), Books.class);
log.info("删除数据id:{}", delete);
//条件删除
NativeSearchQuery nativeSearchQuery = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("name", "三国"))
.build();
ByQueryResponse queryResponse = elasticsearchRestTemplate.delete(nativeSearchQuery, Books.class, IndexCoordinates.of("books"));
log.info("删除queryResponse数据数量:{}", queryResponse.getDeleted());
//全部删除
//直接执行可能会删除时更新操作还未执行完,全部删除时会导致更新的数据还在
ByQueryResponse queryResponse1 = elasticsearchRestTemplate.delete(
new NativeSearchQueryBuilder().withQuery(QueryBuilders.matchAllQuery()).build(),
Books.class, IndexCoordinates.of("books"));
log.info("删除queryResponse1数据数量:{}", queryResponse1.getDeleted());
return response;
}
/**
* 搜索具有给定的人员,并且找到的文档具有术语聚合,用于计算这些人员firstName的出现次数:lastName
*/
@GetMapping("/query")
public void query() {
// 构建查询条件(NativeSearchQueryBuilder更接近原生查询)
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//查询全部 match_all
queryBuilder.withQuery(QueryBuilders.matchAllQuery());
//查询全部 过滤时间范围
queryBuilder.withQuery(QueryBuilders.matchAllQuery())
.withFilter(QueryBuilders.rangeQuery("time")
.timeZone("+08:00")
.format("yyyy-MM-dd HH:mm:ss")
.gt("2024-06-27 14:22:22")
.lt("2024-06-27 14:22:28"));
//查询全部 match_all 并按age升序
queryBuilder.withQuery(QueryBuilders.matchAllQuery()).withSort(Sort.by("age").ascending());
//查询全部 match_all 并按age升序 并分页
queryBuilder.withQuery(QueryBuilders.matchAllQuery()).withSort(Sort.by("age").ascending()).withPageable(PageRequest.of(2, 10));
//term精确查询,整体匹配
// 查询内容只是为数字时 推荐使用term 进行检索,但是当使用term中进行文本内容的全量检索时term不会检索任何内容
queryBuilder.withQuery(QueryBuilders.termQuery("age", "2"));
//多匹配值查询
queryBuilder.withQuery(QueryBuilders.termsQuery("age", "2", "3"));
//全文检索 match_query
queryBuilder.withQuery(QueryBuilders.matchQuery("address", "Beijing"));
//or 只要有一个词存在则就符合条件,and表示每个词都需存在
queryBuilder.withQuery(QueryBuilders.matchQuery("address", "Beijing shanghai").operator((Operator.OR)));
//短语匹配 match_phrase
queryBuilder.withQuery(QueryBuilders.matchPhraseQuery("address", "Beijing aaa"));
//短语匹配 match_phrase_prefix 它允许文本中最后一项使用前缀匹配
queryBuilder.withQuery(QueryBuilders.matchPhrasePrefixQuery("address", "Beijing a"));
//多字段匹配 multi_match
queryBuilder.withQuery(QueryBuilders.multiMatchQuery("Beijing aaa", "address", "username"));
queryBuilder.withQuery(QueryBuilders.multiMatchQuery("Beijing aaa", "address", "username")
//提升该字段查询匹配权重
.field("address", 10));
//match_bool_prefix 允许文本中最后一项使用前缀匹配 其它都是term query。
queryBuilder.withQuery(QueryBuilders.matchBoolPrefixQuery("address", "b"));
//id查询
queryBuilder.withQuery(QueryBuilders.idsQuery().addIds("1", "2"));
//区间查询
queryBuilder.withQuery(QueryBuilders.rangeQuery("age").gte(2).lte(3));
//bool复合查询
//must必须 mustNot必须不
//should 条件可以满足也可以不满足,在查询中如果有满足should的条件就会增加相关性得分
QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("address", "Beijing"))
.must(QueryBuilders.matchQuery("username", "lisi"))
.mustNot(QueryBuilders.matchQuery("age", "1"))
.should(QueryBuilders.matchQuery("age", "2"))
//minimumShouldMatch 最小匹配度,必须 匹配的should子句的数量或百分比。
.minimumShouldMatch("50%");
//filter结果过滤
QueryBuilders.boolQuery()
.filter(QueryBuilders.rangeQuery("age").gte(1).lte(2));
//与上面结果相等
QueryBuilders.boolQuery()
.must(QueryBuilders.rangeQuery("age").gte(1).lte(2));
//查询
queryBuilder.withQuery(QueryBuilders.matchQuery("username","lisi")).withSort(Sort.by("age").ascending());
//高亮查询
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("username");
//多个匹配项高亮关闭
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
//设置高亮
queryBuilder.withHighlightBuilder(highlightBuilder);
SearchHits<News> searchHits = elasticsearchRestTemplate.search(queryBuilder.build(), News.class);
searchHits.forEach(e -> {
log.info("全文检索{}", e.getContent());
Map<String, List<String>> highlightFields = e.getHighlightFields();
List<String> list = highlightFields.get("username");
if (list != null) {
list.forEach(ex -> log.info("高亮{}", ex));
}
});
}
@GetMapping("/query/other")
public void other() {
Criteria criteria = new Criteria("username").is("lisi")
.and("age").is("2");
Query query = new CriteriaQuery(criteria);
SearchHits<News> searchHits = elasticsearchRestTemplate.search(query, News.class);
searchHits.forEach(e -> log.info("全文检索{}", e.getContent()));
}
@GetMapping("/query/string")
public void stringQuery() {
Query query = new StringQuery("{ \"match\": { \"address\": { \"query\": \"Beijing\" } } } ");
SearchHits<News> searchHits = elasticsearchRestTemplate.search(query, News.class);
searchHits.forEach(e -> log.info("全文检索{}", e.getContent()));
List<Books> booksByQuery = bookMapper.findBooksByQuery();
booksByQuery.forEach(System.out::println);
//高亮
SearchHits<Books> name = bookMapper.findByName("西游记");
name.forEach(e -> {
log.info("全文检索{}", e.getContent());
Map<String, List<String>> highlightFields = e.getHighlightFields();
List<String> list = highlightFields.get("name");
if (list != null) {
list.forEach(ex -> log.info("高亮{}", ex));
}
});
}
}