Go-知识测试-性能测试
- [1. 定义](#1. 定义)
- [2. 例子](#2. 例子)
- [3. testing.common 测试基础数据](#3. testing.common 测试基础数据)
- [4. testing.TB 接口](#4. testing.TB 接口)
- [5. 关键函数](#5. 关键函数)
-
- [5.1 testing.runBenchmarks](#5.1 testing.runBenchmarks)
- [5.2 testing.B.runN](#5.2 testing.B.runN)
- [5.3 testing.B.StartTimer](#5.3 testing.B.StartTimer)
- [5.4 testing.B.StopTimer](#5.4 testing.B.StopTimer)
- [5.5 testing.B.ResetTimer](#5.5 testing.B.ResetTimer)
- [5.6 testing.B.Run](#5.6 testing.B.Run)
- [5.7 testing.B.run1](#5.7 testing.B.run1)
- [5.8 testing.B.run](#5.8 testing.B.run)
- [5.9 processBench](#5.9 processBench)
- [5.10 tetsing.B.doBench](#5.10 tetsing.B.doBench)
- [5.11 testing.B.launch](#5.11 testing.B.launch)
- [5.12 testing.B.SetBytes](#5.12 testing.B.SetBytes)
- [6. 数据统计](#6. 数据统计)
建议先看:https://blog.csdn.net/a18792721831/article/details/140062769
1. 定义
性能测试会执行多次,然后计算平均耗时。
性能测试要保证测试文件以_test.go结尾。
测试方法必须以BenchmarkXxx开头。
测试文件可以与源码处于同一目录,也可以处于单独的目录。
2. 例子
在创建切片的时候,可以指定容量,也可以不指定容量。假设可以提前知道数据的长度,就可以在创建切片的时候,预分配存储空间,避免多次拷贝。
函数如下:
Go
func MakeWithout(n int) []int {
var s []int
for i := 0; i < n; i++ {
s = append(s, i)
}
return s
}
func MakeWith(n int) []int {
s := make([]int, n)
for i := 0; i < n; i++ {
s = append(s, i)
}
return s
}接着使用性能测试,看看上面两个函数的性能差距有多大
Go
func BenchmarkMakeWithout(b *testing.B) {
for i := 0; i < b.N; i++ {
MakeWithout(1000)
}
}
func BenchmarkMakeWith(b *testing.B) {
for i := 0; i < b.N; i++ {
MakeWith(1000)
}
}先来个小容量的,n=1000
使用go test -v -bench=.执行性能测试,-v 表示控制台输出结果,-bench表示执行性能测试,-bench=.表示使用.作为正则,也就是执行全部的性能测试
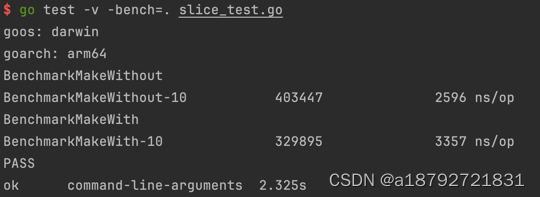
通过输出可以知道 Without 执行了 403447 次,平均每次 2596 纳秒
With 执行了 329895次,平均每次 3357 纳秒
也就是说,在1000的容量下,预先分配反而慢。我猜测是显式调用make花费了时间。
加大容量,n=1000_0000
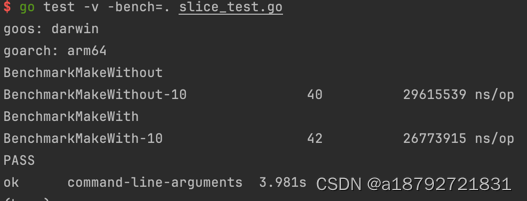
预分配比较快了,平均每次26.7毫秒
3. testing.common 测试基础数据
每个性能测试都有一个入参t *testing.B,结构定义如下:
Go
type B struct {
common // 与 testing.T 共享的 testing.common ,负责记录日志、状态等
importPath string // 包含基准的包的导入路径
context *benchContext
N int // 目标代码执行次数,不需要用户了解具体值,会自动调整
previousN int // 上一次运行中的迭代次数
previousDuration time.Duration // 上次运行的总持续时间
benchFunc func(b *B) // 性能测试函数
benchTime benchTimeFlag // 性能测试函数最少执行的时间,默认为1s
bytes int64 // 每次迭代处理的字节数
missingBytes bool // 其中一个子基准标记没有设置字节。
timerOn bool // 是否已开始计时
showAllocResult bool
result BenchmarkResult // 测试结果
parallelism int // RunParallel创建并行性*GOMAXPROCS goroutines
// memStats的初始状态。Mallocs和MemStats。TotalAlloc。
startAllocs uint64 // 计时开始时堆中分配的对象总数
startBytes uint64 // 计时开始时堆中分配的字节总数
// 运行后此测试的净总数。
netAllocs uint64 // 计时结束时,堆中增加的对象总数
netBytes uint64 // 计时结束时,堆中增加的字节总数
// ReportMetric收集的额外指标。
extra map[string]float64
}T 组合了 common 类型
Go
// common包含T和B之间的公共元素,以及
// 捕获常见的方法,如Errorf。
type common struct {
mu sync.RWMutex // 保卫这群田地
output []byte // 测试或基准测试生成的输出。
w io.Writer // 对于flushToParent。
ran bool // 执行了测试或基准测试(或其中一个子测试)。
failed bool // 测试或基准测试失败。
skipped bool // 已跳过测试或基准测试。
done bool // 测试已完成,所有子测试均已完成。
helperPCs map[uintptr]struct{} // 写入文件/行信息时要跳过的函数
helperNames map[string]struct{} // helperPC转换为函数名
cleanups []func() // 测试结束时要调用的可选函数
cleanupName string // 清除函数的名称。
cleanupPc []uintptr // 调用Cleanup的点处的堆栈跟踪。
finished bool // 测试功能已完成。
chatty *chattyPrinter // 如果设置了chatty标志,则为chattyPrinter的副本。
bench bool // 当前测试是否为基准测试。
hasSub int32 // 以原子形式书写。
raceErrors int // 测试过程中检测到的种族数。
runner string // 运行测试的tRunner的函数名称。
parent *common
level int // 测试或基准的嵌套深度。
creator []uintptr // 如果级别>0,则堆栈跟踪父级调用t.Run的点。
name string // 测试或基准的名称。
start time.Time // 时间测试或基准测试已启动
duration time.Duration
barrier chan bool // 为了发出平行子测验的信号,他们可以开始。
signal chan bool // 发出测试完成的信号。
sub []*T // 要并行运行的子测试的队列。
tempDirMu sync.Mutex
tempDir string
tempDirErr error
tempDirSeq int32
}每个测试均对应一个 testing.common,不仅记录了测试函数的基础信息(比如名字),还管理了测试的执行过程和测试结果。
testing.commong是单元测试,性能测试和模糊测试的基础。
通过继承共同的结构,保证了各种测试的行为一致,降低使用的门槛。
4. testing.TB 接口
testing.common 实现的接口为 testing.TB,单元测试和性能测试通过该接口获取基础能力。
Go
type TB interface {
Cleanup(func()) // 清理
Error(args ...interface{}) // 表示测试失败+记录日志
Errorf(format string, args ...interface{}) // 格式化表示测试失败+记录日志
Fail() // 表示测试失败
FailNow() // 标记测试失败+结束当前测试
Failed() bool // 查询结果
Fatal(args ...interface{}) // 标记测试失败+记录日志+结束当前测试
Fatalf(format string, args ...interface{}) // 格式化标记测试失败+记录日志+结束当前测试
Helper() // 标记测试为 Helper (避免打印当前代码行号)
Log(args ...interface{}) // 记录日志
Logf(format string, args ...interface{}) // 格式化 记录日志
Name() string // 查询测试名
Setenv(key, value string) // 设置环境变量
Skip(args ...interface{}) // 记录日志+跳过测试
SkipNow() // 跳过测试
Skipf(format string, args ...interface{}) // 格式化记录日志+跳过测试
Skipped() bool // 查询测试是否被跳过
TempDir() string // 返回一个临时目录
//阻止用户实现的私有方法
//接口,因此将来不会添加
//违反Go 1兼容性。
private()
}5. 关键函数
5.1 testing.runBenchmarks
runBenchmarks负责创建name=Main的Benchmark作为启动case
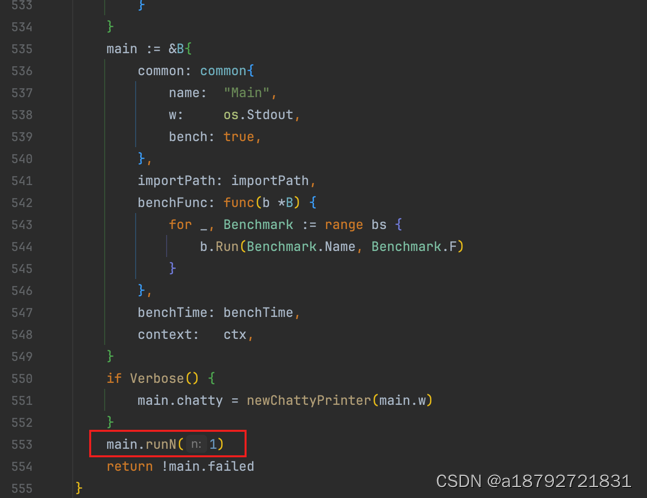
在testing.B.runN中执行testing.B.Run
5.2 testing.B.runN
在runN中启动定时器,然后执行benchFunc
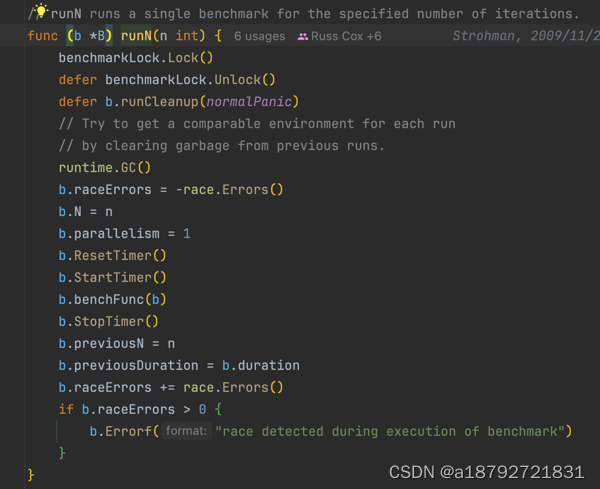
性能测试中,执行多少次,也时由runN中设置的
5.3 testing.B.StartTimer
StartTimer负责启动计时并初始化内存相关计数,测试执行时会自动调用(name=Main的testing.B启动),一般不需要用户启动
Go
func (b *B) StartTimer() {
if !b.timerOn {
runtime.ReadMemStats(&memStats) // 读取当前堆内存分配信息
b.startAllocs = memStats.Mallocs // 记录当前堆内存分配的对象数
b.startBytes = memStats.TotalAlloc // 记录当前堆内存分配的字节数
b.start = time.Now() // 记录测试启动时间
b.timerOn = true // 标记计时标志
}
}5.4 testing.B.StopTimer
StopTimer负责停止计时,并累加相应的统计值:
Go
func (b *B) StopTimer() {
if b.timerOn {
b.duration += time.Since(b.start) // 累加测试耗时
runtime.ReadMemStats(&memStats) // 读取当前堆内存分配信息
b.netAllocs += memStats.Mallocs - b.startAllocs // 累加对北村分配的对象数
b.netBytes += memStats.TotalAlloc - b.startBytes // 累加堆内存分配的字节数
b.timerOn = false // 标记计时标志
}
}5.5 testing.B.ResetTimer
ResetTime用于重置计时器,相应地也会把其他统计值也重置:
Go
func (b *B) ResetTimer() {
if b.timerOn {
runtime.ReadMemStats(&memStats) // 读取当前堆内存分配信息
b.startAllocs = memStats.Mallocs // 记录当前堆内存分配的对象数
b.startBytes = memStats.TotalAlloc // 记录当前堆内存分配的字节数
b.start = time.Now() // 记录测试启动时间
}
b.duration = 0 // 清空耗时
b.netAllocs = 0 // 清空内存分配的对象数
b.netBytes = 0 // 清空内存分配的字节数
}ResetTimer必将常用,比如在一个测试中,初始化部分耗时比较长,初始化后再开始计时
5.6 testing.B.Run
Go
func (b *B) Run(name string, f func(b *B)) bool {
// 是否有子测试
atomic.StoreInt32(&b.hasSub, 1)
// 加锁
benchmarkLock.Unlock()
// 延迟解锁
defer benchmarkLock.Lock()
// 获取 name等信息
benchName, ok, partial := b.name, true, false
// name 进行匹配
if b.context != nil {
benchName, ok, partial = b.context.match.fullName(&b.common, name)
}
// 匹配失败,结束
if !ok {
return true
}
var pc [maxStackLen]uintptr
n := runtime.Callers(2, pc[:])
// 新建子测试数据结构
sub := &B{
common: common{
signal: make(chan bool),
name: benchName,
parent: &b.common,
level: b.level + 1,
creator: pc[:n],
w: b.w,
chatty: b.chatty,
bench: true,
},
importPath: b.importPath,
benchFunc: f,
benchTime: b.benchTime,
context: b.context,
}
// 是否并发
if partial {
atomic.StoreInt32(&sub.hasSub, 1)
}
// 输出日志信息
if b.chatty != nil {
labelsOnce.Do(func() {
fmt.Printf("goos: %s\n", runtime.GOOS)
fmt.Printf("goarch: %s\n", runtime.GOARCH)
if b.importPath != "" {
fmt.Printf("pkg: %s\n", b.importPath)
}
if cpu := sysinfo.CPU.Name(); cpu != "" {
fmt.Printf("cpu: %s\n", cpu)
}
})
fmt.Println(benchName)
}
// 先执行一次子测试,如果子测试不出错且子测试没有子测试则继续执行run
if sub.run1() {
// run 中决定了要执行多少次runN
sub.run()
}
// 累加统计结果到父测试中
b.add(sub.result)
return !sub.failed
}所有的测试都是先使用run1方法执行一次,然后在决定要不要继续迭代。
测试结果实际上以最后一次迭代的数据为准,最后一次迭代往往B.N更大,测试准确性相对更高。
5.7 testing.B.run1
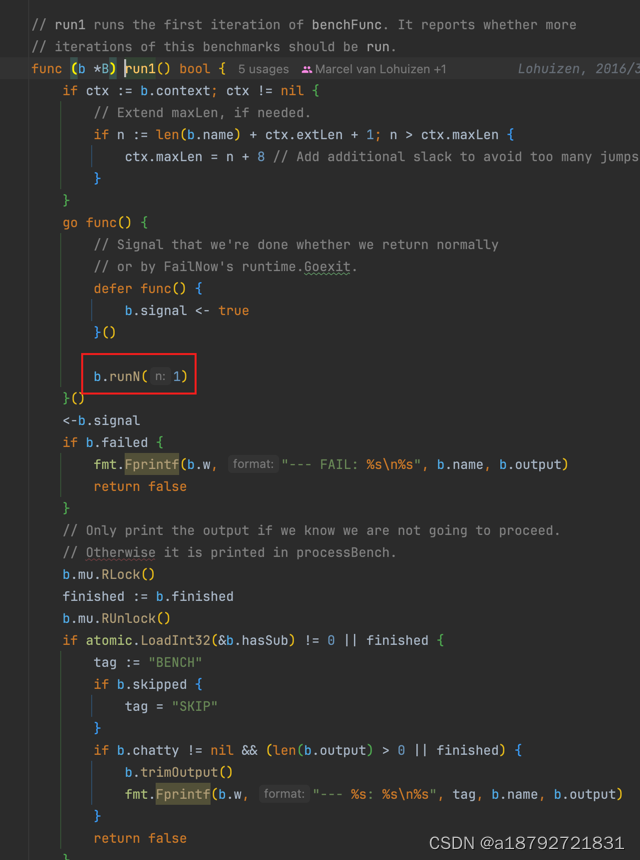
在 run1中,调用runN的时候,传入1,表示执行一次BenchmarkXxx方法,统计执行一次的耗时。
5.8 testing.B.run
Go
func (b *B) run() {
// 打印额外的统计信息
labelsOnce.Do(func() {
fmt.Fprintf(b.w, "goos: %s\n", runtime.GOOS)
fmt.Fprintf(b.w, "goarch: %s\n", runtime.GOARCH)
if b.importPath != "" {
fmt.Fprintf(b.w, "pkg: %s\n", b.importPath)
}
if cpu := sysinfo.CPU.Name(); cpu != "" {
fmt.Fprintf(b.w, "cpu: %s\n", cpu)
}
})
// 如果是子测试,那么此时子测试还未执行run1,在 processBench中会对子测试创建一个B,然后执行run1,接着执行 doBench
if b.context != nil {
// Running go test --test.bench
b.context.processBench(b) // Must call doBench.
} else {
// Running func Benchmark.
b.doBench()
}
}5.9 processBench
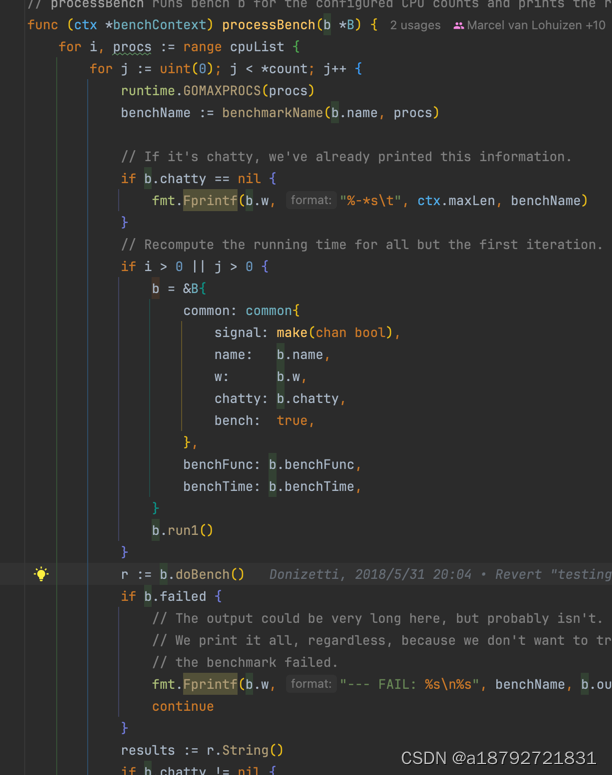
执行子测试的doBench
5.10 tetsing.B.doBench
Go
func (b *B) doBench() BenchmarkResult {
go b.launch() // goroutine 执行 launch 结束
<-b.signal
return b.result
}5.11 testing.B.launch
Go
func (b *B) launch() {
// 延迟调用通知父测试结束
defer func() {
b.signal <- true
}()
// 如果用户指定了,那么按照用户指定的执行
if b.benchTime.n > 0 {
b.runN(b.benchTime.n)
} else {
// 获取默认的时间间隔,默认为1s
d := b.benchTime.d
// 最少执行 b.benchTime(默认为1s)时间,最多执行1e9次
for n := int64(1); !b.failed && b.duration < d && n < 1e9; {
last := n
// 获取1秒的纳秒数
goalns := d.Nanoseconds()
// 获取上一次执行次数,1次
prevIters := int64(b.N)
// 获取上一次执行时间
// 执行 run 之前需要执行一次 run1 也就是说 prevIters 是第一次执行的耗时
prevns := b.duration.Nanoseconds()
if prevns <= 0 {
// Round up, to avoid div by zero.
prevns = 1
}
// goalns * prevIters 上次执行持续了多少纳秒
// prevns 上次执行一次的耗时
// n 表示上次执行多少次
n = goalns * prevIters / prevns
// 先增长 20% , n = 1.2n
n += n / 5
// 不能增加过快,如果 20% 比100倍还大,那么取小值
n = min(n, 100*last)
// 并且至少增加1次
n = max(n, last+1)
// 不能超过 1e9
n = min(n, 1e9)
// 启动执行
b.runN(int(n))
// 执行完成后,进行下一次循环
}
}
// 统计结果
b.result = BenchmarkResult{b.N, b.duration, b.bytes, b.netAllocs, b.netBytes, b.extra}
}在不考虑程序出错,而且用户没有主动停止测试的场景下,每个测试至少执行b.benchTime长的时间(秒),默认为1s.
先执行一遍,看看用户代码执行一次需要花多长时间,如果时间比较短,那么B.N需要足够大,才可以测试更准确。
如果时间比较长,那么B.N需要足够少,否则测试效率比较慢。
n = goalns * prevIters / prevns ,如果 prevns比较少,那么n就会从一个比较大的值开始循环
如果prevns比较大,那么n就会以一个比较小的值开始循环,直到单批次超过1秒。
5.12 testing.B.SetBytes
这个函数用来设置单词迭代处理的字节数,一旦设置了这个字节数,那么输出报告中奖出现 xx MB/s 的信息。
用来表示待测函数处理字节的性能,待测函数每次处理多少字节只有用户知道,所以需要用户设置。
比如:
Go
func MakeWithout(n int) []int {
var s []int
for i := 0; i < n; i++ {
s = append(s, i)
}
return s
}
func MakeWith(n int) []int {
s := make([]int, n)
for i := 0; i < n; i++ {
s = append(s, i)
}
return s
}
func BenchmarkMakeWithout(b *testing.B) {
b.SetBytes(1024)
for i := 0; i < b.N; i++ {
MakeWithout(1000)
}
}
func BenchmarkMakeWith(b *testing.B) {
b.SetBytes(1024)
for i := 0; i < b.N; i++ {
MakeWith(1000)
}
}执行结果
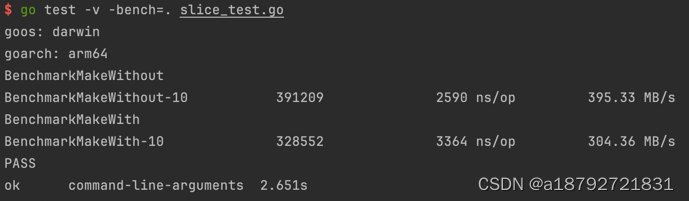
6. 数据统计
在测试开始时,会把当前内存值记录下来:
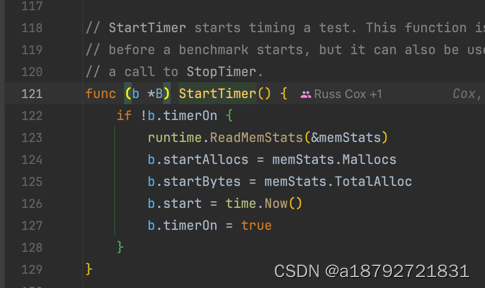
也就是记入testing.B.startAllocs和testing.B.startBytes,测试结束后,会用最终内存值与开始时的内存相减,
得到净增加的内存值,并记入testing.B.netAllocs和testing.B.netBytes中。
每个测试结束后,会吧结果保存到BenchmarkResult中
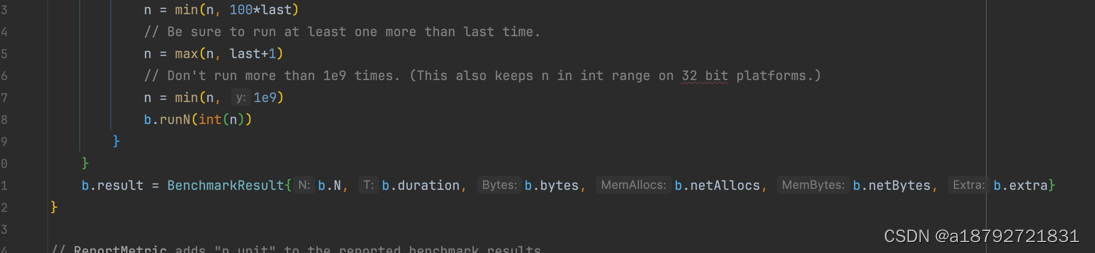
Go
type BenchmarkResult struct {
N int // 用户代码执行的次数
T time.Duration // 测试耗时
Bytes int64 // 用户代码每次处理的字节数,SetBytes设置的值
MemAllocs uint64 // 内存对象净增加值
MemBytes uint64 // 内存字节净增加值
// 附加信息
Extra map[string]float64
}最终统计时,只需要把净增加值除以N就能得到每次新增多少内存。