TimingWheel
字段:
buckets:Array.tabulate[TimerTaskList]类型,其每一个项都对应时间轮中的一个时间格,用于保存
TimerTaskList的数组。在TimingWheel中,同一个TimerTaskList中的不同定时任务的到期时间可能
不同,但是相差时间在一个时间格的范围内。
tickMs:当前时间轮中一个时间格表示的时间跨度。
wheelSize:当前时间轮的格数,也是buckets数组的大小。
interval:当前时间轮的时间跨度,即tickMs*wheelSize。当前时间轮只能处理时间范围在
currentTime~currentTime+tickMs*WheelSize之间的定时任务,超过这个范围,则需要将任务添加到
上层时间轮中。
taskCounter:各层级时间轮中任务的总数。
startMs:当前时间轮的创建时间。
queue:DelayQueue类型,整个层级时间轮共用的一个任务队列,其元素类型是TimerTaskList(实
现了Delayed接口)。
currentTime:时间轮的指针,将整个时间轮划分为到期部分和未到期部分。在初始化时,
currentTime被向下取整成tickMs的倍数,近似等于创建时间,但并不是严格的创建时间。
overflowWheel:上层时间轮的引用。方法:
在TimeWheel中提供了add()、advanceClock()、addOverflowWheel()三个方法,这三个方法实现了时间轮的基础功能。add()方法实现了向时间轮中添加定时任务的功能,它同时也会检测待添加的任务是否已经到期。
scala
def add(timerTaskEntry: TimerTaskEntry): Boolean = {
val expiration = timerTaskEntry.expirationMs
if (timerTaskEntry.cancelled) { // 任务已经被取消
false
} else if (expiration < currentTime + tickMs) { //任务已经到期
false
// 任务在当前时间轮的跨度范围内
} else if (expiration < currentTime + interval) {
// 按照任务的到期时间查找此任务属于的时间格,并将任务添加到对应的TimerTaskList中
val virtualId = expiration / tickMs
val bucket = buckets((virtualId % wheelSize.toLong).toInt)
bucket.add(timerTaskEntry)
// 整个时间轮表示的时间跨度是不变的,随着表针currentTime的后移,当前时间轮能处理
// 时间段也在不断后移,新来的TimerTaskEntry会复用原来已经清理过的
// TimerTaskList(bucket)。此时需要重置TimerTaskList的到期时间,并将bucket
// 重新添加到DelayQueue中。后面还会介绍这个DelayQueue的作用
if (bucket.setExpiration(virtualId * tickMs)) { // 设置bucket的到期时间
queue.offer(bucket)
}
true
} else {// 超出了当前时间轮的时间跨度范围,则将任务添加到上层时间轮中处理
if (overflowWheel == null)
addOverflowWheel()// 创建上层时间轮
overflowWheel.add(timerTaskEntry)
}
}addOverflowWheel()方法会创建上层时间轮,默认情况下,上层时间轮的tickMs是当前整个时间轮的时间跨度interval。
scala
private[this] def addOverflowWheel(): Unit = {
synchronized {
if (overflowWheel == null) {
// 创建上层时间轮,注意,上层时间轮的tickMs更大,wheelSize不变,则表示的时间
// 跨度也就越大
// 随着上层时间轮表针的转动,任务还是会回到最底层的时间轮上,等待最终超时
overflowWheel = new TimingWheel(
tickMs = interval,
wheelSize = wheelSize,
startMs = currentTime,
taskCounter = taskCounter, //全局唯一的任务计数器
queue //全局唯一的任务队列
)
}
}
}advanceClock()方法会尝试推进当前时间轮的表针currentTime,同时也会尝试推进上层的时间轮的表
针。随着当前时间轮的表针不断被推进,上层时间轮的表针也早晚会被推进成功。
scala
def advanceClock(timeMs: Long): Unit = {
// 尝试移动表针currentTime,推进可能不止一格
if (timeMs >= currentTime + tickMs) {
currentTime = timeMs - (timeMs % tickMs)
// 尝试推进上层时间轮的表针
if (overflowWheel != null)
overflowWheel.advanceClock(currentTime) }
}SystemTimer
SystemTimer是Kafka中的定时器实现,它在TimeWheel的基础上添加了执行到期任务、阻塞等待最近到
期任务的功能。
字段:
scala
taskExecutor:JDK提供的固定线程数的线程池实现,由此线程池执行到期任务。
delayQueue:各个层级的时间轮共用的DelayQueue队列,主要作用是阻塞推进时间轮表针的线程
(ExpiredOperationReaper),等待最近到期任务到期。
taskCounter:各个层级时间轮共用的任务个数计数器。
timingWheel:层级时间轮中最底层的时间轮。tickMs、wheelSize、startMs等字段不再重复介绍
readWriteLock:用来同步时间轮表针currentTime修改的读写锁。方法:
主要有add()和advanceClock()两个方法。
SystemTimer.add()方法在添加过程中如果发现任务已经到期,则将任务提交到taskExecutor中执行;如果任务未到期,则调用TimeWheel.add()方法提交到时间轮中等待到期后执行。SystemTimer.add()方法的实现如下:
scala
def add(timerTask: TimerTask): Unit = {
readLock.lock()
try {
// 将TimerTask封装成TimerTaskEntry,并计算其到期时间
// timerTask.delayMs + System.currentTimeMillis()即expirationMs
addTimerTaskEntry(new TimerTaskEntry(timerTask,
timerTask.delayMs + System.currentTimeMillis()))
} finally {
readLock.unlock()
}
}
private def addTimerTaskEntry(timerTaskEntry: TimerTaskEntry): Unit = {
// 向时间轮提交添加任务失败,任务可能已到期或已取消
if (!timingWheel.add(timerTaskEntry)){
if (!timerTaskEntry.cancelled) // 将到期任务提交到taskExecutor执行
taskExecutor.submit(timerTaskEntry.timerTask)
}
}SystemTimer.advanceClock()方法完成了时间轮表针的推进,同时对到期的TimerTaskList中的任务进行
处理。如果TimerTaskList到期,但是其中的某些任务未到期,会将未到期任务进行降级,添加到低层次的
时间轮中继续等待;如果任务到期了,则提交到taskExecutor线程池中执行。
scala
def advanceClock(timeoutMs: Long): Boolean = {
var bucket = delayQueue.poll(timeoutMs, TimeUnit.MILLISECONDS) // 阻塞等待
if (bucket != null) { // 在阻塞期间,有TimerTaskList到期
writeLock.lock()
try {
while (bucket != null) {
timingWheel.advanceClock(bucket.getExpiration()) // 推进时间轮表针
// 调用reinsert,尝试将bucket中的任务重新添加到时间轮。此过程并不一定是将任
// 务提交给taskExecutor执行,对于未到期的任务只是从原来的时间轮降级到下层的
// 时间轮继续等待
bucket.flush(reinsert)
bucket = delayQueue.poll() // 此poll()方法不会阻塞
}
} finally {
writeLock.unlock()
}
true
} else {
false
}
}
// TimerTaskEntry重新提交到时间轮中
private[this] val reinsert = (timerTaskEntry: TimerTaskEntry) => addTimerTaskEntry(timerTaskEntry)DelayedOperation
时间轮中的每一个时间格对应一个TimerTaskList,每个TimerTaskList由多个TimerTask组成,TimerTask是一个抽象的接口,由DelayedOperation实现。
Kafka使用DelayedOperation抽象类表示延迟操作,它对TimeTask进行了扩展,除了有定时执行的功能,还提供了检测其他执行条件的功能。
像kafka中具体使用的DelayedProduce、DelayedFetch等都是DelayedOperation的具体实现。

字段:
delayMs:延迟操作的延迟时长
completed:标识该操作是否完成,初始为false
tryCompletePending:方法:
-
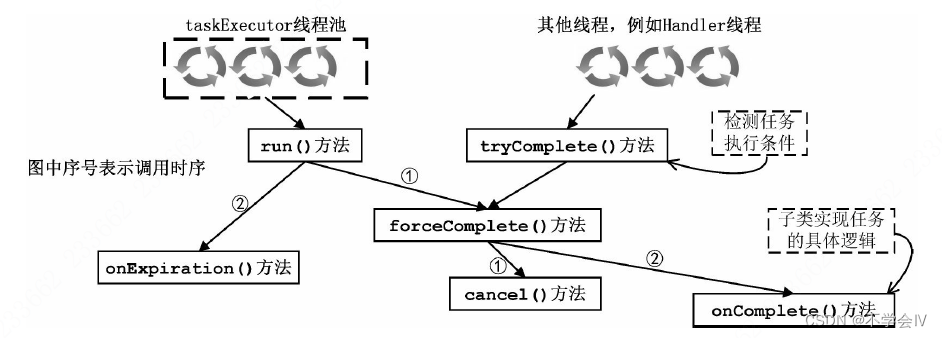
onComplete()方法:抽象方法,DelayedOperation的具体业务逻辑。例如DelayedProduce中该方法的实现执行回调方法(客户端限流和将响应放入responseQueue)。此方法只能在forceComplete()方法中被调用,且在DelayedOperation的整个生命周期中只能被调用一次。
-
forceComplete()方法:如果DelayedOperation没有完成,则先将任务从时间轮中删除掉,然后调用
onComplete()方法执行其具体的业务逻辑。该方法的调用时机有两个:1. tryComplete内部调用;2. 操作已经过期。可能有多个Handler线程并发检测DelayedOperation的执行条件,这就可能导致多个线程并发调用
forceComplete()方法,但是onComplete()方法有只能调用一次的限制。因此在forceComplete方法中用
AtomicBoolean的CAS操作进行限制,从而实现onComplete()方法只被调用一次。
scaladef forceComplete(): Boolean = { // 根据completed字段的值判断延迟操作是否已经完成 if (completed.compareAndSet(false, true)) { // 调用的是TimerTask.cancel()方法,将其从TimerTaskList中删除 cancel() // 延迟操作的真正逻辑,例如,DelayProduce就是向客户端返回ProduceResponse响应 onComplete() true } else { // 没完成则返回false false } } -
onExpiration()方法:抽象方法,DelayedOperation到期时执行的具体逻辑。对于DelayedProduce而言,是更新metrics指标
-
run()方法:DelayedOperation到期时会提交到SystemTimer.taskExecutor线程池中执行。其中会调用
forceComplete()方法完成延迟操作,然后调用onExpiration()方法执行延迟操作到期执行的相关代
码。
scalaoverride def run(): Unit = { if (forceComplete()) onExpiration() } -
tryComplete()方法:抽象方法,在该方法中子类会根据自身的具体类型,检测执行条件是否满足,
若满足则会调用forceComplete()完成延迟操作。
DelayedOperation可能因为到期而被提交到SystemTimer.taskExecutor线程池中执行,也可能在其他线程
检测其执行条件时发现已经满足执行条件,而将其执行。
DelayedOperationPurgatory
DelayedOperationPurgatory是一个辅助类,提供了管理DelayedOperation以及处理到期DelayedOperation
的功能,会传入类型Produce或者Fetch等,即针对DelayedProduce、DelayedFetch等分别会对应一个DelayedOperationPurgatory进行维护
字段:
timeoutTimer:前面介绍的SystemTimer对象。
watchersForKey:管理Watchers的Pool对象,下面会详细介绍。
removeWatchersLock:对watchersForKey进行同步的读写锁操作。
estimatedTotalOperations:记录了该DelayedOperationPurgatory中的DelayedOperation个数。
expirationReaper:此字段是一个ShutdownableThread线程对象,主要有两个功能,一是推进时间轮
表针,二是定期清理watchersForKey中已完成的DelayedOperation,清理条件由purgeInterval字段指
定。在DelayedOperationPurgatory初始化时会启动此线程,下面会详细介绍
brokerId
purgeInterval:Int类型,默认1000,若已完成但未清理操作大于该值,则进行清理
reaperEnabled:默认为true
timerEnabled:默认为trueDelayedOperationPurgatory中的watchersForKey字段用于管理DelayedOperation,它是PoolAny, Watchers
类型,Pool的底层实现是ConcurrentHashMap。watchersForKey集合的key表示的是Watchers中的
DelayedOperation关心的对象,其value是Watchers类型的对象,Watchers是DelayedOperationPurgatory的内部类,表示一个DelayedOperation的集合,底层使用LinkedList实现。
Watchers的字段只有一个operations字段,它是一个用于管理DelayedOperation的LinkedList队列,下面来分析
Watchers其核心方法有三个:
-
watch()方法:将DelayedOperation添加到operations队列中。
-
tryCompleteWatched()方法:遍历operations队列,对于未完成的DelayedOperation执行tryComplete()
方法尝试完成,将已完成的DelayedOperation对象移除。如果operations队列为空,则将Watchers从
DelayedOperationPurgatory. watchersForKey中删除。
scaladef tryCompleteWatched(): Int = { var completed = 0 operations synchronized { val iter = operations.iterator() while (iter.hasNext) { // 遍历operations队列 val curr = iter.next() // DelayedOperation已经完成,将其从operations队列移除 if (curr.isCompleted) { iter.remove() } else if (curr.maybeTryComplete()) { // 调用DelayedOperation.maybeTryComplete()方法,尝试完成延迟操作 // maybeTryComplete是tryComplete的线程安全方法,旧版中的实现为 // curr synchronized curr.tryComplete() completed += 1 iter.remove() // 完成后将DelayedOperation对象从operations队列移除 } } } if (operations.size == 0) removeKeyIfEmpty(key, this) completed } -
purgeCompleted()方法:负责清理operations队列,将已经完成的DelayedOperation从operations队列
中移除,如果operations队列为空,则将Watchers从watchersForKey集合中删除。
expirationReaper线程的doWork()方法的代码如下:
scala
override def doWork() {
advanceClock(200L) // 此方法最长阻塞200ms
}
// 下面是DelayedOperationPurgatory.advanceClock()方法的实现
def advanceClock(timeoutMs: Long) {
timeoutTimer.advanceClock(timeoutMs) // 尝试推进时间轮的表针
// DelayedOperation到期后被SystemTimer.taskExecutor完成后,并不会通知
// DelayedOperationPurgatory删除DelayedOperation
// 当DelayedOperationPurgatory与SystemTimer中的DelayedOperation数量相差到
// 一个阈值时,会调用purgeCompleted()方法执行清理工作
if (estimatedTotalOperations.get - delayed > purgeInterval) {
estimatedTotalOperations.getAndSet(delayed) // 更新estimatedTotalOperations
// 调用Watchers.purgeCompleted()方法清理已完成的DelayedOperation
val purged = allWatchers.map(_.purgeCompleted()).sum
}
}方法:
DelayedOperationPurgatory的核心方法有两个,checkAndComplete()和tryCompleteElseWatch()。checkAndComplete()方法,主要是根据传入的key尝试执行对应的Watchers中的DelayedOperation,通过调用Watchers. tryCompleteWatched()方法实现。
scala
/**
* Check if some delayed operations can be completed with the given watch key,
* and if yes complete them.
*
* @return the number of completed operations during this process
*/
def checkAndComplete(key: Any): Int = {
val watchers = inReadLock(removeWatchersLock) { watchersForKey.get(key) }
if(watchers == null)
0
else
watchers.tryCompleteWatched()
}tryCompleteElseWatch()方法,主要功能是检测DelayedOperation是否已经完成,若未完成则添加到watchersForKey以及SystemTimer中。具体的执行步骤如下:
scala
def tryCompleteElseWatch(operation: T, watchKeys: Seq[Any]): Boolean = {
// 步骤1:调用DelayedOperation.tryComplete()方法,尝试完成延迟操作
var isCompletedByMe = operation.tryComplete()
if (isCompletedByMe) // 已完成,直接返回
return true
var watchCreated = false
// 步骤2:传入的key可能有多个,每个key表示一个DelayedOperation关心的条件
// 将DelayedOperation添加到所有key对应的Watchers中
for (key <- watchKeys) {
// 添加过程中若已经被其他线程完成,则放弃后续添加过程,ExpiredOperationReaper线
// 程会定期清理watchersForKey,所以这里不需要清理之前添加的key
if (operation.isCompleted)
return false
// 将DelayedOperation添加到watchersForKey中对应的Watchers中
watchForOperation(key, operation)
if (!watchCreated) {
watchCreated = true
// 增加estimatedTotalOperations的值
estimatedTotalOperations.incrementAndGet()
}
}
// 步骤3:第二次尝试完成此DelayedOperation,如果成功执行,则直接返回
isCompletedByMe = operation.maybeTryComplete()
if (isCompletedByMe)
return true
// 执行到这里可以保证,此DelayedOperation不会错过任何key上触发的checkAndComplete()
// 步骤4:将DelayedOperation提交到SystemTimer
if (!operation.isCompleted) {
timeoutTimer.add(operation)
if (operation.isCompleted) { // 再次检测完成情况
operation.cancel() // 如果已完成,则将其从SystemTimer中删除
}
}
false
}实际应用
下面以DelayedProduce为例,串起整个流程。首先对DelayedProduce类作一个了解。
DelayedProduce
字段:
delayMs:produceRequest的超时时长(produceRequest.timeout.toLong)
produceMetadata:ProduceMetadata对象。ProduceMetadata中为一个ProducerRequest中的所有相关分
区记录了一些追加消息后的返回结果,主要用于判断DelayedProduce是否满足执行条件
responseCallback:任务满足条件或到期执行时,在DelayedProduce.onComplete()方法中调用的回调
函数。其主要功能是向RequestChannels中对应的responseQueue添加ProducerResponse,之后
Processor线程会将其发送给客户端。
replicaManager:此DelayedProduce关联的ReplicaManager对象。下面介绍一下ProduceMetadata对象:
scala
case class ProduceMetadata(produceRequiredAcks: Short,
produceStatus: Map[TopicPartition, ProducePartitionStatus]) {...}produceRequiredAcks字段记录了ProduceRequest中acks字段的值,produceStatus记录了每个
Partition的ProducePartitionStatus。ProducePartitionStatus的定义如下:
scala
case class ProducePartitionStatus(requiredOffset: Long, responseStatus: PartitionResponse) {
@volatile var acksPending = false
}requiredOffset字段记录了ProducerRequest中追加到此分区的最后一个消息的offset,用来判断其它分区是否已经同步。acksPending字段表示是否正在等待ISR集合中其他副本与Leader副本同步requiredOffset之前的消息,如果ISR集合中所有副本已经完成了requiredOffset之前消息的同步,则此值被设置为false。responseStatus字段主要用来记录ProducerResponse中的错误码。
在构造DelayedProduce对象时,会对produceMetadata字段中的produceStatus集合进行设置,代码如下:
scala
produceMetadata.produceStatus.foreach { case (topicPartition, status) =>
// 对应分区的写入操作成功,则等待ISR集合中的副本完成同步
if (status.responseStatus.error == Errors.NONE) {
// Timeout error state will be cleared when required acks are received
status.acksPending = true
// 下面是预设错误码,如果ISR集合中的副本在此请求超时之前顺利完成了同步,会清除此错误码
status.responseStatus.error = Errors.REQUEST_TIMED_OUT
} else {
// 如果写入操作出现异常,则该分区不需要等待
status.acksPending = false
}
trace(s"Initial partition status for $topicPartition is $status")
}DelayedProduce实现了DelayedOperation.tryComplete()方法,其主要逻辑是检测是否满足DelayedProduce
的执行条件,并在满足执行条件时调用forceComplete()方法完成该延迟任务。满足下列任一条件,即表示此
分区已经满足DelayedProduce的执行条件。只有ProducerRequest中涉及的所有分区都满足条件,DelayedProduce才能最终执行。
(1)某分区出现了Leader副本的迁移。该分区的Leader副本不再位于此节点上,此时会更新对应
ProducePartitionStatus中记录的错误码。
(2)正常情况下,ISR集合中所有副本都完成了同步后,该分区的Leader副本的HW位置已经大于对应
的ProduceStatus.requiredOffset。此时会清空初始化中设置的超时错误码。
(3)如果出现异常,则更新分区对应的ProducePartitionStatus中记录的错误码。
scala
override def tryComplete(): Boolean = {
// 遍历produceMetadata中的所有分区的状态
produceMetadata.produceStatus.foreach { case (topicPartition, status) =>
if (status.acksPending) { // 检查此分区是否已经满足DelayedProduce执行条件
// 获取对应的Partition对象
val (hasEnough, error) = replicaManager.getPartition(topicPartition) match {
case Some(partition) =>
// 检查此分区的HW位置是否大于requiredOffset。这里涉及Partition类中的
// checkEnoughReplicasReachOffset()方法,此方法会在后面介绍Partition时详细分析
partition.checkEnoughReplicasReachOffset(status.requiredOffset)
case None =>
// 条件1:找不到此分区的Leader
(false, Errors.UNKNOWN_TOPIC_OR_PARTITION)
}
// 条件2:此分区Leader副本的HW大于对应的requiredOffset
// 条件3:出现异常
if (error != Errors.NONE || hasEnough) {
status.acksPending = false
status.responseStatus.error = error
}
}
}
// 检查全部的分区是否都已经符合DelayedProduce的执行条件
if (!produceMetadata.produceStatus.values.exists(_.acksPending))
forceComplete()
else
false
}介绍完DelayedProduce类,让我们介绍对DelayedProduce的引用和处理
引用和处理
调用链:KafkaApis.handleProduceRequest() -> ReplicaManager.appendRecords()
在ReplicaManager.appendRecords()中,先调用appendToLocalLog()方法执行真正的追加消息到Log的操作。之后判断是否要构造DelayedProduce(主要看ack是否为-1)。构造完DelayedProduce后执行DelayedOperationPurgatory.tryCompleteElseWatch()方法,该方法的入参是DelayedProduce和producerRequestKeys(该生产请求涉及的所有分区),该方法的作用是将DelayedProduce放入Watchers和SystemTimer中,详见DelayedOperationPurgatory。
scala
val produceMetadata = ProduceMetadata(requiredAcks, produceStatus)
val delayedProduce = new DelayedProduce(timeout, produceMetadata, this, responseCallback, delayedProduceLock)
// producerRequestKeys表示生产请求中所有的分区名
val producerRequestKeys = entriesPerPartition.keys.map(new TopicPartitionOperationKey(_)).toSeq
delayedProducePurgatory.tryCompleteElseWatch(delayedProduce, producerRequestKeys)后续某个分区的高水位变化,或者收到follower的ack后会尝试完成这个DelayedProduce,只有当所有涉及的分区都满足条件后才算真正完成。
总结
DelayedProduce通过DelayedOperationPurgatory.tryCompleteElseWatch()被放入Watchers和SystemTimer中。
Watchers的tryCompleteWatched()方法会尝试完成DelayedProduce(调用DelayedProduce的tryComplete()方法),那么tryCompleteWatched()是怎么被调用的呢?Watchers的tryCompleteWatched()方法只会被DelayedOperationPurgatory.checkAndComplete()方法调用,而DelayedOperationPurgatory.checkAndComplete()方法会在多种情况下被调用,如果是DelayedProduce,则在两种情况下被调用:
- 分区的HW发生了变动(acks = -1时)
- 接收到了follower副本的fetch请求(acks > 1时)
scala
/**
* Try to complete some delayed produce requests with the request key;
* this can be triggered when:
*
* 1. The partition HW has changed (for acks = -1)
* 2. A follower replica's fetch operation is received (for acks > 1)
*/
def tryCompleteDelayedProduce(key: DelayedOperationKey) {
val completed = delayedProducePurgatory.checkAndComplete(key)
}因此对于acks=-1的情况,如果分区HW发生了变化,则会尝试完成DelayedProduce。如果能够成功完成,则该任务会从SystemTimer中移除。
DelayedProduce加入SystemTimer后,是通过DelayedOperationPurgatory.expirationReaper推动时间轮的。如果任务已经在Watchers中完成,则已经被移除。如果还没有则会一直等到过期,然后执行DelayedProduce的onExpiration()方法,具体逻辑是通过metrics记录这一次过期信息。
例子:
DelayProduce关心的对象是TopicPartitionOperationKey对象,表示的是某个Topic中的某个分区。假设现在有一个ProducerRequest请求,它要向名为"test"的Topic中追加消息,分区的编号为0,此分区当前的ISR集合中有三个副本。该ProducerRequest的acks字段为-1表示需要ISR集合中所有副本都同步了该请求中的消息才能返回
ProduceResponse。Leader副本处理此ProducerRequest时会为其生成一个对应的DelayedProduce对象,并交给DelayedOperationPurgatory管理,DelayedOperationPurgatory会将其存放到"test0"(TopicPartitionOperationKey对象)对应的Watchers中,同时也会将其提交到SystemTimer中。之后,每当Leader副本收到Follower副本发送的对"test-0"的FetchRequest时,都会检测"test-0"对应的Watchers中的DelayedProduce是否已经满足了执行条件,如果满足执行条件就会执行DelayedProduce,向客户端返回
ProduceResponse。最终,该DelayedProduce会因满足执行条件或时间到期而被执行。
补充DelayedFetch
调用链:KafkaApis.handleFetchRequest() -> ReplicaManager.fetchMessages()