文章目录
前言
最近接到一个百万级excel数据导入导出的需求,大概就是我们在进行公众号API群发的时候,需要支持500w以上的openid进行群发,并且可以提供发送openid数据的导出功能。可能有的同学会说,这么大的数据量发送为啥不用标签发送呢。哈哈,标签发送需要提前打标签微信限制50个一批,我们开10个线程也是需要3个小时左右才能打完,这样肯定不能满足客户需求。如果用openid群发就不一样了,微信支持10000个每批,基本上我开5个线程同时发送差不多几分钟搞定。所以,问题就来到了百万级excel数据的导入与导出啦。
技术积累
EasyExcel是什么
EasyExcel是一个基于Java的、快速、简洁、解决大文件内存溢出的Excel处理工具。他能让你在不用考虑性能、内存的等因素的情况下,快速完成Excel的读、写等功能。
作为一个资深的搬砖人,秉承着能够用CV大法,绝不自己造轮子的原则,我肯定选择这个阿里开源的excel读写工具来开发功能。
使用案例
对于excel的读、写、填充都有简单的案例,有兴趣的同学可以自己去看,这里不再重复叙述。
https://easyexcel.opensource.alibaba.com/docs/current/quickstart/read
实战演示
相信有很多的同学都使用过Easyexcel这个开源中间件,基本上很多的管理系统项目做到导出导入功能都会使用这个中间件。按照目前使用的情况来看,这个中间件还是比较稳定的,而且这个开源社区的活跃度也是比较高,基本上很难遇到不能解决的问题。
对于简单的excel导入导出我们直接安装Easyexcel提供的Demo就能够完美搞定,但是遇到比较大的数据量的时候就需要我们特殊处理下业务逻辑了。比如今天的重点百万级数据的导入导出。
实现思路
1、由于Easyexcel读功能是对excel一行一行进行读的,这是为了保证不过多占用我们内存。如果我们系统需要对数据进行入库的话则需要对数据进行缓存,比如1w每批次入库。虽然会损失一定的内存,但是写库时间大大降低了呀;
2、如果传入的excel有多个sheet,可以考虑开启多个线程进行读excel。比如每个sheet一个线程,但是线程需要做好管理,如使用线程池等等。但是,一般大数据量都不使用excel来保存,而是使用csv来储存数据,因为这个格式简单、体积小、易于使用、可被多种软件打开和编辑。当然,Easyexel也是可以读取csv文件的,但因为要兼容csv文件就不采用多sheet的方式,因为csv没有sheet。
bash
EasyExcel.read(filePath, Object.class, new PageReadListener<Object>(dataList ->{
//TODO 数据处理,默认读取0号sheet
}, 10000)).sheet().doRead();3、excel导出目前Easyexcel最新版本是不支持多线程写数据的,只能单线程进行写excel。为了保证写excel效率,我采用20w数据一批一次写入excel。
4、由于excel数据行数超过100w打开时间特别长,所以我们在导出的时候对数据进行切割,每个sheet最多只保存100w数据,其他数据写入下个sheet。
5、为了保证我们每批次可以写入20w数据到excel,那么,我必须保证能够用最短的时间从数据库抓取20w数据。这里我们可以采用多线程每个线程去拉5w条,开启4个线程足够,然后用countdownlatch进行多线程处理。当然,如果内存足够可以一次从数据库拉取20w数据,其实也不大最多也才几兆而已。
bash
//需要导出的总数量
int total = count(*)
//每次读20w数据
int readNum = 20 * 10000;
//每个sheet总数据
int sheetDataNum = 100 * 10000;
//需要写入sheetNum
int sheetNum = total % sheetDataNum == 0 ? total / sheetDataNum : (total / sheetDataNum)+1;
//计算每个线程查询数据库次数
int queryNum = sheetDataNum / readNum;
//最后一个线程查询数据库次数
int lastQueryNum = total % sheetDataNum == 0 ? queryNum
: (total % sheetDataNum % readNum == 0 ? (total % sheetDataNum / readNum) : (total % sheetDataNum / readNum + 1));
//导出逻辑
for (int i = 0; i < sheetNum; i++) {
final int finalI = i;
new Runnable() {
@Override
public void run() {
//查询数据数据
for (int j = 0; j < ((finalI < sheetNum -1) ? queryNum : lastQueryNum); j++) {
//查询数据库
int page = j+1+finalI * sheetDataNum;
int pageSize = readNum;
//TODO 调用数据库查询
//TODO 写excel
}
}
};
}模拟代码
数据库创建一个公众号用户表
bash
-- 创建一个缓存openid的数据库
drop table if exists mp_user;
create table mp_user(
id bigint not null auto_increment comment 'ID',
openid varchar(64) not null comment 'openid',
deleted bit(1) NOT NULL DEFAULT b'0' COMMENT '是否删除',
primary key (`id`) using btree
) engine = innodb default charset=utf8mb4 comment '公众号粉丝';引入maven依赖
bash
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>easyexcel</artifactId>
<version>3.3.3</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>application配置数据库
bash
spring:
datasource:
url: jdbc:mysql://localhost:3306/cce-demo?serverTimezone=GMT%2B8&autoReconnect=false&useUnicode=true&characterEncoding=UTF-8&characterSetResults=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=true
username: root
password: 12345678
driver-class-name: com.mysql.cj.jdbc.Driver
# MyBatis Plus 的配置项
mybatis-plus:
configuration:
map-underscore-to-camel-case: true # 虽然默认为 true ,但是还是显示去指定下。
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl #开启sql日志
global-config:
db-config:
id-type: NONE
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)
banner: false # 关闭控制台的 Banner 打印
type-aliases-package: com.example.ccedemo.entity
mapper-locations: classpath:/mapper/*.xml MpUser实体和excel类
bash
/**
* MpUser
* @author senfel
* @version 1.0
* @date 2024/7/1 16:17
*/
@TableName("mp_user")
@KeySequence("mp_user_seq")
@Data
@ToString(callSuper = true)
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class MpUser implements Serializable {
@TableId
private Long id;
/**
* openid
*/
private String openid;
private Boolean deleted;
}
bash
/**
* openId Excel 导入 VO
* @author senfel
*/
@Data
@Builder
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = false)
public class OpenIdImportExcelVo {
/**
* 用户OpenId
*/
@ExcelProperty(index = 0)
private String openid;
}
MpUserMapper
/**
* MpUserMapper
* @author senfel
* @version 1.0
* @date 2024/7/1 16:23
*/
@Mapper
public interface MpUserMapper extends BaseMapper<MpUser> {
/**
* insertBatch
* @param list
* @author senfel
* @date 2024/7/1 17:16
* @return int
*/
int insertBatch(List<OpenIdImportExcelVo> list);
/**
* selectDataByPage
* @param offset
* @param size
* @author senfel
* @date 2024/7/1 17:16
* @return java.util.List<java.lang.String>
*/
List<OpenIdImportExcelVo> selectDataByPage(int offset, int size);
}MpUserMapper.xml
bash
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.example.ccedemo.mapper.MpUserMapper">
<!--批量新增openid-->
<insert id="insertBatch" parameterType="com.example.ccedemo.excel.OpenIdImportExcelVo">
insert into mp_user (openid) values
<foreach collection="list" item="item" separator=",">
(#{item.openid})
</foreach>
</insert>
<!--查询分页数据-->
<select id="selectDataByPage" parameterType="map" resultType="com.example.ccedemo.excel.OpenIdImportExcelVo">
select openid from mp_user
limit #{offset},#{size}
</select>
</mapper>提供测试类
bash
/**
* EasyExcelTest
* @author senfel
* @version 1.0
* @date 2024/7/1 16:03
*/
@SpringBootTest
public class EasyExcelTest {
@Resource
private MpUserMapper mpUserMapper;
/**
* readExcel
* @author senfel
* @date 2024/7/1 17:17
* @return void
*/
@Test
public void readExcel(){
//800w+的csv文件,每批次读取10000条
long startTime = System.currentTimeMillis();
System.err.println("readExcel开始执行时间:"+startTime);
String filePath = "D:\\blank\\工作簿1.csv";
EasyExcel.read(filePath, OpenIdImportExcelVo.class, new PageReadListener<OpenIdImportExcelVo>(dataList ->{
if(!CollectionUtils.isEmpty(dataList)){
//数据存储
mpUserMapper.insertBatch(dataList);
}
}, 10000)).sheet().doRead();
System.err.println("readExcel结束执行时间:"+(System.currentTimeMillis()-startTime));
}
/**
* exportExcel
* @author senfel
* @date 2024/7/1 17:19
* @return void
*/
@Test
public void exportExcel(){
long startTime = System.currentTimeMillis();
System.err.println("exportExcel:"+startTime);
String excelName = "测试导出openid";
String exportPath = "D:\\blank\\";
boolean isRun = true;
int size = 20 * 10000;
int page = 0;
int sheetDataSize = 0;
int sheetNo = 0;
FileOutputStream outputStream = null;
try {
outputStream = new FileOutputStream(exportPath + excelName + ".xlsx");
ExcelWriter excelWriter = EasyExcel.write(outputStream).build();
do {
page++;
List<OpenIdImportExcelVo> openList = mpUserMapper.selectDataByPage((page - 1) * size, size);
if(CollectionUtils.isEmpty(openList)){
isRun = false;
break;
}
sheetDataSize += openList.size();
if(sheetDataSize > 1000000){
sheetNo++;
sheetDataSize = openList.size();
}
//写入文件流
WriteSheet writeSheet = EasyExcel.writerSheet(sheetNo, "openid"+sheetNo).head(OpenIdImportExcelVo.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()).build();
excelWriter.write(openList, writeSheet);
}while (isRun);
excelWriter.finish();
outputStream.flush();
}catch (IOException e){
e.printStackTrace();
}finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.err.println("exportExcel结束执行时间:"+(System.currentTimeMillis()-startTime));
}
}
}测试结果
导入结果
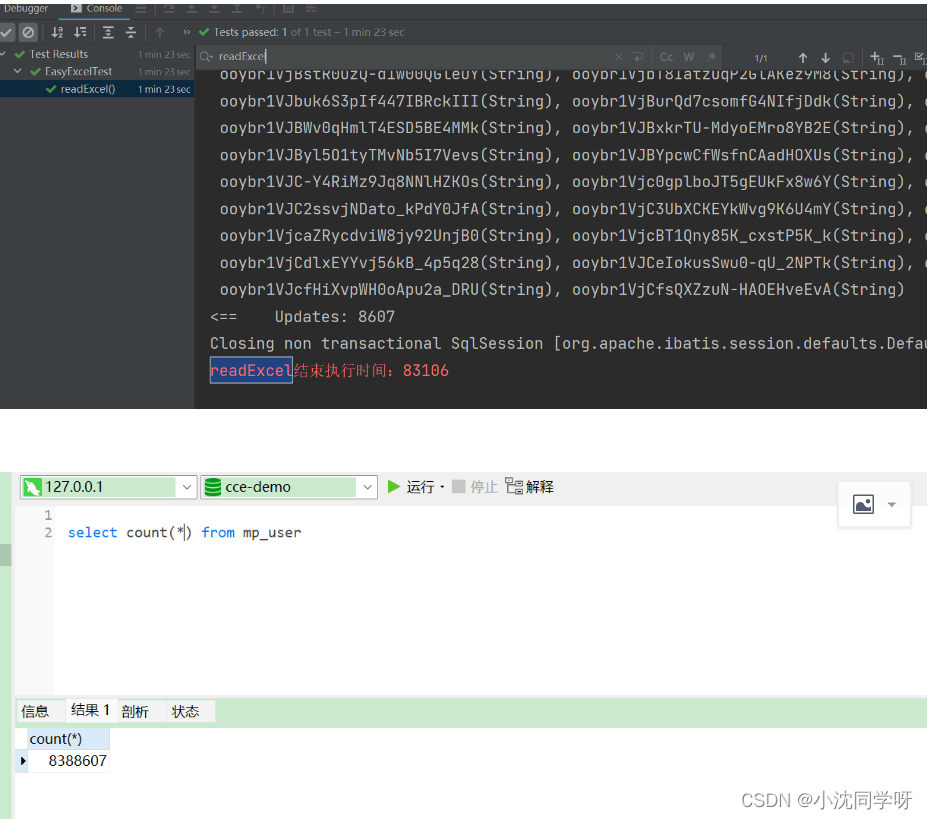
83s导入存入数据库 838w数据,如果改为原生的JDBC操作入库会更快。
导出结果
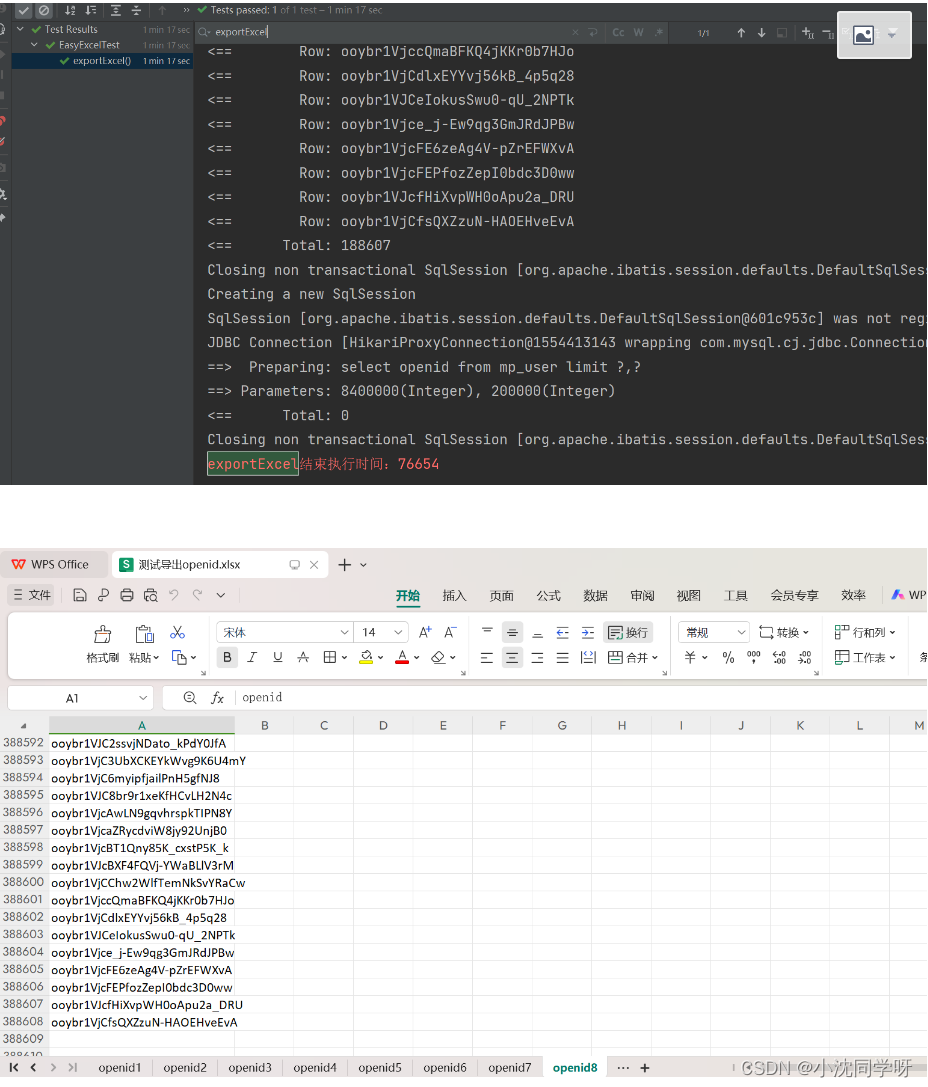
77s导出写入excel 838w数据,写excel不建议多线程。如果受到内存限制查询条数低于20w可以考虑多线程执行,但是写excel必须单线程。
如果需要导出到响应头HttpServletResponse
bash
public void exportExcel2(HttpServletResponse response){
long startTime = System.currentTimeMillis();
String excelName = "测试导出openid";
boolean isRun = true;
int size = 20 * 10000;
int page = 0;
int sheetDataSize = 0;
int sheetNo = 0;
OutputStream outputStream = null;
try {
outputStream = response.getOutputStream();
ExcelWriter excelWriter = EasyExcel.write(outputStream).build();
do {
page++;
List<OpenIdImportExcelVo> openList = mpUserMapper.selectDataByPage((page - 1) * size, size);
if(CollectionUtils.isEmpty(openList)){
isRun = false;
break;
}
sheetDataSize += openList.size();
if(sheetDataSize > 1000000){
sheetNo++;
sheetDataSize = openList.size();
}
//写入文件流
WriteSheet writeSheet = EasyExcel.writerSheet(sheetNo, "openid"+sheetNo).head(OpenIdImportExcelVo.class)
.registerWriteHandler(new LongestMatchColumnWidthStyleStrategy()).build();
excelWriter.write(openList, writeSheet);
}while (isRun);
// 下载EXCEL
response.setContentType("application/vnd.openxmlformats-officedocument.spreadsheetml.sheet");
response.setCharacterEncoding("utf-8");
String fileName = URLEncoder.encode(excelName, "UTF-8").replaceAll("\\+", "%20");
response.setHeader("Content-disposition", "attachment;filename*=" + fileName + ".xlsx");
excelWriter.finish();
outputStream.flush();
}catch (IOException e){
e.printStackTrace();
throw new RuntimeException("exportExcel异常,具体信息为:"+e.getMessage());
}finally {
if (outputStream != null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.err.println("exportExcel结束执行时间:"+(System.currentTimeMillis()-startTime));
}
}