7月2日,++系统之家++发布消息,月之暗面科技有限公司旗下的Kimi开放平台正式推出上下文缓存功能,并已开放公测。这项功能专为处理频繁请求和大量重复引用初始上下文的场景设计,能有效降低使用长文本模型的成本,并显著提升处理效率。据官方数据显示,上下文缓存功能可以将费用降低至最高90%,同时将首次Token的延迟时间缩短83%,从而加快模型的响应速度。

** 系统之家附 Kimi 开放平台上下文缓存功能公测详情如下:**
技术简介
据介绍,上下文缓存是一种数据管理技术,允许系统预先存储会被频繁请求的大量数据或信息。当用户请求相同信息时,系统可以直接从缓存中提供,无需重新计算或从原始数据源中检索。

适用场景
适用业务场景如下:
提供大量预设内容的 QA Bot,例如 Kimi API 小助手
针对固定的文档集合的频繁查询,例如上市公司信息披露问答工具
对静态代码库或知识库的周期性分析,例如各类 Copilot Agent
瞬时流量巨大的爆款 AI 应用,例如哄哄模拟器,LLM Riddles
交互规则复杂的 Agent 类应用等


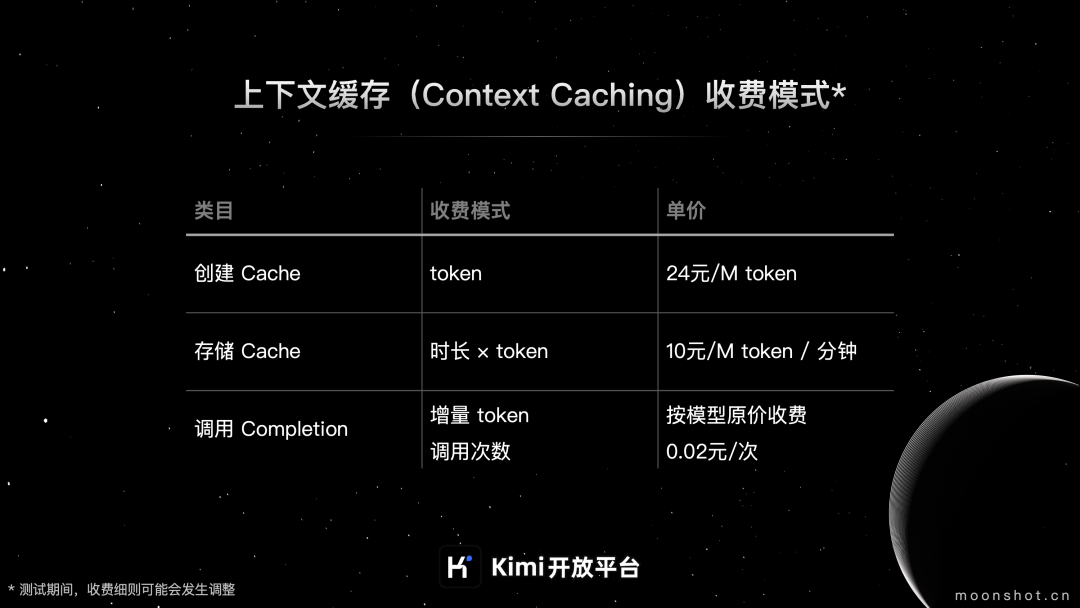
** 计费说明**
上下文缓存收费模式主要分为以下三个部分:
** Cache 创建费用**
调用 Cache 创建接口,成功创建 Cache 后,按照 Cache 中 Tokens 按实际量计费。24 元 / M token
** Cache 存储费用**
Cache 存活时间内,按分钟收取 Cache 存储费用。10 元 / M token / 分钟
** Cache 调用费用**
Cache 调用增量 token 的收费:按模型原价收费
Cache 调用次数收费:Cache 存活时间内,用户通过 chat 接口请求已创建成功的 Cache,若 chat message 内容与存活中的 Cache 匹配成功,将按调用次数收取 Cache 调用费用。0.02 元 / 次
公测时间和资格说明
公测时间:功能上线后,公测 3 个月,公测期价格可能随时调整。
公测资格:公测期间 Context Caching 功能优先开放给 Tier5 等级用户,其他用户范围放开时间待定。
以上是系统之家提供的最新资讯,感谢您的阅读,更多精彩内容请关注系统之家官网。