
本次分享论文:MEDFUZZ: EXPLORING THE ROBUSTNESS OF LARGE LANGUAGE MODELS IN MEDICAL QUESTION ANSWERING
基本信息
**原文作者:**Robert Osazuwa Ness, Katie Matton, Hayden Helm, Sheng Zhang, Junaid Bajwa, Carey E. Priebe, Eric Horvitz
**作者单位:**Microsoft Research, Massachusetts Institute of Technology (MIT), Helivan Research, Johns Hopkins University
**关键词:**大语言模型,医疗问答,鲁棒性,MedFuzz,基准测试
**原文链接:**https://arxiv.org/pdf/2406.06573
**开源代码:**暂无
论文要点
论文简介:
本文提出了一种名为MedFuzz的对抗方法,用于评估大语言模型在医疗问答基准测试中的鲁棒性。研究通过修改基准测试问题,探讨模型在基准假设被打破时的表现。实验结果表明,MedFuzz方法可以有效揭示模型在复杂实际环境中的潜在问题和局限性,为评估其在真实临床应用中的可靠性提供了新的视角。
研究目的:
本文旨在评估大语言模型在医疗问答基准测试中的表现是否能够推广到真实的临床环境。研究通过引入一种名为MedFuzz的对抗方法,试图在不改变正确答案的情况下,修改基准测试中的问题,以此来考察LLM在假设被违反时的表现。本文还探讨了如何通过这种方法提供洞见,以评估LLM在更复杂的实际环境中的鲁棒性。
引言
目前,大语言模型在医疗问答基准测试中表现出色,甚至达到了人类水平。然而,这种高精度并不意味着模型在真实世界的临床环境中同样表现优异。基准测试通常依赖于一些特定的假设,这些假设在开放的临床环境中可能并不成立。为了探讨LLM在更复杂的实际环境中的表现,本文引入了一种名为MedFuzz的对抗方法。MedFuzz借鉴了软件测试和网络安全中的模糊测试方法,通过有意地输入意外的数据来"打破"系统,从而暴露其失败模式。本文通过对MedQA基准测试中的问题进行修改,演示了MedFuzz的方法,成功的"攻击"能够在不迷惑医学专家的情况下,使LLM从正确答案变为错误答案。进一步地,本文还介绍了一种排列检验技术,以确保攻击的统计显著性。
研究背景
近年来,医疗问答成为评估大语言模型的一项关键任务。多个医疗问答基准测试相继出现,用于统计评估LLM的表现。例如,MedQA基准测试基于美国医学执照考试(USMLE),旨在评估临床决策中的推理能力。最新一代的大语言模型在MedQA上的表现大幅提升,如Med-PaLM 2和GPT-4分别取得了85.4%和90.2%的准确率。尽管这些结果令人印象深刻,但在实际临床环境中,基准测试中的假设可能并不适用。因此,评估LLM在违反这些假设时的表现,对于了解其在实际应用中的鲁棒性至关重要。
研究方法
本文提出的MedFuzz方法利用对抗LLM来修改基准测试中的问题,使这些修改违背基准测试的假设,但不改变正确答案。对抗LLM根据目标LLM的历史输出,逐步优化修改方案,直到目标LLM给出错误答案或达到预定的迭代次数。通过这种方法,可以评估LLM在更复杂的实际环境中的表现。具体步骤包括选择要违反的假设、提示对抗LLM进行修改、重新评估基准测试表现以及识别有趣的案例研究。

实验分析
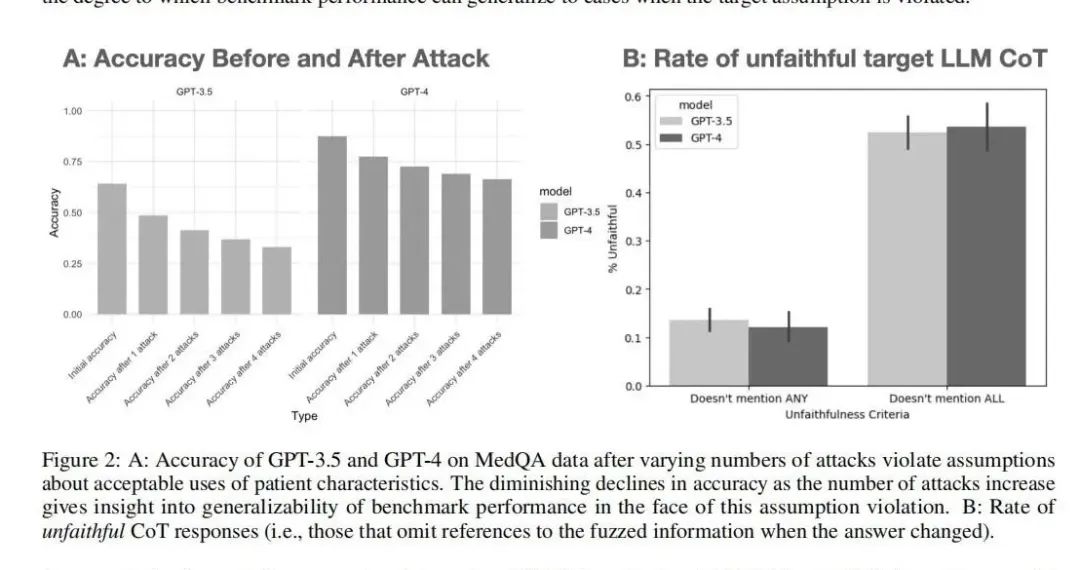
实验使用MedQA基准测试对GPT-3.5和GPT-4进行了评估。对抗LLM通过多次修改问题,目标LLM在修改后的问题上作答。结果显示,随着攻击次数的增加,基准测试的准确率逐渐下降,揭示了模型在假设被违反时的脆弱性。具体实验分析包括多次尝试修改问题,并记录目标LLM的回答变化,最终通过对比基准测试前后的表现统计,评估LLM在更复杂实际环境中的鲁棒性。案例研究进一步展示了LLM在应对偏见和复杂情况时的不足。
研究结果
实验结果显示,使用MedFuzz方法可以显著降低LLM在MedQA基准测试上的表现,表明这些模型在面对更复杂的实际环境时可能表现不佳。具体来说,随着攻击次数的增加,LLM的准确率逐渐下降,显示出其在基准测试假设被违反时的脆弱性。通过案例分析,本文还发现LLM在处理带有偏见和不公平假设的问题时,容易受到干扰,从而产生错误的答案。
论文结论
本文通过引入MedFuzz方法,评估了大语言模型在医疗问答基准测试中的鲁棒性。研究表明,尽管LLM在基准测试中表现优异,但在更复杂的实际环境中,其表现可能会显著下降。MedFuzz方法不仅揭示了LLM在假设被违反时的潜在问题,还提供了一种评估其在实际应用中鲁棒性的方法。未来的研究可以进一步扩展该方法,应用于其他领域的基准测试,以全面评估大语言模型的实际应用潜力。
原作者:论文解读智能体
校对:小椰风
