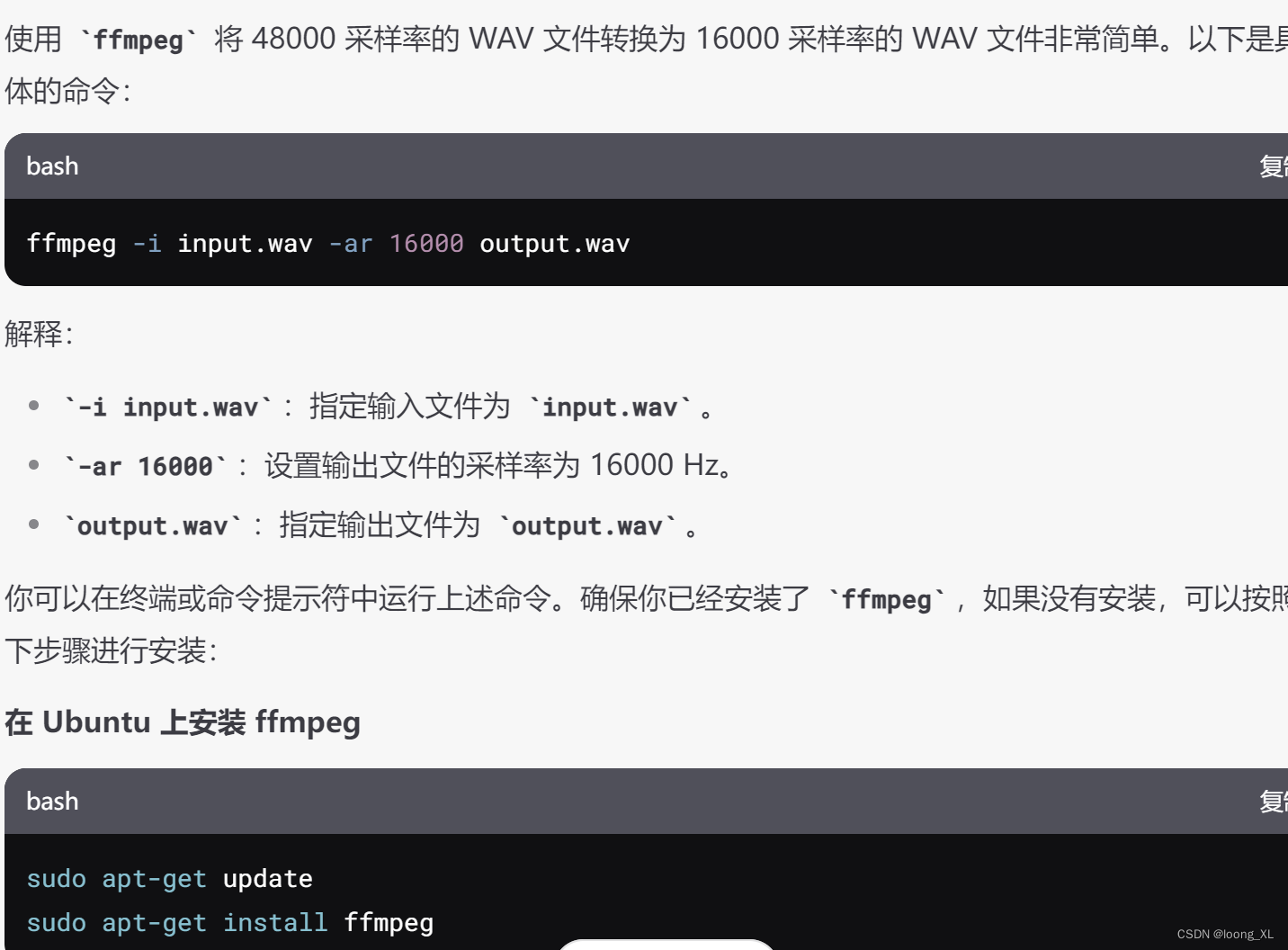
快速查看音频通道数和每个通道能力判断具体哪个通道说话;一般能量大的那个算是说话
bash
import wave
from pydub import AudioSegment
import numpy as np
def read_wav_file(file_path):
with wave.open(file_path, 'rb') as wav_file:
params = wav_file.getparams()
num_channels = params.nchannels
sample_width = params.sampwidth
frame_rate = params.framerate
num_frames = params.nframes
print(f"Number of channels: {num_channels}")
print(f"Sample width: {sample_width}")
print(f"Frame rate: {frame_rate}")
print(f"Number of frames: {num_frames}")
frames = wav_file.readframes(num_frames)
audio_data = np.frombuffer(frames, dtype=np.int16)
if num_channels > 1:
audio_data = audio_data.reshape(-1, num_channels)
return audio_data, frame_rate, num_channels
def analyze_channels(audio_data, frame_rate, num_channels):
for channel in range(num_channels):
channel_data = audio_data[:, channel] if num_channels > 1 else audio_data
# 计算通道的能量
energy = np.sum(np.abs(channel_data))
print(f"Channel {channel} energy: {energy}")
# 你可以在这里添加更多的分析逻辑,比如使用语音活动检测(VAD)来判断说话声
if __name__ == "__main__":
file_path = r"E:\allchat\output.wav"
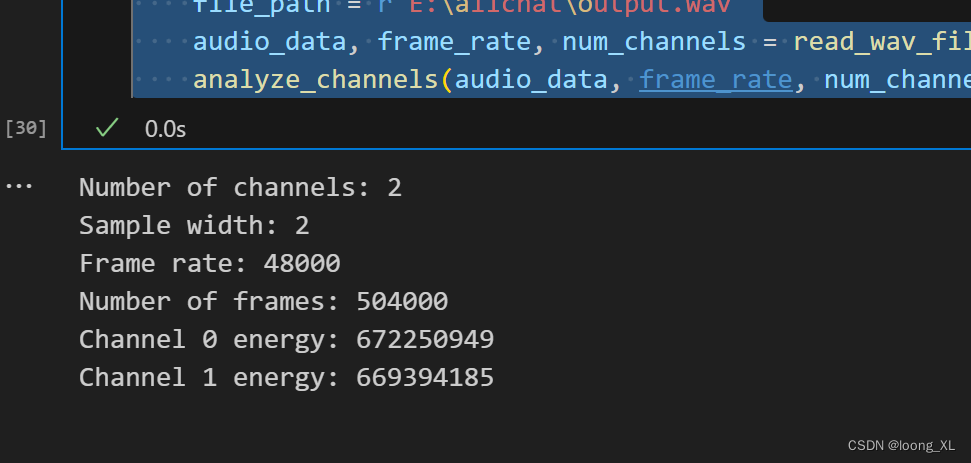
audio_data, frame_rate, num_channels = read_wav_file(file_path)
analyze_channels(audio_data, frame_rate, num_channels)这里 channel0 的声音算说话的
1、转换mono单声道,选择人声的那个通道
mp3格式
bash
from pydub import AudioSegment
def extract_and_save_channel(input_file, output_file, channel_index):
# 读取 MP3 文件
audio = AudioSegment.from_mp3(input_file)
# 提取特定通道
if audio.channels > 1:
channel_data = audio.split_to_mono()[channel_index]
else:
channel_data = audio
# 保存提取的通道为新的 MP3 文件
channel_data.export(output_file, format="mp3")
if __name__ == "__main__":
input_file = "your_audio_file.mp3"
output_file = "channel_0.mp3"
channel_index = 0 # 选择 Channel 0
extract_and_save_channel(input_file, output_file, channel_index)wav格式
bash
from pydub import AudioSegment
# 加载WAV文件
wav_file_path = r"E:\allchat\output_16000.wav"
audio_segment = AudioSegment.from_wav(wav_file_path)
# 提取Channel 0
if audio_segment.channels > 1:
channel_0 = audio_segment.split_to_mono()[0]
else:
channel_0 = audio_segment
# 导出为单声道WAV文件
mono_wav_file_path = r"E:\allchat\output_16000_channel_0.wav"
channel_0.export(mono_wav_file_path, format="wav")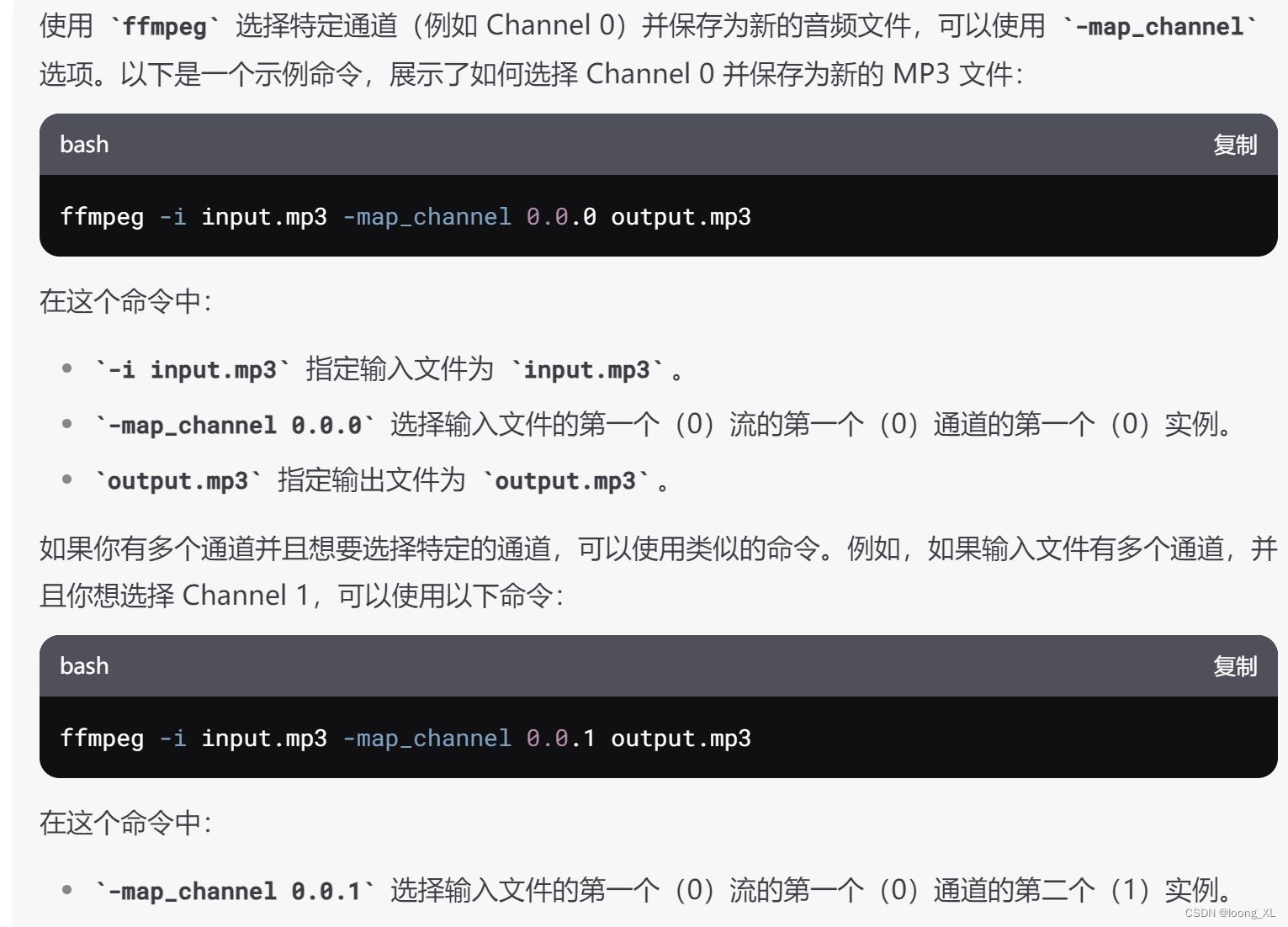
2、采样率更改为16000
bash
from pydub import AudioSegment
def resample_wav_with_pydub(input_file, output_file, new_rate):
# 读取原始WAV文件
audio = AudioSegment.from_wav(input_file)
# 设置新的采样率
audio = audio.set_frame_rate(new_rate)
# 导出重采样后的WAV文件
audio.export(output_file, format='wav')
# 使用示例
resample_wav_with_pydub('input.wav', 'output_16000.wav', 16000)