
文章目录
- 前言
- 什么是分布式锁
- 分布式锁的基本实现
-
- 引入过期时间
- [引入校验 id](#引入校验 id)
- [引入 lua 脚本](#引入 lua 脚本)
- [引入 watch dog(看门狗)](#引入 watch dog(看门狗))
- [引入 Redlock 算法](#引入 Redlock 算法)
前言
在使用 redis 作为中间件的时候,如果使用单机部署的话,如果这个机器故障的话,那么整个的服务都会受到影响,所以为了避免单机问题,我们的 redis 通常都是部署在多个主机上的,也就是分布式系统。既然是分布式系统,也就不可避免的出现类似多线程上的线程安全问题,分布式系统也会因为多个节点访问同一个公共资源的顺序随机而出现问题,为了避免分布式出现的访问公共资源出现的问题,通过前面多线程使用的加锁的问题是无法解决的,因为多线程中的加锁解决的是同一个进程中的多个线程的问题,而我们这里的分布式则是在多个主机上,显然不属于同一个进程,那么如何解决分布式中出现的问题呢?那就是我们这篇文章要说的------分布式锁。
什么是分布式锁
在一个分布式系统中,不可避免的会出现多个节点访问同一个公共资源的问题,因为节点的访问顺序不同,所以就可能出现不可预期的问题,那么为了解决这种类似"线程不安全"的问题,就需要依赖于分布式锁来做互斥控制。
分布式锁本质上就是使用一个公共的服务器来记录加锁的状态,当有节点需要访问公共资源的时候,首先就需要判断这个资源是否被其他节点加锁了,如果没有,那么该节点就会访问这个公共资源并且对这个资源进行加锁操作,如果这个公共资源被其他节点加锁之后,那么该节点就会选择进行阻塞等待还是放弃访问这个资源。
这个公共的服务器可以是 redis,也可以是其他组件(比如 MySQL 或者 Zookeeper等),还可以是我们自己写的一个服务。
分布式锁的基本实现
分布式锁的实现思路是很简单的,就是通过一个键值对来表示锁的状态。给大家举个例子:
大家肯定都买过限量发售的东西吧,就是一个东西出售的数量是有限的,最多只卖 n 个,那么这个东西在发售的瞬间肯定会有很多的人抢着去买,也就是同一时间有大量的客户端去访问一个数据库:

不同的请求就会经过负载均衡器的计算给分配到不同的服务器中,不同的不服气访问同一个数据库,服务器处理请求的时候首先会先查询商品的数量,如果商品的数量大于等于1的话,就会生成订单信息,然后该商品的数量减去1,但是因为这个查询和修改的操作不具有原子性,所以这这两个操作中间就会穿插其他服务器的操作:
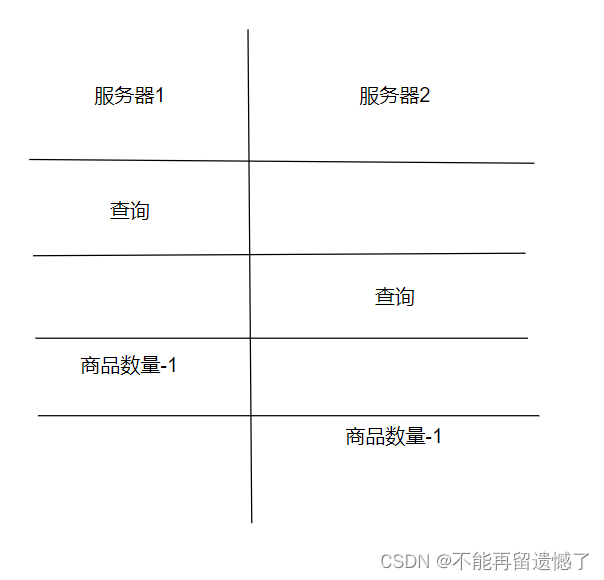
假设服务器1查询的商品的数量为1,1 >= 1,然后服务器2查询的商品的数量也是 1,1 >= 1,然后服务器1生成一份订单,服务器2也生成一份订单,也就是说订单的数量是多于出售的商品的数量的,这样就发生了超卖的问题。
为了解决这个问题,就引入了 redis 服务器作为分布式锁的管理器:

假设是服务器1先向数据库发起的访问数据请求,在访问数据库之前,会先去 redis 服务器中查看数据库资源是否被加锁了,因为是第一个访问数据库的,所以就没有其他节点对其进行加锁,那么服务器1就可以正常访问数据库资源,并且为了避免其他服务器同时也访问并且修改数据库中的数据,服务器1就会在 redis 分布式锁管理器中设置一个key-value,key 可以是商品的编号,然后 value 就是服务器1的编号,然后当服务器2要访问数据库资源的时候,也是会先访问 redis 分布式锁管理器,查看 001 这个 key 是否存在,此时 001 这个 key 是存在的,所以服务器2就会选择进入阻塞等待还是放弃访问这个资源,这样就保证了一个节点在访问和修改数据库的数据的时候不会被其他节点的操作影响。
当服务器 1 的访问操作结束的时候,就会进行"解锁"操作,在 redis 中就可以直接将这个 key 删除,删除这个 key 的时候,其他节点要访问的时候该 key 就不存在了,那么其他节点就可以正常访问了。
这个加锁的操作正好跟 redis 中的 setnx 的命令操作是类似的,当设置的 key 不存在的时候才设置成功,如果 key 存在那么就会报错。但是有一个问题:就是如果服务器1在 redis 中对资源进行加锁之后,突然这个服务器挂掉了,也就是该服务器没有对其进行解锁操作,那么其他服务器在访问这个数据的时候,就会一直读取不到,那么这个问题该如何解决呢?
引入过期时间
在加锁的时候,也就是设置键值对的时候,为这个锁(键值对)设置过期时间,当达到指定的时间之后,这个 key 就会自动删除,这样就算加锁的服务器没有正常解锁,也不会影响其他服务器的正常操作。
在 redis 中可以使用 set ex nx 的方式保证只有当 key 不存在的时候才设置 key-value 成功,并且指定过期时间。那么只有这一种方式吗?在 redis 中不是可以先使用 setnx 设置 key-value,然后再使用 expire 为存在的 key 设置过期时间吗?在 redis 中确实如此,但是该方式在分布式锁中是非常不建议使用的,分布式锁设置键值对应尽量保证一个命令就可以实现。为什么呢?同样是"线程不安全"问题,因为 setnx 和 expire 两个命令不是原子性的操作,并且 redis 事务本身不支持回滚操作,这样就可能出现 expire 设置过期时间失败的问题出现,所以应使用 set ex nx 来设置键值对。
设置过期时间,那么过期时间设置多少才合适呢?过期时间设置太短,一个节点的操作还没解锁,锁就被释放了,那么就无法达到分布式锁的作用,但是如果过期时间设置的太长的话,又会导致其他节点无法及时访问资源的问题出现。这个问题文章的后面再为大家介绍。
接下来我们来思考一下下面的问题:加锁就是在 redis 分布式管理锁系统中设置键值对,解锁就是删除键值对的操作,那么是否会出现一个问题就是,当一个节点加锁之后,这个锁被其他节点解锁了的情况了呢?这种情况是可能出现的,如果一个节点内部出现了故障,导致错误的解开了其他节点加的锁的的话,分布式锁的目的就无法达到了,那么如何解决这个问题呢?
引入校验 id
我们在加锁设置键值对的时候,设置的 value 的值不再是简单的 value,而是设置为加锁的节点的服务器的编号,例如"001",这样当在进行解锁删除键值对的操作的时候,会根据 key 中 value 值表示的服务器的编号,然后跟进行解锁操作的服务器的编号进行比较,如果相等则可以解锁,不相等,则不能解锁:
java
String key = [要加锁的资源 id];
String serverId = [服务器的编号];
// 加锁, 设置过期时间为 10s
redis.set(key, serverId, "NX", "EX", "10s");
// 执⾏各种业务逻辑, ⽐如修改数据库数据.
doSomeThing();
// 解锁, 删除 key. 但是删除前要检验下 serverId 是否匹配.
if (redis.get(key) == serverId) {
redis.del(key);
}这样虽然可以解决锁被其他服务器错误解锁的问题,但是又会出现新的问题,这里的 get 和 del 操作也是非原子的操作,在这两个操作执行期间也是可能出现问题的:

假设一个服务器中的多个线程同时执行解锁操作,服务器1中的线程 A 先执行 GET 操作,然后服务器1中的线程B再执行 GET 操作,因为这个锁就是服务器1加的,所以 GET 比较之后的结果就是可以进行 DEL 操作,然后线程 A 执行 DEL 操作,在线程 B 执行 DEL 操作之前,服务器2上的线程 C 又执行了 set ex nx 加锁操作对相同的资源进行了加锁,也就是 key 相同,然后服务器1的线程 B 再执行 DEL 操作,因为之前的比较得到的结果是可以进行解锁操作,所以就导致其他服务器加的锁被其他服务器解锁了。
所以这个问题如何解决呢?这个问题虽然可以用事务来保证一个服务器上的命令执行之间不会插入其他服务器的命令,但是实际中更好的解决方案是引入 lua 脚本。
引入 lua 脚本
Lua是一种轻量级、可嵌入的脚本语言,设计目标是通过简单、紧凑、可扩展的方式支持通用过程式编程。它经常被用于游戏开发、Web应用程序、扩展和配置、机器人控制、系统监控和管理、以及许多其他需要灵活性和高效性的领域。
lua可以作为 redis 的内嵌脚本,事务可以完成的事情,使用 lua 脚本也基本可以实现,可以使用 lua 编写一些逻辑,然后将这个逻辑上传到 redis 服务器中,这样就可以使用客户端来控制 redis 执行上述脚本了。redis 执行 lua 脚本的过程就相当于执行一条命令的过程,也可以说 lua 脚本中的所有命令具有原子性。
lua
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;这个代码可以编写成一个 .lua 后缀的文件,由 redis-cli 或者 redis-plus-plus 或者 jedis 等客户端加载,并发送给 redis 服务器,由 redis 服务器来执行这段逻辑。
当使用 lua 脚本解决上述问题之后,我们再来看看如何解决上面的 key 过期时间的设置问题。
引入 watch dog(看门狗)
相比于设置一个可能不合适的固定的过期时间,不如动态的调整时间更合适,所谓的看门狗本质上就是加锁的服务器上的一个单独的线程,通过这个线程来对锁的过期时间进行"续约"。
假设初始的过期时间设置的是 10s,同时设定看门狗线程每隔 3s 检测一次。那么当 3s 时间到的时候,看门狗就会判断当前任务是否完成:
- 如果任务已经完成,则直接通过 lua 脚本的方式,释放锁
- 如果任务未完成,则把过期时间重写设置为 10s,既续约
通过看门狗这样的机制,就不会因为 key 过期时间设置的不合理而导致提前解锁问题以及过期时间过长其他服务器无法及时拿到资源的问题。并且另一个方面,如果服务器挂了,看门狗线程自然业绩挂了,那么也就无法自动续约,这个 key 到了指定的时间就会自动删除了。
使用 redis 作为分布式锁的管理器,那么如果这个 redis 服务器挂了该怎么办呢?
我们可以使用多个 redis 节点,使得这些节点构成主从的关系,并且引入哨兵机制,当主节点挂了之后,就会由哨兵选出一个从节点作为新的主节点,但是因为主从复制的过程中需要点时间,如果服务器在加锁的过程中,先在 master 节点中设置键值对,当 master 设置完成之后,master 节点挂掉了,那么就算从节点成为了新的主节点,这个新加的锁也是无法记录的,所以就出现了 Redlock 算法。
引入 Redlock 算法
我们引入一组 redis 节点,其中每一组 redis 节点都包含一个主节点和若干从节点,每一组的节点中存储的数据都是全量数据,在加锁的时候,会按照一定的顺序,将加锁的信息写入多个 master 节点,并且在写锁的时候设置"超时时间",如果某个 master 的写锁执行时间超过了指定的时间,就认为加锁失败,然后所有 master 都尝试加锁之后,枷锁成功的节点的个数超过所有 master 节点个数的一半的时候就认为加锁成功,解锁的时候也是同样的操作:

简而言之,Redlock 算法的核心就是,加锁操作不能只写给一个 redis 节点,而是要写多个,分布式系统的任何一个节点都是不可靠的,最终加锁成功的结论是"少数服从多数"。