目录
[一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务](#一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务)
[1. 统计 2011-12-30 日搜索记录,每个时间段的搜索次数](#1. 统计 2011-12-30 日搜索记录,每个时间段的搜索次数)
[(2) 源代码](#(2) 源代码)
[2. 统计 2011-12-30 日 3 点至 4 点之间,哪些 UID 访问了搜狗引擎。](#2. 统计 2011-12-30 日 3 点至 4 点之间,哪些 UID 访问了搜狗引擎。)
[二、有两个输入文件 A 和 B,使用 MapReduce 编程合并文件,得到输出文件 C](#二、有两个输入文件 A 和 B,使用 MapReduce 编程合并文件,得到输出文件 C)
[1. 输入文件A和B如下](#1. 输入文件A和B如下)
[2. 通过MapReduce编程合并文件得到outputC](#2. 通过MapReduce编程合并文件得到outputC)
[3. 源代码](#3. 源代码)
一、对于 sogou_500w_utf 数据,使用 MapReduce 编程模型完成对以下数据的分析任务
1. 统计 2011-12-30 日搜索记录,每个时间段的搜索次数
(每小时为一个单位,比如 0 点钟多少次,1 点钟多少次,2 点钟多少次,一直到 23 点多少次)
(1)运行截图
bash
hadoop jar /home/2130502441ryx/SearchCountJob.jar org/ryx/SearchCountJob /sogou.500.utf8 /output5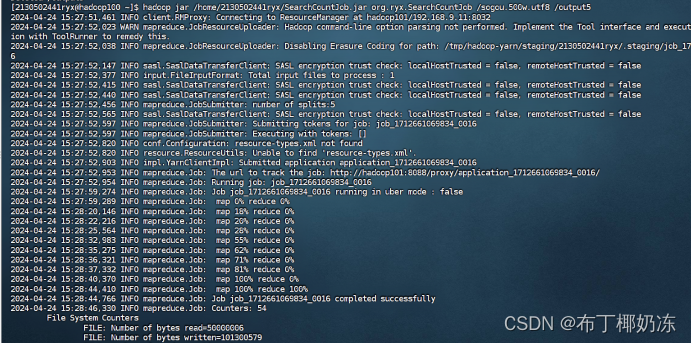
bash
hdfs dfs -ls /output5
hdfs dfs -cat /output5/part-r-00000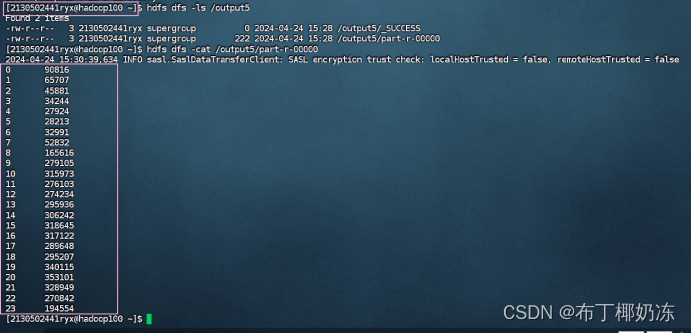
(2) 源代码
① SearchCountMapper

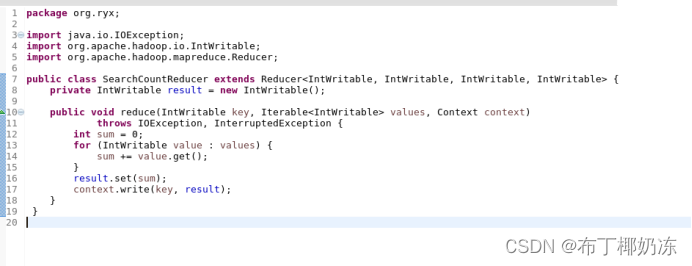
② SearchCountReduct
③ SearchCountJob
2. 统计 2011-12-30 日 3 点至 4 点之间,哪些 UID 访问了搜狗引擎。
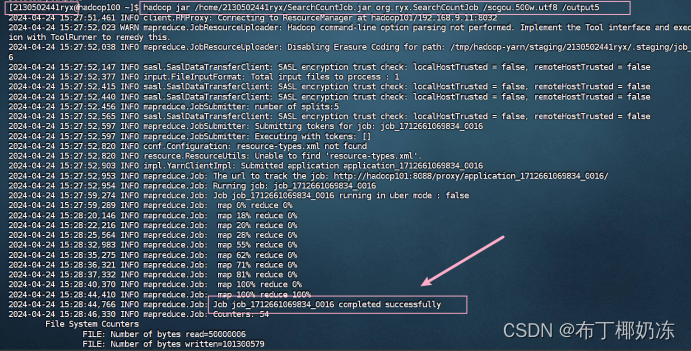
(1)运行截图
bash
hadoop jar /home/2130502441ryx/UIDCountJob.jar org/ryx/SogouDriver /sogou.500.utf8 /output7(下面截图贴错了,上面的运行命令才是正确的)
bash
hdfs dfs -ls /output7
hdfs dfs -cat /output7/part-r-00000
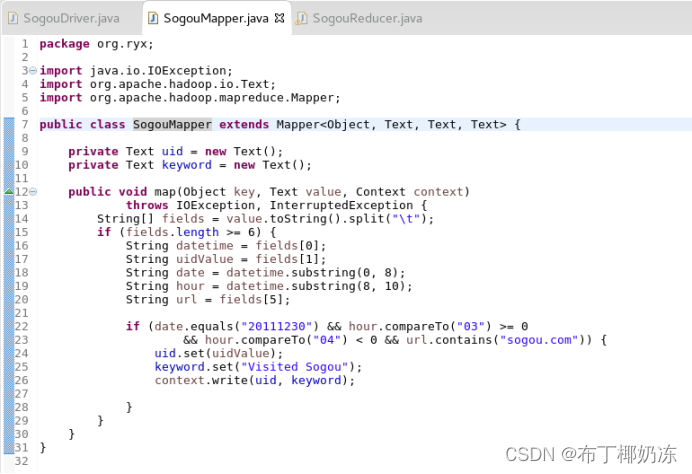
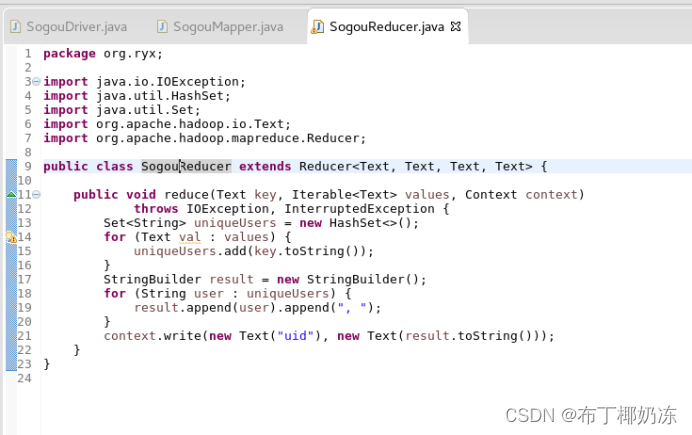
(2)源代码
SogouMapper.java
SogouReducer.java
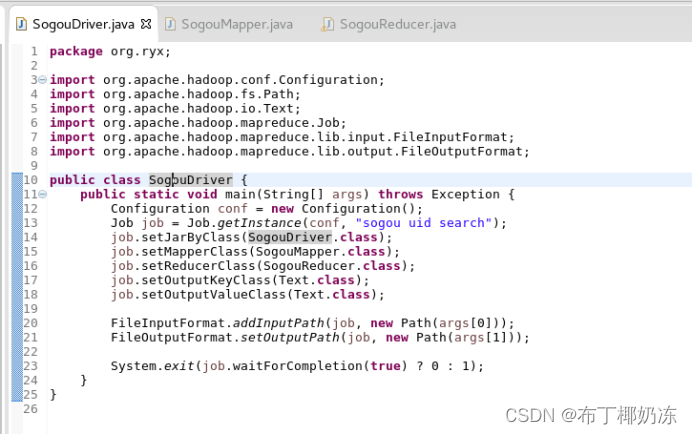
SogouDriver.java
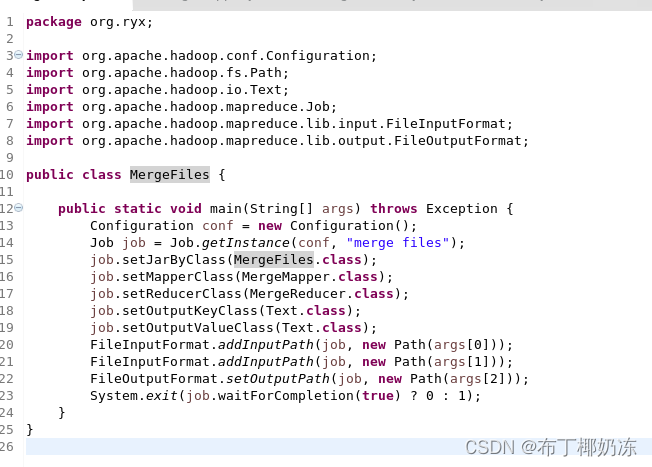
二、有两个输入文件 A 和 B,使用 MapReduce 编程 合并文件 ,得到 输出文件 C
输入文件 A 的样例如下:
20150101 x
20150102 y
20150103 x
20150104 y
20150105 z
20150106 x
输入文件 B 的样例如下:
20150101 y
20150102 y
20150103 x
20150104 z
20150105 y
根据输入文件 A 和 B 合并得到的输出文件 C 的样例如下:
20150101 x
20150101 y
20150102 y
20150103 x
20150104 y
20150104 z
20150105 y
20150105 z
20150106 x
1. 输入文件A和B如下
bash
hdfs dfs -cat /inputA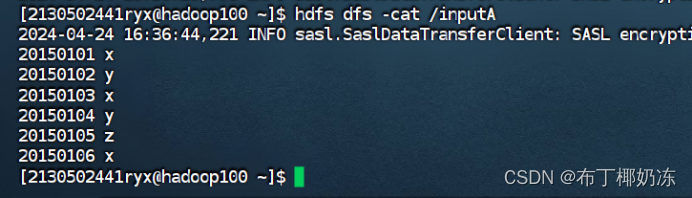
bash
hdfs dfs -cat /inputB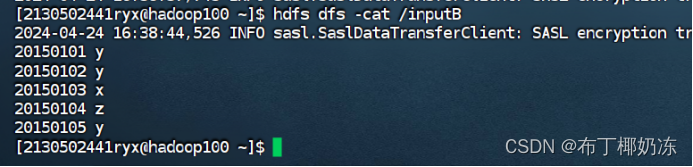
2. 通过MapReduce编程合并文件得到outputC
bash
hadoop jar /home/2130502441ryx/MergeFiles.jar org/ryx/MergeFiles /inputA /inputB /outputC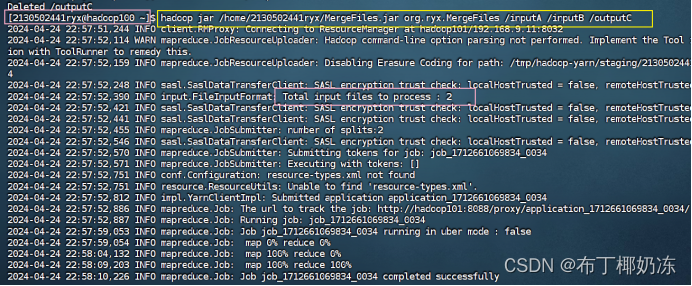
bash
hdfs dfs -cat /outputC/part-r-00000
3. 源代码
① MergeMapper
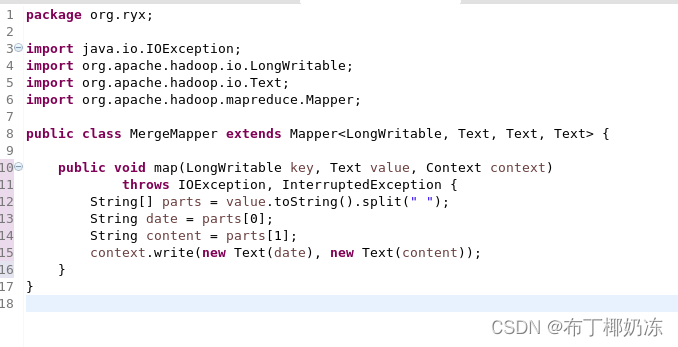
② MergeReducer
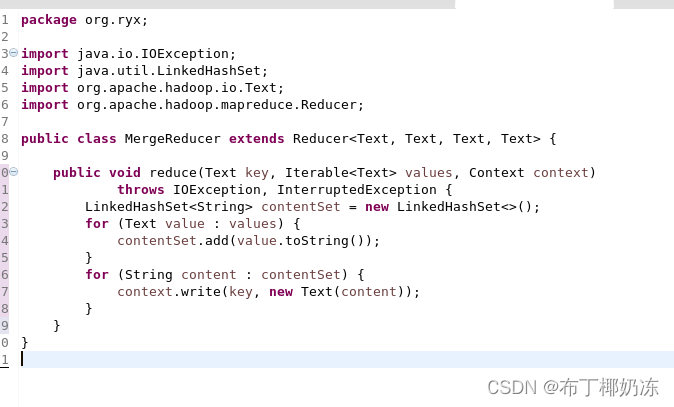
③ MergeFiles