上一篇博客我们正式进入C++的学习,这一篇博客我们继续学习C++入门的基础内容,一定要学好入门阶段的内容,这是后续学习C++的基础,方便我们后续更加容易的理解C++。
目录
[1.0 产生的原因](#1.0 产生的原因)
[1.1 概念](#1.1 概念)
[1.2 特性](#1.2 特性)
[1.3 面试题](#1.3 面试题)
[2.1 缺省参数的概念](#2.1 缺省参数的概念)
[2.2 缺省参数的分类](#2.2 缺省参数的分类)
[2.2.1 全缺省参数](#2.2.1 全缺省参数)
[2.2.2 半缺省参数](#2.2.2 半缺省参数)
[2.3 多文件结构的缺省参数函数](#2.3 多文件结构的缺省参数函数)
[2.3.1 缺省参数补充](#2.3.1 缺省参数补充)
[3.0 函数重载的引入](#3.0 函数重载的引入)
[3.1 函数重载概念](#3.1 函数重载概念)
[3.2 判断函数重载的规则(编译器的工作)](#3.2 判断函数重载的规则(编译器的工作))
[3.3 函数重载解析的步骤](#3.3 函数重载解析的步骤)
[3.4 函数重载判断练习](#3.4 函数重载判断练习)
[3.5 C++支持函数重载的原理-名字修饰(name Mangling)](#3.5 C++支持函数重载的原理-名字修饰(name Mangling))
[3.5.1 预备知识](#3.5.1 预备知识)
[3.5.2 C语言编译时函数名修饰约定规则(Windows平台下)](#3.5.2 C语言编译时函数名修饰约定规则(Windows平台下))
[3.5.2 C语言编译时函数名修饰约定规则(Linux平台下)](#3.5.2 C语言编译时函数名修饰约定规则(Linux平台下))
[3.5.3 C++编译时函数名修饰约定规则(Windows平台下)](#3.5.3 C++编译时函数名修饰约定规则(Windows平台下))
[3.5.3 C++编译时函数名修饰约定规则(Linux平台下)](#3.5.3 C++编译时函数名修饰约定规则(Linux平台下))
[3.6 C++函数重载的名字粉碎(名字修饰)](#3.6 C++函数重载的名字粉碎(名字修饰))
[3.7 如何指定函数以C方式修饰函数名还是以C++方式修饰函数名](#3.7 如何指定函数以C方式修饰函数名还是以C++方式修饰函数名)
[4.0 产生的原因](#4.0 产生的原因)
[4.1 函数模板定义](#4.1 函数模板定义)
[4.2 数组的推演及引用的推演](#4.2 数组的推演及引用的推演)
[4.3 利用函数模板实现泛型编程](#4.3 利用函数模板实现泛型编程)
[4.4 模板函数的重载与特化(完全特化、部分特化、泛化)](#4.4 模板函数的重载与特化(完全特化、部分特化、泛化))
[4.5 类模板](#4.5 类模板)
[5.1 C++作用域的划分](#5.1 C++作用域的划分)
[5.2 命名空间](#5.2 命名空间)
[5.3 命名空间的定义](#5.3 命名空间的定义)
[5.4 命名空间使用](#5.4 命名空间使用)
[5.4.1 加命名空间名称及作用域限定符](#5.4.1 加命名空间名称及作用域限定符)
[5.4.2 使用using将命名空间中某个成员引入](#5.4.2 使用using将命名空间中某个成员引入)
[5.4.3 使用using namespace 命名空间名称引入](#5.4.3 使用using namespace 命名空间名称引入)
一、内联函数
1.0 产生的原因
当程序执行函数调用时,系统要建立栈空间,保护现场,传递参数以及控制程序执行的转移等等, 这些工作需要系统时间和空间的开销。当函数功能简单,使用频率很高,为了提高效率,直接将函数的代码嵌入到程序中。但这个办法有缺点,一是相同代码重复书写,二是程序可读性往往没有使用函数的好。因此,便产生了内联函数,它的作用主要如下:
1、减少函数调用开销:函数调用通常会有一些额外的开销,包括压栈、跳转、返回等。这些开销对于频繁调用的小函数(如访问器函数、简单的计算函数)而言,可能会显得过高。通过将这些小函数定义为内联函数,可以避免这些开销,因为内联函数会在编译时直接将函数代码插入到调用点。
2、增强代码可读性 :通过内联函数,可以将一些频繁使用的代码块抽象为函数,从而提高代码的可读性和可维护性。同时,因为内联函数在编译时会被展开,所以在运行时不会引入函数调用的开销。
cpp
#include<ctype.h> //C语言中的字符处理函数库
#include<iostream>
using namespace std;
boo1 IsNumber(char ch)
{
return ch >= 'O' && ch <= '9' ? 1 : 0;
//return isdigit(ch) ;
}
int main()
{
char ch;
while (cin.get(ch), ch != '\n')
{
if (IsNumber(ch))
{
cout << " 是数字字符" <<endl;
}
else
{
cout << "不是数字字符 " <<endl;
}
}
return 0;
}如果上述代码判断数字字符函数在程序频繁调用,那么将会产生一笔不小的空间开销和时间开销。为了协调好效率和可读性之间的矛盾,C++提供 了另一种方法,即定义内联函数。
1.1 概念
以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开(在编译期间编译器会用函数体替换函数的调用。),没有函数调用建立栈帧的开销,内联函数提升程序运行的效率。
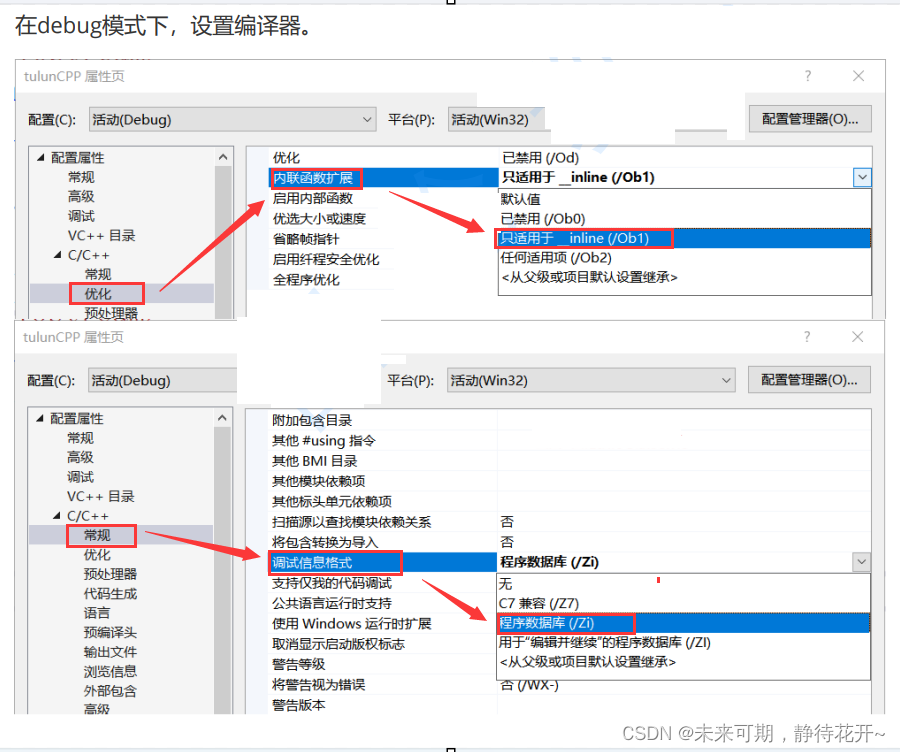
查看方式:
- 在release模式下,查看编译器生成的汇编代码中是否存在call Add
- 在debug模式下,需要对编译器进行设置,否则不会展开(因为debug模式下,编译器默认不会对代码进行优化,以下给出vs2019的设置方式)

1.2 特性
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用,缺陷:可能会使目标文件变大,优势:少了调用开销,提高程序运行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建 议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性。下图为 《C++prime》第五版关于inline的建议:
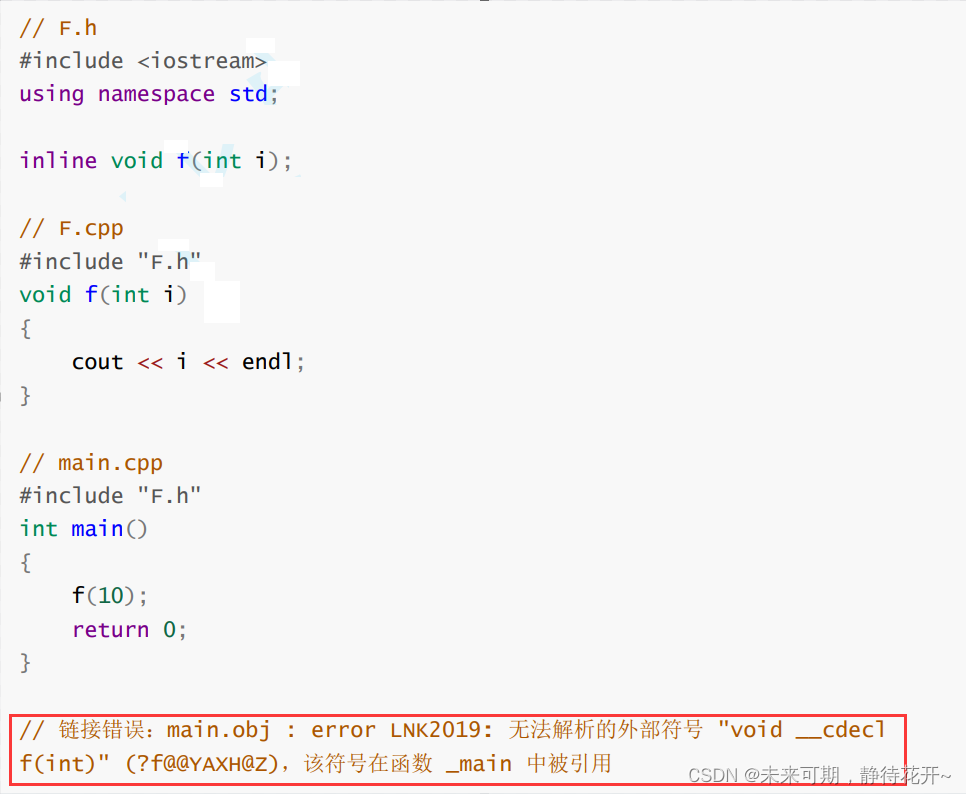
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
哪什么情况下采用inline处理合适,什么情况下以普通函数形式处理合适呢?这里有个建议给大家。
如果函数的执行开销小于开栈清栈开销(函数体较小),使用inline处理效率高。如果函数的执行开销大于开栈清栈开销,使用普通函数方式处理。

1.3 面试题
内联函数与宏定义区别:
- 内联函数在编译时展开,带参的宏在预编译时展开。
- 内联函数直接嵌入到目标代码中,带参的宏是简单的做文本替换。
- 内联函数有类型检测、语法判断等功能,宏只是替换。
二、缺省参数
2.1 缺省参数的概念
一般情况下,函数调用时的实参个数应与形参相同,但为了更方便地使用函数,C++也允许定义具有缺省参数的函数,这种函数调用时,实参个数可以与形参不相同。缺省参数指在定义函数时为形参指定缺省值(默认值)。这样的函数在调用时,对于缺省参数,可以给出实参值,也可以不给出参数值。如果给出实参,将实参传递给形参进行调用,如果不给出实参,则按缺省值进行调用。
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。

2.2 缺省参数的分类
2.2.1 全缺省参数

2.2.2 半缺省参数

注意事项:
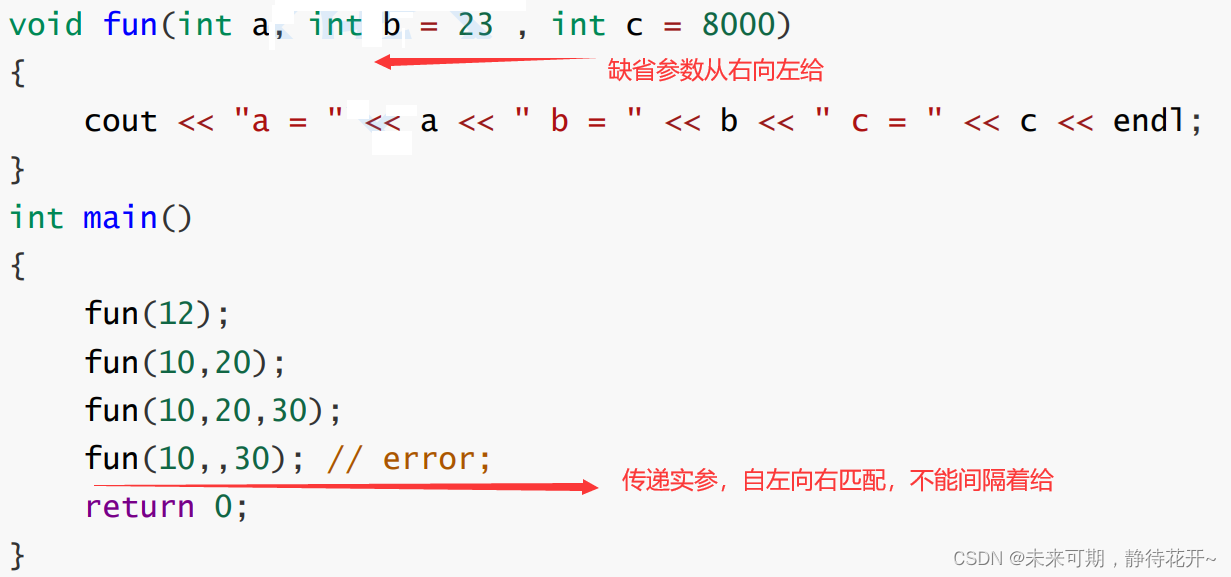
缺省参数可以有多个,但所有缺省参数必须放在参数表的右侧,即先定义所有的非缺省参数,再定义缺省参数(半缺省参数必须从右往左依次来给出,不能间隔着给)。这是因为在函数调用时,参数自左向右逐个匹配(函数调用时同样从左往右给实参,不能间隔着给),当实参和形参个数不一致时只有这样才不会产生二义性。
2.3 多文件结构的缺省参数函数
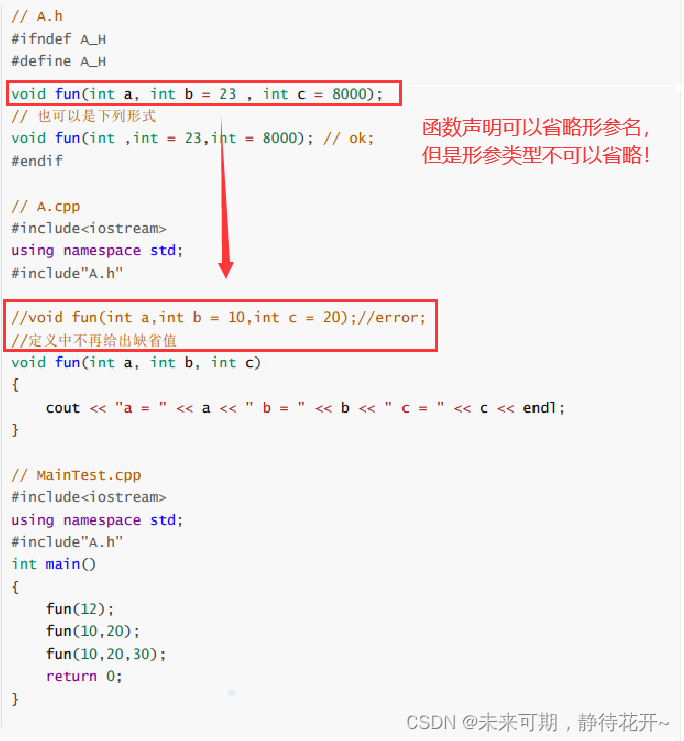
函数的原型(声明):由返回值类型+函数名+形参表,形参名称可以省略,但必须有形参类型
指针变量参数为缺省值的时候,指针变量名不可以省略!
缺省参数不能在函数声明和定义中同时出现,因为如果函数的声明与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值!
习惯上,缺省参数在公共头文件包含的函数声明中指定, 不要函数的定义中指定。如果在函数的定义中指定缺省参数值,在公共头文件包含的函数声明中不能再次指定缺省参数
值。
2.3.1 缺省参数补充
缺省实参不一定必须是常量表达式,可以使用任意表达式。当缺省实参是一个表达式时在函数被调用时该表达式被求值。
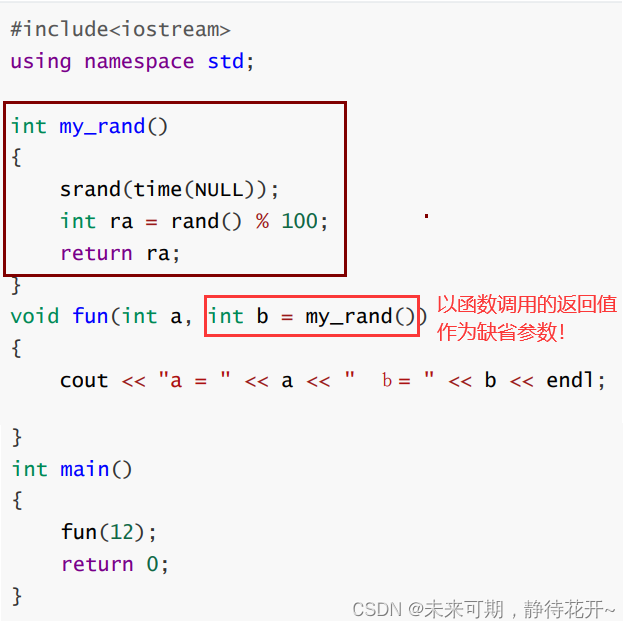
C语言不支持缺省参数(编译器不支持)
三、函数重载(重点)
自然语言中,一个词可以有多重含义,人们可以通过上下文来判断该词真实的含义,即该词被重载了。 比如:以前有一个笑话,中国有两个体育项目大家根本不用看,也不用担心。一个是乒乓球,一个是男足。前者是"谁也赢不了!",后者是"谁也赢不了!"
3.0 函数重载的引入
C语言实现int, double,char类型的比较大小函数。如下:
cpp
int my_max_i(int a, int b)
{
return a > b ? a : b;
}
double my_max_d(double a, double b)
{
return a > b ? a : b;
}
char my_max_c(char a, char b)
{
return a > b ? a : b;
}很容易发现它们的共同特点:这些函数都执行了相同的一般性动作; 都返回两个形参中的最大值;从用户的角度来看,只有一种操作,就是判断最大值,至于怎样完成其细节,用户一点也不关心。这种词汇上的复杂性不是"判断参数中的最大值"问题本身固有的,而是反映了程序设计环境的一种局限性:在同一个作用域中出现的函数名字必须指向一个唯实体(函数体)。这种复杂性给程序员带来了一个实际问题,他们必须记住或查找每一个函数名字。函数重载把程序员从这种词汇复杂性中解放出来。
cpp
#include<iostream>
using namespace std;
int max(int a, int b)
{
return a > b ? a : b;
}
double max(double a, double b)
{
return a > b ? a : b;
}
char max(char a, char b)
{
return a > b ? a : b;
}
int main()
{
cout << max(12, 23) << endl;
cout << max(12.23, 23.45) << endl;
cout << max('a', 'b') << endl;
编译器在编译的时候就已经确定数据类型,从而匹配相应的函数
return 0;
}3.1 函数重载概念
函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 类型顺序)不同,常用来处理实现功能类似数据类型 不同的问题。
cpp
#include<iostream>
using namespace std;
// 1、参数类型不同构成函数重载
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
// 2、参数个数不同构成函数重载
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3、参数类型顺序不同构成函数重载
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
编译器在编译的时候就已经确定数据类型,从而匹配相应的函数
return 0;
}编译器的工作:
当一个函数名在同一个域中被声明多次时,编译器按如下步骤解释第二个(以及后续的)的声明。如果两个函数的参数表中参数的个数或类型或顺序不同,则认为这两个函数是重载。而不认为是函数的重复声明(编译器报错!)。
3.2 判断函数重载的规则(编译器的工作)
这一小节来学习,编译器是如何识别函数重载的,只有我们明白了编译器判断的规则,我们才能正确使用函数重载!
1.如果两个函数的参数表相同,但是返回类型不同, 会被标记为编译错误:函数的重复声明。
cpp
int my_max(int a, int b)
{
return a > b ? a : b;
}
unsigned int my_max(int a, int b) // 编译报错,被认为是函数的重复声明;
{
return a > b ? a : b;
}
int main()
{
int ix = my_max(12, 23);
unsigned int =my_max(12, 23); // 编译无法通过;
reutrn 0;
}为什么呢?
函数的返回类型不能作为函数重载的依据,编译器区分函数是依靠函数声明中的函数名和参数的类型,编译器不知道应该调用哪个函数,编译器认为是同一个函数重复声明;
2.参数表的比较过程与形参名无关。
cpp
//编译器会把下面这两个函数认为是同一个函数,编译报错,函数重复声明
int my_add(int a, int b);
int my_add(int x, int y);为什么呢?
函数的参数列表中的参数名不能作为函数重载的依据,同样,因为编译器不以参数名称来区分函数,被认为是同一个函数,编译器认为是同一个函数重复声明;
3.如果在两个函数的参数表中,只有缺省实参不同,编译器同样认为是同一个函数重复声明;也就是说它认为这是一个函数。
cpp
//编译器会把下面这两个函数认为是同一个函数,编译报错,函数重复声明
void Print(int* br, int n);
void Print(int* br, int len = 10);4.typedef名为现有的数据类型提供了一个别名,它并没有创建一个新类型,因此,如果两个函数参数表的区别只在于一个使用了typedef重命名,而另一个使用了与typedef相应的类型。则该参数表被视为相同的参数列表,编译器同样认为是同一个函数重复声明;也就是说它认为这是一个函数。
cpp
//编译器会把下面这两个函数认为是同一个函数,编译报错,函数重复声明
typedef unsigned int u_int;
int Print(u_int a);
int Print(unsigned int b);5.当一个形参类型有const或volatile修饰时,如果形参是按值传递方式定义,在识别函数声明是否相同时,并不考虑const和volatile修饰符.(不考虑CV特性)
cpp
//编译器会把下面这两个函数认为是同一个函数,编译报错,函数重复声明
void fun(int a);
void fun(const int a);6.当一个形参类型有const或volatile修饰时,如果形参是按照指针或引用定义时,在识别函数声明是否相同时,就要考虑const和volatile修饰符.**(考虑CV特性),**那么又该如何考虑呢?
cpp
#include<iostream>
using namespace std;
void print(int &a)
{
cout<<"左值引用"<<endl;
}
void print(const int &b)
{
cout<<"常性左值引用(万能引用)"<<endl;
}
void print(int &&b)
{
cout<<"右值引用"<<endl;
}
int main()
{
int x = 10;
print(x); //优先匹配左值引用
const int y = 10;
print(y); //只匹配常性左值引用/常引用!(万能引用)
print(10); //优先匹配右值引用
return 0;
}匹配规则如下:
首先,C++只有三种引用方式:左值引用(引用的是左值:可以取地址)、常性左值引用/万能引用(既可以引用左值:可以取地址,又可以引用右值:不可以取地址)、右值引用(引用的是右值:不可以取地址),当存在三个引用的函数时,我们应明确编译器的匹配顺序,根据实参的类型进行匹配!!!
对于左值,优先匹配左值引用,其次才是常性左值引用!
对于常性左值,直接匹配常性左值引用,不存在,编译器直接报错!
对于右值引用,优先匹配右值引用,其次才是常性左值引用!
- 对于普通的变量(它是左值),编译器首先优先匹配形参为左值引用的函数,如果不存在该函数,然后,匹配形参为常性左值引用(常引用)的函数,如果二者都不存在,编译器直接报错!
- 对于常变量(const修饰),编译器直接匹配形参为常性左值引用(常引用)的函数,如果该函数不存在,编译器直接报错(不能匹配参数为右值引用的函数,右值引用引用的是右值)!
- 对于右值,编译器首先优先匹配形参为右值引用的函数,如果该函数不存在,然后,匹配形参为常性左值引用(常引用)的函数,如果二者都不存在,编译器直接报错!
7.注意函数调用的二义性; 如果在两个函数的参数表中,形参类型相同,而形参个数不同,形参默认值将会影响函数的重载.
cpp
#include<iostream>
using namespace std;
/****函数调用的二义性****/
void fun(int a);
void fun(int a, int b);
void fun(int a, int b = 10);
int main()
{
fun(12); //这里第一个函数会和第三个函数会发生冲突,编译器不知道该调用哪一个函数
fun(12,13); //这里第二个函数会和第三个函数会发生冲突,编译器不知道该调用哪一个函数
return 0;
}3.3 函数重载解析的步骤
- 确定函数调用考虑的重载函数的集合,确定函数调用中实参表的属性(由形参表的属性确定调用那个函数)。
- 从重载函数集合中选择函数,该函数可以在(给出实参个数和类型)的情况下可以调用函数。
- 选择与调用最匹配的函数。
3.4 函数重载判断练习
cpp
#include<iostream>
using namespace std;
* /*******下面两个函数构成重载***********/
void func(int *p) {} //可读可写
void func(const int *p) {} //只可读,不可解引用修改
int main()
{
int x = 10; //普通变量:可读可写
func(&x); //优先匹配普通指针的函数(第一个),其次才是const修饰的指针的函数(第二个)
const int y = 10; //常变量:只可读
func(&y); //只能匹配const修饰的指针的函数(第二个),如果不存在该函数,直接报错!
return 0;
}
cpp
#include<iostream>
using namespace std;
/*******下面两个函数不构成重载***********/
//编译器会报错,这不是函数的重载,第二个在编译的时候会直接忽略const ,认为是同一个函数重复声明
void func(int *p) {} //可读可写,可以解引用修改数据
void func( int* const p) {} //可读可写,可以解引用修改数据,const修饰指针自身的时候,编译器可以忽略const的存在
/**如果修改第二个为:void func( const int* const p) {} 那么这便又是函数的重载**********/
int main()
{
int x = 10; //普通变量
func(&x); //两个函数功能一样,对传入的数据都可读可写,匹配两个都可以!编译器不知道调用哪个,就会报错,认为是同一个函数重复声明!
return 0;
}
#endif
cpp
#include<iostream>
using namespace std;
/*****下面两个函数是重载函数:参数的个数不同******/
void func(int a);
void func(int a,int b);
int main()
{
func(12);
func(12, 23);
}
cpp
#include<iostream>
using namespace std;
void func(int a);
void func(int a, int b=20);
int main()
{
func(12); //这里第一个函数会和第二个函数会发生冲突,编译器不知道该调用哪一个函数
func(12, 23);//这里第一个函数会和第二个函数会发生冲突,编译器不知道该调用哪一个函数
}
由于函数调用的二义性,不是重载函数,这种问题只要不调用函数就不会报错,但是只要调用就会出现编译错误!!!3.5 C++支持函数重载的原理-名字修饰(name Mangling)
3.5.1 预备知识
"C"或者"C++"函数在内部(编译和链接)通过修饰名识别。修饰名是编译器在编译函数定义或者
原型时生成的字符串。修饰名由函数名、类名、调用约定、返回值类型、参数表共同决定。不同的调用方式,形成的修饰名也不同。
- **_stdcall调用:**Pascal程序的缺省调用方式,通常用于Win32 Api中,函数采用从右到左的压栈方式,自己在退出时清空堆栈。
- C调用(即用_cdecl 关键字说明):按从右至左的顺序压参数入栈,由调用者把参数弹出栈。对于传送参数的内存栈是由调用者来维护的(正因为如此,实现可变参数的函数只能使用该调用约定)。
- _fastcall 调用:"人"如其名,它的主要特点就是快,因为它是通过寄存器来传送参数的(实际上,它用ECX和EDX传送前两个双字( DWORD )或更小的参数,剩下的参数仍旧自右向左压栈传送,被调用的函数在返回前清理传送参数的内存栈),在函数名修饰约定方面,它和前两者均不同。
- **thiscall调用:**仅仅应用于"C++ "类的成员函数。this 指针存放于ECX寄存器,参数从右到左压。thiscall不是关键词,因此不能被程序员指定。
在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。


- 实际项目通常是由多个头文件和多个源文件构成,而通过C语言阶段学习的编译链接,我们 可以知道,【当前a.cpp中调用了b.cpp中定义的Add函数时】,编译后链接前,a.o的目标文件中没有Add的函数地址,因为Add是在b.cpp中定义的,所以Add的地址在b.o中。那么怎么办呢?
- 所以链接阶段就是专门处理这种问题,链接器看到a.o调用Add,但是没有Add的地址,就会到b.o的符号表中找Add的地址,然后链接到一起。
- 那么链接时,面对Add函数,链接接器会使用哪个名字去找呢?这里每个编译器都有自己的 函数名修饰规则。
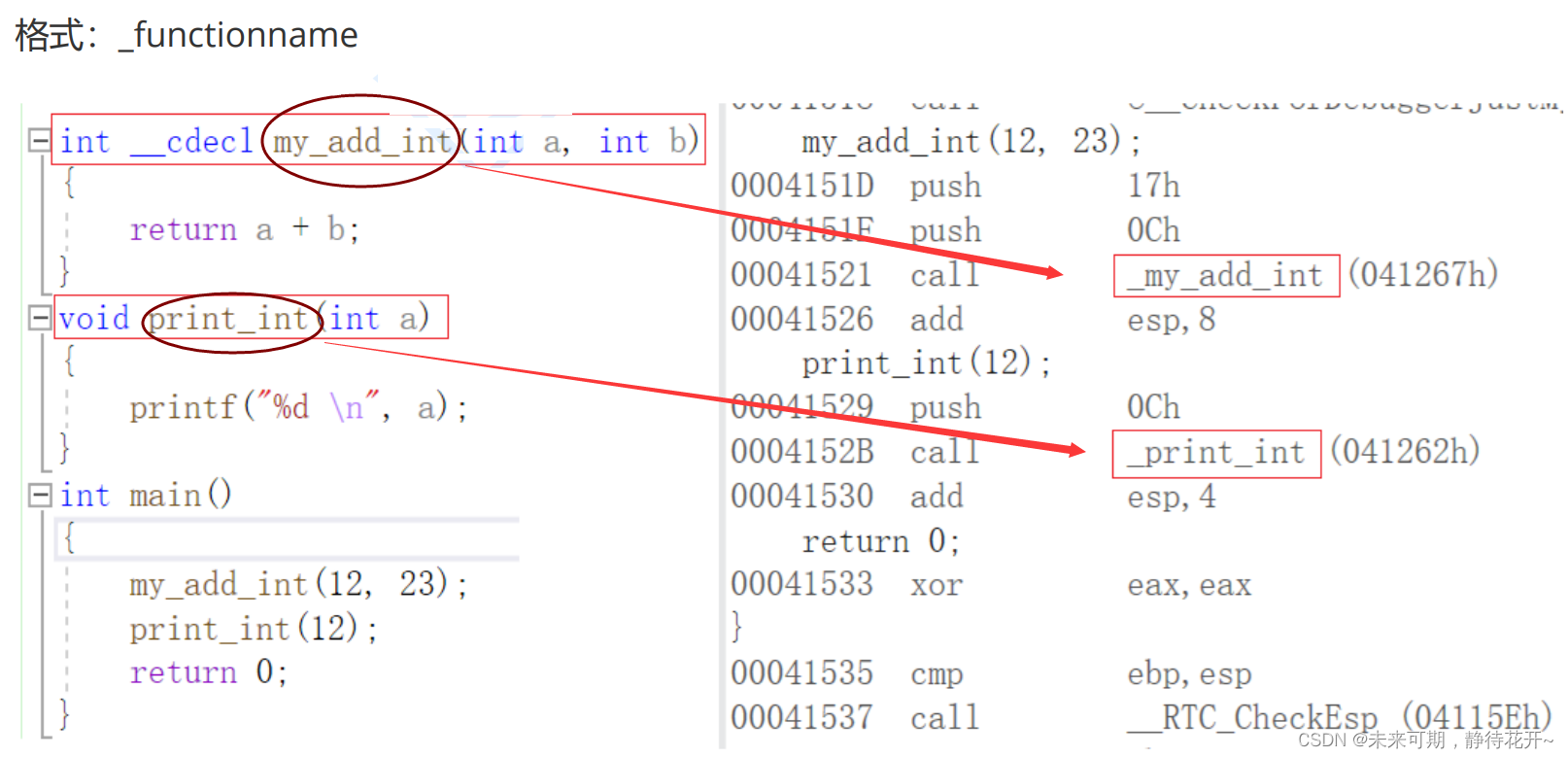
3.5.2 C语言编译时函数名修饰约定规则(Windows平台下)
C语言的名字修饰规则非常简单,_ cdec是C/C++的缺省调用方式,调用约定函数名字前面添加了下划线前缀。
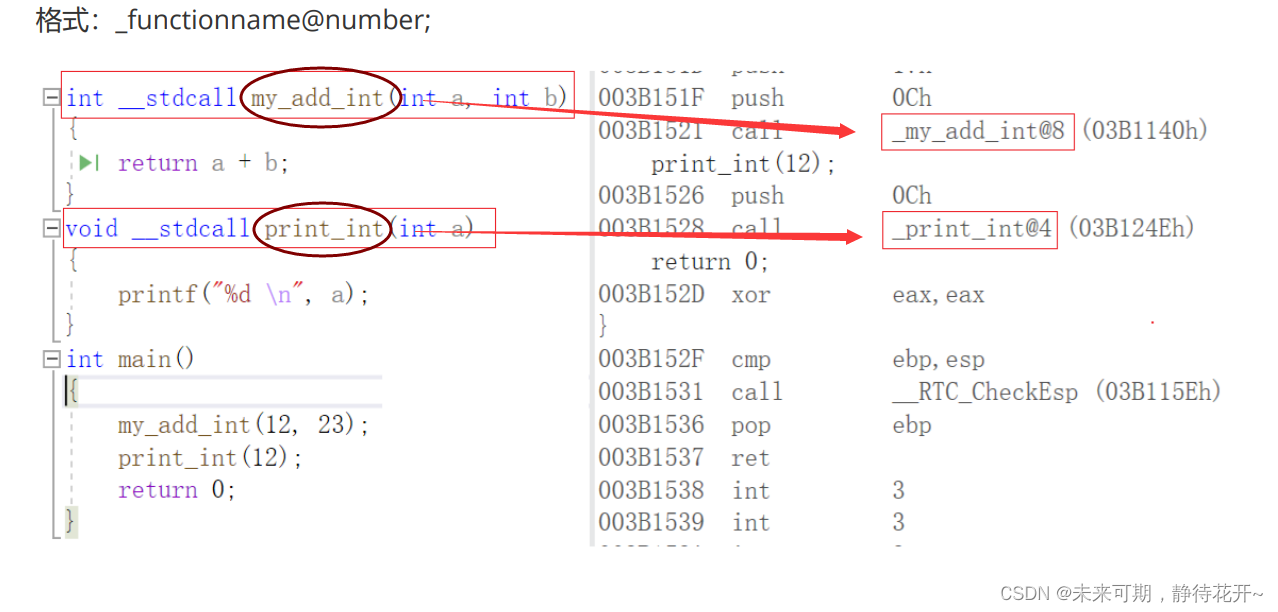
_stdcall调用约定在输出函数名前加上一个下划线前缀,后面加上一个"@"符号和其参数的字节数。
_fastcall调用约定在输出函数名前加上一个" @ "符号,函数名后面也是一个" @ "符号和其参数的字节数。

3.5.2 C语言编译时函数名修饰约定规则(Linux平台下)
通过下面我们可以看出gcc的函数修饰后名字不变。

3.5.3 C++编译时函数名修饰约定规则(Windows平台下)


3.5.3 C++编译时函数名修饰约定规则(Linux平台下)

3.6 C++函数重载的名字粉碎(名字修饰)
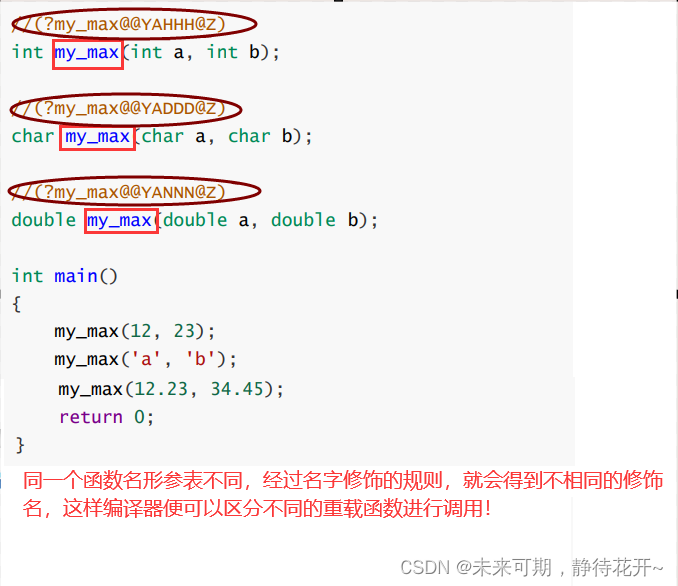
面试题:
编译器编译完是按照修饰名访问这些函数的,不同的调用方式,编译器编译时函数名修饰约定规则不同。
1、什么是函数重载?
函数名相同而参数列表不同(类型或者数量),叫函数重载!
2、返回值可不可以作为函数重载的依据?
不可以!C++的函数调用解析机制仅基于参数类型和数量来匹配函数,而不考虑返回值类型!如果两个函数函数名和参数是一样的,返回值不同是不构成重载的,因为调用时编译器没办法区分。
3、为什么C++可以进行函数的重载,而C语言不可以?
原因在于:二者的修饰名规则不同!(名字粉碎技术不同), C语言只是在函数名的 前面加个下划线,那么对于多个同名函数,他们的修饰名都相同,都是在函数名前面加个下划线!编译器在编译阶段无法区分!C++把形参列表的类型和数量作为修饰名的一部分,这样相同的函数名(函数重载)就会得到不同的修饰名,这样编译器在编译阶段就可以区分出来!
3.7 如何指定函数以C方式修饰函数名还是以C++方式修饰函数名
cpp
extern "C" int add(int x, int y) { return x + y; } //<==> 按照C的修饰规则,修饰名为:_add
double add(double x, double y) { return x + y; }//<==> 按照C++的修饰规则,修饰名为:?add@@YAHHH@Z
//上面编译可以通过,因为C和C++修饰名规则不同,编译器可以区分!
extern "C" int add(int x, int y) { return x + y; } //<==>按照C的修饰规则,修饰名为:_add
extern "C" double add(double x, double y) { return x + y; } //<==>按照C的修饰规则,修饰名为:_add
//上面编译不可以通过,因为二者使用的都是C的修饰名规则,编译器无法区分!
//如何将一批函数指定相同的修饰规则:加个大括号
extern "C"
{
int add(int x, int y) //<==> 按照C的修饰规则,修饰名为:_add
{
return x + y;
}
double add(double x, double y) //<==> 按照C的修饰规则,修饰名为:_add
{
return x + y;
}
}四、函数模板(重点)
4.0 产生的原因
为了代码重用, 代码就必须是通用的;通用的代码就必须不受数据类型的限制。那么我们可以把
数据类型改为一个设计参数。这种类型的程序设计称为参数化(parameterize) 程序设计。
软件模块由模板构造。包括函数模板(function template)和类模板(class template)。
函数模板可以用来创建一个通用功能的函数, 以支持多种不同形参, 简化重载函数的设计。
4.1 函数模板定义

<模板参数表> 尖括号中不能为空,参数可以有多个,用逗号分开。模板参数主要是模板类型参数。模板类型参数代表一种类型,由关键字class 或typename 后加一个标识符构成,在这里两个关键字的意义相同,它们表示后面的参数名代表一个潜在的内置或用户设计的类型。
cpp
#include<iostream>
using namespace std;
template<class T>
T my_max(T a,T b)
{
return a > b ? a : b;
}
int main()
{
my_max(12, 23);
my_max('a', 'b');
my_max(12.23, 34.45);
return 0;
}编译阶段,编译器根据实参类型自动的生成如下函数代码:这也叫模板实参推演,其本质上还是函数重载,由编译器自动生成代码。
cpp
typedef int T;
T my_max<int>(T a, T b)
{
return a > b ? a : b;
}
typedef char T;
T my_max<char>(T a, T b)
{
return a > b ? a : b;
}
typedef double T;
T my_max<double>(T a, T b)
{
return a > b ? a : b;
}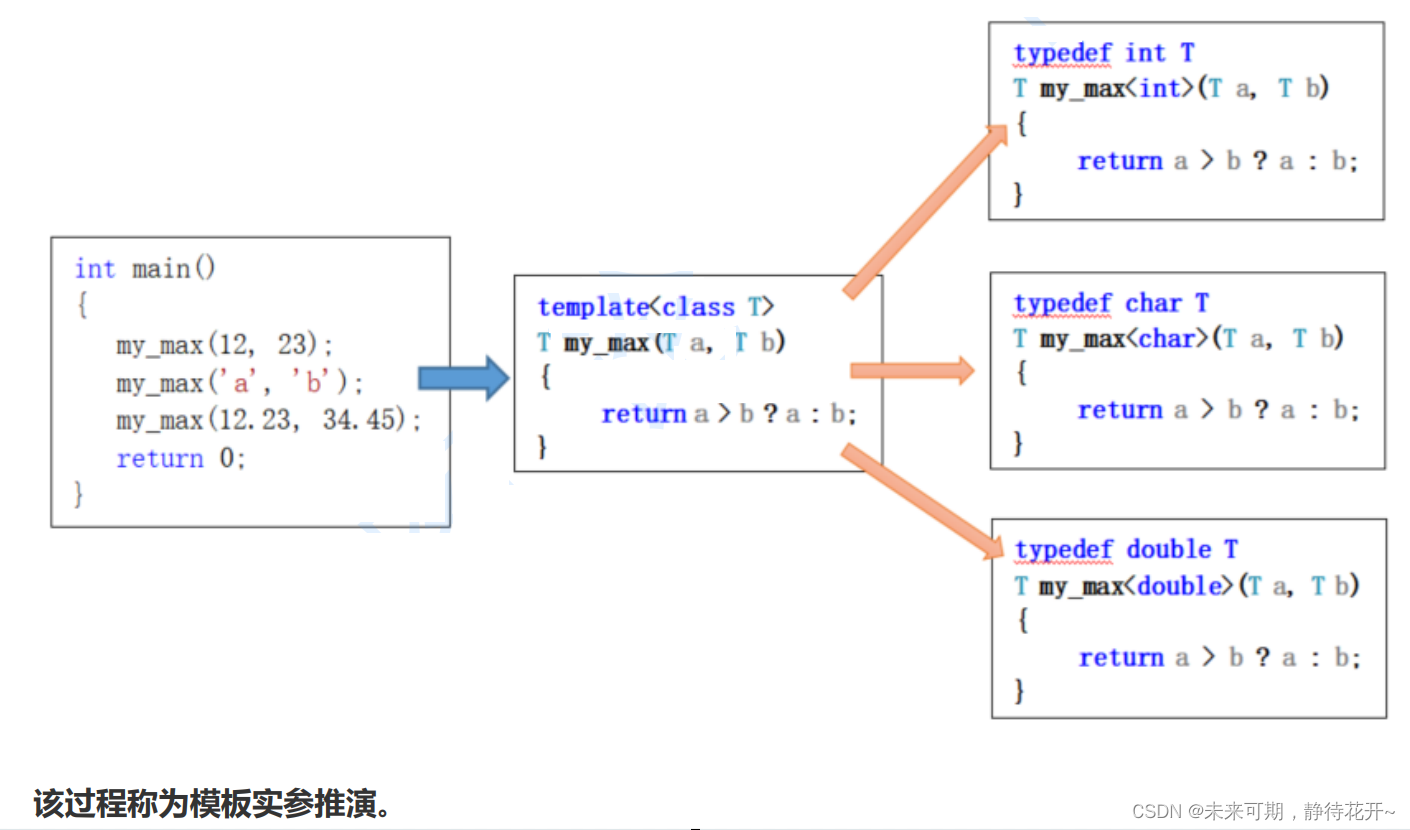
在编译过程中,根据函数模板的实参构造出独立的函数,称为模板函数。这个构造过程被称为模板实例化。
cpp
#if 0
#include<iostream>
using namespace std;
#include <typeinfo>
template<class T>
void print(T a)
{
cout << typeid(a).name() << endl;
cout << typeid(a).name() << endl;
cout << typeid(a).name() << endl;
}
int main()
{
int a = 10;
int arr[] = { 1,2,3,4,5 };
print(a); //编译阶段,编译器推演出:T为整型 int
print(&a); //编译阶段,编译器推演出:T为整型指针 int *
print(arr); //数组名代表首元素的地址,也就是一个指针,编译阶段,编译器推演出:T为整型指针 int *
}
#endif4.2 数组的推演及引用的推演
cpp
#if 1
#include<iostream>
using namespace std;
#include <typeinfo>
template<class T>
void print(T &a) //函数的参数为实参类型的引用(实参的引用)
{
cout << typeid(T).name() << endl;
cout << typeid(a).name() << endl;
cout << sizeof(a) << endl; //20
}
int main()
{
int a = 10;
int arr[] = { 1,2,3,4,5 };
print(a); //编译阶段,实参a为一个整型, 编译器推演出:T为整型 int ,函数参数a为整型引用类型:int &
print(&a); //编译阶段,编译器无法推演,实参为一个整型指针也就是:int *, 所以a就是这个整型指针的引用,按道理推演a为:int* & ,在实参里面可以a++,但是这里的&a是一个地址,是一个常量(带有常性const),所以编译器无法推演!,
print(arr); //编译阶段,数组名代表首元素的地址,也就是一个整型指针,编译阶段,编译器推演出:数组引用,int [5]&
}4.3 利用函数模板实现泛型编程
cpp
下面这个打印数组的函数代码适用于一切类型的数组,我都可以打印整个数组,类型由编译器自动推演
#include<iostream>
using namespace std;
// typedef int T ==>int
// #define N 5 ==>5
template<class T, int N>
void print(T(&br)[N]) /*模板类型参数推演时:类型是重命名规则,非类型是宏的规则直接拿数值替换*/
{
for (int i = 0; i < N; i++)
{
cout << br[i] << " ";
}
count << endl;
}
int main()
{
int arr[5] = { 1,2,3,4,5 };
double brr[3] = { 1.2,3.4,5.3 };
print(arr); //数组引用:int (&br)[5]=arr;
print(brr); //数组引用:double (&br)[3]=brr;
}4.4 模板函数的重载与特化(完全特化、部分特化、泛化)
- 模板函数的重载是C++中允许通过模板实现多个函数版本的功能。在C++中,函数可以通过相同的名字但不同的参数列表来重载。模板函数也可以通过这种方式实现重载。
- 函数模板特化是指为特定类型提供一个专门的模板实现,与上面相比,而不是使用通用的模板版本。
cpp
#include<iostream>
using namespace std;
/*泛化:无任何限制*/
template<class T>
void func(T a)
{
}
/*部分特化:限制常性的任意类型指针*/
template<class T>
void func(const T *p)
{
}
/*完全特化:限制常性的字符类型指针*/
void func(const char* p)
{
}
int main()
{
const char* str = "hello";
int a = 10;
func(a);
func(&a);
func(str);
return 0;
}4.5 类模板
类模板是C++中一种强大的工具,用于定义通用的类。**通过类模板,可以创建能够处理任意数据类型的类,而无需为每种数据类型编写单独的类。**类模板使用模板参数来表示类中的数据类型,使得类的实现能够适用于多种类型。容器是一种数据结构,用于存储和管理一组对象。在C++标准库(STL,Standard Template Library)中,容器是实现了特定接口的类模板。这些类模板提供了存储、访问和操作其包含的元素的功能。
C++容器库包括序列容器、关联容器和无序容器。
序列容器(Sequence Containers):用于按照线性顺序存储数据。
std::vector:动态数组,支持快速随机访问和在末尾插入 / 删除元素。
std::deque:双端队列,支持快速随机访问和在两端插入 / 删除元素。
std::list:双向链表,支持在任何位置快速插入 / 删除元素。
std::array:固定大小的数组,大小在编译时确定。
std::forward_list:单向链表,支持在任何位置快速插入 / 删除元素,但只允许单向遍历。
容器库的特点泛型编程:通过模板实现,容器可以存储任意类型的对象。
自动管理内存:容器会自动管理其所需的内存,开发者无需手动分配和释放内存。
迭代器支持:所有容器都提供迭代器,用于遍历和操作元素。
算法兼容性:STL中的算法可以与容器无缝配合使用,提供诸如排序、搜索、复制等操作。
cpp
使用类模板生成任意类型的顺序栈
template<class T>
class SeqStack
{
private:
T* data;
int top;
public:
SeqStack(int sz = 100)
{
data = (T*)malloc(sizeof(T) * sz);
top = -1;
}
};
int main()
{
SeqStack<int> ist; //类模板的类型必须给定
SeqStack<double> dst;
}
/*******编译器会根据上述模板生成如下代码:**/
class SeqStack<int>
{
typedef int T;
private:
T* data;
int top;
public:
SeqStack(int sz = 100)
{
data = (T*)malloc(sizeof(T) * sz);
top = -1;
}
};
class SeqStack<double>
{
typedef double T;
private:
T* data;
int top;
public:
SeqStack(int sz = 100)
{
data = (T*)malloc(sizeof(T) * sz);
top = -1;
}
};五、名字空间:namespace
5.1 C++作用域的划分
在C++中把作用域划分为:全局作用域,局部作用域、块作用域,名字空间作用域和类作用域。注意:作用域是针对编译器来说的,生存周期针对运行的时候来说的。函数被调用时,被调用函数内部的变量才会分配内存空间,当函数执行完毕,被调用函数内部的变量将会归还给操作系统。我们定义的变量存储在栈区或者堆区。
- 全局变量:函数之外定义的变量:存储在数据区,
- 局部变量:函数内部定义的变量:存储在栈区,
- 静态局部变量:函数内部定义的变量加static关键字修饰,只创建一次,保存上次的值,不会重新初始化:存储在数据区(字符串常量也是)
- 花括号内部的变量,只在花括号内部有效:存储在栈区。
- 类作用域是指在类定义内部的作用域,决定了类中的成员(包括成员变量和成员函数)的可见性和生命周期。
- 名字空间作用域:多文件编程时:多个源文件定义相同的全局变量名字或者函数名,在项目进行编译链接时候就会发生全局命名冲突!名字空间域是随标准C++而引入的。它相当于一个更加灵活的文件域(全局域)。
5.2 命名空间
在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存 在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化, 以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。
名字空间域的引入,主要是为了解决全局名字空间污染(global namespace pollution)问题,即防止程序中的全局实体名与其他程序中的全局实体名的命名冲突。于是,便产生了命名空间。

5.3 命名空间的定义
定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{} 中即为命名空间的成员。
cpp
// 1. 正常的命名空间定义
namespace p1
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
int Add(int left, int right)
{
return left + right;
}
struct Node
{
struct Node* next;
int val;
};
}
//2. 命名空间可以嵌套
// test.cpp
namespace N1
{
int a;
int b;
int Add(int left, int right)
{
return left + right;
}
namespace N2
{
int c;
int d;
int Sub(int left, int right)
{
return left - right;
}
}
}
//3. 同一个工程中允许存在多个相同名称的命名空间,编译器最后会合成同一个命名空间中。
// ps:一个工程中的test.h和上面test.cpp中两个N1会被合并成一个
// test.h
namespace N1
{
int Mul(int left, int right)
{
return left * right;
}
}注意:一个命名空间就定义了一个新的作用域,命名空间中的所有内容都局限于该命名空间中
5.4 命名空间使用
命名空间中成员该如何使用呢?比如:

5.4.1 加命名空间名称及作用域限定符
cpp
int main()
{
int a = yhp: :my_ add(12,23) ;
printf("%1f \n",Primer: :pi);
printf ("%f \n",yhp: :pi);
Primer: :Matrix: :my_ _max('a','b');
return 0;
}5.4.2 使用using将命名空间中某个成员引入
cpp
using yhp::pi;
using Primer: :Matrix: :my_max;
//名字空间类成员matrix的using声明
//以后在程序中使用matrix时,就可以直接使用成员名,而不必使用限定修饰名。
int main()
{
printf("%1f \n",Primer: :pi) ;
printf("%f \n",pi); // yhp::
my_max('a','b');
return 0;
}5.4.3 使用using namespace 命名空间名称引入
使用using指示符可以一次性地使名字空间中所有成员都可以直接被使用,比using声明方便。using指示符;以关键字using开头,后面是关键字namespace,然后是名字空间名。
using namespace名字空间名;
cpp
using namespace yhp;
int main()
{
printf("%1f n",Primer: :pi ) ;
printf("%f n" ,pi) ;// yhp: :
my_add(12,23); // yhp::
return 0;
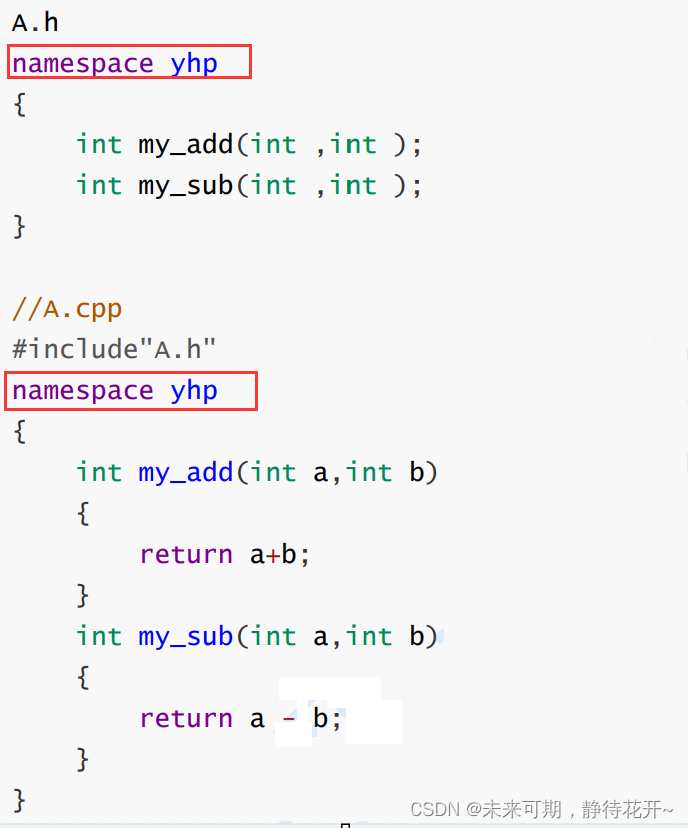
}多文件结构示例
std命名空间的使用惯例: .
std是C++标准库的命名空间,如何展开std使用更合理呢?
1.在日常练习中,建议直接using namespace std即可,这样就很方便。
- using namespace std展开,标准库就全部暴露出来了,如果我们定义跟库重名的类型/对
象/函数,就存在冲突问题。该问题在日常练习中很少出现,但是项目开发中代码较多、规模
大,就很容易出现。所以建议在项目开发中使用,像std::cout这样使用时指定命名空间+
using std::cout展开常用的库对象/类型等方式。
这篇博客内容较为丰富,为后续学习好C++做好准备, 如果对此专栏感兴趣,点赞加关注!