【IJCAI2024】LeMeViT: Efficient Vision Transformer with Learnable Meta Tokens for Remote Sensing Image Interpretation

由于相邻像素和图像块之间的高度相关性,以及遥感图像中纹理和模式的重复性质,存在大量的空间冗余。如下图所示,ViT 中的自注意力机制计算每两个图像块之间的相似性,相似的token对特征表示的贡献很小,但消耗了大量的计算负载,影响了模型性能。
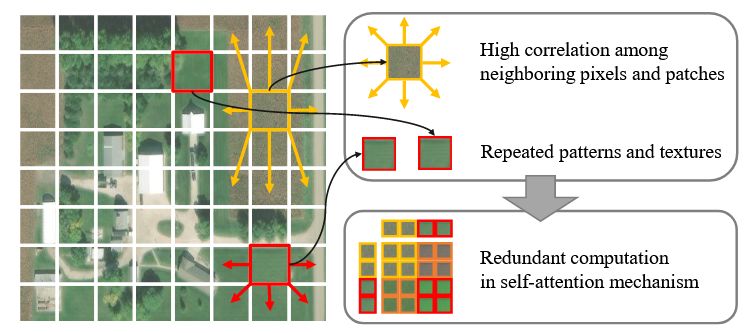
为此,作者提出了下图所示的框架。本质上引入了一个可学习的 meta token(类似于原型或者记忆),不断的进行 image token 和 meta token 的信息交换。值得注意的是,网络的浅层使用的是cross-attention,深层使用的是自注意力(作者解释是自注意力的性能更高)。
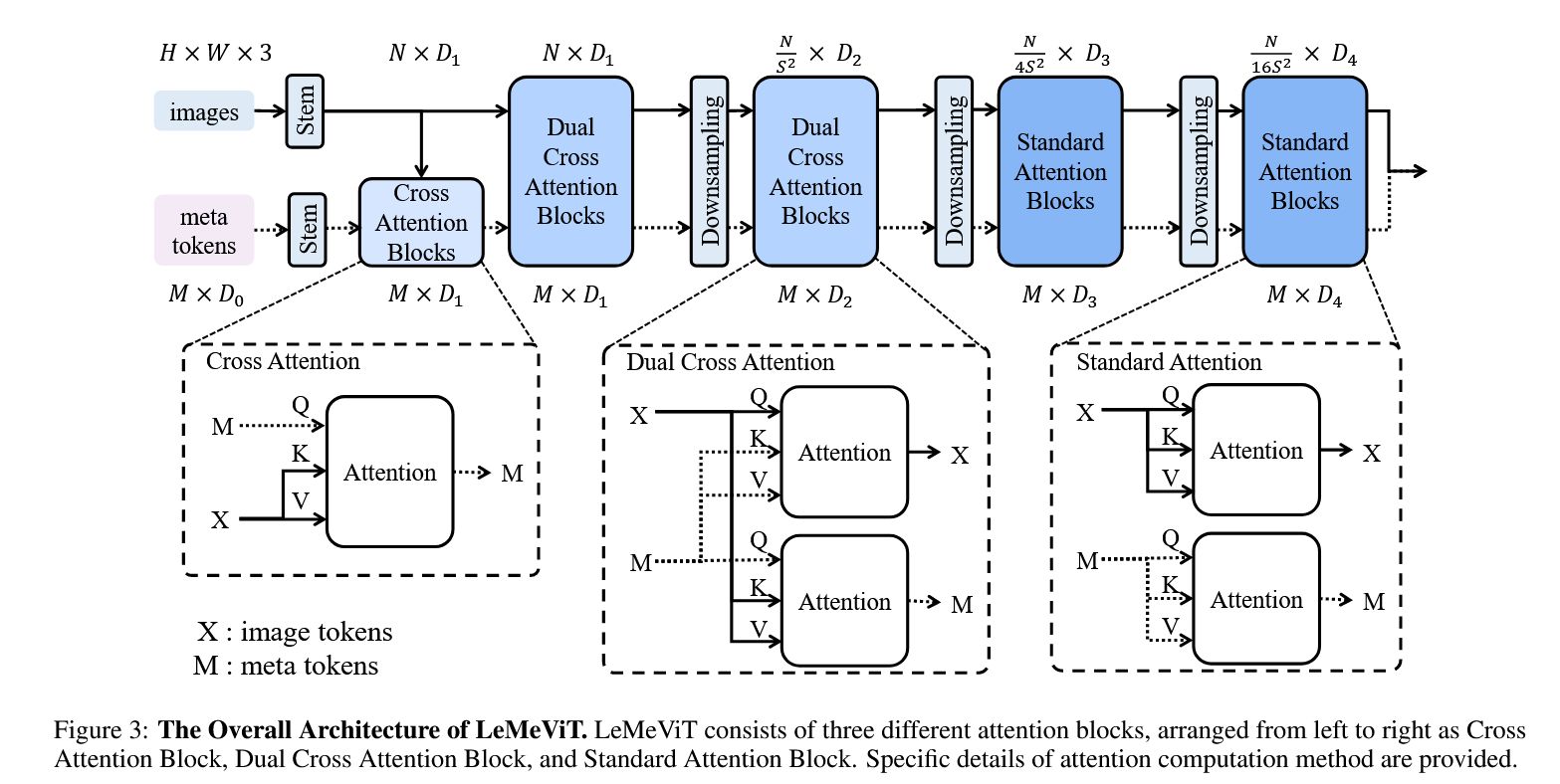
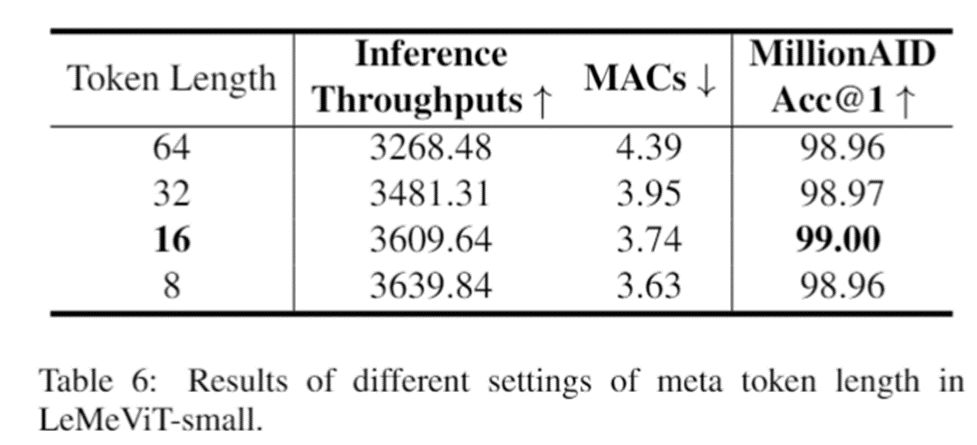
作者在语义分割、目标检测等多个应用上做了大量实验,结果表明该方法具有较好的性能。有个有趣的消融实验是meta token 长度对性能的影响。长度为 64、32、16 和 8时,准确率几乎相同。这进一步证实了注意力计算的冗余,表明使用较少数量的 meta token 来表示密集图像 token 的动机。最后,考虑到效率和准确性,作者选择 16 作为 meta token 长度的默认设置。
作者还可视化了 dual cross attention最后一个块中,交叉注意映射结果。自然图像上的实验结果表明,学习到的 meta token 可以很好地关注图像中的目标,有助于提高分类精度。遥感图像上的实验结果则表明不同的 meta token 负责图像的不同语义部分。
