1995年VAPINK 等人在统计学习理论的基础上提出了一种模式识别的新方法---支持向量机 。它根据有限的样本信息在模型的复杂性和学习能力之间寻求一种最佳折衷。 以期获得最好的泛化能力.支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部极小值,从而也保证了它对未知样本的良好泛化能力。
支持向量机的理论最初来自对两类数据分类问题的处理。SV M 考虑寻找一个超平面, 以使训练集中属于不同分类的点正好位于超平面的不同侧面, 并且,还要使这些点距离该超平面尽可能远。 即寻找一个超平面, 使其两侧的空白区域最大

既往我们在文章《R语言手把手教你进行支持向量机分析》中介绍了e1071包进行支持向量机分析。今天咱们来介绍一下fastshap包进行支持向量机shap可视化分析,
先导入数据
r
library(e1071)
library(caret)
bc<-read.csv("E:/r/test/demo.csv",sep=',',header=TRUE)
bc <- na.omit(bc)
数据变量很多,我解释几个我等下要用的,HBP:是否发生高血压,结局指标,AGE:年龄,是我们的协变量,BMI肥胖指数,FEV1肺活量指标,WEIGHT体重,"SBP","DBP":收缩压和舒张压。公众号回复:体检数据,可以获得数据。
有些变量用不到,我先精简一下,把结局变量变成因子,这个很重要。
r
bc<-bc[,c("HBP","BMI","AGE","FEV1","WEIGHT","SBP","DBP","SEX")]
bc$HBP<-as.factor(bc$HBP)
bc$SEX<-as.factor(bc$SEX)接下来就是对数据进行标准化,这样可以消除数据见的差异。
定义一个标准化的小程序
r
f1<-function(x){
return((x-min(x)) / (max(x)-min(x)))
}
bc.scale<-as.data.frame(lapply(bc[2:7],f1))
bc.scale<-cbind(HBP=bc$HBP,SEX=bc$SEX,bc.scale)#分成建模和验证组
r
set.seed(12345)
tr1<- sample(nrow(bc.scale),0.7*nrow(bc.scale))##随机无放抽取
bc_train <- bc.scale[tr1,]#70%数据集
bc_test<- bc.scale[-tr1,]#30%数据集接下来咱们要生成一个支持向量机的模型,这里我就直接上代码了,想具体了解的直接可以看上面的文章。
r
############生成模型
svm <- svm(HBP~.,data=bc.scale, probability = TRUE)接下来咱们导入fastshap包和辅助包fastshap包可以做全局解释和辅助解释,其实就是全部数据和部分数据或者单个数据。我这里只做全局解释,
r
library(magrittr)
library(tidyverse)
library(fastshap)
library(shapviz)使用fastshap包可以做很多模型的shap,做shap可视化的关键就是要定义一个生成预测值概率的函数,
r
pred_wrapper <- function(model,newdata){
newdata$def_pred<-predict(model, newdata=newdata,probability = TRUE)
Pred_Prob <- attr(newdata$def_pred, "probabilities")
def_pred<-as.data.frame(Pred_Prob)
newdata$prob1<-def_pred[,2]
newdata$prob1
}其实就是一个放入模型生成预测值的简单函数,然后咱们还要生成一个没有结局变量的数据矩阵
r
x<-bc_train[,-1]生成以后就是用fastshap包的explain函数来进行计算shap就可以了,使用的是蒙特卡罗算法。Nsim就是蒙特卡罗算法的次数,作者说尽量多点比较好
r
shap <- explain(svm, X = x, pred_wrapper = pred_wrapper, nsim = 10, adjust = TRUE,
shap_only = FALSE)生成以后就用shapviz包来可视化就行
r
shv.global <- shapviz(shap)
sv_importance(shv.global)
也可以做一些变量的相关依赖性分析
r
sv_dependence(shv.global, v = "AGE")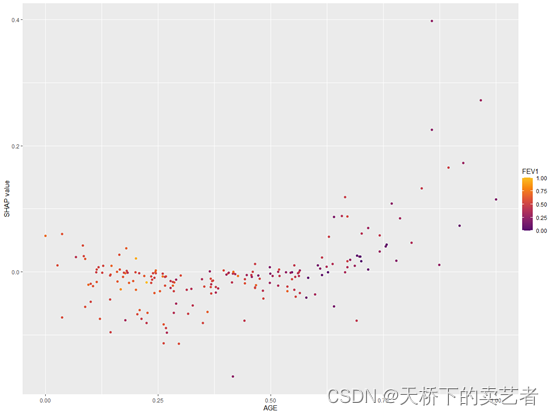
r
sv_dependence(shap.global, v = "SEX")