💡 本系列文章是 DolphinScheduler 由浅入深的教程,涵盖搭建、二开迭代、核心原理解读、运维和管理等一系列内容。适用于想对 DolphinScheduler了解或想要加深理解的读者。
祝开卷有益:)
用过 DolphinScheduler 的小伙伴应该都知道,DolphinScheduler 的依赖任务是被动检测的,下游配置了上游的依赖,下游任务启动的时候,会检测上游任务是否成功,这个过程不是很复杂,但却是比较容易出问题的。

本文先说明了依赖节点删除的影响(背景),最后是巡检任务的逻辑(解决方案)。
感兴趣的小伙伴也可以看看之前的历史文章:
背景:
使用调度的团队越来越多,任务也越来越多,互相依赖的任务也变多了,任务会随着数仓的迭代,进行下线、删除等操作。
如图,工作流① 里面有任务 A,工作流② 里面有任务 dep_A 和 B。
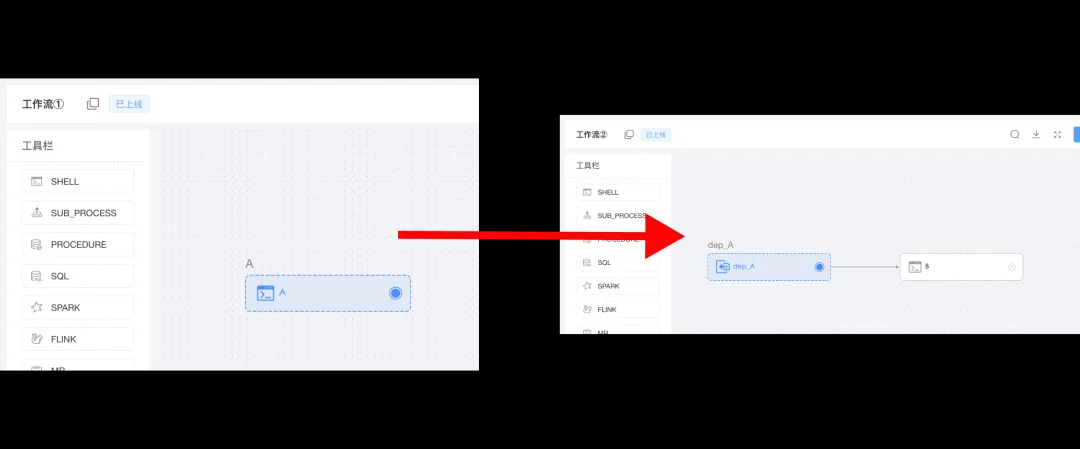
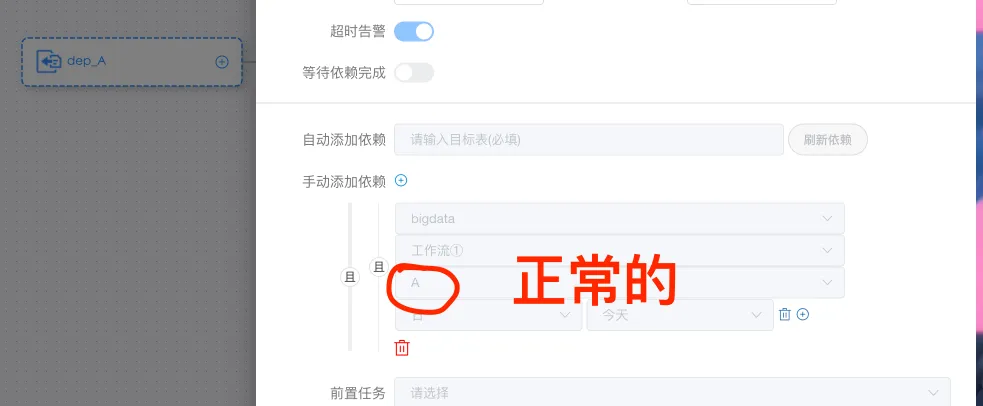
打开依赖节点dep_A,可以看到上游任务是 A,可以正常限时任务名字。
我把任务 A 删掉,如图1-3,打开依赖节点dep_A,就只能看到一个code,不能显示名称了。(其实就是找不到上游任务了)。
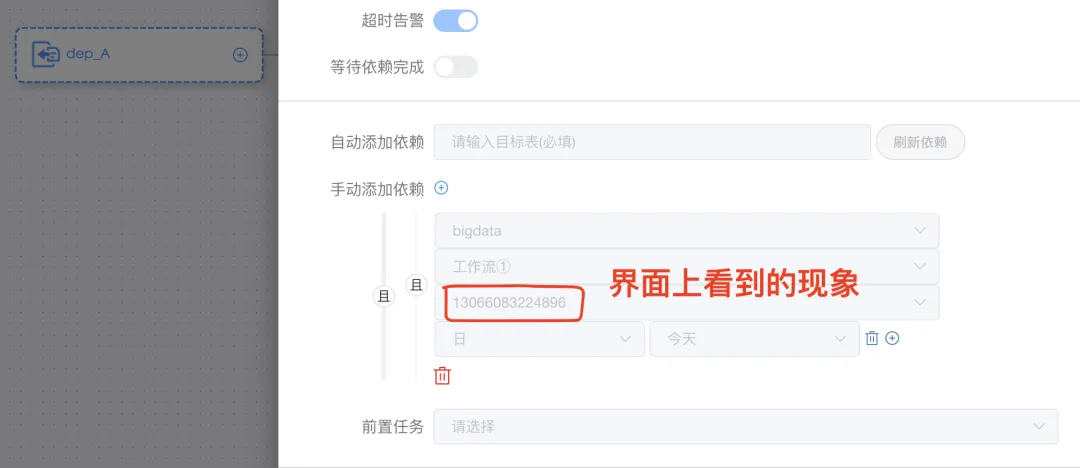
工作流② 后面在运行的时候,依赖节点dep_A,在运行的时候就会一直卡在那里,找不上游任务,因为已经被删了或者被禁用了。
为什么呢?因为依赖(DEPENDE)节点里面配置的是上游任务的projectCode 、definitionCode 、depTaskCode。只要上游任务被禁用、删除、或者复制了一个新的出来,depTaskCode 就会变或者找不到。
依赖节点找不到上游任务是谁,就没办法判断运行状态了,就会一直卡在那里。
解决方案:
回到生产环境,使用调度的团队越来越多,任务也越来越多,互相依赖的任务也变多了,任务会随着数仓的迭代,进行下线、删除等操作。这种依赖缺失的现象就越来越多了,这是用户操作不当导致的重大生产事故,必须要防止这种情况。
解决方案就是新增一个依赖巡检。一段 SQL + 一个告警脚本搞定!
 第一步是先清理调度任务的血缘关系到一张 mysql 表。
第一步是先清理调度任务的血缘关系到一张 mysql 表。
第二步是检测依赖缺失,报警到钉钉群。
先看下 SQL主要逻辑逻辑,清洗调度任务的关系,包括依赖节点,依赖节点是一个json结构的数据,把它解析出来,最后看关联不上的任务,就是缺失依赖的任务,然后告警出来。

①清洗逻辑如下:
脚本放在 GitHub上了,dep_mysql.sql 1
清洗之后,产出了 4 张表
1.t_ds_dag_task_relation_base_data 关系基础数据表
2.t_ds_task_node_base_data 任务基础表,后续会用于 Nebula Graph,这个后面会讲。
3.t_ds_dag_task_relation_dep_data_df 依赖节点关系表,用于后续依赖告警的的主表
4.t_ds_dag_task_relation_data_df 关系最终表,后续会用于 Nebula Graph,这个后面会讲。
②写一个 Python 脚本运行上述 SQL
脚本放在 GitHub上了,run_dep_mysql.py 2
主要是运行第一步的 SQL。
③告警脚本:
脚本放在 GitHub上了,check_dolphin_deps_lost.py 3
主要是拿 t_ds_dag_task_relation_dep_data_df 这个表的上游工作流code、上游任务code 关联 t_ds_task_node_base_data 任务信息表,关联不上的就是被删除了或者修改了,要告警出来,提醒用户。
④告警结果展示!
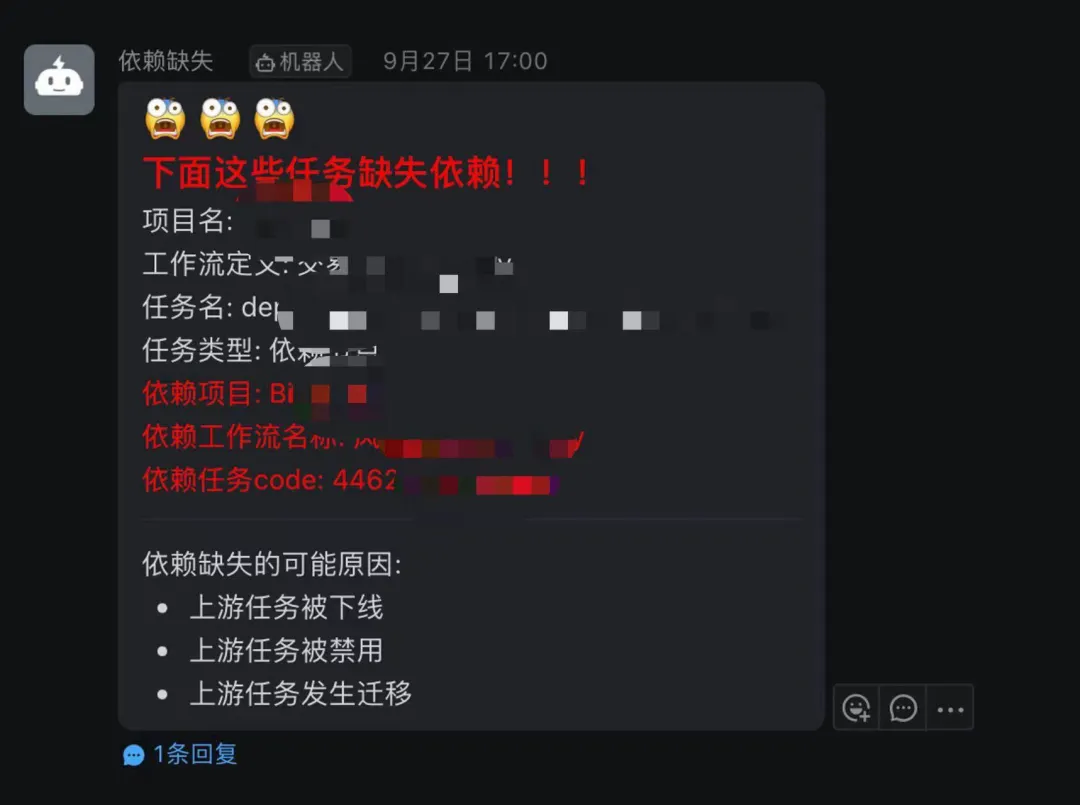 新增了这个依赖巡检之后,用户操作导致的依赖缺失问题被解决了,用户改动任务再也不用担心了!就算操作失误,巡检也会告警出来,提醒用户及时修复掉。
新增了这个依赖巡检之后,用户操作导致的依赖缺失问题被解决了,用户改动任务再也不用担心了!就算操作失误,巡检也会告警出来,提醒用户及时修复掉。
这个 SQL 放在 Mysql 执行速度很快,对主库没什么压力,可以把数据实时同步到 Doris ,再做巡检,也是可以的。
以上就是依赖缺失巡检的全部内容,如果有任何疑问,都可以与我交流,希望可以帮到你,下次见。
参考资料
1
dep_mysql.sql:https://github.com/aikuyun/dolphin\_practices/blob/main/dep\_mysql.sql
2
run_dep_mysql.py:https://github.com/aikuyun/dolphin\_practices/blob/main/run\_dep_mysql.py
3
check_dolphin_deps_lost.py:https://github.com/aikuyun/dolphin\_practices/blob/main/check\_dolphin\_deps\_lost.py
本文由 白鲸开源科技 提供发布支持!