论文:RPG-Palm: Realistic Pseudo-data Generation for Palmprint Recognition(2023.7)
作者:Lei Shen, Jianlong Jin, Ruixin Zhang, Huaen Li, Kai Zhao, Yingyi Zhang, Jingyun Zhang, Shouhong Ding, Yang Zhao, Wei Jia
链接:https://arxiv.org/abs/2307.14016
代码:暂无
文章目录
- 1、算法概述
- 2、背景知识
- 3、RPG-Palm细节
-
- [3.1 Conditional Modulation Palmprint Generator](#3.1 Conditional Modulation Palmprint Generator)
- [3.2 Palmprint Encoder](#3.2 Palmprint Encoder)
- [3.3 ID-aware Loss](#3.3 ID-aware Loss)
- [3.4 Improved Bézier Palm Creases Synthesis](#3.4 Improved Bézier Palm Creases Synthesis)
- 4、实验
1、算法概述
该文是腾讯在2022年提出的BézierPalm的升级版,利用BézierPalm生成的掌纹褶皱图作为条件,结合作者自己设计的generation model和ID-aware loss,达到了可以同时扩展掌纹数据的类间多样性和类内多样性。
2、背景知识
识别领域的数据生成算法,在人脸识别领域,有利用人脸属性、人脸结构及3D face来生成,对于指纹识别,也有手工制作或基于学习的方法来生成逼真的指纹图片。在掌纹识别任务中,BézierPalm用Bezier曲线模拟掌纹的褶皱;PalmGAN利用CycleGAN使得普通掌纹和多光谱掌纹之间转换样式提升了掌纹的跨越识别能力。但是PalmGAN这个方法不能创造新的掌纹id,而BézierPalm生成的掌纹褶皱图片(一个id可生成多张图片)与真正的掌纹图片有着比较明显的风格差异。所以作者想到利用BézierPalm生成的掌纹褶皱图片作为GAN的条件,结合作者自己设计的generation model和ID-aware loss,该方法可以同时扩展掌纹数据的类间多样性和类内多样性。于是达到生成虚拟的掌纹数据集目的,且这个数据集包含多个虚拟的id,一个id包含多张图片。
3、RPG-Palm细节
RPG-Palm整个框架包含训练和推理阶段,如下图所示:
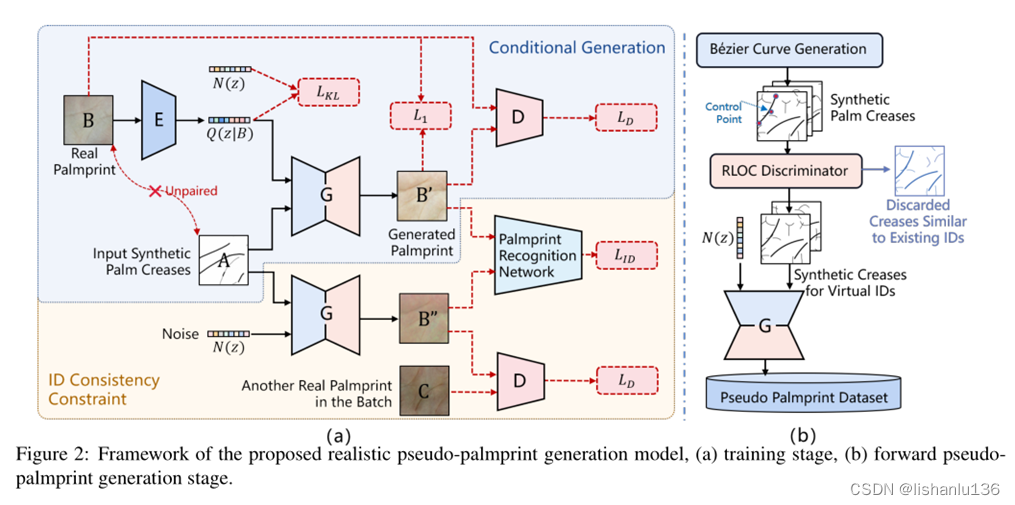
注:读过BicycleGAN论文的看到这个框图就有点熟悉了,作者是在BicycleGAN的基础上改进的,下图是BicycleGAN框图作为对比。
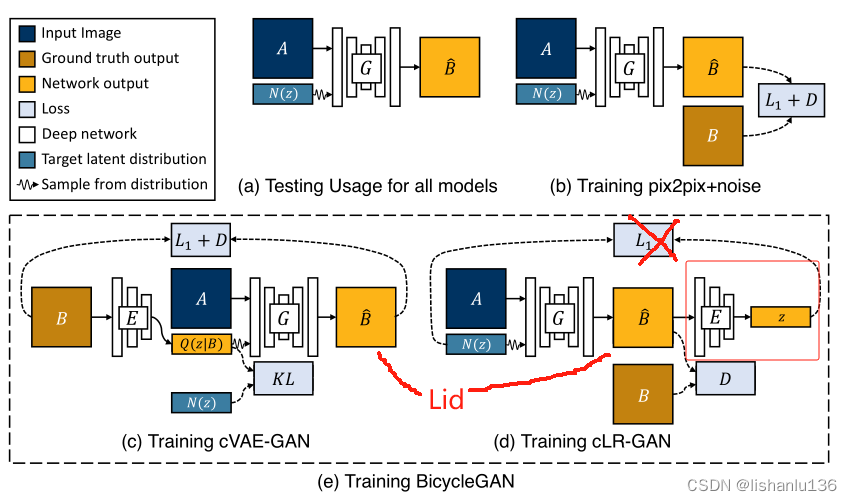
仔细对比可以看出,本文框图中左上蓝色部分和BicycleGAN的Training cVAE-GAN一模一样,本文主要改进点在框图右下黄色部分,即对应BicycleGAN的Training cLR-GAN部分,本文作者将BicycleGAN的Training cLR-GAN中我画的红框部分去掉,并且去掉了后续的L1损失,新增了两个生成图像的Lid损失用于规范生成图像的id一致性。后面实验部分,作者所使用的参数也是依据BicycleGAN,在它的基础上新增了一个Lid损失的权重参数。
3.1 Conditional Modulation Palmprint Generator
生成器G以高斯噪声向量作为输入,以BézierPalm方法合成的掌纹折线图A作为条件,生成掌纹图片B'。生成器G结构类似于常见的图像生成器结构UNet,其详细结构如下图a所示,为了生成多样化的结果,引入了条件自适应实例规范化模块(CAdaIN),对每个Down-Block和Up-Block生成的细节进行调制。
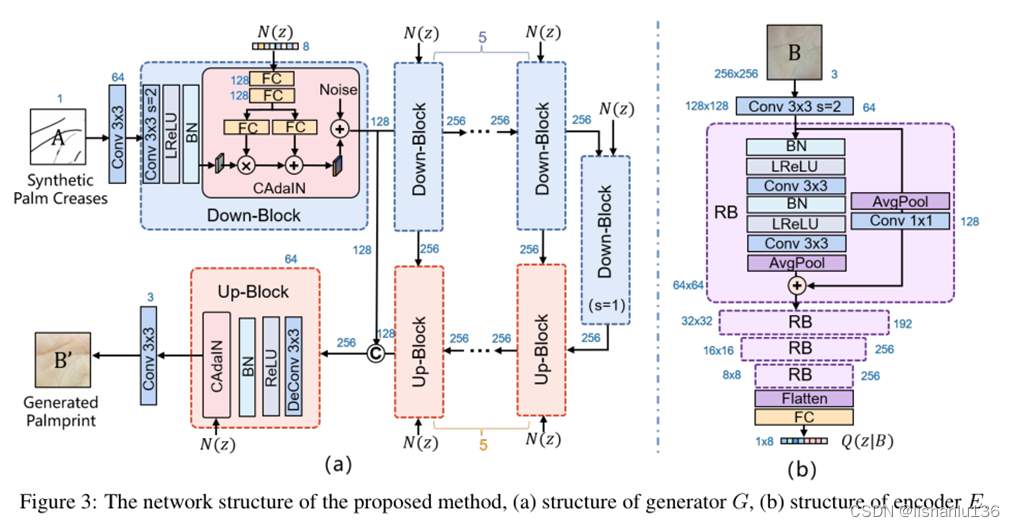
CAdaIN模块可用以下公式表示:
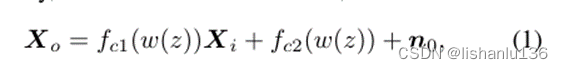
其中Xi和X0代表CAdaIN模块的输入和输出特征,fc1和fc2代表两个FC层。通过使用随机噪声编码的潜在控制向量,实现了系统的控制CAdaIN可以调节特征产生不同的分布,从而产生多样化的掌纹图像。此外,为了进一步提高多样性,在调制特征中加入与特征图具有相同空间分辨率的随机噪声n0(也就是图中的Noise),以注入更多的随机性。
为了能产生逼真的生成效果,采用L1损失和对抗损失LD来更新生成器G,公式如下:
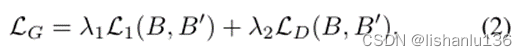
L1是常见的逐像素损失,它保证生成的掌纹图像与真实掌纹在数值上的相似性,但是由于生成的掌纹图像B'是以生成的掌纹褶皱图A为条件,而A与B其实不是"配对"的,即不是同一个id,所以过于强烈的像素约束可能会导致错误的过拟合到B的细节上。所以作者增加对抗损失LD用来放松约束,约束B和B'之间的语义相似度,LD的损失和PatchGAN的方法类似。
3.2 Palmprint Encoder
编码器E用于将掌纹图像B映射到高斯噪声域Q(z|B)。编码器结构如上图b结构,它是Resnet结构,输入为256x256,经过几个残差模块后分辨率下降到16x16,后面接FC,它被用来估计均值uQ和方差σQ2,最后,从高斯空间N(uQ,σQ2)中采样噪声向量Q(z|B)。
在训练过程中,作者在Q(z|B)~ N(uQ,σQ2)和噪声向量N(z)~N(0,1)之间保持KL散度,使得编码器E的目标域近似逼近标准正态分布。其损失函数可以用如下公式表示:
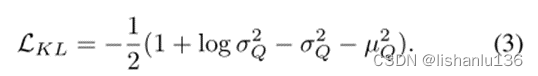
本文将编码器E和生成器G结合起来,从未配对的训练数据中学习域到域的映射,而不是使用完全监督的方式。首先,这种结构可以避免对人工标注配对数据的依赖。其次,条件双向域到域映射既能再现随机逼真的图像,又能保持手掌折痕条件的信息。
3.3 ID-aware Loss
对于训练识别模型来说,生成的掌纹不仅需要多样化,而且需要带有预先定义的id身份信息。对于相同的输入条件A,生成的掌纹图片应该具有相同的id信息,即应该具有相同的掌纹折痕。因此,增加了一个ID感知损失LID来约束生成器。如Fig2(a)中所示,生成器G通过利用相同的输入条件图片A和噪声N(z)生成掌纹图像B",理论上,B'与B"应该带有相同的id信息。所以用ID感知损失LID表示两者的id一致性损失。公式为:
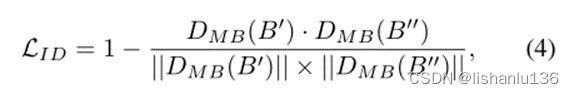
公式中"."代表向量点积,DMB是采用MobileFaceNet结构得到的预训练掌纹识别模型提取的512维特征向量。即LID计算同一ID下生成的两张图像的提取特征之间的余弦相似度。有了ID感知损失,增加生成器的随机性和多样性便不会破坏类内ID的一致性。
总的训练损失如下:
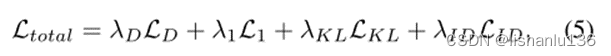
3.4 Improved Bézier Palm Creases Synthesis
在推理阶段,仅使用生成器G利用生成的手掌折痕A中生成掌纹图像,如Fig2(b)所示。受BézierPalm的启发,作者也采用两级bezier曲线合成了包含三条主线和随机皱纹线的手掌折痕图像用于生成大量的虚拟id掌纹图像。但是作者发现随机调整bezier曲线可能导致一些随机生成的折痕的布局与真实掌纹的布局有很大的不同。如下图所示:
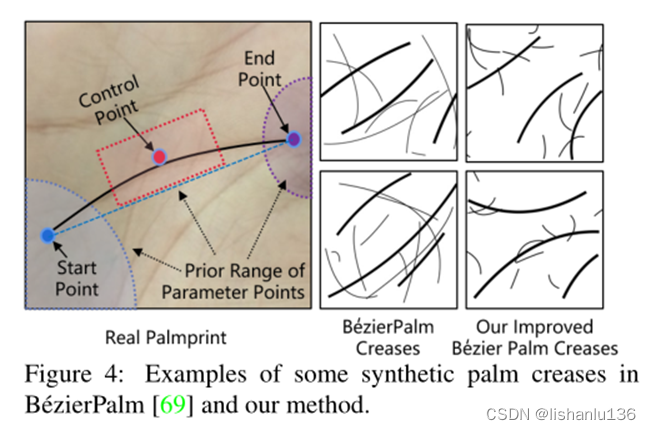
所以,本文将从以下三个点来改进BézierPalm生成的掌纹折痕。
首先,作者根据真实掌纹情况调整三条主线参数点(即起点、控制点和终点)的粗略范围。使合成主线的布局更接近真实掌纹主线布局。
其次,对合成规则进行调整,生成更多长度适中、分布均匀的皱纹线。
第三,加入基于RLOC的相似性约束,使不同id的主线具有充分的可区分性。RLOC是一种经典的掌纹识别方法,它可以测量两个折痕图像的相似度。为了避免为不同的id生成非常相似的主线,我们过滤掉了一些超过RLOC类间相似性阈值的折痕图像。
最后,将改进后的随机bézier曲线输入到生成器G中,得到相应的掌纹图像。
4、实验
ImageNet ILSVRC2012上分类实验
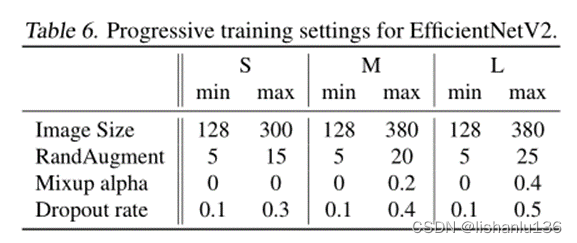
网络训练采用渐进式学习,设置如下:
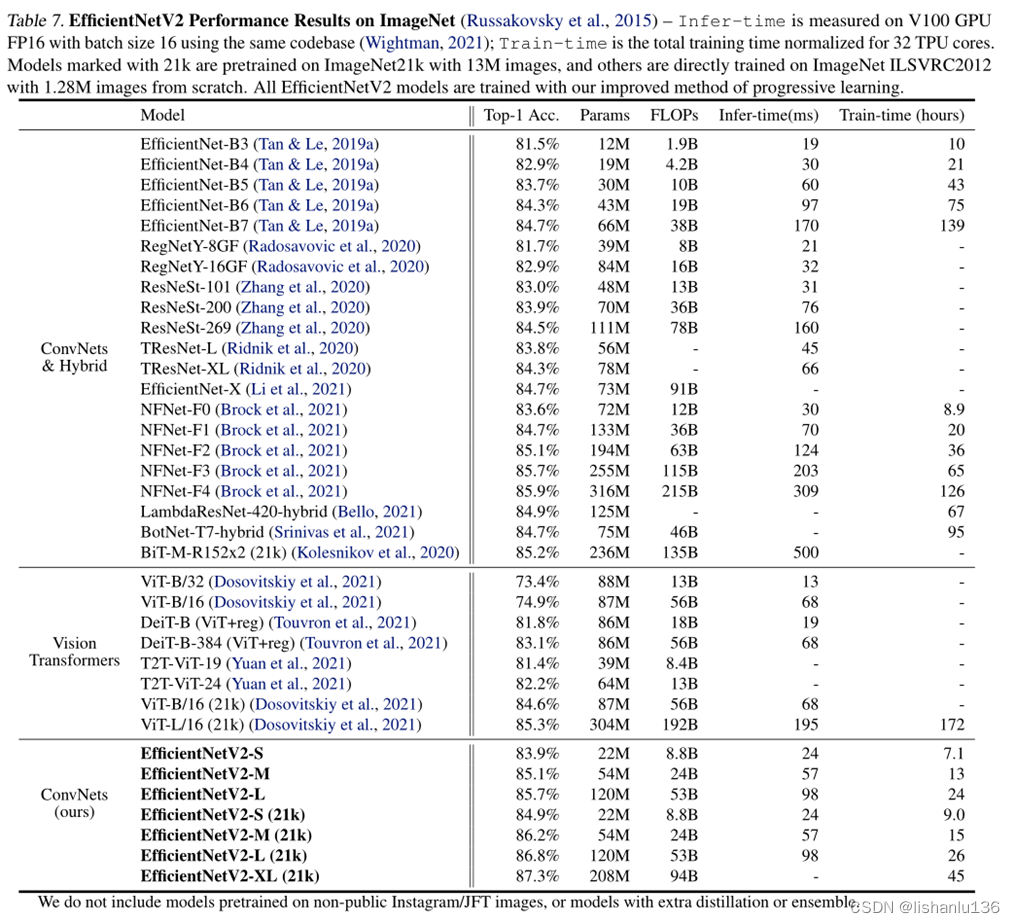
得到的分类结果如下:
消融实验:略