Paper![]() https://arxiv.org/pdf/2501.04699
https://arxiv.org/pdf/2501.04699
Code (coming soon)
目录
EditAR是一个统一的自回归框架,用于各种条件图像生成任务------图像编辑、深度到图像、边缘到图像、分割到图像。
next-token预测的功效尚未被证明用于图像编辑。
EditAR主要构建在Llamagen的基础上,这是一种基于Llama2架构的文本到图像自回归模型。然而,由于缺少条件图像输入,Llamagen不支持图像处理或转换等任务。
贡献:
(1)我们引入了一个新的自回归框架EditAR,它在各种图像处理和图像翻译任务上进行了联合训练,并展示了建立统一的条件图像生成模型的潜力。
(2)在自回归模型的学习中引入蒸馏损失来增强语义。
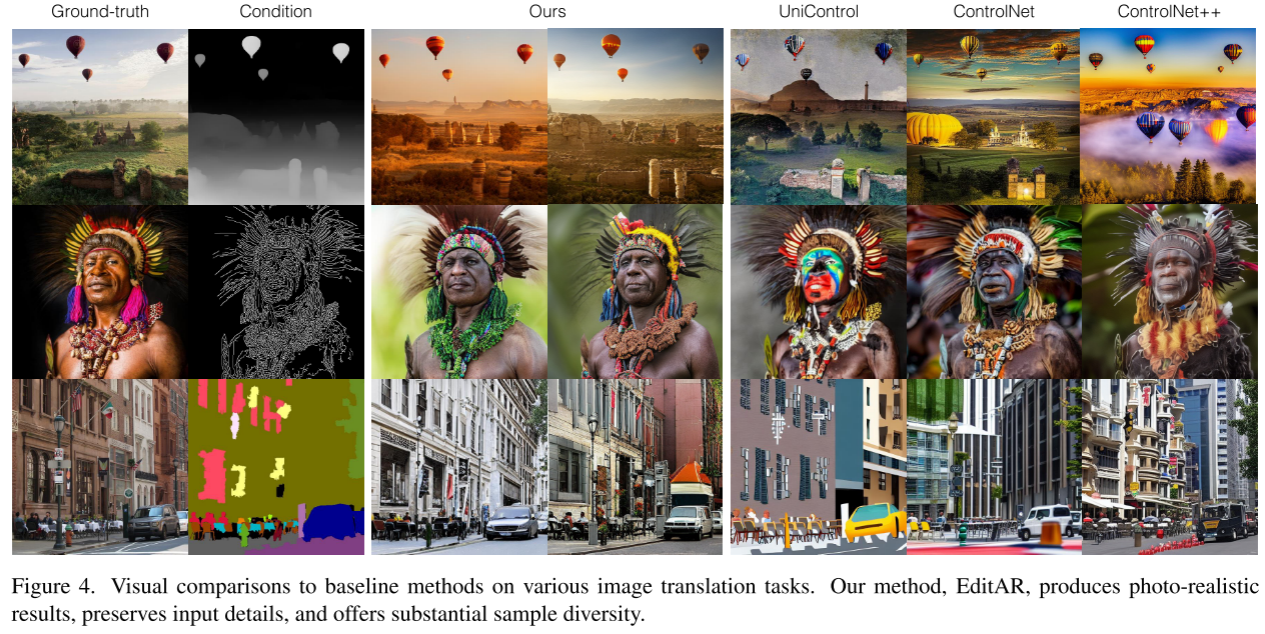
(3)实验表明,该方法在纹理操作、对象替换、对象移除、局部编辑、canny到image、depth到image和segmentation到image等任务上表现出了较强的性能。
方法
一般情况下,自回归模型将文本到图像生成作为序列到序列建模任务。一种常见的方法包括两个主要组件:将图像转换为离散令牌的VQAutoencoder和对这些令牌的分类分布进行建模的自回归Transformer。
EditAR:
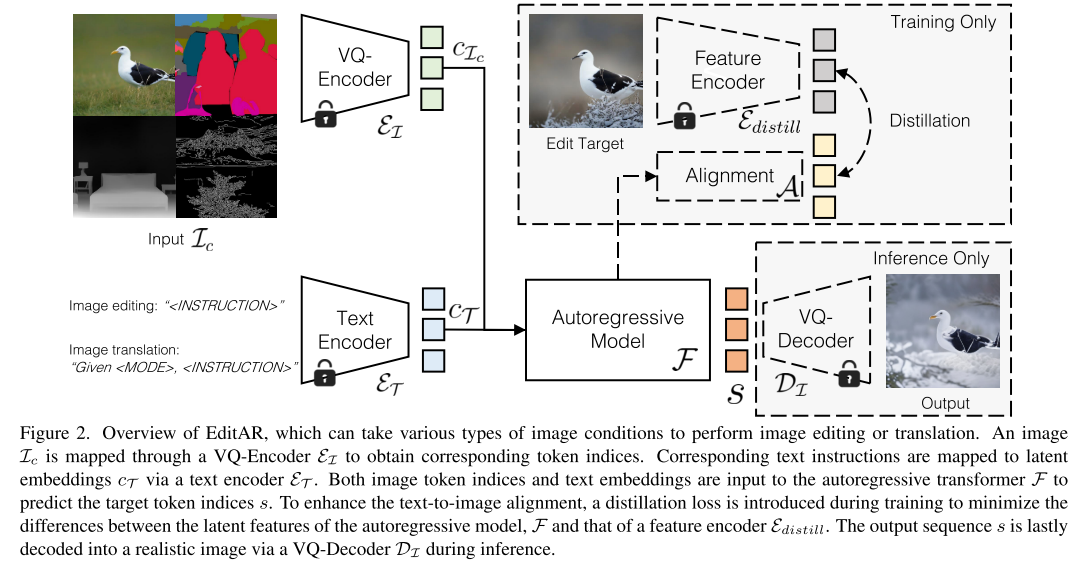
图2:可以采用各种类型的图像条件来执行图像编辑或变换。图像标记索引和文本嵌入都被输入到自回归Transformer F以预测目标标记索引s。为了增强文本到图像的对齐,在训练期间引入蒸馏损失。输出序列s最后在推理期间经由VQ解码器DI解码成真实图像。
**描述图像模态:**通过修改文本输入的措辞,例如,从深度图生成图像,使用"给定深度,按照指令生成图像:<INSTRUCTION>",指令是对生成图像的内容的描述。
蒸馏: 从DINOv2视觉特征编码器中引入了蒸馏损失。对齐网络A由单个卷积层组成,用于将自回归模型F(·)的嵌入空间的维度与基础模型的嵌入空间的维度相匹配。
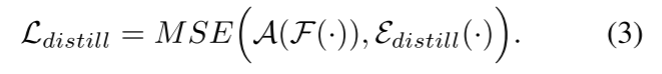
对于F和Edistill,从最后一个隐藏层提取的特征用于计算此损失。从经验上讲,我们发现这种设计可以改善文本到图像的对齐。
**训练和推理:**L_CE是用于训练下一个令牌预测模型的交叉熵损失。
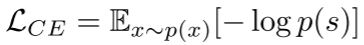
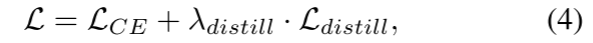
在5%的训练样本中设置, 在另外5%的训练样本中设置
, 在最后5%的训练样本中设置
,
。在推理时,只给出
和
作为输入,并顺序预测集合s。
在推理过程中使用无分类器指导:
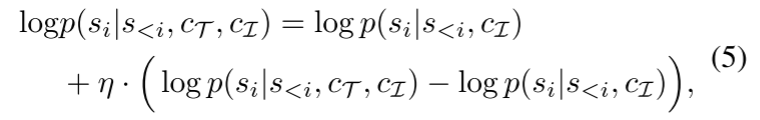
实验
数据集:
我们使用来自SEED-Data-Edit-Unsplash的1.5M个示例,用于一系列图像编辑任务,包括修改样式,对象,颜色和材料。为了进一步支持对象添加和删除等编辑操作,我们添加了具有180万个示例的PIPE数据集。
在训练过程中,我们以50%的概率随机翻转每一对,并相应地将编辑指令从"添加"调整为"删除"。
对于图像转换任务,我们遵循ControlNet++ ,使用COCOStuff进行分割掩模到图像的转换,MultiGen-20M用于canny边缘和深度到图像任务。