在接触过大量的传统关系型数据库后你可能会有一些新的问题: 无法整理成表格的海量数据该如何储存? 在数据非常稀疏的情况下也必须将数据存储成关系型数据库吗? 除了关系型数据库我们是否还有别的选择以应对Web2.0时代的海量数据?
如果你也曾经想到过这些问题, 那么HBase将是其中的一个答案, 它是非常经典的列式存储数据库. 本文首先介绍HBase的由来以及其与关系数据库的区别, 其次介绍其访问接口、数据模型、实现原理和运行机制. 即便之前没有接触过HBase的相关知识也不影响阅读该文章.

如果想了解其他的非关系型数据库也可以查看我的博客文章:NoSQL数据库
概述
HBase是谷歌公司BigTable的开源实现. 而BigTable是一个分布式存储系统, 使用谷歌分布式文件系统GFS作为底层存储, 主要用来存储非结构化和半结构化的松散数据. HBase的目标是处理非常庞大的表, 可以通过水平扩展的方式利用廉价计算机集群处理超过10亿行数据和百万列元素组成的数据表.
GFS、HDFS、BigTable、HBase的关系:
HDFS是GFS的开源实现. HBase是BigTable的开源实现.
GFS是BigTable的底层文件系统, BigTable的数据存储在GFS上.
HDFS是HBase的底层存储方式. 虽然HBase可以使用本地文件系统, 但是为了提高数据可靠性一般还是会选择HDFS作为底层存储.
HBase和BigTable底层技术对应关系
| 项目 | BigTable | HBase |
|---|---|---|
| 文件存储系统 | GFS | HDFS |
| 海量数据处理系统 | MapReduce | Hadoop MapReduce |
| 协同服务系统 | Chubby | Zookeeper |
与传统的数据库相比主要区别在于:
- 数据类型: 关系数据库采用关系模型, HBase则采用更加简单的数据模型--将数据存储为未经解释的字符串.
- 数据操作: 关系数据库通常包括丰富的操作, 涉及复杂的多表连接. HBase则不存在复杂的多表关系, 只有简单的增删查改.
- 存储模式: 关系数据库是基于行模式存储的, 元组或行被连续地存储在磁盘中. HBase是基于列存储的.
- 数据索引: 关系数据库可以针对不同列构建复杂的多个索引以提高访问效率. HBase则只有一个索引--行键.
- 数据维护: 关系数据库中更新操作会用新值替换旧值. HBase则会保留旧数据, 仅仅生成一个新的版本.
- 可伸缩性: 关系数据库很难进行横向扩展, 纵向扩展的空间也比较有限. HBase作为分布式数据库可以轻易地通过增加集群中的机器数量来达到性能的伸缩.
访问接口
HBase提供了多种访问方式, 不同的方式适用于不同的场景.
| 类型 | 特点 | 场合 |
|---|---|---|
| Native Java API | 最常规高效的访问方式 | 适合Hadoop MapReduce作业并行批处理HBase表数据 |
| HBase Shell | HBase的命令行工具, 最简单的接口 | 适合HBase管理 |
| Thrift Gateway | 利用Thrift序列化技术, 支持C++, PHP, Python等多种语言 | 适合其他异构系统访问HBase |
| REST Gateway | 解除语言限制 | 支持REST风格的HTTP API访问HBase |
| Pig | 使用Pig Latin流式编程语言来处理HBase的数据 | 适合做数据统计 |
| Hive | 简单 | 可以用类似SQL语言的方式来访问 |
数据模型
数据模型是一个数据库产品的核心, 接下来将介绍HBase列族数据模型并阐述HBase数据库的概念视图和物理视图的差异.
相关概念
HBase实际上是一个稀疏、多维、持久化存储的映射表, 采用行键、列族、列限定符和时间戳进行索引, 每个值都是未经解释的字节数组byte\[\].
表
表由行和列组成, 列被分为若干个列族
行
每个HBase表都由若干行组成, 每个行由行键(Row Key)进行标识.
访问表中的行有3种方式:
- 通过单个行键访问
- 通过行键区间访问
- 全表扫描
行键可以是任意字符串(最大长度64KB, 实际应用中一般为10-100字节). 在HBase内部将行键保存为 字节数组, 按照行键的 字典序 排序. 所以在设计行键时可以充分考虑该特性, 将需要一起读的行存储在一起.
列族
HBase中一个表被分为多个列族, 列族是最基本的访问控制单元. 表中的每个列都必须属于一个列族, 我们可以将其理解为 把列按照需求分到不同的组中, 就如同整理文件到不同的文件夹中去.
为什么要这么做?
- 控制权限. 我们通过列族可以实现权限的控制, 例如某些应用只可以修改某些数据.
- 获得更高的压缩率. 同一个列族中的所有数据都属于同一种数据类型, 着通常意味着更高的压缩率.
缺点
- 列族数量不可太多. HBase的一些缺陷导致列族只能有几十个.
- 不能频繁修改.
列限定符
列族中的数据是通过列限定符来定位的. 列限定符无需事先定义, 也没有数据类型, 总被视为字节数组byte\[\].
单元格
在HBase的表中, 通过行、列和列限定符可以确定一个"单元格(Cell)". 单元格中存储的数据没有数据类型, 总被视为字节数组byte\[\].
每个单元格中可以保留一个数据的多个版本, 每个版本对应一个不同的时间戳.
时间戳
每个单元格都保留了同一个数据的多个版本, 这些版本采用时间戳进行索引. 事实上每一次对于一个单元格执行的操作(增删改)时, HBase都会自动生成并存储一个时间戳, 通常这个时间戳是64位整型. 当然, 这个时间戳也可以由用户自己赋值, 用以避免应用程序中出现数据版本冲突.
一个单元格中的不同版本的数据是以时间戳降序排序的, 以便于读到最新的数据版本.
我认为下面的一张图可以很好地表述上面的5个概念. 类比于关系数据库, 行键就是主键行号, 列限定符就是列名, 列族就是列名组成小组的组名, 单元格就是具体存储数据的格子, 时间戳则标识了一个单元格中不同时间的数据版本.
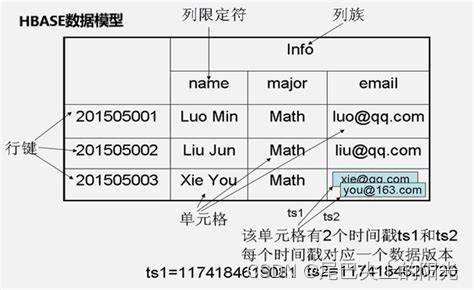
一个HBase数据模型的实例
数据坐标
相较于我们所熟悉的关系数据库, HBase无法仅使用行号和列号确定一个数据. 在HBase中, 我们需要: 行键、列族、列限定符和时间戳 这4个东西来确定一个数据.
行键, 列族, 列限定符, 时间戳被称为是HBase的坐标, 可以通过这个坐标来直接访问数据. 在这种层面上讲, HBase也可以被视为一个键值数据库.
概念视图
在HBase的概念视图中, 一个表是一个稀疏、多维的映射关系.
| 时间戳 | 列族 contents | 列族 anchor | |
|---|---|---|---|
| com.cnn.www | t5 | anchor:cnnsi.com="CNN" | |
| com.cnn.www | t4 | anchor:my.look.ca="CNN.com" | |
| com.cnn.www | t3 | contents:html="xxxx" | |
| com.cnn.www | t2 | contents:html="xxxx" | |
| com.cnn.www | t1 | contents:html="xxxx" |
上表存储了一个网页的页面内容(html代码)和一些反向连接. contents中存储的是网页内容, anchor中存储的是反向连接. 不过有几个地方需要额外注意:
- 行键. 行键采用的是url的倒序, 因为HBase的行键采用字典倒序排列, 这样可以使得相同的网页都保存在相邻的位置
- 每个行都包含了相同的列族, 即便有些列族不需要存储数据(为空)
物理视图
列族 contents
| 时间戳 | 列族 contents | |
|---|---|---|
| com.cnn.www | t3 | contents:html="xxxx" |
| com.cnn.www | t2 | contents:html="xxxx" |
| com.cnn.www | t1 | contents:html="xxxx" |
列族 anchor
| 时间戳 | 列族 anchor | |
|---|---|---|
| com.cnn.www | t5 | anchor:cnnsi.com="CNN" |
| com.cnn.www | t4 | anchor:my.look.ca="CNN.com" |
我们可以轻易发现, 在物理的存储层面上来看HBase采用了基于列的存储方式, 而不是传统关系数据库那样基于行来存储. 这也是HBase与传统关系数据库间的重要区别.
与概念视图的不同
- 列族的分开存放. 可以看到contents和anchor两个列族被分开存放.
- 不存在空值. 在概念视图中有些列是空的, 但是在物理视图中这些值根本不会被存储.
总结
行式数据库使用 NSM(N-ary Storage Model) 存储模型, 将一个元组(或行)连续地存储在磁盘页中. 数据被一行一行地储存, 写完第一行再写第二行. 在读取数据时需要从磁盘中顺序扫描每个元组的完整内容. 显然, 如果每个元组只有少量属性的值对查询有用时, NSM模型会浪费许多磁盘空间.
列式数据库采用 DSM(Decomposition Storage Model) 存储模型, 将关系进行垂直分解, 以列为单位存储, 每个列单独存储. 该方法最小化了无用的I/O.
行式存储主要适合于小批量的数据处理, 比如联机事务处理. 列式数据库主要适用于批量数据处理和即席查询(Ad-Hoc Query). 列式数据库的优点是: 降低I/O开销, 支持大量用户并发查询, 数据处理速度比传统方法快100倍, 并且具有更高的数据压缩比.
如果严格从关系数据库的角度来看, HBase并不是一个列式存储的数据库, 毕竟它是以列族为单位进行分解的, 而不是每个列都单独存储. 但是HBase借鉴和利用了磁盘上这种列存的格式, 所以某种角度上来说它可以被视为列式数据库. 常用的商业化列式数据库有: Sybase IQ, Verticad等.
如果想要更深入地了解HBase的实现原理, 架构以及运行机制, 可以阅读我的博客: 分布式数据库HBase