全栈工程师开发手册 (作者:栾鹏)
全栈工程师开发手册 (作者:栾鹏)
前言
开源地址:https://github.com/tencentmusic/cube-studio
cube studio 腾讯开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,sso单点登录,支持在线镜像调试,在线ide开发,数据集管理,图文音标注和自动化标注,任务模板自定义,拖拉拽任务流,模型分布式多机多卡训练,超参搜索,模型管理,推理服务弹性伸缩,支持ml/tf/pytorch/onnx/tensorrt/llm模型0代码服务发布,以及配套资源监控和算力,存储资源管理。支持机器学习,深度学习,大模型 开发训练推理发布全链路。支持元数据管理,维表,指标,sqllab,数据etl等数据中台对接功能。支持多集群,边缘集群,serverless集群方式部署。支持计量计费,资源额度限制,支持vgpu,rdma,国产gpu,arm64架构。
aihub模型市场:支持AI hub模型市场,支持400+开源模型应用一键开发,一键微调,一键部署。
gpt大模型:支持40+开源大模型部署一键部署,支持ray,volcano,spark等分布式计算框架,支持tf,pytorch,mxnet,mpi,paddle,mindspre分布式多机多卡训练框架,支持deepspeed,colossalai,horovod分布式加速框架,支持llama chatglm baichuan qwen系列大模型微调。支持llama-factory 100+llm微调,支持大模型vllm推理加速,支持智能体私有知识库,智能机器人。
Cube Studio
整体架构
cube studio是 腾讯音乐 开源的一站式云原生机器学习平台,目前主要包含
| 模块分组 | 功能 | 功能明细 |
|---|---|---|
| 基础能力 | 项目组管理 | * AI平台需要通过项目划分, * 支持配置相应项目组用户的权限, * 任务/服务的挂载,资源组,集群,服务代理, * ++项目组内角色应用++ |
| 基础能力 | 网络 | * 支持非80端口, * 支持公网/域名, * 支持反向代理和内网穿透方式访问, * ++支持https++ |
| 基础能力 | 用户管理 角色管理/权限管理 | * 管理平台用户的基本信息,组织架构,支持账号密码,rbac权限体系。 * ++增加修改和删除,清理等操作的历史记录++ |
| 基础能力 | 计量计费功能 | * 1、支持平台资源限制的分配和查看;项目组资源限制,租户资源限制、任务资源限制,项目组下个人的资源限制,包括开发资源,训练资源、推理资源等。 额度限制限制在notebook,docker构建,pipeline,超参搜索,内部服务,推理服务中的生效。限制支持单任务,并行任务总和和历史任务总和等方法 * 2、提供统一的开发、训练、推理服务资源监控,从租户、项目、任务角度分析模型资源分配及使用情况。 * 3、支持自定义计费模式,通过计量结果自定义获取计费值 |
| 基础能力 | SSO单点登录 | * 账号密码注册自动登录, * ++支持对接公司账号体系AUTH_OID/AUTH_LDAP/AUTH_REMOTE_USER等登录注册方式,++ * ++支持消息推送。++ * ++增加登录验证,强密码,远程用户,登录频率限制,密码密文传输等++ |
| 基础能力 | 支持多种算力 | * 提供多种规格的资源支持不同的使用场景,cpu/gpu等 支持T4/V100/A100等多种卡型, * ++支持arm64芯片,++ * ++支持vgpu等模式。++ * ++支持国产gpu,支持海光gpu,海飞科dcu,华为npu,++ * ++支持rdma调度,mellanox。++ * ++支持gpu禁用模型,共享模式,独占模式++ |
| 基础能力 | 多资源组/多集群 | * 支持划分多资源组, * 支持ipvs的k8s网络模式, * ++支持多k8s集群,++ * ++支持containerd容器运行态++ |
| 基础能力 | 边缘集群 | * ++支持边缘集群模式,支持边缘节点开发,训练,推理++ |
| 基础能力 | serverless集群模式 | * ++支持腾讯云serverless集群模式,(notebook,pipeline,推理服务模块支持)++ * ++阿里云serverless集群模式(notebook,pipeline,推理服务模块支持)++ |
| 基础能力 | 数据库存储 | * 支持外部mysql作为元数据库 * ++支持外部postgres作为元数据库++ |
| 基础能力 | 存储盘管理 | * ++支持web界面添加存储盘,支持项目组绑定,notebook pipeline 推理服务,直接在pod中挂载外部分布式存储。++ * ++支持nfs,cfs,oss,nas,cos,glusterfs,cephfs,s3/minio++ |
| 基础能力 | 国际化能力 | * ++mlops支持配置多语言配置,目前支持中英文++ |
| 数据管理 | 数据地图 | * 元数据库表管理,指标,维表 |
| 数据管理 | 数据计算 | * sqllab交互查询,支持mysql,postgresql等计算引擎 |
| 数据管理 | ETL编排 | * 数据ETL任务流编排,任务管理等对接公司数据中台相应计算/调度引擎 |
| 数据管理 | 数据集管理 | * 允许用户随时上传样本集(图片、音频、文本等), * ++支持sdk进行数据集对接,++ * ++支持数据集一键探索功能++ |
| 数据管理 | 数据标注 | * ++支持标注平台,图/文/音/多模态各类型标注能力,++ * ++对接一站式机器学习平台,支持自动化标注(需购买aihub):++ * ++支持目标识别,目标边界识别,目标遮罩识别,图片分类,图片描述,ocr,关键点检测。支持大模型自动化标注:文本分类,文本翻译,命名实体识别,阅读理解,问答,摘要提取。++ |
| 开发环境 | 镜像功能 | * 镜像仓库/镜像管理/在线构建镜像。同时提供平台所有镜像,包括模板镜像/服务镜像/notebook镜像/gpu基础环境的构建方法和构建后镜像, * ++支持dockerfile在线构建++ * ++支持同一仓库多个秘钥配置++ |
| 开发环境 | notebook | * 支持基于开源的Jupyterlab/vscode,提供在线的交互式开发调试工具; * 提供多种可选环境ide和开发示例,支持资源类型选择 支持大数据版本,机器学习版本,深度学习版本 * ++大数据版本支持用户信息和内网spark链接++ * 支持ssh remote与notebook对接远程开发,方便快速将本地代码提交到平台的训练环境。 * ++ssh隧道代理,单端口开放++ * ++支持matlab,Rstudio等在线ide++ * ++支持gpu,cpu,内存,监控,支持git交互++ * ++支持自定义notebook镜像,便于封装公司自己的notebook++ * ++多环境notebook,支持R语言/julia语言/python2.7/python3.6/python3.7/python3.8/python3.9/python3.10环境和cube-studio专有环境++ * ++支持tensorboard任务可视化++ * ++notebook支持环境镜像保存++ * ++jupyter支持密码保护++ * ++notebook支持整卡占用,虚拟卡占用,gpu共享占用++ * 支持notebook启动自动初始化环境 |
| 模型训练 | 拖拉拽任务流编排调试 | * 提供拖拽式交互开发环境,支持开发者以拖拽的方式完成业务逻辑的PIPLINE; * 支持单任务调试, * 训练支持多种资源规格(CPU、GPU等),支持卡型的选择,超时重试等。 * ++分布式任务模板支持单任务调试用户镜像而非模板镜像++ * ++分布式任务模板支持gpu型号透传,rdma高速通信,拉取秘钥透传++ * pipeline调试,支持定时调度,补录,并发限制,超时,实例依赖等, * 任务管理, * workflow实例管理, * 资源监控, * ++支持任务输入输出,++ * ++任务流全局变量,++ * ++文本/图片/echart结果可视化,++ * ++支持workflow暂停和恢复。++ * ++支持单任务和pipeline运行中任务监听端口提供运行中服务监听能力++ * ++任务流支持任务推荐++ |
| 模型训练 | 主流功能算子 | 基础算子: * 自定义镜像, * ++逻辑节点,++ * ++python++ * 数据同步: * 数据集导入, * datax, * 模型导入 * 数据处理工具: * hadoop/spark作业提交, * volcanojob/ray分布式数据处理, * sparkjob * 特征处理: * -数据合并,包含union、join操作 * -去除重复样本 * -数据变换,包括boxcox转换、二值化、数据类型转换、dct变换、根据函数转换、ma移动平均、多项式展开 * -非数值型变量处理,包括hash、根据统计量转换、one-hot * -异常值检测 * -获取变量的统计量 * -去除值过于单一的变量 * -删除缺失率过高的值 * -删除缺失率过高的值 * -填充缺失值 * -数据离散化,等宽、等频、聚类离散化 * -标准化、正则化、归一化,有最大绝对值归一化、最大最小归一化、z_score标准化 * -索引处理,包含增加索引、索引转列、列索引重命名 * -排序 * -执行sql * -hadamard乘积 * -特征组合,用于衍生特征 * -降维,包括pca降维和卡方降维 * -特征重要性,通过随机森林、逻辑回归、xgboost等模型计算特征重要性,可计算特征的iv值、互信息值、方差等 * -特征向量间的相关性计算 * -数据拆分,包括列内拆分、列间拆分、行间拆分、svd奇异值分解 * -采样,包括随机采样、分层采样、过采样、欠采样 * 传统机器学习: * ray-sklearn分布式, * xgb单机训练推理 * 传统机器学习算法: * ar/arima时间序列算法/random-forest/random-forest-regression/lr/lightgbm/knn/kmean/gbdt/decision-tree/pca/lda/catboost/xgb/超参搜索 * 分布式深度学习框架: * tf/pytorch/++mxnet/horovod/paddlejob/mindspore分布式训练++ * 分布式加速框架: * ++mpi/colossalai/deepspeed/horovod/megatron++ * 模型处理: * 模型评估, * 模型格式转换 * 模型服务化: * 模型注册, * ++模型离线推理++, * 模型部署 * 媒体分布式处理: * 分布式媒体下载, * 视频提取图片, * 视频提取图片 |
| 模型训练 | 算子自定义 | 支持算子自定义,通过web界面操作将自定义算法代码镜像,注册为可被他人复用的pipeline算子 |
| 模型训练 | 自动学习 | 面向非AI背景的用户提供自动学习服务,用户选择某一个场景之后,上传训练数据即可自动开始训练和模型部署,++支持示例automl任务流导入导出++ |
| 模型训练 | 自定义镜像 | 面向高级 AI 开发者,提供自定义训练作业(执行环境 + 代码)功能; |
| 模型训练 | 自动调参 | 基于单机/++分布式自动超参搜索++ |
| 模型训练 | TensorBoard作业 | ++实时/离线观察模型训练过程中的参数和指标变化情况++ |
| 模型管理 推理服务 | 内部服务 | 支持开发或运维工具快捷部署,提供mysql-web,postgresql web,mobgo web, redis web,neo4j,rstudio等开源工具 |
| 模型管理 推理服务 | 模型管理 | 模型管理用于对模型多版本管理,支持模型发布为推理服务 |
| 模型管理 推理服务 | 推理服务 | * 支持++ml++/tf/pytorch/tentortrt/onnx常规模型的多版本的0代码发布。 * 支持gpu卡型选择,++支持vgpu,独占,共享占用++, * 支持cpu/mem/++gpu等弹性伸缩,++ * 支持服务优先级, * 支持远程模型路径,支持流量分流,流量复制,sidecar配置,支持泛域名配置,支持配置文件挂载,启动目录/命令/环境变量/端口/指标/健康检查等 支持调试环境/测试环境/生产环境 支持域名/ip代理多种形式 * 支持服务负载指标监控 * 支持多版本服务滚动升级和回滚, * ++支持单pod滚动发布++ * ++支持禁用k8s service负载均衡器++ * 提供++ml++/tf/pytorch/tentortrt/onnx常规模型推理服务镜像 支持用户自定义模型推理镜像 |
| 监控 | 整体资源 | * 所有集群,所有计算机器的使用情况,包括机器的所属集群,所属资源组,机器ip,cpu/gpu类型和卡型,当前cpu/内存/gpu的使用率 * 所有集群,所有计算pod的使用情况,包括pod所属集群,所属资源组,所属命名空间,调度ip,pod名称,启动用户,cpu,gpu,内存的申请使用率 * ++整体资源页面,支持管理员批量删除++ |
| 监控 | 监控体系 | * 所有机器的gpu资源的使用情况, * 所有机器的内存/cpu/网络io/磁盘io的负载情况, * 所有pod的内存/cpu/gpu/网络io负载情况 * 所有推理服务的内存/cpu/gpu/qps/吞吐/vgpu负载情况 * ++支持ib流量监控++ |
| 模型应用市场 | 模型应用管理方案 | * ++提供cubestudio sdk,提供模型开发规范和使用规范++ |
| 模型应用市场 | 模型应用管理方案 | * ++提供web端模型应用体验,支持同步/异步推理++ |
| 模型应用市场 | 模型应用管理方案 | * ++提供开发多个python cuda版本的基础镜像++ |
| 模型应用市场 | 预训练模型 | * ++提供视觉,听觉,nlp,多模态等400+预训练模型,提供预训练模型的模型加载和推理能力,可直接一键部署服务,并提供api++ |
| 模型应用市场 | 模型市场 | * ++aihub应用对接cube-studio平台进行卡片式展示++ |
| 模型应用市场 | 模型一键开发 | * ++提供一键转notebook开发,提供符合当前模型所需环境的jupyter++ |
| 模型应用市场 | 模型一键微调 | * ++支持一键转pipeline微调链路,包括示例数据集下载,微调,模型注册,模型部署,支持微调后模型部署++ |
| 模型应用市场 | 模型一键部署web | * ++提供模型一键部署提供手机端和pc端web界面和api,和demo示例弹窗演示++ |
| 模型应用市场 | 模型自动化标注 | * ++支持部署对接labelstudio自动化标注++ |
| 模型应用市场 | 数据集sdk | * ++支持通过python sdk搜索上传下载数据集,支持数据集的加解密/解压缩/数据集基础信息查看等++ |
| 模型应用市场 | notebook sdk | * ++支持通过api,对接cube-studio创建notebook,并跳转到指定目录,用于其他算法平台在当前平台的调试和演示++ |
| 模型应用市场 | pipeline训练sdk | * ++支持AI开发主流语言 Python,提供Python SDK支持用户通过SDK来进行pipeline任务流管理和训练任务启动以及任务流编排++ |
| 模型应用市场 | 推理服务sdk | * ++提供python sdk,对接cube tudio进行推理服务的发布,服务升级++ |
| 大模型 | 大模型分布式多机多卡 | * ++支持分布式多机多卡训练,例如mpi/deepspeed/Colossal-AI++ |
| 大模型 | 支持大模型推理 | * ++支持chatglm/chatglm2/lalma/llama2/通义千问部署++ |
| 大模型 | 支持大模型微调 | * ++支持chatglm2/llama2/baichuan2 lora微调++ |
| 大模型 | 智能对话 | * ++提供支持多场景对话,支持提示词构建,推理接口配置,llm问答,支持问询中模型切换,清理,历史上下文++ |
| 大模型 | 私有知识库 | * ++私有知识库配置,私有知识库召回++ |
| 大模型 | 私有知识库 | * ++支持召回列表模式++ |
| 大模型 | 私有知识库 | * ++支持aigc模式++ |
| 大模型 | 私有知识库 | * ++支持微信公众号服务号对接++ |
| 大模型 | 私有知识库 | * ++支持企业微信群聊机器人对接++ |
| 大模型 | 私有知识库 | * ++支持钉钉群聊机器人对接++ |
帮助文档
https://github.com/tencentmusic/cube-studio/wiki
开源共建
学习、部署、体验、开源建设、商业合作 欢迎来撩。或添加微信luanpeng1234,备注<开源建设>

支持模板
提示:
- 1、可自由定制任务插件,更适用当前业务需求
| 模块 | 模板 | 类型 | 文档地址 |
|---|---|---|---|
| 数据导入导出 | datax | 单机 | job-template/job/datax/README.md |
| 数据导入导出 | 数据集导入 | 单机 | job-template/job/dataset/README.md |
| 数据导入导出 | 模型导入 | 单机 | job-template/job/model_download/README.md |
| 数据预处理 | data-process | 单机 | job-template/job/data-process/README.md |
| 数据处理工具 | hadoop | 单机 | job-template/job/hadoop/README.md |
| 数据处理工具 | spark | 分布式 | job-template/job/spark/README.md |
| 数据处理工具 | ray | 分布式 | job-template/job/ray/README.md |
| 数据处理工具 | volcanojob | 分布式 | job-template/job/volcano/README.md |
| 特征处理 | feature-process | 单机 | job-template/job/feature-process/README.md |
| 机器学习框架 | ray-sklearn | 分布式 | job-template/job/ray_sklearn/README.md |
| 机器学习算法 | random_forest | 单机 | job-template/job/random_forest/README.md |
| 机器学习算法 | lr | 单机 | job-template/job/lr/README.md |
| 机器学习算法 | lightgbm | 单机 | job-template/job/lightgbm/README.md |
| 机器学习算法 | knn | 单机 | job-template/job/knn/README.md |
| 机器学习算法 | kmeans | 单机 | job-template/job/kmeans/README.md |
| 机器学习算法 | nni | 单机 | job-template/job/hyperparam-search-nni/README.md |
| 机器学习算法 | xgb | 单机 | job-template/job/xgb/README.md |
| 机器学习算法 | gbdt | 单机 | job-template/job/gbdt/README.md |
| 机器学习算法 | decision-tree | 单机 | job-template/job/decision_tree/README.md |
| 机器学习算法 | bayesian | 单机 | job-template/job/bayesian/README.md |
| 机器学习算法 | adaboost | 单机 | job-template/job/adaboost/README.md |
| 深度学习 | tfjob | 分布式 | job-template/job/tf/README.md |
| 深度学习 | pytorchjob | 分布式 | job-template/job/pytorch/README.md |
| 深度学习 | paddle | 分布式 | job-template/job/paddle/README.md |
| 深度学习 | mxnet | 分布式 | job-template/job/mxnet/README.md |
| 深度学习 | mindspore | 分布式 | job-template/job/mindspore/README.md |
| 深度学习 | horovod | 分布式 | job-template/job/horovod/README.md |
| 深度学习 | mpi | 分布式 | job-template/job/mpi/README.md |
| 深度学习 | colossalai | 分布式 | job-template/job/colossalai/README.md |
| 深度学习 | deepspeed | 分布式 | job-template/job/deepspeed/README.md |
| 深度学习 | megatron | 分布式 | job-template/job/megatron/README.md |
| 模型处理 | model-evaluation | 单机 | job-template/job/model_evaluation/README.md |
| 模型服务化 | model-convert | 单机 | job-template/job/model_convert/README.md |
| 模型服务化 | model-register | 单机 | job-template/job/model_register/README.md |
| 模型服务化 | deploy-service | 单机 | job-template/job/deploy-service/README.md |
| 模型服务化 | model-offline-predict | 分布式 | job-template/job/model_offline_predict/README.md |
| 多媒体类 | media-download | 分布式 | job-template/job/video-audio/README.md |
| 多媒体类 | video-img | 分布式 | job-template/job/video-audio/README.md |
| 多媒体类 | video-audio | 分布式 | job-template/job/video-audio/README.md |
| 大模型 | llama2 | 单机多卡 | job-template/job/llama2/README.md |
| 大模型 | chatglm2 | 单机多卡 | job-template/job/chatglm2/README.md |
| 大模型 | baichuan2 | 单机多卡 | job-template/job/baichuan2/README.md |
公司

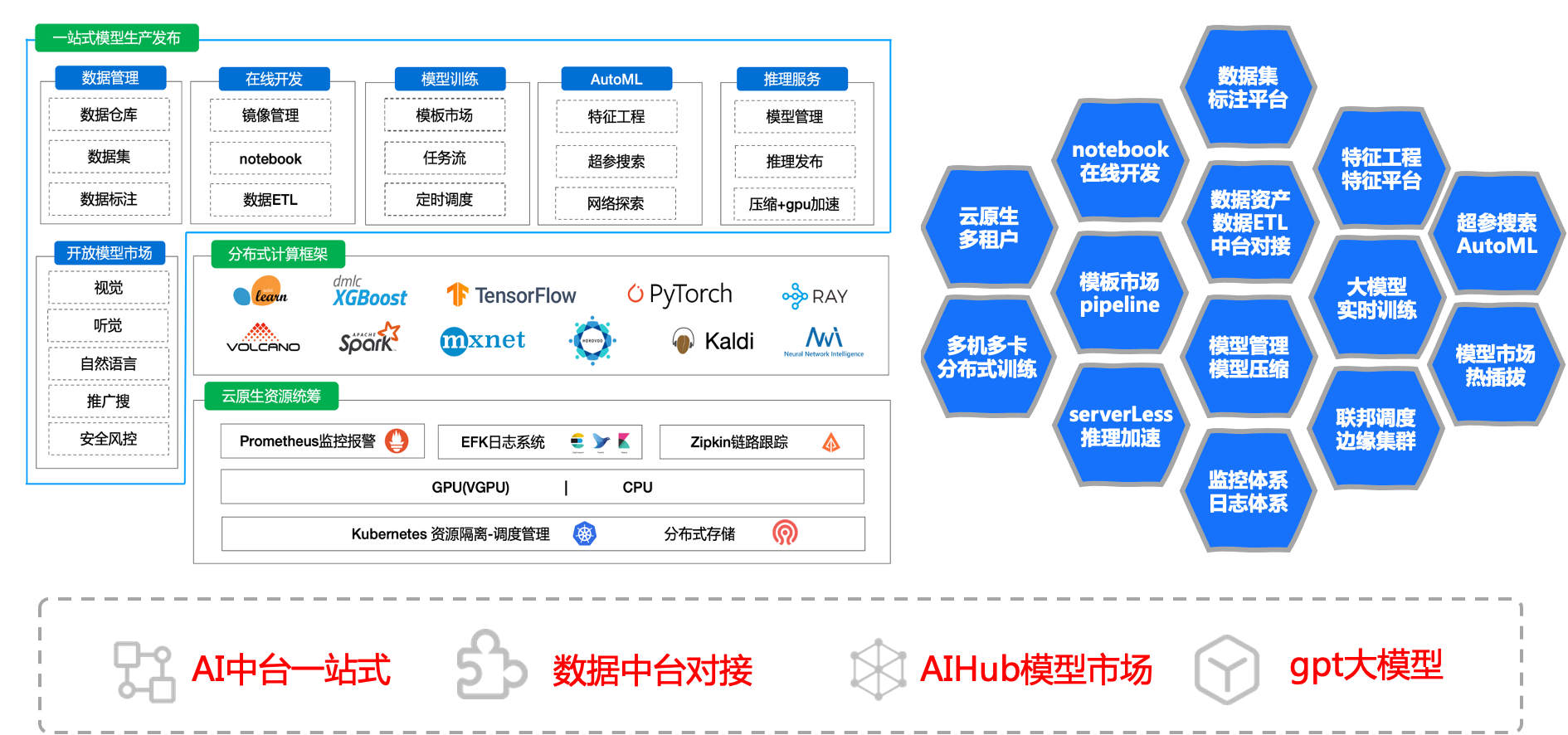
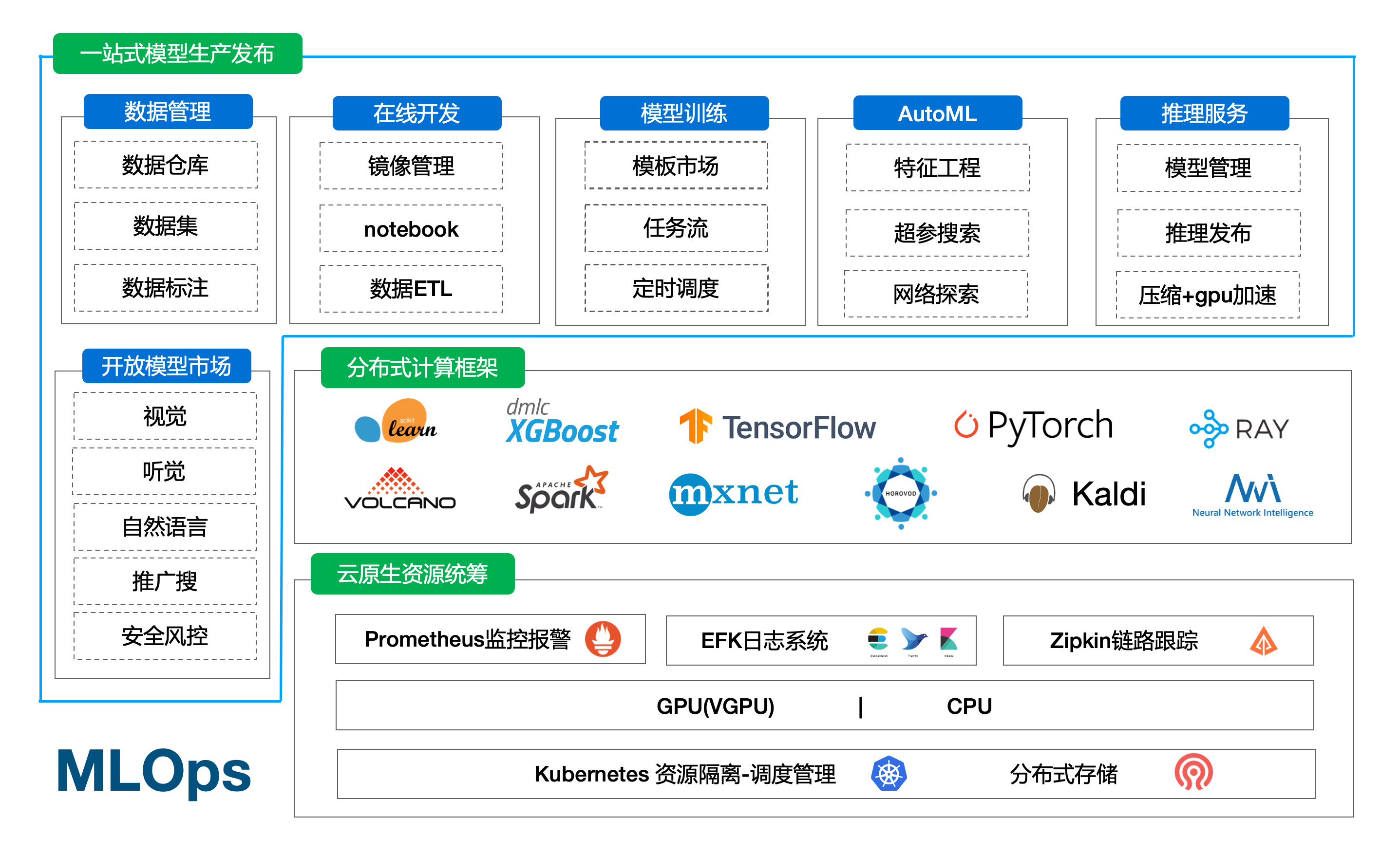
平台简介
完整的平台包含
- 1、机器的标准化
- 2、分布式存储(单机可忽略)、k8s集群、监控体系(prometheus/efk/zipkin)
- 3、基础能力(tf/pytorch/mxnet/valcano/ray等分布式,nni/katib超参搜索)
- 4、平台web部分(oa/权限/项目组、在线构建镜像、在线开发、pipeline拖拉拽、超参搜索、推理服务管理等)
算力/存储/用户管理
算力:
- 云原生统筹平台cpu/gpu等算力
- 支持划分多资源组,支持多k8s集群,多地部署
- 支持T4/V100/A100/昇腾/dcu/VGPU等异构GPU/NPU环境
- 支持边缘集群模式,支持边缘节点上开发/训练/推理
- 支持鲲鹏芯片arm64架构,RDMA
存储:
- 自带分布式存储,支持多机分布式下文件处理
- 支持外部存储挂载,支持项目组挂载绑定
- 支持个人存储空间/组空间等多种形式
- 平台内存储空间不需要迁移
用户权限:
- 支持sso登录,对接公司账号体系
- 支持项目组划分,支持配置相应项目组用户的权限
- 管理平台用户的基本信息,组织架构,rbac权限体系
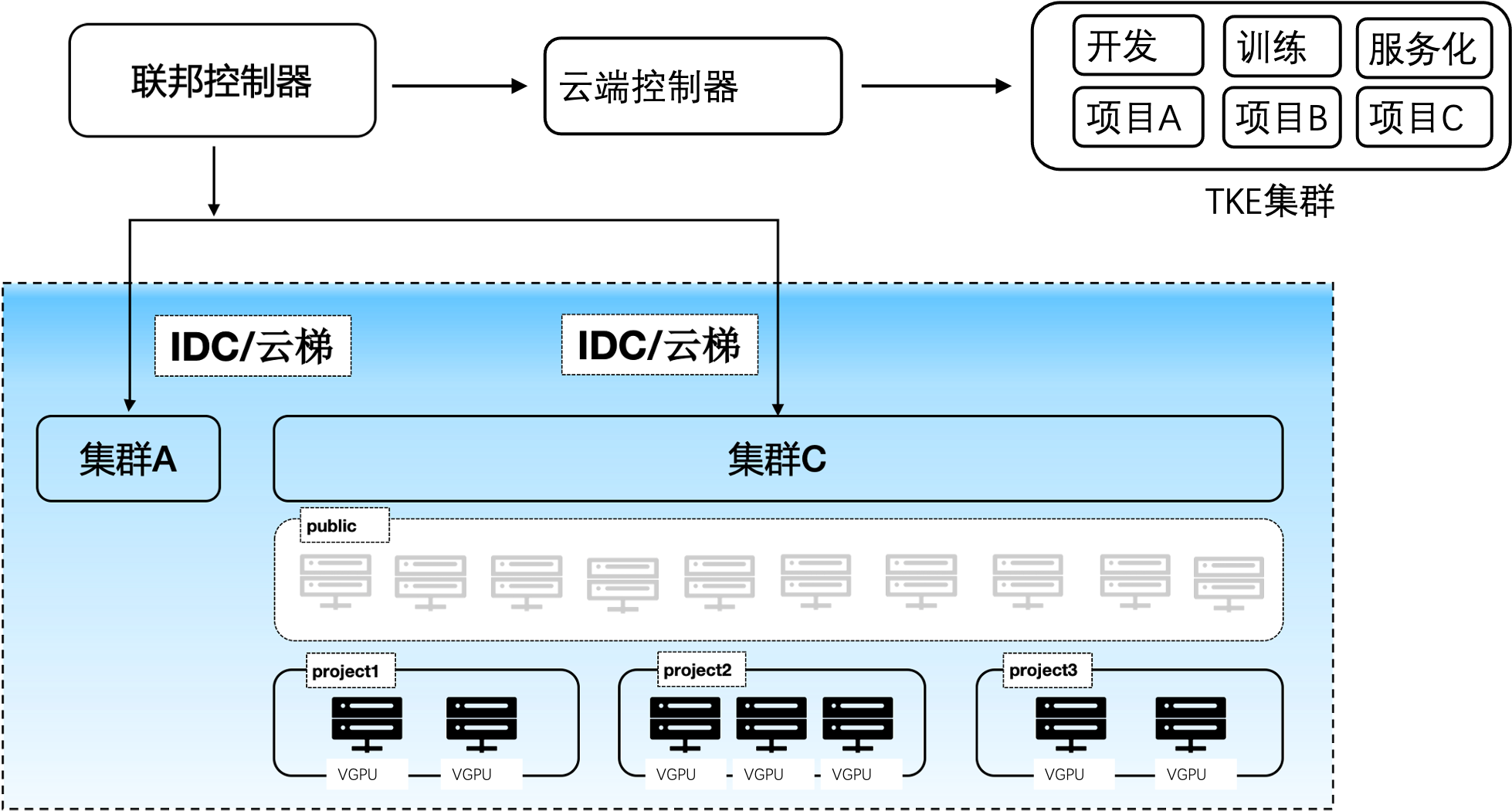
多集群管控
cube支持多集群调度,可同时管控多个训练或推理集群。在单个集群内,不仅能做到一个项目组内对在线开发、训练、推理的隔离,还可以做到一个k8s集群下多个项目组算力的隔离。另外在不同项目组下的算力间具有动态均衡的能力,能够在多项目间共享公共算力池和私有化算力池,做到成本最低化。
分布式存储
cube会自动为用户挂载用户的个人目录,同一个用户在平台任何地方启动的容器,其用户个人子目录均为/mnt/$username。可以将pvc/hostpath/memory/configmap等挂载成容器目录。同时可以在项目组中配置项目组的默认挂载,进而实现一个项目组共享同一个目录等功能。

在线开发
- 系统多租户/多实例管理,在线交互开发调试,无需安装三方控件,只需浏览器就能完成开发。
- 支持vscode,jupyter,Matlab,Rstudio等多种在线IDE类型
- Jupyter支持cube-studio sdk,Julia,R,python,pyspark多内核版本,
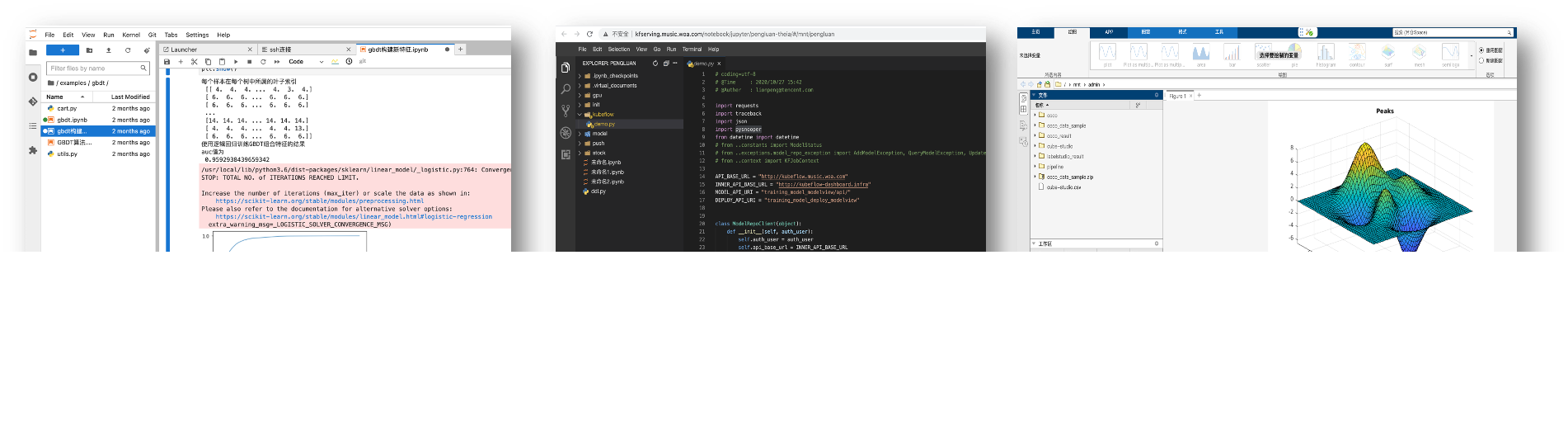
- 支持c++,java,conda等多种开发语言,以及tensorboard/git/gpu监控等多种插件
- 支持ssh remote与notebook互通,本地进行代码开发
- 在线镜像构建,通过Web Shell方式在浏览器中完成构建;并提供各种版本notebook,inference,gpu,python等基础镜像
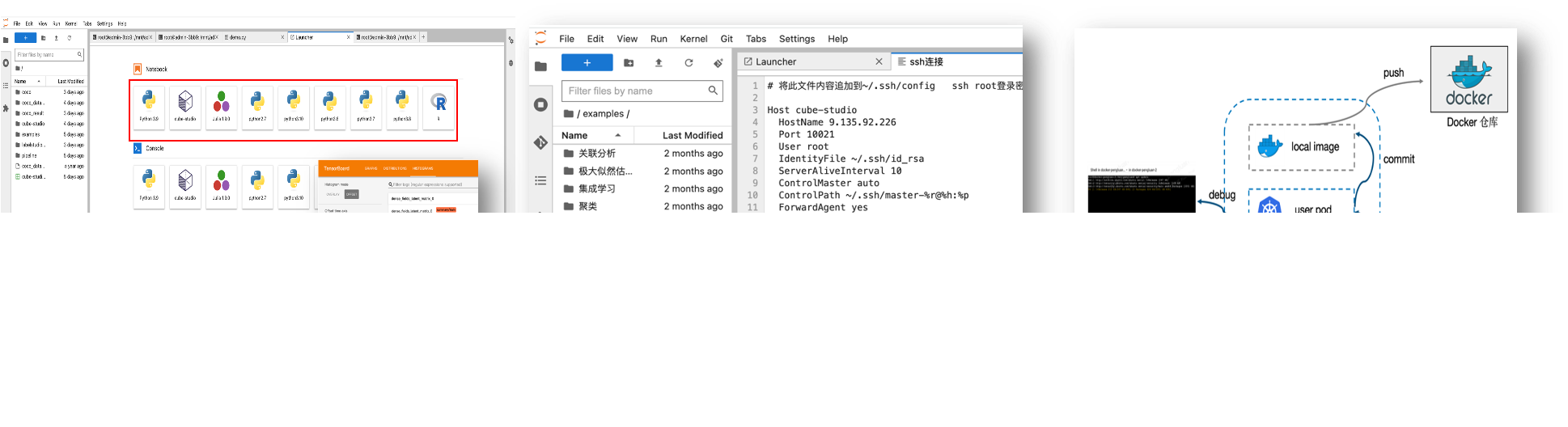
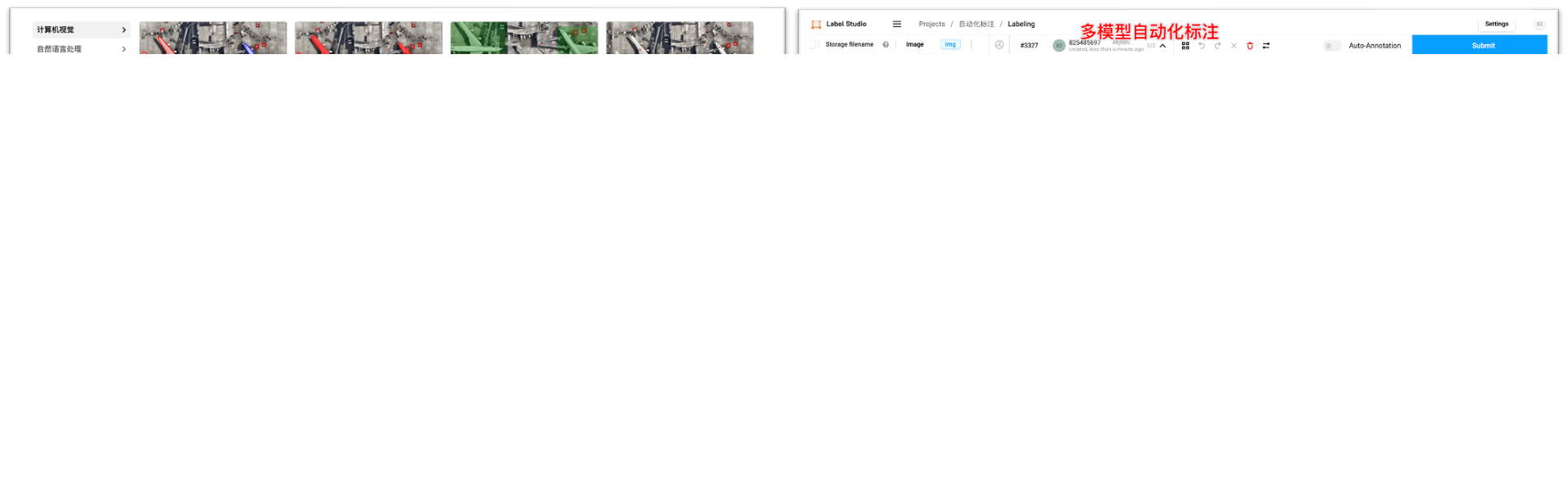
标注平台:
- 支持图/文/音/多模态/大模型多种类型标注功能,用户管理,工作任务分发
- 对接aihub模型市场,支持自动化标注;对接数据集,支持标注数据导入;对接pipeline,支持标注结果自动化训练
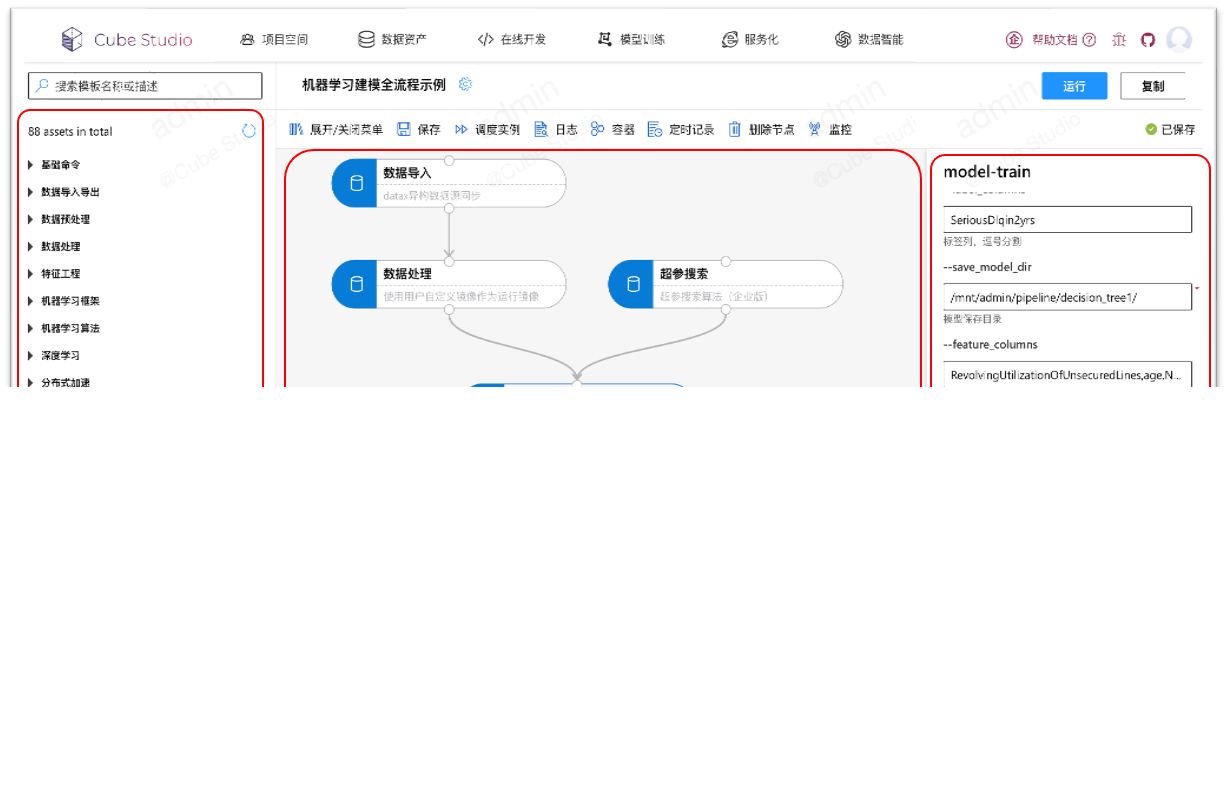
拖拉拽pipeline编排
1、Ml全流程
数据导入,数据预处理,超惨搜索,模型训练,模型评估,模型压缩,模型注册,服务上线,ml算法全流程
2、灵活开放
支持单任务调试、分布式任务日志聚合查看,pipeline调试跟踪,任务运行资源监控,以及定时调度功能(包含补录,忽略,重试,依赖,并发限制,过期淘汰等功能)
分布式框架
1、训练框架支持分布式(协议和策略)
2、代码识别分布式角色(有状态)
3、控制器部署分布式训练集群(operator)
4、配置分布式训练集群的部署(CRD)
多层次多类型算子
以k8s为核心,
1、支持tf分布式训练、pytorch分布式训练、spark分布式数据处理、ray分布式超参搜索、mpi分布式训练、horovod分布式训练、nni分布式超参搜索、mxnet分布式训练、volcano分布式数据处理、kaldi分布式语音训练等,
2、 以及在此衍生出来的分布式的数据下载,hdfs拉取,cos上传下载,视频采帧,音频抽取,分布式的训练,例如推荐场景的din算法,ComiRec算法,MMoE算法,DeepFM算法,youtube dnn算法,ple模型,ESMM模型,双塔模型,音视频的wenet,containAI等算法的分布式训练。
功能模板化
- 和非模板开发相比,使用模板建立应用成本会更低一些,无需开发平台。
- 迁移更加容易,通过模板标准化后,后续应用迁移迭代只需迁移配置模板,简化复杂的配置操作。
- 配置复用,通过简单的配置就可以复用这些能力,算法与工程分离避免重复开发。
为了避免重复开发,对pipeline中的task功能进行模板化开发。平台开发者或用户可自行开发模板镜像,将镜像注册到平台,这样其他用户就可以复用这些功能。平台自带模板在job-template目录下

流水线调试
- Pipeline调试支持定时执行,支持,补录,并发限制,超时,实例依赖等。
- Pipeling运行,支持变量在任务间输入输出,全局变量,流向控制,模板变量,数据时间等
- Pipeling运行,支持任务结果可视化,图片、csv/json,echart源码可视化
nni超参搜索
界面化呈现训练各组数据,通过图形界面进行直观呈现。
减少以往开发调参过程的枯燥感,让整个调参过程更加生动具有趣味性,完全无需丰富经验就能实现更精准的参数控制调节。
bash
# 上报当前迭代目标值
nni.report_intermediate_result(test_acc)
# 上报最终目标值
nni.report_final_result(test_acc)
# 接收超参数为输入参数
parser.add_argument('--batch_size', type=int)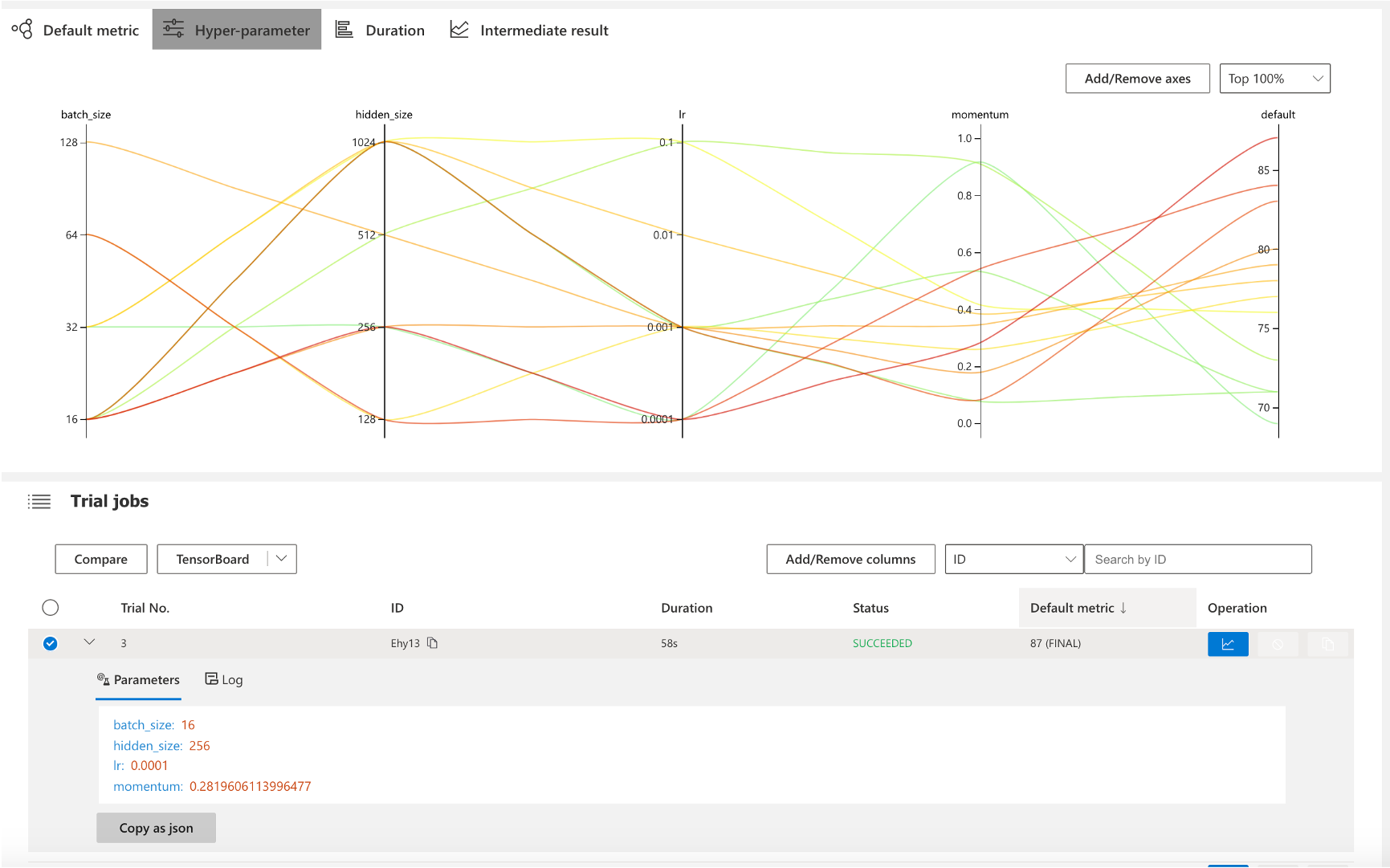
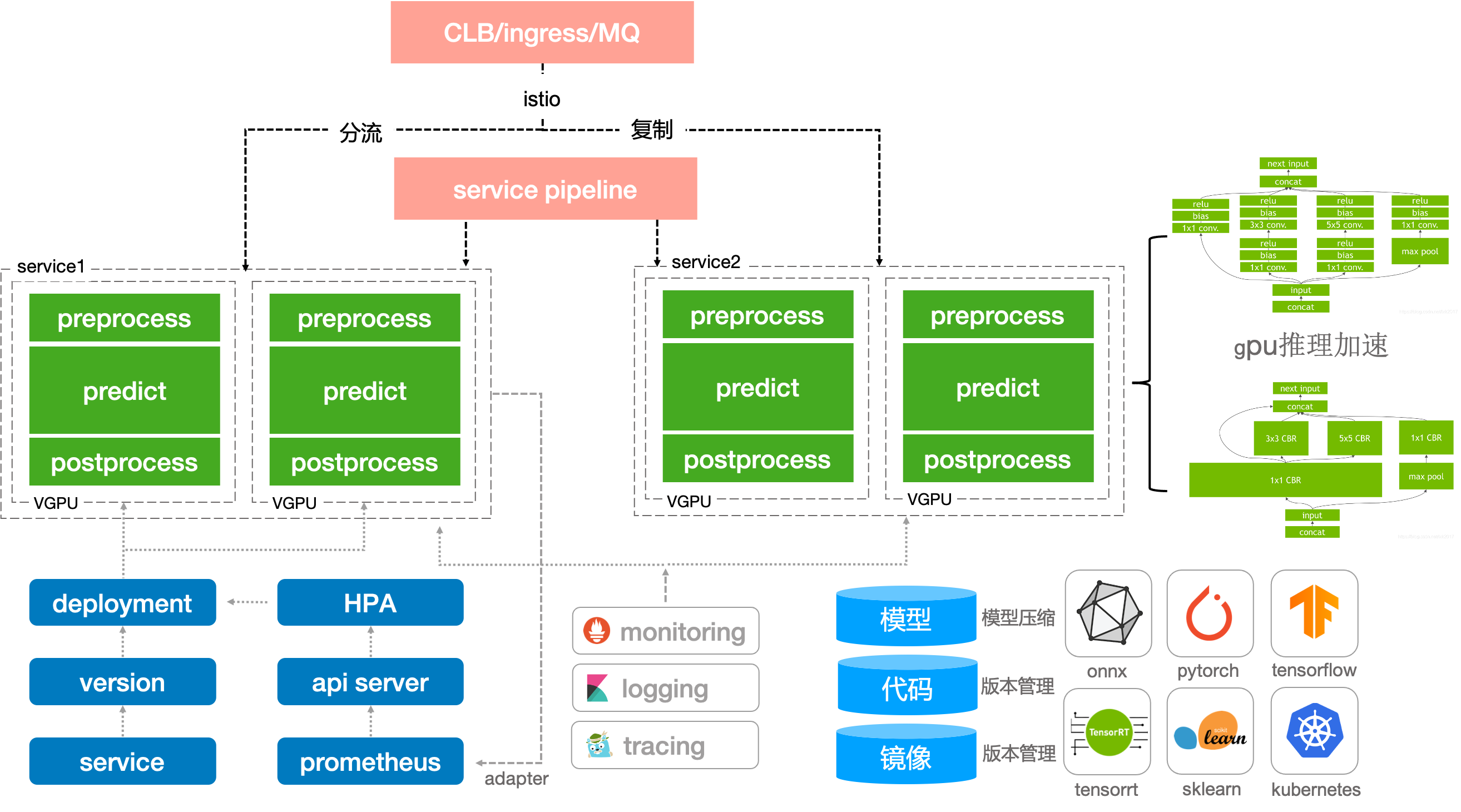
推理服务
0代码发布推理服务从底层到上层,包含服务网格,serverless,pipeline,http框架,模型计算。
-
服务网格阶段:主要工作是代理流量的中转和管控,例如分流,镜像,限流,黑白名单之类的。
-
serverless阶段:主要为服务的智能化运维,例如服务的激活,伸缩容,版本管理,蓝绿发布。
-
pipeline阶段:主要为请求在各数据处理/推理之间的流动。推理的前后置处理逻辑等。
-
http/grpc框架:主要为处理客户端的请求,准备推理样本,推理后作出响应。
-
模型计算:模型在cpu/gpu上对输入样本做前向计算。
主要功能:
- 支持模型管理注册,灰度发布,版本回退,模型指标可视化,以及在piepline中进行模型注册
- 推理服务支持多集群,多资源组,异构gpu环境,平台资源统筹监控,VGPU,服务流量分流,复制,sidecar
- 支持0代码的模型发布,gpu推理加速,支持训练推理混部,服务优先级,自定义指标弹性伸缩。
监控和推送
监控:cube-studio集成prometheus生态,可以监控包括主机,进程,服务流量,gpu等相关负载,并配套grafana进行可视化
推送:cube-studio开放推送接口,可自定义推送给企业oa系统
AIHub
- 系统自带通用模型数量400+,覆盖绝大数行业场景,根据需求可以不断扩充。
- 模型开源、按需定制,方便快速集成,满足用户业务增长及二次开发升级。
- 模型标准化开发管理,大幅降低使用门槛,开发周期时长平均下降30%以上。
- AIHub模型可一键部署为WEB端应用,手机端/PC端皆可,实时查看模型应用效果
- 点击模型开发即可进入notebook进行模型代码的二次开发,实现一键开发
- 点击训练即可加入自己的数据进行一键微调,使模型更贴合自身场景
GPT训练微调
- cube-studio支持deepspeed/colossalai等分布式加速框架,可一键实现大模型多机多卡分布式训练
- AIHub包含gpt/AIGC大模型,可一键转为微调pipeline,修改为自己的数据后,便可以微调并部署
GPT-RDMA
rdma插件部署后,k8s机器可用资源
bash
capacity:
cpu: '128'
memory: 1056469320Ki
nvidia.com/gpu: '8'
rdma/hca: '500'代码分布式训练中使用IB设备
bash
export NCCL_IB_HCA=mlx5
export MLP_WORKER_GPU=$GPU_NUM
export MLP_WORKER_NUM=$WORLD_SIZE
export MLP_ROLE_INDEX=$RANK
export MLP_WORKER_0_HOST=$MASTER_ADDR
export MLP_WORKER_0_PORT=$MASTER_PORT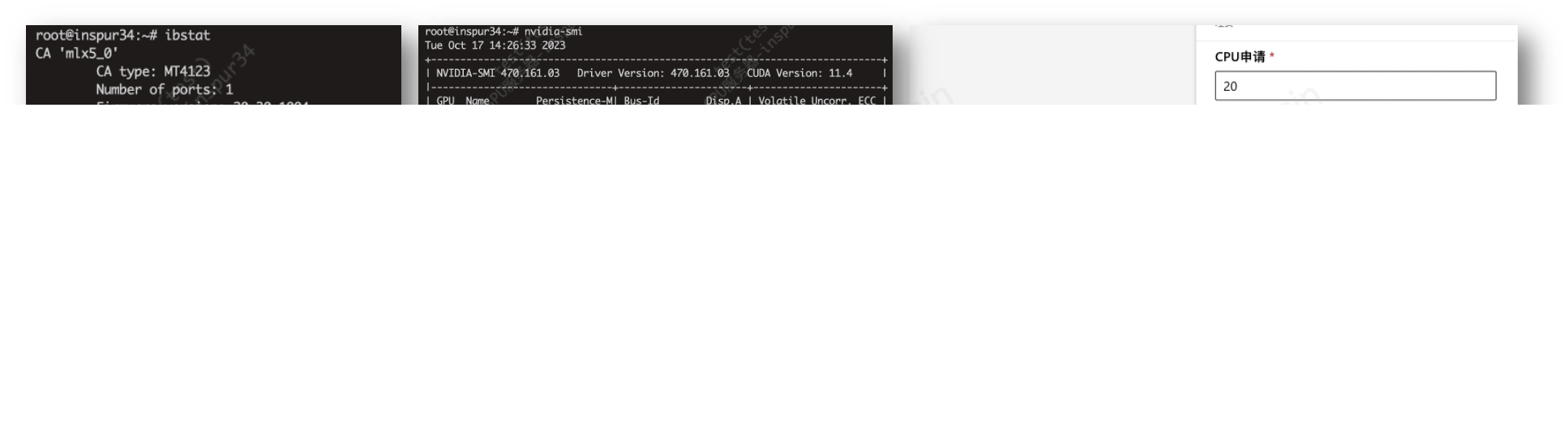
gpt私有知识库
- 数据智能模块可配置专业领域智能对话,快速敏捷使用llm
- 可为某个聊天场景配置私有知识库文件,支持主题分割,语义embedding,意图识别,概要提取,多路召回,排序,多种功能融合
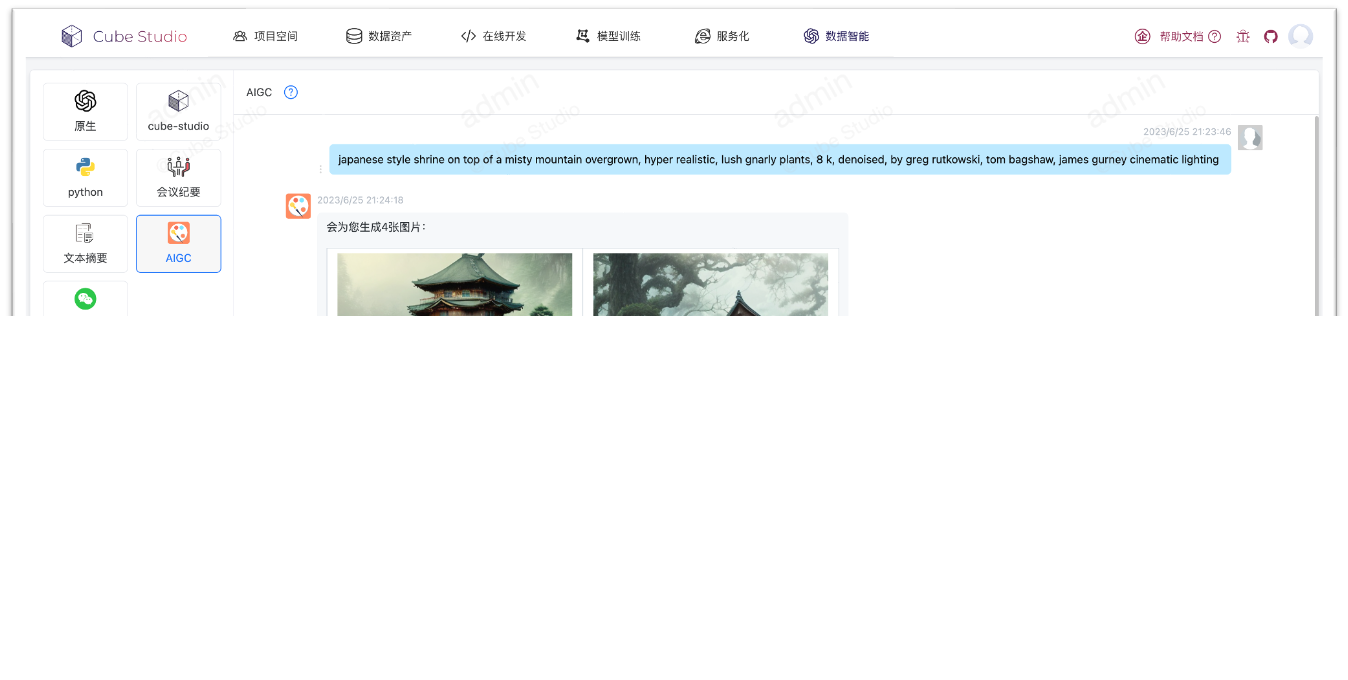
gpt智能聊天
- 可以将智能会话与AIHub相结合,例如下面AIGC模型与聊天会话
- 可使用Autogpt方式串联所有aihub模型,进行图文音智能化处理
- 智能会话与公共直接打通,可在微信公众号中进行图文音对话
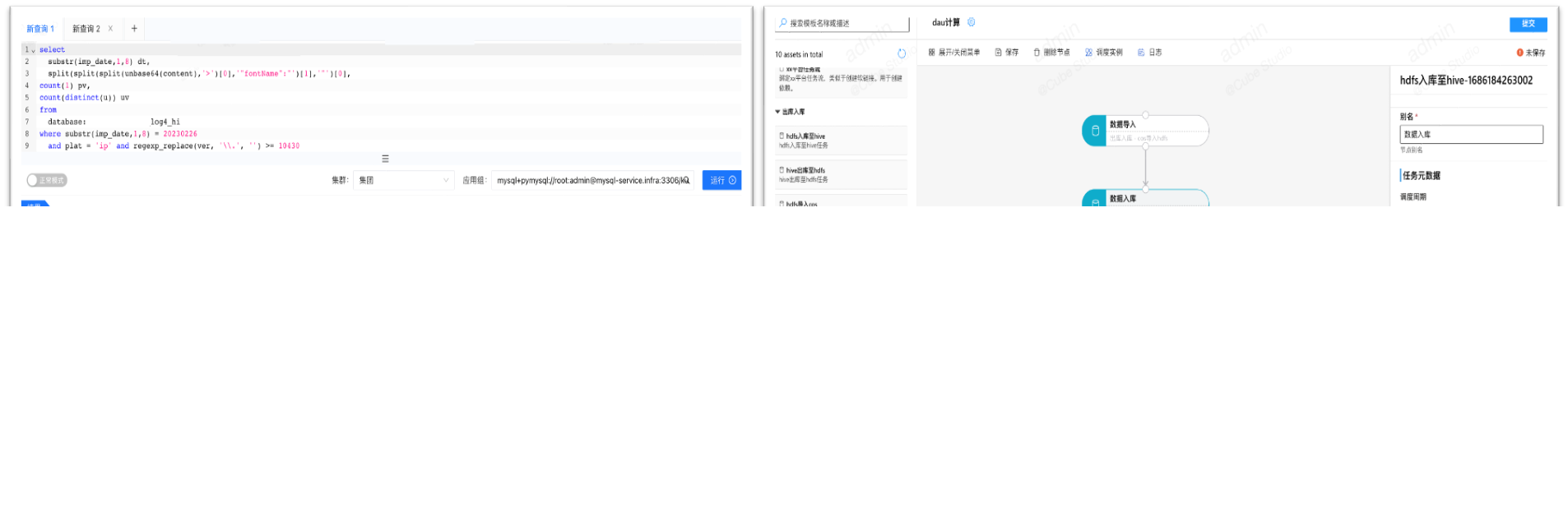
数据中台对接
为了加速AI算法平台的使用,cube-studio支持对接公司原有数据中台,包括数据计算引擎sqllab,元数据管理,指标管理,维表管理,数据ETL,数据集管理
三种方式部署
针对企业需求,根据不同场景对计算实时性的不同需求,可以提供三种建设模式
模式一:私有化部署------对数据安全要求高、预算充足、自己有开发能力
模式二:边缘集群部署------算力分散,多个子网环境的场景,或边缘设备场景
模式三:serverless集群------成本有限,按需申请算力的场景
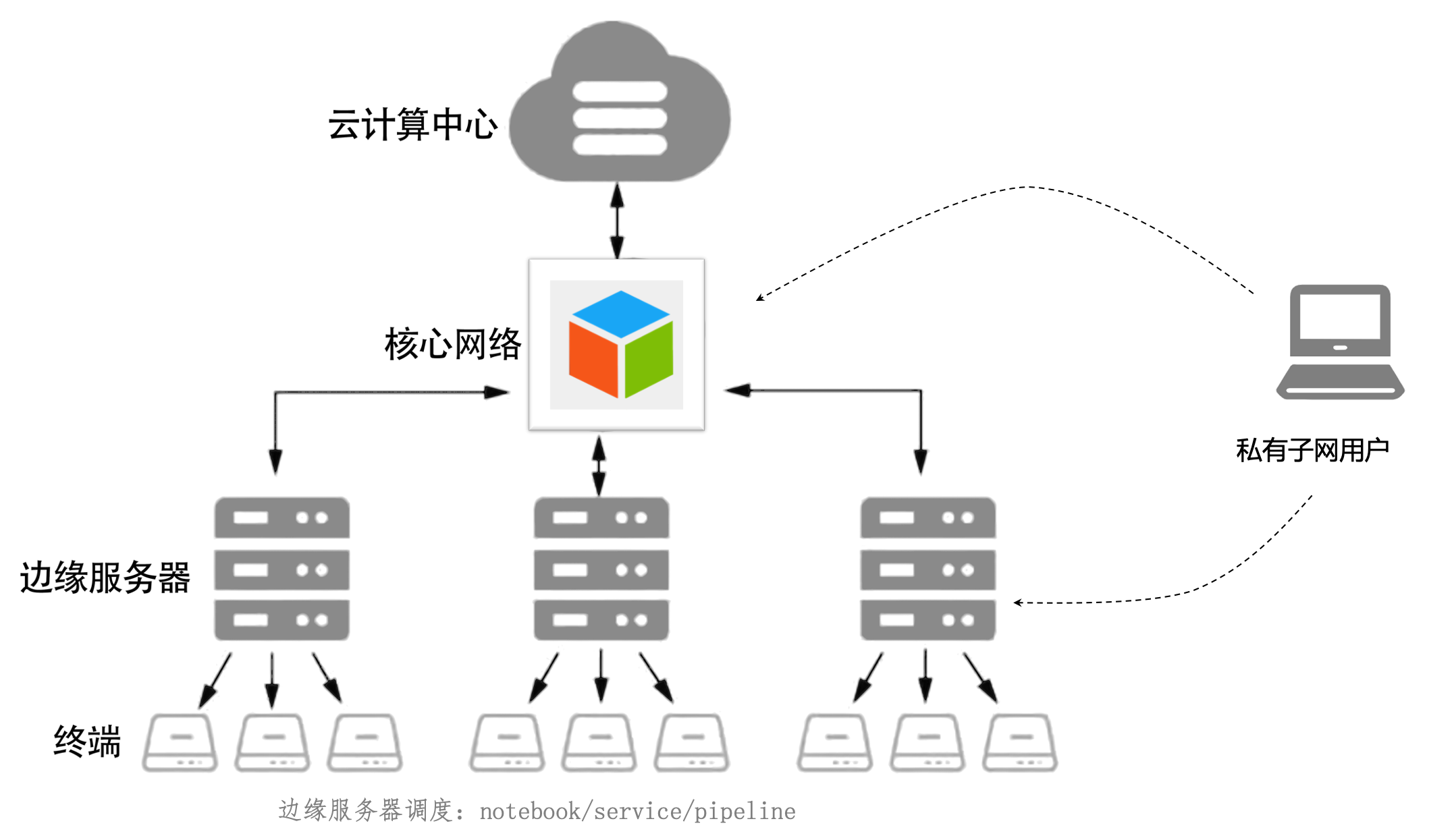
边缘计算
通过边缘集群的形式,在中心节点部署平台,并将边缘节点加入调度,每个私有网用户,通过项目组,将notebook,pipeline,service部署在边缘节点
- 1、避免数据到中心节点的带宽传输
- 2、避免中心节点的算力成本,充分利用边缘节点算力
- 3、避免边缘节点的运维成本