从一间堆满机器人的实验室说起
我想象自己刚刚走出 Physical Intelligence 位于旧金山的实验室。那里的桌面上摆满了各种形态的机械臂------轻量级的双臂 BiPi、笨重的工业级 UR5e、带轮子的移动操作平台------它们在做同一件事:叠衣服、做咖啡、装箱子。但让工程师们真正兴奋的不是这些已知任务的完成度,而是一个 UR5e 从未见过叠衣服数据的机器人,在零样本条件下,把一件 T 恤叠得和经验丰富的遥操作员一样好。这不是靠针对新机器人微调出来的,而是一个通用模型"涌现"出来的能力。
arXiv 链接:π_{0.7}: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
这篇论文要解决的根本矛盾其实很尖锐:机器人基础模型一直无法像大语言模型那样进行组合泛化------它不但做不了训练时没见过的任务,甚至连训练过的任务都经常做不利索,必须依赖针对特定任务的微调。 之前的 VLA(视觉-语言-动作模型)试图通过增大模型和数据量来突破这个瓶颈,但问题在于,当你把不同质量、不同策略、不同来源的数据混在一起训练时,模型会把各种模式"平均"成一个模糊的中间态,结果比任何一个单一策略都差。
π₀.₇ 的回答是:不是数据不够多,而是上下文不够丰富。 论文的核心论点可以用一句话概括:给机器人更丰富的"提示词"(不只是告诉你做什么,还要告诉你怎么做、用什么策略、期望什么质量),就能让它从混乱的数据中提取出可组合的技能模块。
把"提示词工程"搬进机器人的训练流程
如果让我用一个类比来解释 π₀.₇ 的核心机制,我会说:它就像一个经验极其丰富的厨师学校。 传统 VLA 训练就像给学生一堆菜谱,只写"做一道番茄炒蛋"。但现实中,有的学生做得好吃,有的做得难吃;有人用大火快炒,有人用小火慢炖;有人翻锅利索,有人手忙脚乱。如果你把这些学生的作品混在一起,只看成品照片来学做菜,你学到的将是一个"平均味道"------既不是大火版也不是小火版,而是哪个都不像的模糊版。
π₀.₇ 的做法是:给每一道菜都贴上详细标签------"这是大火快炒版,用时 3 分钟,质量评分 5 分"、"这是新手做的,中间翻车了一次,用了 8 分钟,质量 2 分"、"这是一段人类切菜的视频,不是机器人做的,但动作可以参考"。有了这些标签,模型就能在训练时理解"同样是番茄炒蛋,策略可以完全不同",然后在测试时通过指定"我要大火快炒版、质量 5 分、不能出错"来精确控制输出。
这个机制的骨架由三个支柱组成:
支柱一:子任务指令(Subtask Instructions)。 不只是"打扫厨房"这种笼统任务描述,而是细化到"打开冰箱门"、"把牛奶拿出来"这样的中间步骤。在测试时可以由人类或另一个高层策略实时提供,相当于有人在旁边用语言一步步指导。
支柱二:子目标图像(Subgoal Images)。 语言再精确,有些细节也说不清------比如"把 T 恤叠成这样"到底是什么样?子目标图像直接给模型看一张"做完这一步后世界应该长什么样"的图片。这些图像由一个基于 BAGEL(14B 参数的图像生成模型)的轻量级世界模型生成,它利用了网络规模的视频和图像编辑预训练,能把语义理解转化为视觉提示。
支柱三:元数据(Episode Metadata)。 这是论文最巧妙的设计。每条训练数据都附带三个元标签:整体速度(用时间步数衡量)、整体质量(1-5 分)、是否包含错误。测试时指定"速度最快、质量最高、无错误",模型就会从训练数据中提取出最好的行为模式。
Figure 3 展示了这些提示组件如何组合在一起使用:

在这张图中,你可以看到 π₀.₇ 的提示词是一个多模态组合体:左侧是语言指令(任务描述 + 子任务),中间是子目标图像(多视角的未来状态),右侧是元数据(速度、质量、错误标签)和控制模式(关节/末端执行器)。训练时每个组件都以一定概率被随机丢弃(dropout),这样模型既能使用完整的提示,也能
整个架构可以用 Figure 2 来理解:
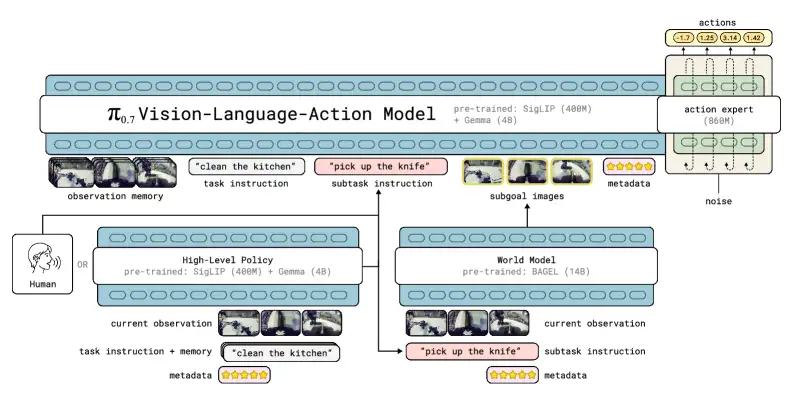
这是一个 5B 参数的系统:4B 的 Gemma3 VLM 作为骨干网络(含 400M 的视觉编码器),加上 860M 的"动作专家"(一个使用 flow matching 目标生成动作的轻量 Transformer)。关键的设计是"知识隔离"(Knowledge Insulation):VLM 骨干通过离散的 FAST token 监督训练,动作专家可以"看到"VLM 的所有激活
与之前方法的本质差异在于:传统 VLA 只把语言指令作为上下文,π₀.₇ 把上下文扩展成了一个"控制面板"。这不是简单的"加更多信息"------每个信息组件都解决了一个具体的数据利用问题。元数据解决了"如何从失败数据中学习而不被污染";子目标图像解决了"语言无法精确描述的视觉目标";子任务指令解决了"长程任务的阶段性引导"。
实验证据:三个最值得细看的发现
通才打败专才:开箱即用的灵巧性
论文最震撼的结果是 π₀.₇ 在没有任何任务特定微调的情况下,匹配甚至超越了经过 RL 微调的专家模型。
看 Figure 6 的数据------它展示了 π₀.₇ 与 π*₀.₆(经过 RL 微调的专家模型)在多个灵巧任务上的对比:
| 任务 | π₀.₇ 成功率 | π*₀.₆ 成功率 | π₀.₇ 吞吐量(相对) |
|---|---|---|---|
| 做咖啡(Espresso) | 与专家持平 | 基准 | ~1.0x |
| 装箱子(Box Building) | 与专家持平 | 基准 | >1.0x |
| 叠衣服(Laundry) | 与专家持平 | 基准 | >1.0x |
| 做三明治 | 与 SFT 专家持平 | --- | --- |
| 切西葫芦 | 与 SFT 专家持平 | --- | --- |
| 换垃圾袋 | 与 SFT 专家持平 | --- | --- |
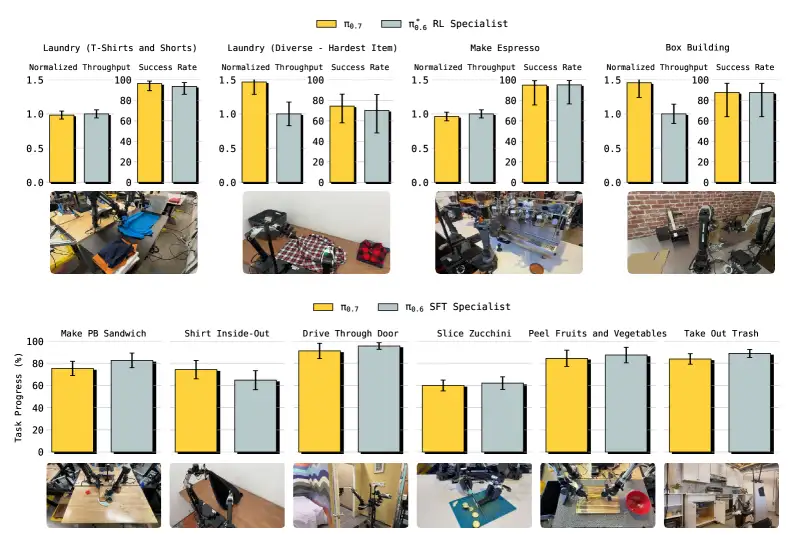
关键信息在这张图的上半部分:对于 π*₀.₆ 发布的任务,π₀.₇ 的成功率与 RL 专家持平,而在叠衣服和装箱子这两个最难的任务上,吞吐量甚至超过了 RL 专家。这不是一个"差不多"的结果------一个通用模型在没有任何针对性训练的情况下,匹配了每个任务单独训练的专家,这在之前从未被报道过。
更重要的是 Figure 7 的消融实验,它揭示了为什么 π₀.₇ 能做到这一点:
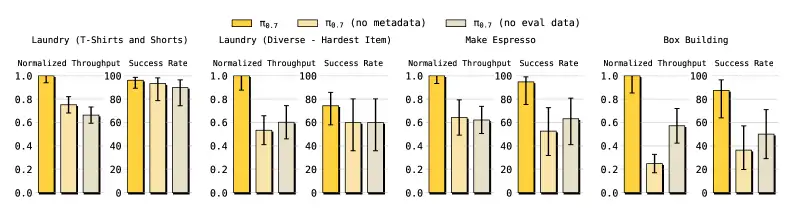
去掉元数据或去掉评估数据,性能都会显著下降。这说明两个设计缺一不可:光有元数据但没有多样化的数据(包括失败数据),模型学不到丰富的行为模式;光有数据但没有元数据来区分好坏,模型会把各种质量的行为"平均"成次优输出。
零样本跨具身迁移:模型自己发现了新策略
跨具身迁移的实验最能说明 π₀.₇ 的"涌现"能力。数据都在轻量级 BiPi 双臂机器人上收集,从未在 UR5e 上训练过叠衣服,但 π₀.₇ 在 UR5e 上成功叠了衬衫和毛巾。
Figure 12 展示了跨具身迁移的完整结果:
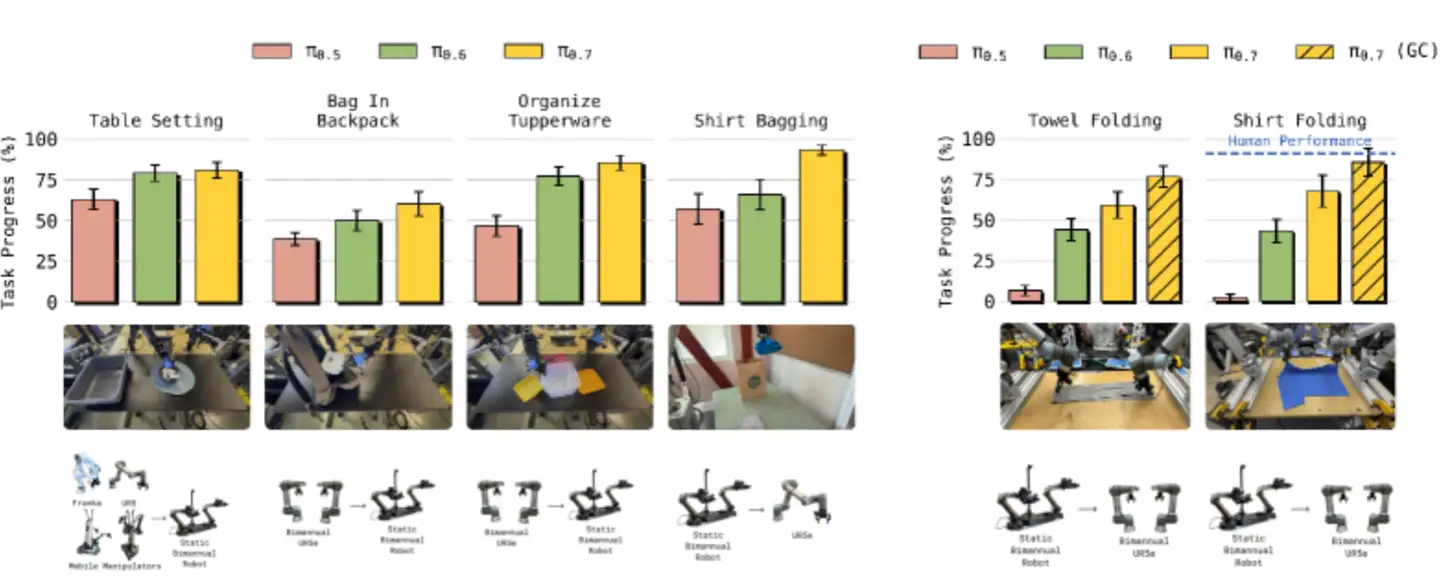
左边是物体重排类任务(较简单),右边是叠衣服(极难)。在简单的重排任务上,所有模型都有一定迁移能力。但在叠衣服上,π₀.₇ 是唯一成功的模型,而且使用子目标图像后性能进一步提升。
最让我印象深刻的是 Figure 13 展示的"涌现策略":

左图:在源机器人上,人类操作员用一只手臂撑开袋子、另一只手放东西。在 UR5e 上,π₀.₇ 自动切换成单臂抓取放置策略------因为 UR5e 的臂展更长,不需要两只手配合。右图:在源机器人上叠衣服时,操作员倾斜末端执行器压住布料再抬起;在 UR5e 上,π₀.₇ 改用垂直抓取------因为 UR5e 的臂更重、惯性更大,倾斜
这不是简单的"复制源机器人的动作",而是模型根据目标机器人的形态学自动调整了操作策略。论文还做了一个很有说服力的人类实验:10 位经验丰富的遥操作员(平均 375 小时操作经验,前 2%)在 UR5e 上零样本叠衬衫,成功率 80.6%,任务进度 90.9%;π₀.₇ 达到了 80% 成功率和 85.6% 任务进度。模型做到了和顶级人类操作员相当的水平。
从"更多数据"到"更多好数据"的范式转换
Figure 18 左图是整个消融研究中最具洞察力的一张:
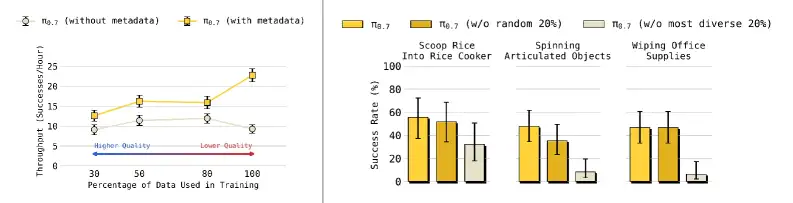
横轴是数据量(从 top 30% 质量到全部数据),纵轴是性能。不带元数据的 π₀.₇ 在数据量增加时性能反而下降------因为低质量数据"污染"了模型。但带元数据的 π₀.₇ 随着数据量增加持续提升,即使平均质量在下降。
这张图的意义远超技术细节本身:它证明了元数据提示让模型具有了"可扩展性"------你可以放心地把所有数据(包括失败的、次优的、来自旧模型的)都扔进去训练,只要附上质量标签,模型就能从中提取有用信息。这从根本上改变了机器人数据收集的经济学:你不再需要精心筛选高质量数据,而是可以把所有数据都利用起来。
右图进一步证明了任务多样性的重要性:去掉最高多样性的 20% 数据后,性能显著下降;而去掉随机 20% 数据影响很小。这意味着模型的组合泛化能力直接来源于训练数据的任务多样性。
两个疑问地方------以及我的思路
元数据的标注成本和噪声问题
论文中的元数据(质量评分、错误标签)是"由人类粗略标注"的。但论文没有详细讨论:这个标注过程有多贵?标注者之间的一致性如何?当数据规模进一步扩大(比如从目前的规模扩展到 10 倍),人工标注元数据是否还能跟上?
我的推理: 元数据的质量直接决定了模型能否正确区分好行为和坏行为。如果标注有噪声------比如把一个中等质量的 episode 标成 5 分------模型就会学到错误的关联。在当前规模下这个问题可能不严重,因为数据量还在人工可处理的范围内。但一旦扩展到更大规模,这可能成为瓶颈。
补救思路: 可以尝试用模型自身来自动标注元数据。具体来说,先用人工标注的小数据集训练一个"质量评估器",然后用它来自动标注大数据集。或者更激进地,让模型在训练过程中自己学习质量评估------比如用一个辅助头来预测 episode 的成功率,然后用这个预测值作为元数据。论文提到了他们用时间步数来衡量速度(这是自动的),但质量评分和错误标签仍然是人工的,这里有很大的自动化空间。
"未见任务"的定义模糊性
论文自己也承认了一个尴尬的限制:在如此大规模、多样化的数据集上,很难确定哪些任务是真正"未见"的。论文说"我们的数据集包含太多不同的场景和行为,潜在相关的技能可能在数据中的其他地方出现过"。
我的推理: 这不是一个小问题。如果 π₀.₇ 的"组合泛化"本质上只是"在训练数据中见过类似技能的重新组合",那它的泛化边界就不清晰。比如"把红薯放进空气炸锅"这个任务,训练数据中可能没有完全一样的任务,但很可能有"把东西放进容器"的类似动作模式。这到底是真正的组合泛化还是高级的模式匹配?论文自己也无法给出确定答案。
补救思路: 可以设计一个更严格的"新颖性度量"。具体来说,对于每个声称的"未见任务",计算它的动作序列与训练数据中最近邻任务的编辑距离或轨迹相似度。如果相似度很高,说明模型可能只是在做模式匹配;如果相似度很低,才更可能是真正的组合泛化。论文没有做这种分析,但这是理解模型泛化边界的关键。
一个跨领域的脑洞:用"教练制"重塑机器人学习的范式
论文中最让我兴奋的不是那些刷榜的数字,而是 Figure 14-16 展示的"语言教练"机制。

人类可以用语言一步步指导 π₀.₇ 完成一个从未见过的任务(比如用空气炸锅烤红薯),然后把这些语言指令作为训练数据,训练一个高层策略来自动生成这些指令。结果是:你不需要任何遥操作数据,只需要用语言"教"机器人一次,它就能自主完成这个任务。
这个机制让我想到了一个更大胆的应用场景:分布式的机器人技能共享网络。 想象一下,一个仓库里的机器人 A 在人类教练指导下学会了"处理退货包裹",这些教练语言可以被提炼成高层策略,然后发送给全球各地仓库的机器人 B、C、D......它们都能零样本执行这个任务,因为它们共享同一个底层 π₀.₇,只需要一个新的高层策略(语言规划器)。这比传统的"在每个机器人上收集数据然后微调"的范式高效几个数量级。
更进一步,这个机制可以与 RL 结合:先用语言教练快速获得一个"能做但做不好"的策略,然后用 RL 在目标环境中自主优化。论文提到 π₀.₇ 的未见任务成功率在 60-80% 范围------这个"及格线"正好是 RL 的理想起点,因为 RL 需要一个能偶尔成功的初始策略才能有效探索。
一句话带走
π₀.₇ 的本质贡献不是更大的模型或更多的数据,而是证明了丰富的上下文提示词是解锁机器人基础模型组合泛化能力的关键杠杆------就像 Chain-of-Thought 解锁了 LLM 的推理能力一样。
最该记住的一个词:可引导性(Steerability)------通过精确控制提示词中的元数据、子目标图像和子任务指令,你可以在测试时精确"驾驶"这个通用模型去完成它从未被专门训练过的任务。
谁该读这篇论文: 任何在做机器人学习、VLA、或者对"如何让基础模型从杂乱数据中高效学习"感兴趣的研究者。特别是如果你正在为数据质量筛选而头疼,这篇论文的元数据提示方案提供了一个优雅的替代思路。
立刻可以尝试的下一步: 如果你有自己的机器人数据集(即使是小规模的),试着给每条轨迹标注几个简单的元标签(质量、速度、是否出错),然后在训练时把这些标签作为文本提示加入上下文。这是最容易复现的部分,也是论文中效果最显著的设计之一。