Databend db-archiver 数据归档压测报告
背景
本次压测目标为使用 db-archiver 从 MySQL 归档数据到 Databend Cloud, 归档的数据量为一亿条数据。
准备工作
Create target databend table
首先到 Databend Cloud worksheet 中根据源表结构创建目标表:
CREATE TABLE test_table1 (id INT64, field1 VARCHAR(255), field2 VARCHAR(255), field3 VARCHAR(255), field4 VARCHAR(255), field5 VARCHAR(255), field6 VARCHAR(255), field7 VARCHAR(255), field8 VARCHAR(255), field9 VARCHAR(255), field10 VARCHAR(255), field11 VARCHAR(255), field12 VARCHAR(255), field13 VARCHAR(255), field14 VARCHAR(255), field15 VARCHAR(255), field16 VARCHAR(255), field17 VARCHAR(255), field18 VARCHAR(255), field19 VARCHAR(255), field20 VARCHAR(255));总共 21 个字段,其中 id 在源表中自增主键。
启动 small warehouse
到 Databend Cloud 上启动 small warehouse 用作同步目标,本次我们选择 Databend Cloud的阿里云北京区。
准备北京区阿里云 ECS
为了减小跨区域的网络延迟影响,我们同样选择开启一个北京区的 ECS 作为我们同步任务执行的地方。
db-archiver 的配置文件
{
"sourceHost": "127.0.0.1",
"sourcePort": 3306,
"sourceUser": "root",
"sourcePass": "",
"sourceDB": "mydb",
"sourceTable": "test_table1",
"sourceQuery": "select * from mydb.test_table1",
"sourceWhereCondition": "id < 100000000",
"sourceSplitKey": "id",
"databendDSN": "https://user:password@tnf34b0rm--elt-wh-s.gw.aliyun-cn-beijing.default.databend.cn:443",
"databendTable": "default.test_table1",
"batchSize": 50000,
"batchMaxInterval": 30,
"copyPurge":true,
"copyForce":true,
"disableVariantCheck": false,
"userStage": "~",
"deleteAfterSync": false,
"maxThread": 20
}更多详细配置可以参考:https://github.com/databendcloud/db-archiver?tab=readme-ov-file#parameter-references
准备一亿条源表数据
往源表中插入一亿条数据。
开始压测
所以这里同步的前置条件为:
- 测试区域:databend cloud cn 北京区
- Databend warehouse 配置:small warehouse
- 运行机器配置: 8c16g
- 运行机器所在区域:阿里云北京区
- 一亿条数据-MySQL
这里压测三波,每次的压测的结果以及配置如下:
| 开启线程 | BatchSize | 完成时间 |
|---|---|---|
| 1 | 20000 | 85min |
| 10 | 40000 | 13min |
| 10 | 50000 | 11.5min |
| 20 | 60000 | 18min |
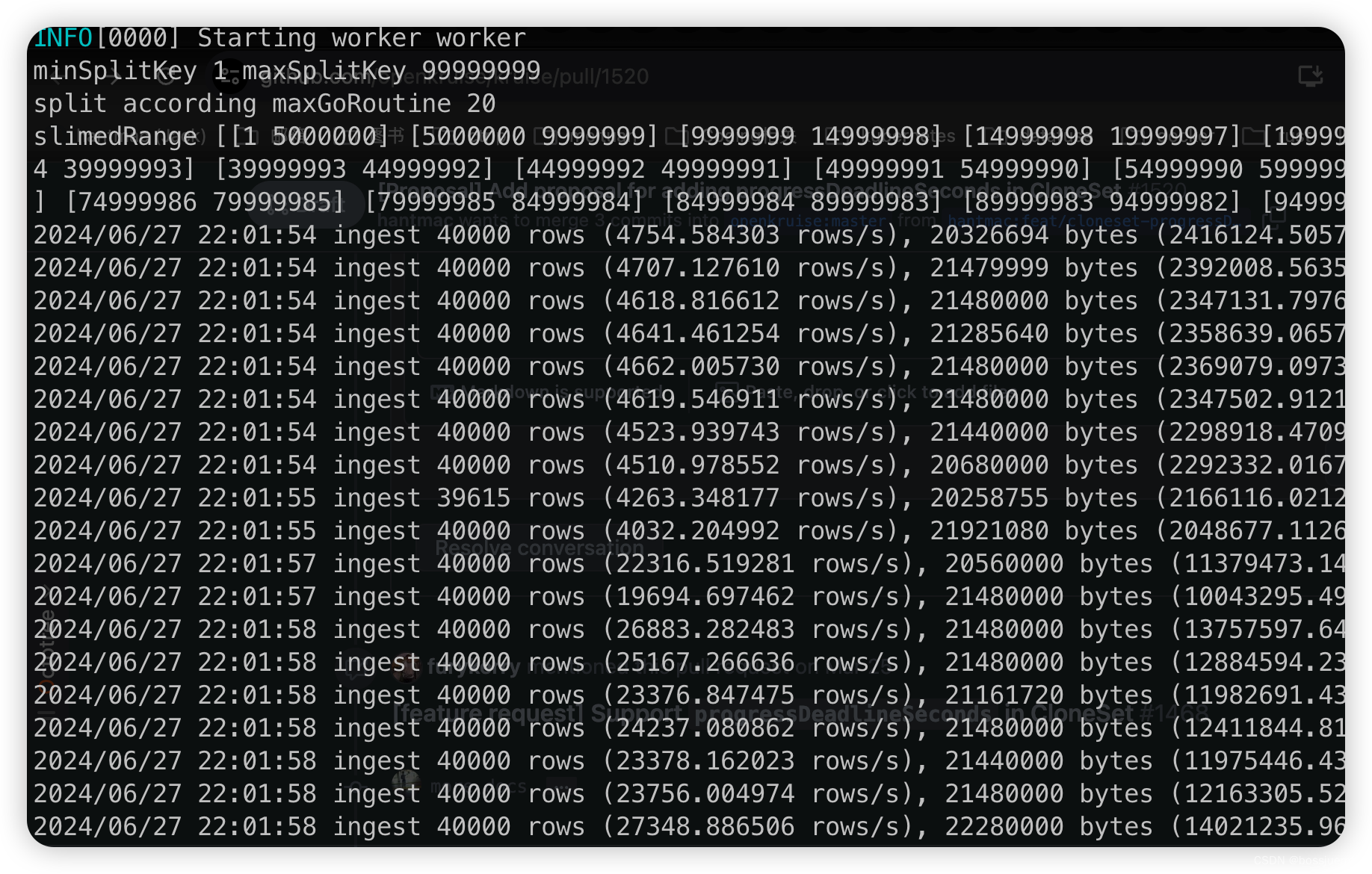 |
可以看到 db-archiver 的线程数比较重要,但线程也不能无限开大,要根据所在机器的具体配置调优。并且 BatchSize 也不是越大越好,这里推荐 10 个线程配合 40000 的 batchSize。具体情况可以由客户自行测试调优。