CTE是『common table expression』的缩写,中文翻译过来就是『公共表表达式』,使用它可以为临时查询结果命名,命名后可以在后续的查询语句中反复引用。CTE完整语法格式如下:
sql
WITH [RECURSIVE]
cte_name [(column_list)] AS (
subquery
)
[, cte_name [(column_list)] AS (subquery)] ...
SELECT ... FROM cte_name ...;『RECURSIVE』是递归的意思,但是它可选,表示CTE有两种模式:普通CTE和递归CTE。
官方文档:https://dev.mysql.com/doc/refman/8.0/en/with.html#common-table-expressions-recursive-examples
一、普通CTE
普通CTE写法是最常用的写法,一个经典的写法如下所示:
sql
WITH
cte1 AS (SELECT a, b FROM table1),
cte2 AS (SELECT c, d FROM table2)
SELECT b, d FROM cte1 JOIN cte2
WHERE cte1.a = cte2.c;这个没什么好说的,非常简单,需要注意的是,不只是可以写select语句,还可以写update、delete语句:
sql
WITH ... SELECT ...
WITH ... UPDATE ...
WITH ... DELETE ...二、递归CTE
递归CTE是一种在查询中引用自身的写法,是处理层次结构或树形数据的强大工具。其完整语法如下所示:
sql
WITH RECURSIVE cte_name [(column_list)] AS (
-- 初始化查询提供初始结果集
SELECT initial_columns
FROM initial_table
WHERE initial_condition
UNION [ALL | DISTINCT]
-- 递归部分
SELECT recursive_columns
FROM recursive_table
JOIN cte_name ON join_condition
WHERE recursive_condition
)
SELECT * FROM cte_name [OPTIONAL_CLAUSES];递归CTE的子查询分为两部分,通过UNION [ALL | DISTINCT]连接:
sql
SELECT ... -- 非递归select语句,提供初始结果集,不引用CTE名字
UNION [ALL | DISTINCT]
SELECT ... -- 递归select语句,引用CTE名字需要注意的是基础部分和递归部分是通过UNION [ALL | DISTINCT]连接的,虽然语法上允许UNION DISTINCT去重,但是实际上几乎都是使用UNION ALL。
递归CTE语法有如下限制使用条件:
-
基础部分的列长度将会限制递归部分的列长度
-
递归select语句不能包含如下语句:聚合函数比如
SUM()、窗口函数、GROUP BY、order by、distinct -
递归select语句只能引用一次CTE,并且只能在from语句中使用,不能在任何子查询中使用;可以使用join语句与其它表连接,但是在这种使用场景中,CTE不能位于
LEFT JOIN的右侧。
1、案例讲解
递归CTE不是很容易理解,下面通过几个案例来说明下:
案例1:打印1到5
sql
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte WHERE n < 5
)
SELECT * FROM cte;输出结果:
sql
+------+
| n |
+------+
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
+------+首先执行基础查询部分 SELECT 1,生成初始结果集,此时CTE的结果为:[1];
第一次递归迭代 :从CTE中取出n=1,执行递归部分 SELECT n + 1 FROM cte WHERE n < 5,计算:1 + 1 = 2,,将结果2添加到CTE中,现在CTE的结果为:[1, 2]。
第二次递归迭代 :从CTE中取出n=2,执行递归部分,计算:2 + 1 = 3,将结果3添加到CTE中,现在CTE的结果为:[1, 2, 3]。
第三次递归迭代 :从CTE中取出n=3,执行递归部分,计算:3 + 1 = 4,将结果4添加到CTE中,现在CTE的结果为:[1, 2, 3, 4]。
第四次递归迭代 :从CTE中取出n=4,执行递归部分,计算:4 + 1 = 5,将结果5添加到CTE中,现在CTE的结果为:[1, 2, 3, 4, 5]。
终止条件检查 :下一次迭代时n=5,不满足WHERE条件 n < 5,递归终止。
所以,最终的查询结果就是[1, 2, 3, 4, 5]
案例2:重复字符串
在下面这个案例中,将要验证递归CTE的一个特性:基础部分的列长度将会限制递归部分的列长度。什么意思呢?看下面的sql语句:
sql
WITH RECURSIVE cte AS
(
SELECT 1 AS n, 'abc' AS str
UNION ALL
SELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;正常来说,我们预测输出如下所示:
sql
+------+--------------+
| n | str |
+------+--------------+
| 1 | abc |
| 2 | abcabc |
| 3 | abcabcabcabc |
+------+--------------+但是在实际执行过程中,如果是严格模式下的运行,会提示报错:
sql
错误代码: 1406
Data too long for column 'str' at row 1如果是非严格模式下的运行,则会有结果如下所示:
sql
+------+------+
| n | str |
+------+------+
| 1 | abc |
| 2 | abc |
| 3 | abc |
+------+------+结果总是和我们的预测不一样。这是因为在初始语句SELECT 1 AS n, 'abc' AS str中,'abc'字符串长度为3,这限制了之后的递归查询语句中的所有str列长度都是3,那么'abcabc'就存储不了了,在非严格模式下,结果会被截断,仍然是'abc';在严格模式下,则会报错。
解决方案就是在初始语句中重新定义列长度:
sql
WITH RECURSIVE cte AS
(
SELECT 1 AS n, CAST('abc' AS CHAR(20)) AS str
UNION ALL
SELECT n + 1, CONCAT(str, str) FROM cte WHERE n < 3
)
SELECT * FROM cte;通过CAST('abc' AS CHAR(20)) 将列长度扩展到了20,这样就能在接下来的递归中容纳的了abcabcabc了。
案例3:斐波那契数列
斐波那契数列的定义如下:
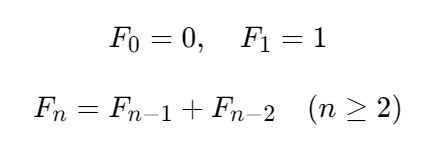
按照定义,前10个斐波那契额数列如下所示:0,1,1,2,3,5,8,13,21,34
写下sql打印如上斐波那契额数列:
sql
WITH RECURSIVE cte AS
(
SELECT 1 AS n,0 AS fn,1 AS fn_next
UNION ALL
SELECT n+1,fn_next,fn+fn_next FROM cte WHERE n<10
)
SELECT * FROM cte案例4:日期序列生成
首先先创建表并插入数据:
sql
-- 创建 sales 表
CREATE TABLE sales (
DATE DATE,
price DECIMAL(10,2)
);
-- 插入数据
INSERT INTO sales (DATE, price) VALUES
('2017-01-03', 100.00),
('2017-01-03', 200.00),
('2017-01-06', 50.00),
('2017-01-08', 10.00),
('2017-01-08', 20.00),
('2017-01-08', 150.00),
('2017-01-10', 5.00);我们现在根据日期分组统计销售额:
sql
mysql> SELECT date, SUM(price) AS sum_price
FROM sales
GROUP BY date
ORDER BY date;
+------------+-----------+
| date | sum_price |
+------------+-----------+
| 2017-01-03 | 300.00 |
| 2017-01-06 | 50.00 |
| 2017-01-08 | 180.00 |
| 2017-01-10 | 5.00 |
+------------+-----------+虽然查询结果是对的,但是这并不是我想要的结果,我想要的结果应该是连续的日期,如果销售额为0则显示0,我想要的输出应该是这样:
sql
+------------+-----------+
| date | sum_price |
+------------+-----------+
| 2017-01-03 | 300.00 |
| 2017-01-04 | 0.00 |
| 2017-01-05 | 0.00 |
| 2017-01-06 | 50.00 |
| 2017-01-07 | 0.00 |
| 2017-01-08 | 180.00 |
| 2017-01-09 | 0.00 |
| 2017-01-10 | 5.00 |
+------------+-----------+可以借助递归CTE实现该功能:
sql
WITH RECURSIVE dates (date) AS
(
SELECT MIN(date) FROM sales
UNION ALL
SELECT date + INTERVAL 1 DAY FROM dates
WHERE date + INTERVAL 1 DAY <= (SELECT MAX(date) FROM sales)
)
SELECT dates.date, COALESCE(SUM(price), 0) AS sum_price
FROM dates LEFT JOIN sales ON dates.date = sales.date
GROUP BY dates.date
ORDER BY dates.date;当然这个查询有些复杂,最重要的一部分是这部分sql:
sql
WITH RECURSIVE dates (DATE) AS
(
SELECT MIN(DATE) FROM sales
UNION ALL
SELECT DATE + INTERVAL 1 DAY FROM dates
WHERE DATE + INTERVAL 1 DAY <= (SELECT MAX(DATE) FROM sales)
)
SELECT dates.date FROM dates这部分sql生成了sales表中从最小日期到最大日期之间的所有日期列表:
sql
+------------+
| date |
+------------+
| 2017-01-03 |
| 2017-01-04 |
| 2017-01-05 |
| 2017-01-06 |
| 2017-01-07 |
| 2017-01-08 |
| 2017-01-09 |
| 2017-01-10 |
+------------+然后通过左外连接sales表分组统计销售额,这样就实现了日期的连续列表。
COALESCE函数用于返回第一个不为NULL的值,在此处COALESCE(SUM(price), 0)的意思是如果没有销售额,则为0。
案例5:树状组织架构
接下来创建一个雇员表来演示树状组织架构:
sql
CREATE TABLE employees (
id INT PRIMARY KEY NOT NULL,
name VARCHAR(100) NOT NULL,
manager_id INT NULL,
INDEX (manager_id),
FOREIGN KEY (manager_id) REFERENCES employees (id)
);
INSERT INTO employees VALUES
(333, "Yasmina", NULL), # Yasmina is the CEO (manager_id is NULL)
(198, "John", 333), # John has ID 198 and reports to 333 (Yasmina)
(692, "Tarek", 333),
(29, "Pedro", 198),
(4610, "Sarah", 29),
(72, "Pierre", 29),
(123, "Adil", 692);执行完上述sql,表中内容如下所示:
sql
+------+---------+------------+
| id | name | manager_id |
+------+---------+------------+
| 29 | Pedro | 198 |
| 72 | Pierre | 29 |
| 123 | Adil | 692 |
| 198 | John | 333 |
| 333 | Yasmina | NULL |
| 692 | Tarek | 333 |
| 4610 | Sarah | 29 |
+------+---------+------------+现在我们要写一个查询sql,用于查询每个雇员向上汇报的路径,其查询结果应当如下所示:
sql
+------+---------+-----------------+
| id | name | path |
+------+---------+-----------------+
| 333 | Yasmina | 333 |
| 198 | John | 333,198 |
| 29 | Pedro | 333,198,29 |
| 4610 | Sarah | 333,198,29,4610 |
| 72 | Pierre | 333,198,29,72 |
| 692 | Tarek | 333,692 |
| 123 | Adil | 333,692,123 |
+------+---------+-----------------+查询sql如下:
sql
WITH RECURSIVE employee_paths (id, name, path) AS
(
SELECT id, name, CAST(id AS CHAR(200))
FROM employees
WHERE manager_id IS NULL
UNION ALL
SELECT e.id, e.name, CONCAT(ep.path, ',', e.id)
FROM employee_paths AS ep JOIN employees AS e
ON ep.id = e.manager_id
)
SELECT * FROM employee_paths ORDER BY path;这个CTE语句从根节点(CEO)节点开始查找,查找谁的上级是CEO,然后依次递归查找,直到普通雇员为止,由于普通雇员不是谁的上级,所以JOIN语句会返回空,递归结束。
进阶问题1:查询Sarah的向上汇报路径,每个节点返回一条数据
sql
WITH RECURSIVE employees_paths(id,NAME,manager_id) AS
(
SELECT id,NAME,manager_id FROM `employees`
WHERE NAME = 'Sarah'
UNION ALL
SELECT employees.id,employees.name,employees.manager_id FROM employees_paths
JOIN `employees` ON employees_paths.manager_id = employees.`id`
)
SELECT * FROM employees_paths查询结果:
sql
id name manager_id
------ ------- ------------
4610 Sarah 29
29 Pedro 198
198 John 333
333 Yasmina (NULL)进阶问题2:查询John的所有下级节点
这个问题要求的是John的所有下级节点,由于子节点也有子节点,所以需要递归查询,查询sql如下:
sql
WITH RECURSIVE employees_paths(id,NAME,manager_id) AS
(
SELECT id,NAME,manager_id FROM `employees`
WHERE NAME = 'John'
UNION ALL
SELECT employees.id,employees.name,employees.manager_id FROM employees_paths
JOIN `employees` ON employees_paths.id = employees.`manager_id`
)
SELECT * FROM employees_paths查询结果:
sql
id NAME manager_id
------ ------ ------------
198 John 333
29 Pedro 198
72 Pierre 29
4610 Sarah 29这个问题的查询sql和上一个问题的查询sql非常像,只是将连接条件互换了下,其结果就完全不一样了。
2、递归失控
如果递归终止条件设置的不正确,则会导致递归失控,看下面的案例sql:
sql
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte
)
SELECT * FROM cte在mysql中执行上述语句,会提示如下报错:
sql
错误代码: 3636
Recursive query aborted after 1001 iterations. Try increasing @@cte_max_recursion_depth to a larger value.这意思是递归次数超过了系统限制,拒绝执行剩余递归查询。从报错上来看,系统默认设置的递归最大次数是1000次,可以在命令行中动态调整cte_max_recursion_depth的值设置最大递归次数,比如我执行了命令
sql
SET SESSION cte_max_recursion_depth = 10再次执行程序,报错提示就变成了:
sql
错误代码: 3636
Recursive query aborted after 11 iterations. Try increasing @@cte_max_recursion_depth to a larger value.另外,还可以设置 max_execution_time 值限制递归查询最大超时时间,单位是毫秒,默认值0表示无超时时间限制。
3、使用limit终止递归
在mysql8.0.19开始,mysql开始支持使用limit语句终止递归,比如在上面的查询中:
sql
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte
)
SELECT * FROM cte由于没有设置递归终止条件,会在递归1000次以后,触发系统递归最大次数的阈值上限从而报错。通过limit语句也可以终止递归:
sql
WITH RECURSIVE cte (n) AS
(
SELECT 1
UNION ALL
SELECT n + 1 FROM cte LIMIT 1001
)
SELECT * FROM cte这样会查询出来1到1001共1001个数。