哨兵机制概念
在传统主从复制机制中,会存在一些问题:
主节点发生故障时,进行主备切换的过程是复杂的,需要人工参与,导致故障恢复时间无法保障。
主节点可以将读压力分散出去,但写压力/存储压力是无法被分担的,还是受到单机的限制。
哨兵机制就是为了解决第一个高可用问题的
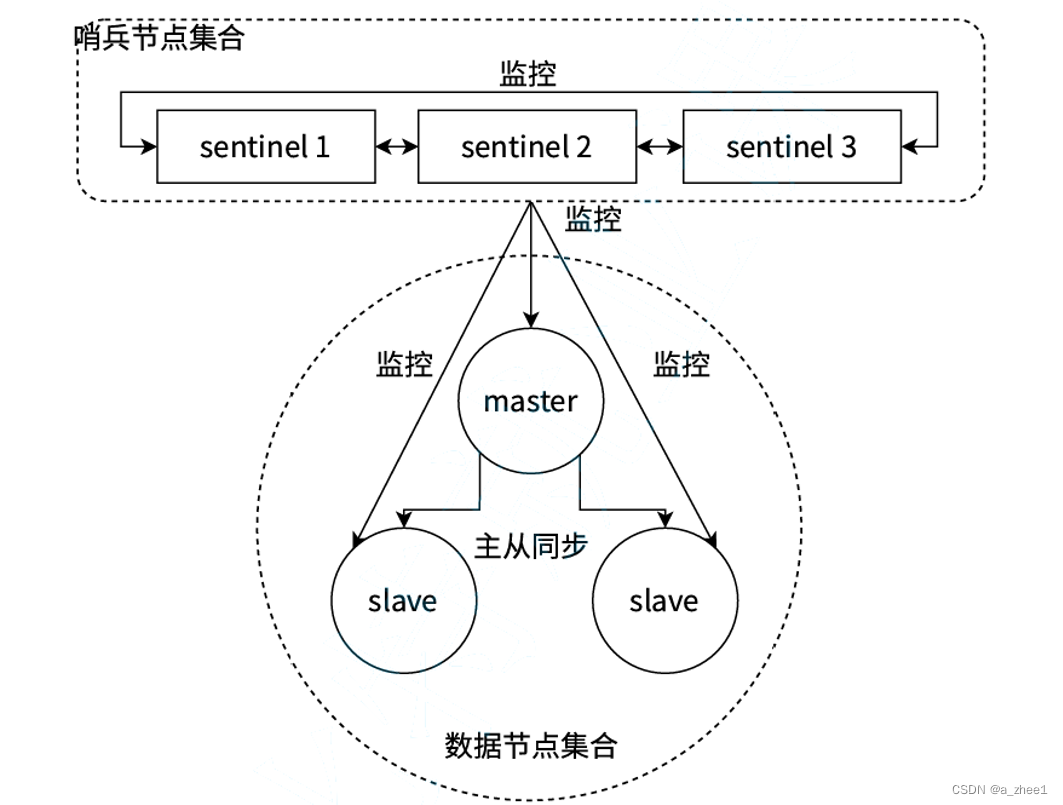
当主节点出现故障时,哨兵机制能自动完成故障发现和故障转移,并通知应用方,从而实现真正的高可用。 哨兵机制是一个分布式架构,其中包含若干个redis哨兵节点和Redis数据节点,每个哨兵节点会对数据节点和其余Sentinel节点进行监控,当它发现节点不可达时,会对节点做下线标识。如果下线的是主节点,它还会和其他的哨兵节点进行"协商",当大多数哨兵节点对主节点不可达这个结论达成共识之后,它们会在内部"选举"出一个领导节点来完成自动故障转移的工作,同时将这个变化实时通知给Redis应用方。整个过程是完全自动的,不需要人工介入。
环境规划
redis版本:5.0.9
我们将使用docker搭建redis哨兵环境
docker-compose 来进行容器编排
1)创建三个容器,作为redis的数据节点(主从结构,一主两从)
2)创建三个容器,作为redis的哨兵节点
目录结构:
搭建数据节点
docker-compose.yml是 Docker Compose 使用的配置文件,它定义了多个 Docker 容器的服务、网络和卷的配置。通过这个文件,你可以使用一条命令来批量启动多个docker容器
配置docker-compose.yml
version: '3.7'
services:
master:
image: 'redis:5.0.9'
container_name: redis-master
restart: always
command: redis-server --appendonly yes
ports:
- 6379:6379
slave1:
image: 'redis:5.0.9'
container_name: redis-slave1
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6380:6379
slave2:
image: 'redis:5.0.9'
container_name: redis-slave2
restart: always
command: redis-server --appendonly yes --slaveof redis-master 6379
ports:
- 6381:6379version: '3.7'指定 Docker Compose 文件的版本。版本 3.7 支持更高级的功能和配置选项。
services:定义一组服务,每个服务对应一个容器。在这里,我们定义了三个服务,分别是主节点master和两个从节点slave。
image:指定要使用的镜像,这里是我们提前拉取的redis:5.0.9镜像
container_name: 指定容器的名称。这样,你可以通过这个名称来引用和管理容器。
restart: always:指定容器的重启策略。在这里配置为always,表示无论容器是因何原因退出,Docker 都会自动重启该容器。
command:设置启动命令,为主节点和从节点配置不同的命令
ports:映射主机端口到容器端口。前一个是主机端口,后一个是容器端口。就是说,在主机里这三个redis分别是6379,6380,6381端口,映射到各自容器的6379端口
启动docker compose配置的服务
在docker-compose.yml配置文件同级目录下使用命令:
sudo docker-compose up -d
up表示构建、(重新)创建、启动并连接配置文件中定义的所有服务。如果某些服务已经在运行,up命令会重新启动它们。
-d表示 --detach 选项,它会将服务在后台运行。如果没有-d选项,服务将会在前台运行,并输出日志信息到当前终端窗口

如果启动后发现前面的配置有误,需要重新操作,使用 docker-compose down 即可停止并删除 刚才创建好的容器.
查看运行日志
同级目录下使用命令:
sudo docker-compose logs

可以看见成功加载了三个容器
也可以使用命令:
sudo docker ps -a
显示容器的列表

可以在最后一列看到名字分别是redis-slave1、redis-slave2、redis-master代表三个数据节点
搭建成功
验证
连接主节点
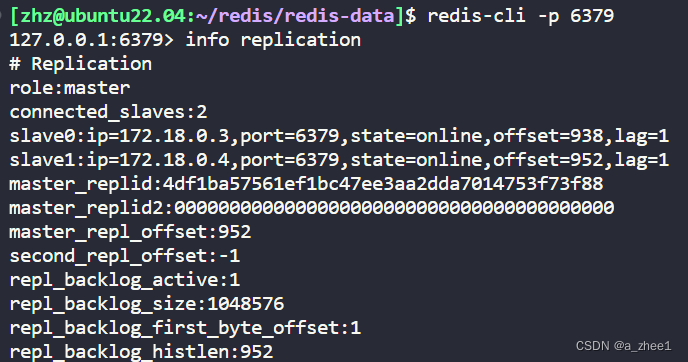
可以看到,主节点,有两个连接的从节点
搭建哨兵节点
(其实也可以把哨兵节点的yml配置文件和上面的配置文件写到一起,这里分成两组,主要是为了方便观察)
哨兵节点配置
放在redis-sentinel目录中,分别创建三个,内容完全相同
bind 0.0.0.0
port 26379
sentinel monitor redis-master redis-master 6379 2
sentinel down-after-milliseconds redis-master 1000sentinel monitor表示监听的redis节点,第一个redis-master是给哨兵内部的名字,第二个是主节点ip,但是这里用的是docker,所以就写容器名,会自动DNS成对应的ip,6379表示端口,2表示票数,如果有哨兵节点觉得主节点挂了,那就投1票,当票数大于等于2时,就认为主节点真的挂了,就会启动后面的流程
sentinel down-after-milliseconds redis-master 1000主节点和哨兵之间通过心跳包来进行沟通.如果心跳包在指定的时间(1000ms)内还没回来,就视为是节点出现故障.
为什么要创建三个一样的文件,而不用同一个呢?
因为redis-sentinel 在运行中可能会对配置进行重写,修改文件内容.如果用一份文件,就可能出现修改 混乱的情况.
配置docker-compose.yml
version: '3.7'
services:
sentinel1:
image: 'redis:5.0.9'
container_name: redis-sentinel-1
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel1.conf:/etc/redis/sentinel.conf
ports:
- 26379:26379
sentinel2:
image: 'redis:5.0.9'
container_name: redis-sentinel-2
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel2.conf:/etc/redis/sentinel.conf
ports:
- 26380:26379
sentinel3:
image: 'redis:5.0.9'
container_name: redis-sentinel-3
restart: always
command: redis-sentinel /etc/redis/sentinel.conf
volumes:
- ./sentinel3.conf:/etc/redis/sentinel.conf
ports:
- 26381:26379
networks:
default:
external:
name: redis-data_default volume:配置挂载的卷,将主机上的文件或目录映射到容器内部。
networks:表示要加入的网络而不是创建新的网络,因为是两个配置文件,会启用两个局域网,为了让数据节点和哨兵节点互相认识并通信,所以要加入到一个网络中。
启动docker compose配置的服务
在docker-compose.yml配置文件同级目录下使用命令:
sudo docker-compose up -d

查看运行日志
同级目录下使用命令:
sudo docker-compose logs
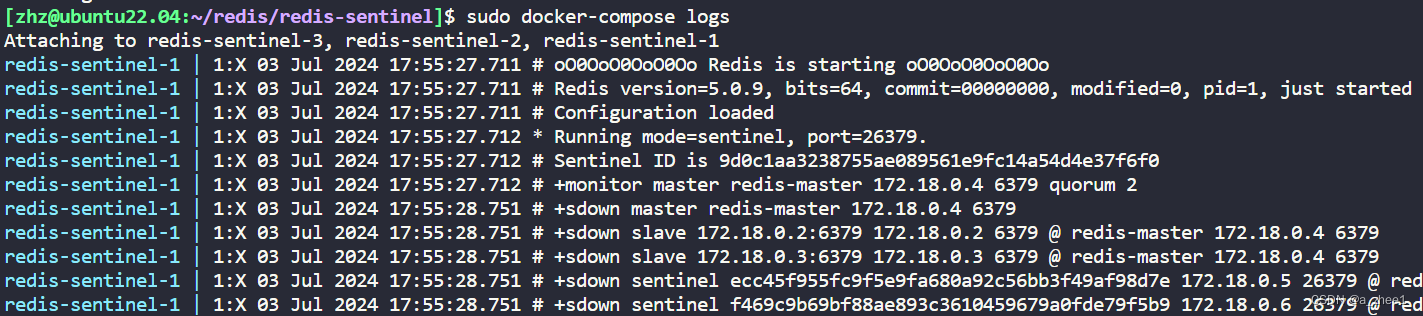
可以发现正在监控主节点172.18.0.4 6379
验证哨兵机制
主节点挂掉
sudo docker stop redis-master

查看哨兵日志
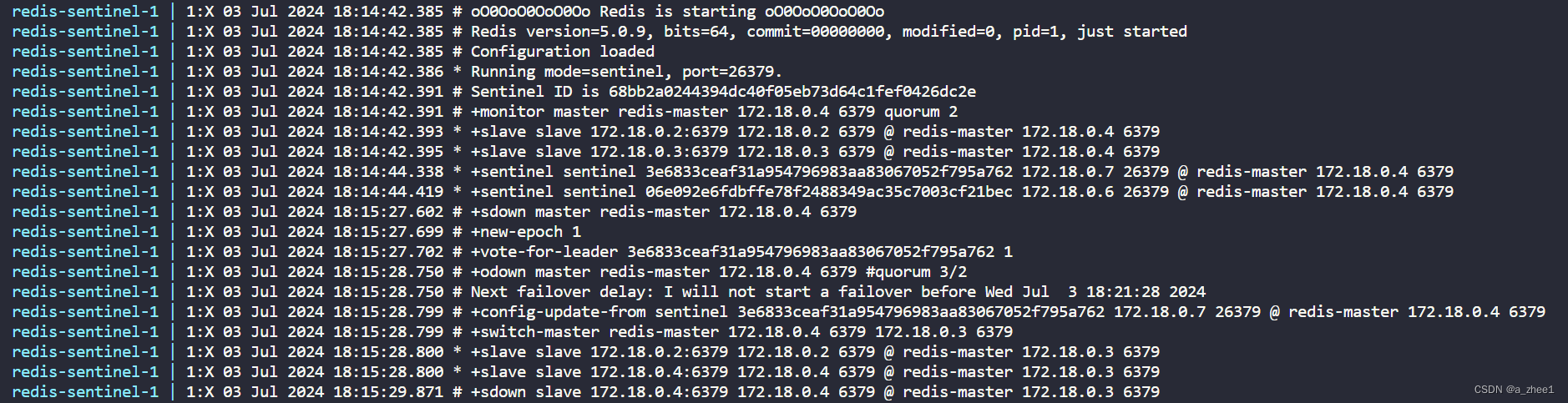
这里从sdown master redis-master 172.18.0.4 6379之前都是启动时的日志
后面是主节点挂了后的日志
sdown是主观下线,就是说这个节点主观认为主节点挂了(投一票)
odown是客观下线,就是说主节点客观挂了(票数超过设置)

表示票数达到3/2,超过规定, 认为主节点已经不能正常工作了,开启选取新的主节点的流程

表示选取172.18.0.3作为主节点代替172.18.0.4
重启原来的主节点
sudo docker start redis-master

这个节点变成从节点,并设置主节点为172.18.0.3
选取新主节点流程
主观下线
当redis-master 宕机,此时redis-master和三个哨兵之间的心跳包就没有了. 此时,站在三个哨兵的角度来看,redis-master出现严重故障。因此三个哨兵均会把redis-master判定为主观下线(SDown)
并投一票故障
客观下线
当故障得票数>=配置的法定票数之后,意味着redis-master故障这个事情被坐实了.此时触发客观下线(ODown)
选举出哨兵的leader
因为选取新主节点的工作不能让大家一起做,会乱套,所以现在需要在哨兵节点中选举出一个领导leader节点,来选举新主节点
这个选举的过程涉及到 Raft 算法
1.每个哨兵节点都给其他所有哨兵节点,发起一个"拉票请求"
2.收到拉票请求的节点,会回复一个"投票响应".响应的结果有两种可能,投or不投
如果已经发现主节点客观下线,需要选举leader,但是没有收到拉票请求,就会投给自己,然后向其他哨兵拉票。
如果哨兵收到多个拉票请求,会投票给收到第一个请求的哨兵。
3.一轮投票完成之后,发现得票超过半数的节点,自动成为leader
如果平票,再投一次
把哨兵节点的个数设置为奇数,可以减小平票的可能,提高效率
leader哨兵选举新主节点
leader 挑选出合适的slave成为新的 master
挑选规则:
1.比较优先级.优先级高(数值小的)的上位.优先级是redis配置文件中的配置项( slave-priority或replica-priority )
2.比较 replication offset 谁复制的数据多,高的上位
3.比较 run id ,谁的id小,谁上位.
选举后
当某个slave节点被指定为master之后,
-
leader 指定该节点执行 slave no one ,成为master
-
leader 指定剩余的slave节点,都依附于这个新master
注意事项
• 哨兵节点不能只有一个,否则哨兵节点挂了也会影响系统可用性.
• 哨兵节点最好是奇数个,方便选举leader,得票更容易超过半数.
• 哨兵节点不负责存储数据,仍然是redis主从节点负责存储.
• 哨兵+主从复制解决的问题是"提高可用性",不能解决"数据极端情况下写丢失"的问题.
• 哨兵+主从复制不能提高数据的存储容量,当我们需要存的数据接近或者超过机器的物理内存,这样的结构就难以胜任了。
为了能存储更多的数据,就引入了集群.