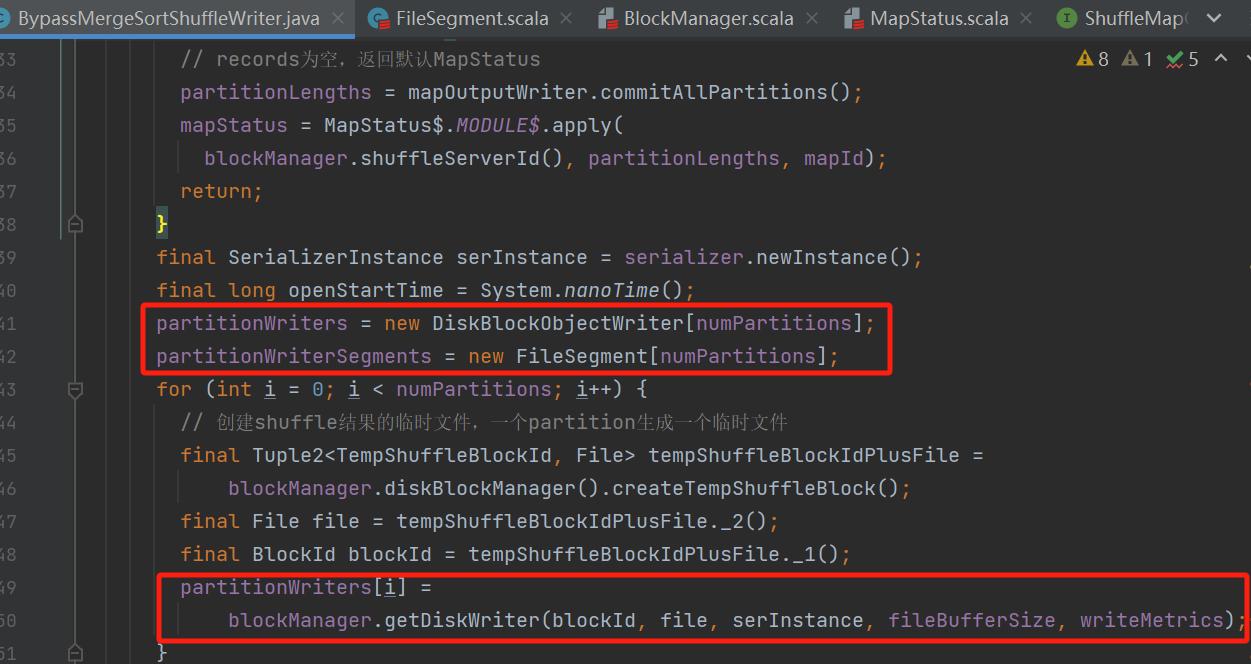
创建分区文件writer
每一个分区都生成一个临时文件,创建DiskBlockObjectWriter对象,放入partitionWriters
分区writer写入消息
遍历所有消息,每一条消息都使用分区器选择对应分区的writer然后写入

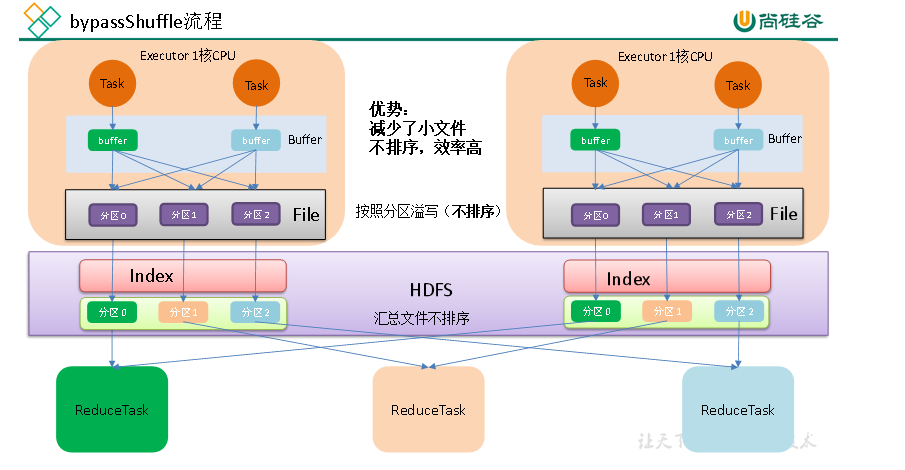
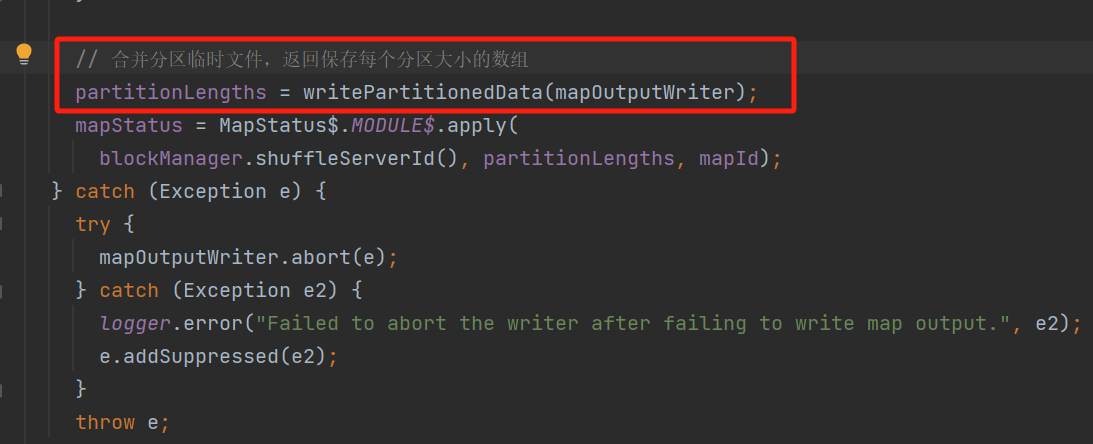
生成分区文件
将分区writer的数据flush,每个分区生成一个FlieSegment,保存在partitionWriterSegments
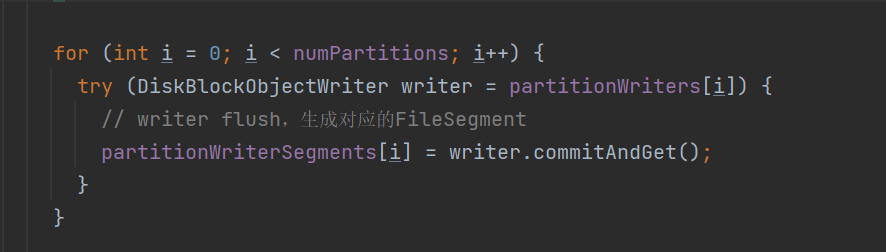
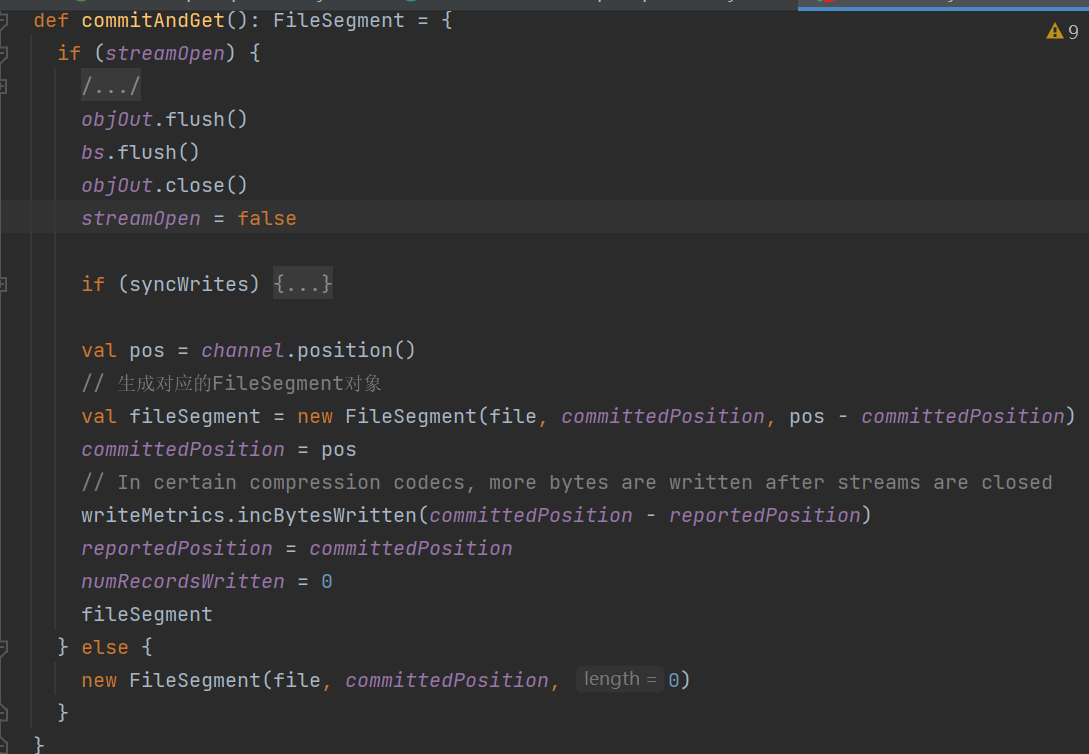
分区writer的commit
可以看到生成的fileSegment中file还是上面的分区临时文件
合并分区临时文件
遍历分区临时文件,获取对应的合并writer,将临时文件的数据写入到合并writer中
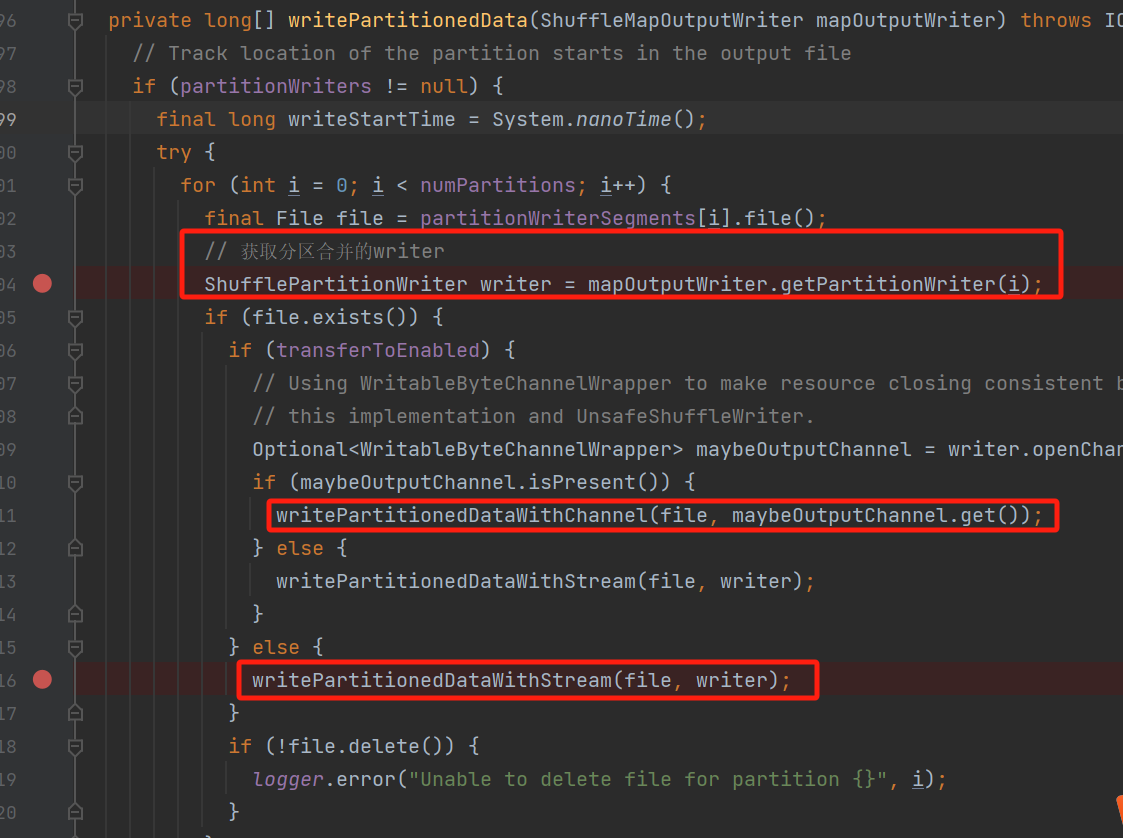
获取合并的writer
生成一个临时文件,多个reducer使用同一个临时文件。
每个分区都会生成一个LocalDiskShufflePartitionWriter
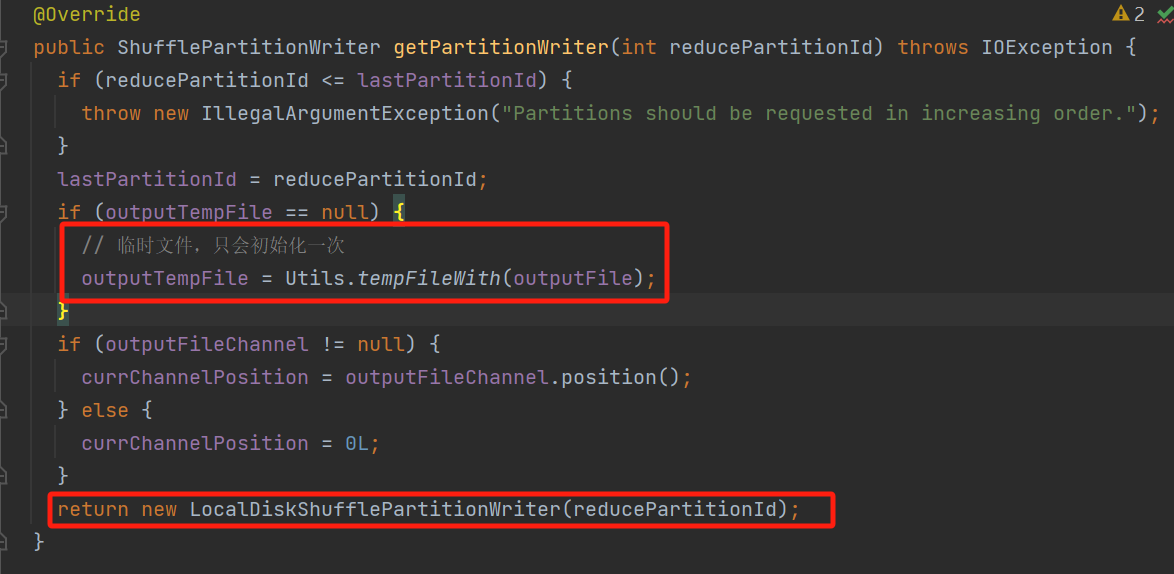
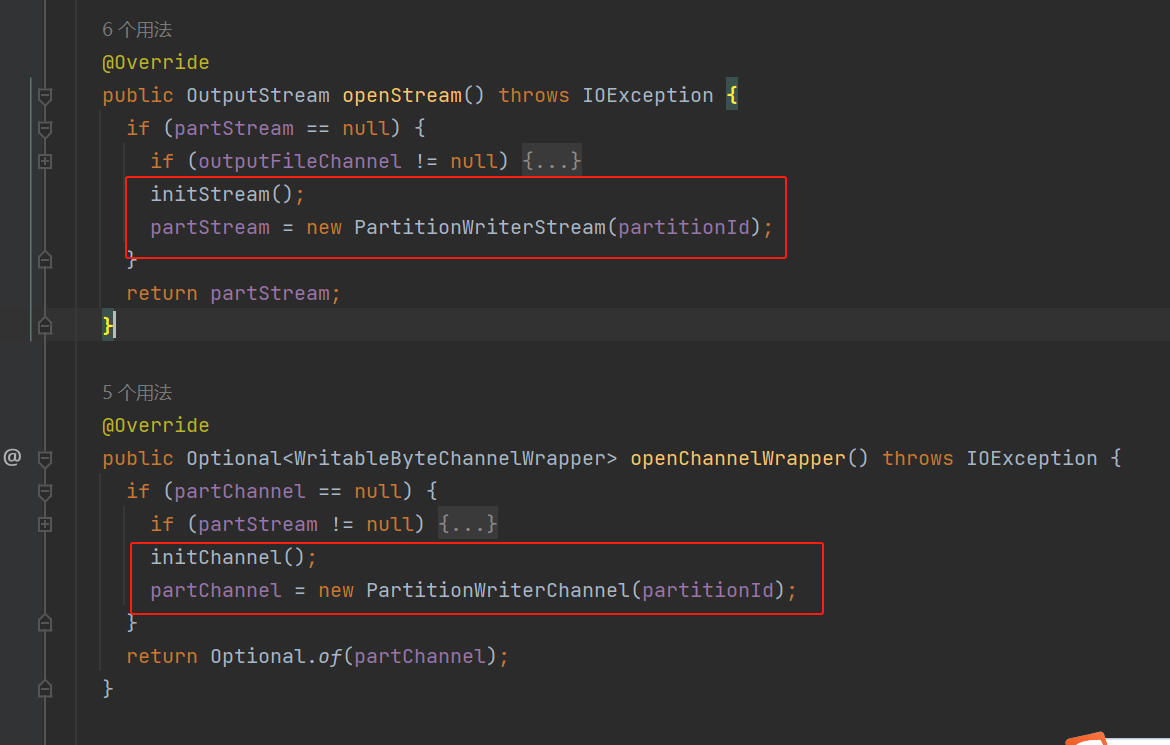
LocalDiskShufflePartitionWriter类核心方法有两个openStream、openChannelWrapper。
两个方法分别调用对应的init方法,返回PartitionWriterStream的stream对象和PartitionWriterChannel的channel对象。
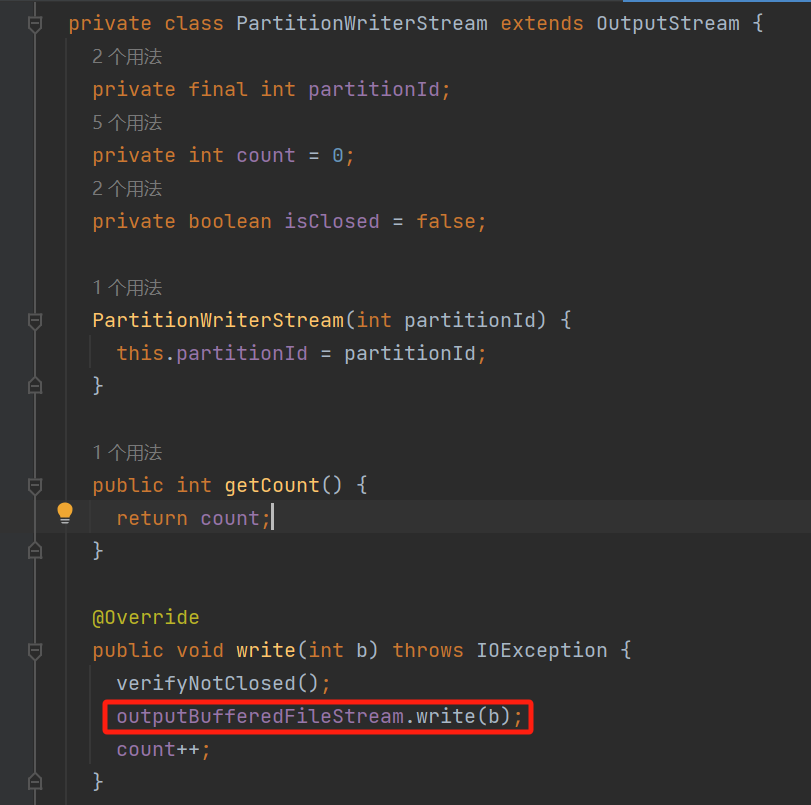
PartitionWriterStream的write方法中使用outputBufferedFileStream,在initStream中可以看到outputBufferedFileStream使用的上面生成的临时文件outputTempFile。
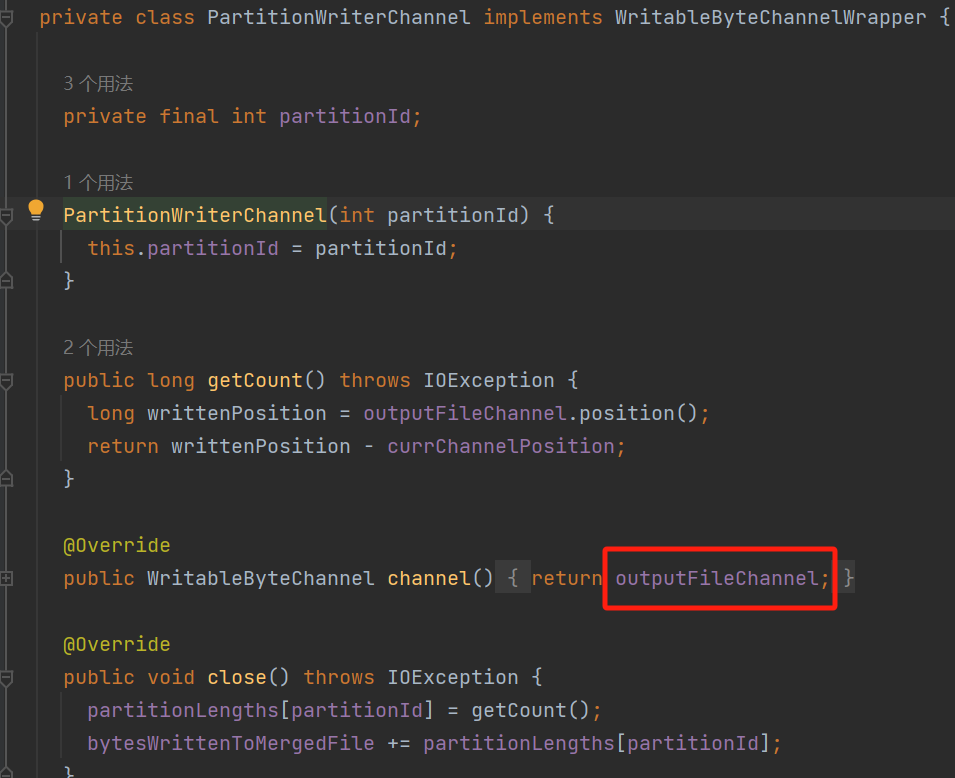
PartitionWriterChannel的channel方法返回的是outputFileChannel,outputFileChannel在initChannel中使用的也是上面生成的临时文件outputTempFile。
这表明无论使用stream还是channel,最后都是写入临时文件outputTempFile中。

临时文件数据写入合并writer
writePartitionedDataWithChannel是使用channel的方式,调用copyFileStreamNIO
writePartitionedDataWithStream是使用stream的方式,调用copyStream
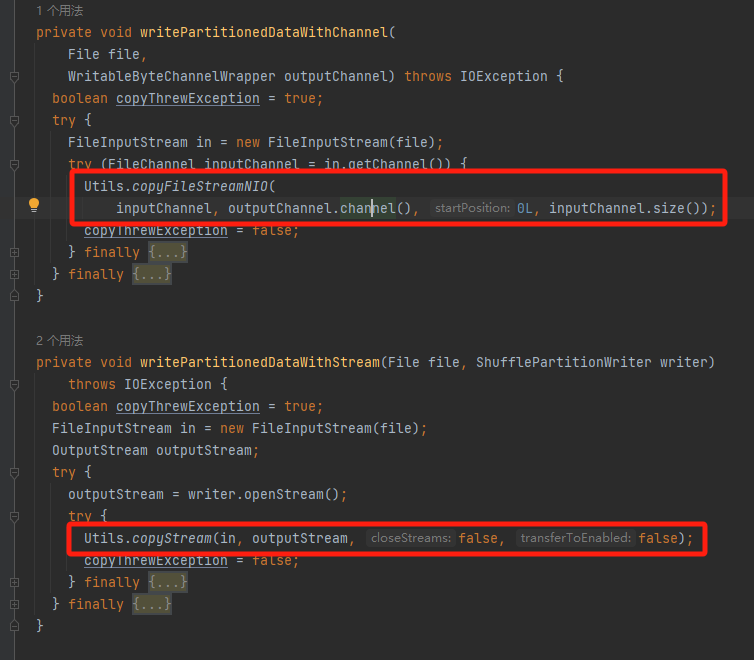
copyFileStreamNIO
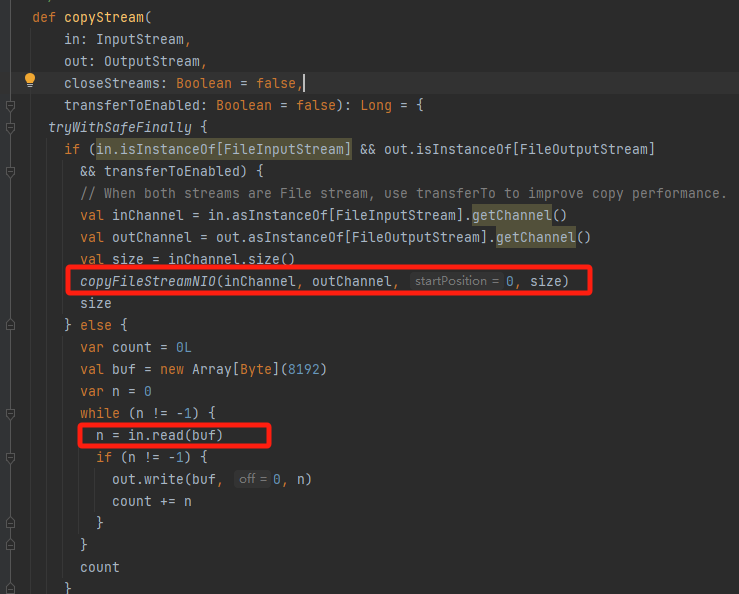
可以看到使用了transferTo方法(零拷贝)

copyStream
先判断是否能使用transferTo,能的话就调copyFileStreamNIO用零拷贝的方式,不行的话就走普通的流复制
最终的分区文件提交
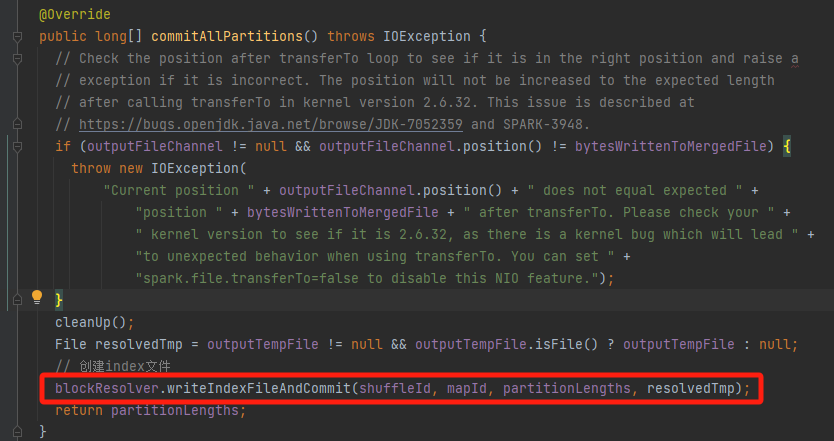
将最终的分区临时文件提交,生成对应的data文件和index文件。
可以看到是调用的IndexShuffleBlockResolver类的writeIndexFileAndCommit方法。