概述:项目开发中,在进行数据库表结构设计时,会根据业务需求及业务模块之间的关系,分析并设计表结构,由于业务之间相互关联,所以各个表结构之间也存在着各种联系,分为三种:
- 一对多
- 多对多
- 一对一
一、多表关系
一对多
- 案例:部门与员工的关系
- 关系:一个部门对应多个员工,一个员工对应一个部门
- 实现:在多的一方建立外键,指向一的一方的主键
多对多
- 案例:学生于课程的关系
- 关系:一个学生可以选修多门课程,一门课程也可以供多个学生选择
- 实现:建立第三张中间表,中间表至少包含两个外键,分别关联两方主键
sql
create table student(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '姓名',
no varchar(10) comment '学号'
) comment '学生表';
insert into student values (null,'lkh','20010202'),(null,'cxk','20010204'),(null,'lh','20010212');
create table course(
id int auto_increment primary key comment '主键ID',
name varchar(10) comment '课程名称'
) comment '课程表';
insert into course values (null,'java'),(null,'PHP'),(null,'MySQL'),(null,'C');
//中间表
create table student_course(
id int auto_increment primary key comment '主键',
studentid int not null comment '学生ID',
courseid int not null comment '课程ID',
constraint fk_courseid foreign key (courseid) references course(id),
constraint fk_studentid foreign key (studentid) references student(id)
) comment '学生课程中间表';
insert into student_course values (null,1,1),(null,1,2),(null,1,3),(null,2,2),(null,2,3),(null,3,4);一对一
- 案例:用户于用户详情的关系
- 关系:一对一关系,多用于单表拆分,将一张表的基础字段放在一张表中,其他详情字段放在另一张表中
- 实现:在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的UNIQUE
二、多表查询
- 指从多张表中查询数据
- 笛卡尔积:两个集合A和集合B的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
sql
-- 多表查询 -- 笛卡尔积
select * from emp ,dept where emp.dept_id = dept_id;分类
- 连接查询:
- 内连接:相当于查询A、B交集部分数据
- 外连接:左外连接:查询左表所有数据,以及交集部分(右外连接同理)
- 自连接:当前表与自身的连接查询,自连接必须使用表别名
- 子查询
内连接
- 查询语法:
- 隐式内连接
sql
-- 1.查询每一个员工的姓名 ,及关联的部门名称(隐式内连接)
-- 表结构:emp , dept
-- 连接条件: emp.dept_id = dept.id
select emp.name ,dept.name from emp , dept where emp.dept_id = dept_id;
-- 别名
select e.name ,d.name from emp e , dept d where e.dept_id = d.id;- 显式内连接
sql
-- 2.查询每一个员工的姓名 , 及关联的部门的名称 (显式内连接) ---INNER JOIN ..... ON .....
select e.name , d.name from emp e inner join dept d on e.dept_id = d.id;外连接
- 查询语法:

sql
-- 1,查询emp表的所有数据 , 和对应的部门信息(左外连接)
select e.*, d.name from emp e left outer join dept d on e.dept_id = d.id;
select e.*, d.name from emp e left join dept d on e.dept_id = d.id;
-- 2,查询dept表的所有数据 , 和对应的员工信息(右外连接)
select d.*, e.* from emp e right outer join dept d on e.dept_id = d.id;自连接

sql
-- 自连接
-- 1.查询员工 及其 所属领导的名字
-- 表结构:emp
-- a是员工 b是领导的
select a.name, b.name from emp a , emp b where a.managerid = b.id;
-- 2.查询所有员工 emp 及其领导的名字emp,如果员工没有领导,也需要查询出来
-- 表结构:emp a ,emp b
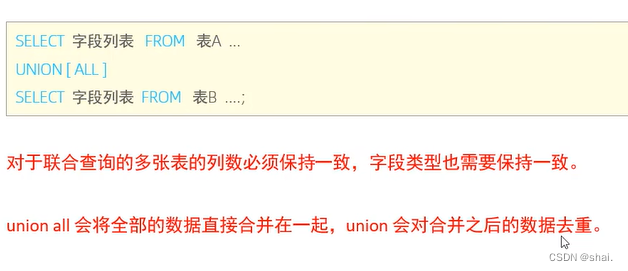
select a.name '员工', b.name '领导' from emp a left join emp b on a.managerid = b.id;联合查询-union,union all
对于union查询,就是把多次查询的结果合并起来,形成一个新的查询结果集
sql
-- 1.将薪资低于5000的员工 , 和年龄大于 50岁的员工全部查询出来
select * from emp where salary > 5000
union all
select * from emp where age > 50;
-- 去重
select * from emp where salary > 5000
union
select * from emp where age > 50;子查询

标量子查询
sql
-- 1.查询"销售部" 的所以员工信息
select * from emp where dept_id = (select id from dept where name = '销售部');
-- 2.查询在zwj入职之后的员工信息
select * from emp where entrydate > (select entrydate from emp where name = 'zwj'列子查询

sql
-- 3.查询比研发部其中任意一人工资高的员工信息
-- a.查询研发部所有人工资
select salary from emp where dept_id = (select id from dept where name = '研发部');
-- b. 比研发部其中任意一人工资高的员工信息
select * from emp where salary > any (select salary from emp where dept_id = (select id from dept where name = '研发部'));行子查询
子查询返回的结果是一行(可以是多列)
sql
-- 1.查询与lkh的薪资及直属领导相同的员工信息
-- a.查询lkh的薪资及直属领导
select salary, managerid from emp where name = 'lkh';
-- b.查询于lkh的薪资及直属领导相同的员工信息
select * from emp where (salary,managerid) = (select salary, managerid from emp where name = 'lkh');表子查询
子查询返回的结果是多行多列,这种子查询称为表子查询
sql
-- 2.查询入职日期是"2006-01-01"之后的员工信息 , 及其部门信息
-- a.入职日期是"2006-01-01"之后的员工信息
select * from emp where entrydate > '2006-01-01';
-- b.查询这部分员工, 对应的部门信息
select e.* , d.* from (select * from emp where entrydate > '2006-01-01') e left join dept d on e.dept_id = d.id;练习案例
sql
-- 1.查询员工的姓名、年龄、职位、部门信息(隐式内连接 where)
select e.name, e.age,e.job,d.name from emp e, dept d where e.dept_id = d.id;
-- 2,查询年龄小于30岁的员工的姓名、年龄、职位、部门信息(显式内连接 inner join.....on)
select e.name, e.age,e.job,d.name from emp e inner join dept d on e.dept_id = d.id where e.age < 30;
-- 3.查询所有员工的部门ID、部门名称
select distinct d.id , d.name from emp e ,dept d where e.dept_id = d.id;
-- 4.查询所有年龄大于40岁的员工,及其所属的部门部门名称;如果员工没有分配部门,也需要展示出来
-- 左外连接
select e.name , d.name from emp e left join dept d on e.dept_id = d.id where e.age > 40;
-- 5.查询所有员工的工资等级
-- 连接条件e.salary >= s.losal and e.salary <= s.hisal
select e.*,s.grade ,s.losal, s.hisal from emp e, salgrade s where e.salary >= s.losal and e.salary <= s.hisal;
select e.* ,s.grade ,s.losal, s.hisal from emp e, salgrade s where e.salary between s.losal and s.hisal;
-- 6.查询"研发部"所有员工的信息及工资等级
-- 连接条件 e.salary between s.losal and s.hisal ,e.dept_id = d.id
select e.*, s.grade -- 查询返回字段
from emp e, -- 表
salgrade s,
dept d
where e.dept_id = d.id
and (e.salary between s.losal and s.hisal)
and d.name = '研发部';
-- 7.查询研发部员工的平均工资
select avg(e.salary) from emp e,dept d where e.dept_id = d.id and d.name = '研发部';
-- 8.查询工资比lkh高的员工信息
select * from emp where salary > (select salary from emp where name = 'lkh');
-- 9.查询比平均薪资高的员工信息
select * from emp where salary > (select avg(salary) from emp);
-- 10.查询低于本部门平均工资的员工信息
select * from emp e2 where e2.salary < (select avg(e1.salary) from emp e1 where e1.dept_id = e2.dept_id)
-- 11.查询所有部门信息,并统计部门的员工人数
select d.id,d.name , (select count(*) from emp e where e.dept_id = d.id) '人数' from dept d;
-- 12.查询所有学生的选课情况,展示出学生名称、学号、课程名称
select s.name,s.id,c.name from student s, student_course sc,course c where s.id = sc.studentid and sc.courseid = c.id;