今天第一次接触阿里云存储,才开始使用感觉有点懵逼,直接跟本地存储搞混淆了,所以写一个文档记录一下阿里云存储的使用和什么是阿里云存储。
介绍
一句话简单介绍:
使用阿里云的存储服务将数据存储在云端,通过调用相关的key来获取数据的下载链接(二进制流上传和下载保存,不会损坏文件格式)
阿里云相关的知识点:
|-----------|------------------------------------------|
| 概念 | 说明 |
| Bucket | 存储桶(类似数据库) |
| Object | 对象(一个文件) |
| Endpoint | 访问地址 |
| AccessKey | 访问凭证 |
| Prefix | 逻辑路径(如 images/a.png)- 作为key去存储/访问存储的对象 |
python如何使用:
阿里云有提供给python的SDK包------oss2
# 配置access_key_id、access_key_secret
export OSS_ACCESS_KEY_ID=你的AccessKeyId
export OSS_ACCESS_KEY_SECRET=你的AccessKeySecret
# 初始化
import oss2
import os
auth = oss2.Auth(
os.getenv("OSS_ACCESS_KEY_ID"),
os.getenv("OSS_ACCESS_KEY_SECRET")
)
bucket = oss2.Bucket(
auth,
endpoint="https://oss-cn-shenzhen.aliyuncs.com",
bucket_name="hz-aiservice"
)
# 上传文件
content = b"hello oss" # 使用其他文件类也行
# 如果文件时其他类型文件,
# 此处需要将文件通过二进制数据读取到内存后进行上传
# 并且可以传入头部信息防止被识别成二进制流
# headers = {
# 'Content-Type': 'application/pdf', # 如果是图片则是 image/jpeg 等
# # 'x-oss-object-acl': 'public-read' # 如果需要设置单独的读写权限
# }
# with open("document.pdf", 'rb') as f:
# bucket.put_object(
# key="test/document.pdf",
# data=f.read(),
# headers=headers # 传入头部信息
# )
bucket.put_object(
key="test/hello.txt", # 此处需要注意命名规范
data=content
)
# 下载文件
bucket.get_object_to_file(
key="documents/1/demo.pdf",
filename="downloaded.pdf"
)
# 通过bucket的下载链接来进行处理 - 更加具有安全性,通常用于接口中
url = bucket.sign_url(
method="GET",
key="documents/1/demo.pdf",
expires=3600 # 1 小时
)
print(url)
# 项目中相关封装
class OSSService:
def __init__(self, bucket):
self.bucket = bucket
def upload_bytes(self, key: str, data: bytes):
self.bucket.put_object(key, data)
def generate_download_url(self, key: str, expires=3600):
return self.bucket.sign_url("GET", key, expires)
def delete(self, key: str):
self.bucket.delete_object(key)实际流程
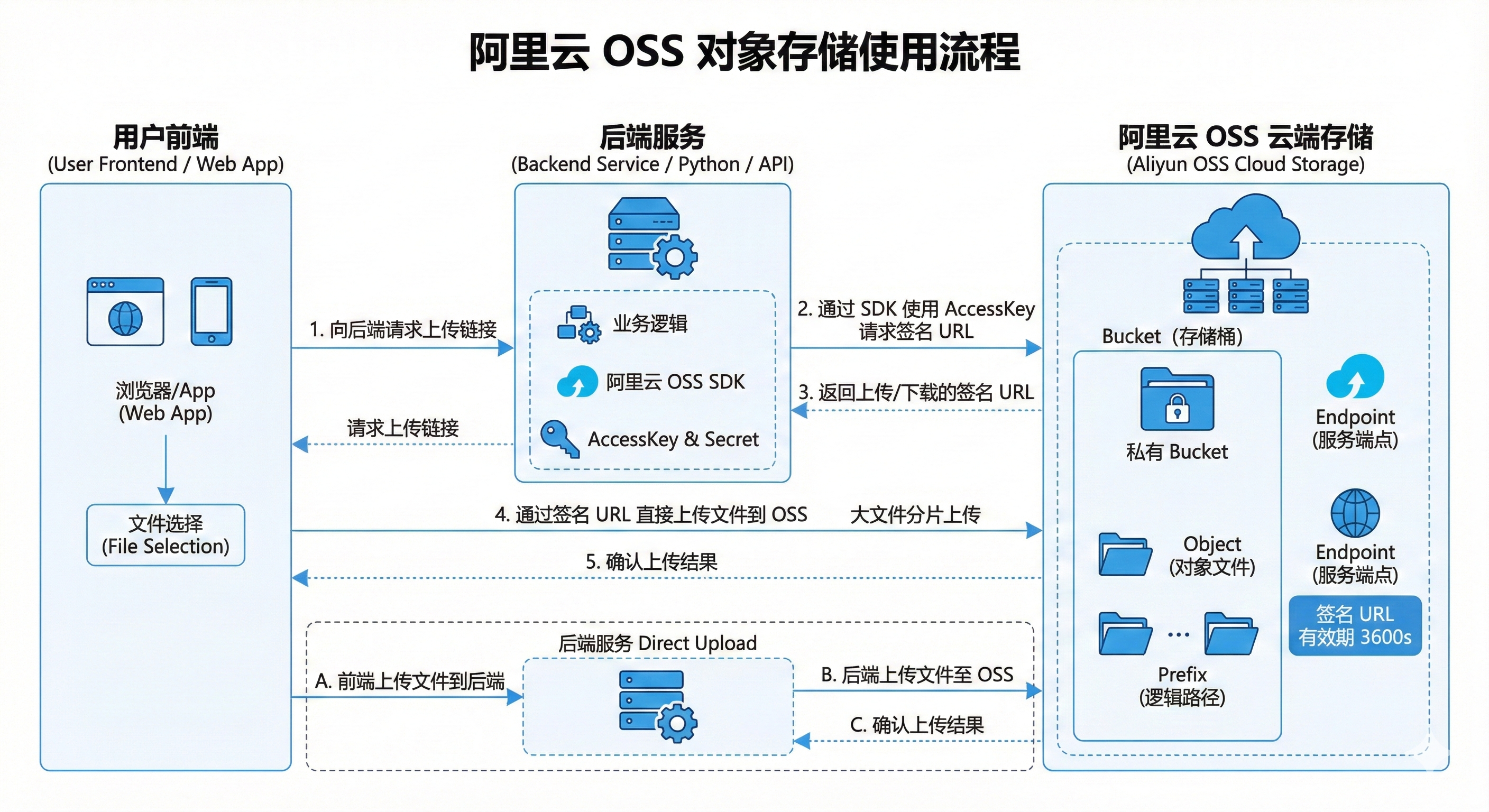
简要流程概述:
- 在阿里云控制台开通OSS服务, 配置权限 ,获取相关密钥信息: AccessKey ID 、 AccessKey Secret 、 Endpoint
- 后端通过阿里云封装的SDK上传/读取在阿里云的文件,进行签名URL
- 阿里云返回访问地址
- 前端/后端系统request访问地址后进行相关操作
总体流程实现:
上传文件部分(分为两种):
-
- 前端上传
-
- 用户前端上传文件,首先向后端请求阿里云上传文件链接
- 后端向阿里云请求上传链接并返回上传链接给前端
- 前端通过后端返回的上传链接来进行文件上传
- 上传完成后向后端请求确认上传接口
-
- 后端上传
-
- 前端通过调用后端接口将文件传输给后端
- 后端接受到文件之后用阿里云SDK上传文件
注意点:
- 密钥等不要写死再代码里,可以通过环境变量或者配置config后读取的方式来进行读取
- bucket需要设置为私有,需要通过签名的方式去进行下载
- 阿里云存储的storage_path的命名方式:f"{操作名}/{uuid.uuid7()}_{file.filename}"
- 上传和下载链接都是有时间选项配置的,一般为3600s
- 如果涉及大文件传输最好使用前端来进行传输,并且大文件最好采用分片的方式传输防止传输失败