二、任务场景
2.1. 无条件生成
无条件生成是指生成模型在生成图像时不受任何额外条件或约束的影响。模型从学习的数据分布中生成图像,而不需要关注输入条件。
2.2. 有条件生成
有条件生成是指生成模型在生成图像时受到额外条件或上下文的影响。这些条件可以是类别标签、文本描述、特定属性等。有条件生成广泛应用于需要模型理解并满足特定条件的任务。例如,给定文本描述,生成与描述相符的图像;或者在生成特定类别的图像时,提供类别标签。
2.2.1. 类别条件生成
类别条件生成是非常常见的一种场景,也有许多相关的任务,其中 ImageNet 是最常见的一种,ImageNet 常用于图像分类任务,每个图像都有一个类别标签,总共有 1000 个类别。在图像生成领域,可以指定对应的类别标签,然后让模型按照类别生成图像。
如下图所示为基于 ImageNet 训练后,按类别生成的图像结果(来自 ViT-VQGAN):
9.1. DALL-E mini 模型概述
如下图所示,DALL-E mini 中作者使用 VQ-GAN 替代 dVAE,使用 Encoder + Decoder 的 BART 替代 DALL-E 中 Decoder only 的 Transformer。

训练过程:
将图像输入进VQGAN-Encoder,得到image encoder vector,将图像对应的文本输入进bert encoder-decoder模型,得到根据文本预测得到的图像,计算image encoder vector与预测图像的loss,从而更新VQGAN-Encoder、Bert
9.2. DALL-E mini 模型推理
在推理过程中,不是生成单一的图像,而是会经过采样机制生成多个 latent code,并使用 VQ-GAN 的 Decoder 生成多个候选图像,之后再使用 CLIP 提取这些图像的 embedding 和文本 embedding,之后进行比对排序,挑选出最匹配的生成结果。
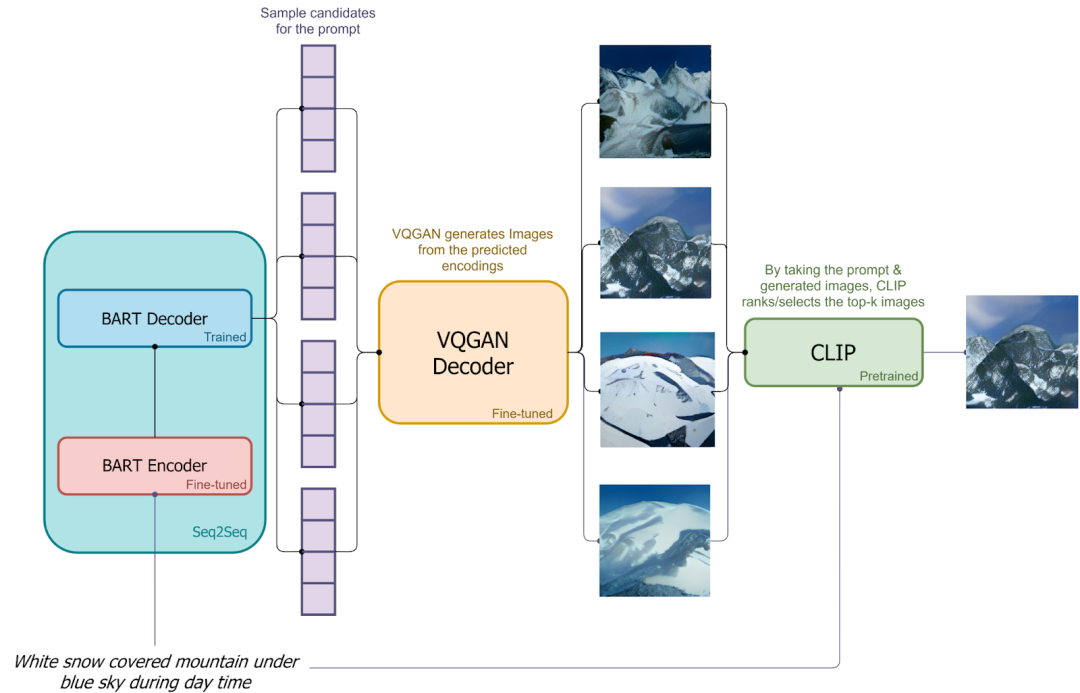
将文本输入进Bert,得到预测的多个候选,通过VQGAN-Decoder得到多个解码后的图像,利用CLIP计算解码后的图像与文本之间的最小距离对应的图像,当成输出