1 简介及安装
1.1 简介
ControlNet是由斯坦福大学研究者张吕敏等人于2023年提出的一种AI图像生成控制技术,核心作用是让用户在保持生成图像 "创造力" 的同时,精准控制图像的结构、姿态、轮廓、深度等关键空间信息,解决了传统扩散模型(如 Stable Diffusion)生成结果 "不可控" 的核心痛点。
1 核心原理:"锁定结构+释放风格"
ControlNet的本质是在扩散模型(如 Stable Diffusion)的基础上,增加了一套 "结构约束机制",其原理可拆解为 3 个关键步骤:
1)提取 "结构参考图" 特征
用户需提供一张 "结构指导图"(如线稿、姿态骨架、深度图、语义分割图),ControlNet通过专门的 "预处理器(Preprocessor)" 分析这张图的空间结构(如物体位置、线条走向、人体关节角度),并将其转化为模型可理解的 "结构特征向量"。
2)冻结 "结构特征" 并绑定扩散过程
ControlNet会将提取的 "结构特征""冻结",并在扩散模型生成图像的每一步(从噪声图逐步去噪为清晰图)中,强制模型的生成结果贴合该结构特征------例如,线稿的每一条线条必须对应生成图像中的物体边缘,姿态骨架的每一个关节必须对应人体的动作角度。
3)保留模型的"风格与细节创造力"
在"结构锁定"的前提下,扩散模型依然可以自由生成图像的风格(如写实、卡通、油画)、纹理(如皮肤质感、衣物面料)、色彩等非结构信息,实现"结构可控,风格自由"的平衡。
2 核心组件:预处理器(Preprocessor)与控制模型(Model)
ControlNet的功能依赖"预处理器"和"控制模型"的配合,二者需一一对应使用,不同组合对应不同的控制场景:
| 控制类型 | 预处理器(Preprocessor)功能 | 控制模型(Model)作用 | 典型应用场景 |
|---|---|---|---|
| Canny 边缘控制 | 将参考图转化为黑白边缘线稿(突出物体轮廓) | 强制生成图像贴合边缘线稿的轮廓结构 | 线稿转插画、产品设计图上色 |
| OpenPose 姿态控制 | 提取参考图中人体 / 动物的骨骼关节(如手脚角度) | 精准控制生成人物的动作姿态 | 动漫角色 Pose 生成、影视分镜设计 |
| Depth 深度控制 | 生成参考图的 "深度图"(黑白表示远近,黑近白远) | 控制图像的 3D 空间关系(如前后遮挡、透视) | 室内装修效果图生成、3D 场景还原 |
| Segmentation 语义分割控制 | 将参考图按 "物体类别" 分割(如人、车、天空用不同颜色标注) | 强制生成图像中各类物体的位置与范围 | 城市规划图生成、场景元素替换(如换天空) |
| Normal Map 法线控制 | 生成参考图的法线图(表示物体表面的凹凸方向) | 控制物体的质感与立体感(如金属褶皱) | 游戏角色建模、工业设计细节优化 |
3 关键优势:解决传统 AI 生成的 "痛点"
相比传统扩散模型(如直接用文字生成图像),ControlNet的核心优势体现在"可控性"和"实用性"上:
1)结构精准可控
无需反复调整文字提示词(Prompt),只需一张简单的线稿或姿态图,就能让生成结果严格贴合预设结构(例如确保人物 "左手举高" 而非 "右手举高")。
2)降低创作门槛
非专业用户无需掌握绘画、建模技能,只需用手机拍一张场景照(作为深度 / 语义参考图),即可生成风格化图像(如将生活照转化为宫崎骏风格插画)。
3)适配主流模型
ControlNet并非独立模型,而是 "插件式技术",可无缝对接 Stable Diffusion、MidJourney(第三方插件)等主流生成模型,复用现有模型的风格能力。
4)支持 "增量控制"
可同时叠加多种控制类型(如 "OpenPose 控制姿态 + Depth 控制透视"),实现更复杂的场景需求(如生成 "特定动作的人物在特定透视的房间里")。
4 典型应用场景
ControlNet已广泛应用于创意设计、内容生产、工业领域等,常见场景包括:
1)创意设计领域
插画师:用简笔画线稿生成高精度插画,快速迭代风格;
平面设计:用语义分割图(标注 "标题区、图片区、文字区")生成符合版式的海报。
2)影视与游戏制作
分镜设计:用文字 + 姿态图生成影视分镜(如 "武侠角色拔剑的分镜,符合OpenPose姿态");
游戏建模:用法线图控制角色装备的细节(如盔甲的凹凸纹理)。
3)生活与内容创作
照片风格化:用手机拍的人像照(提取OpenPose姿态)生成动漫风、油画风人像;
表情包制作:用简单的线稿生成不同表情、动作的表情包角色。
4)工业与科研
建筑设计:用建筑线稿生成带真实光影的效果图;
医学影像:用CT扫描图(转化为深度图)生成3D可视化模型,辅助诊断。
1.2 安装说明
这里介绍基于Stable Diffusion WebUI的安装过程,并假设sdwebui已经安装完成。
1 安装Control Net
在extensions中配置下载链接,单击"Load from"加载相关插件:
https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui-extensions/master/index.json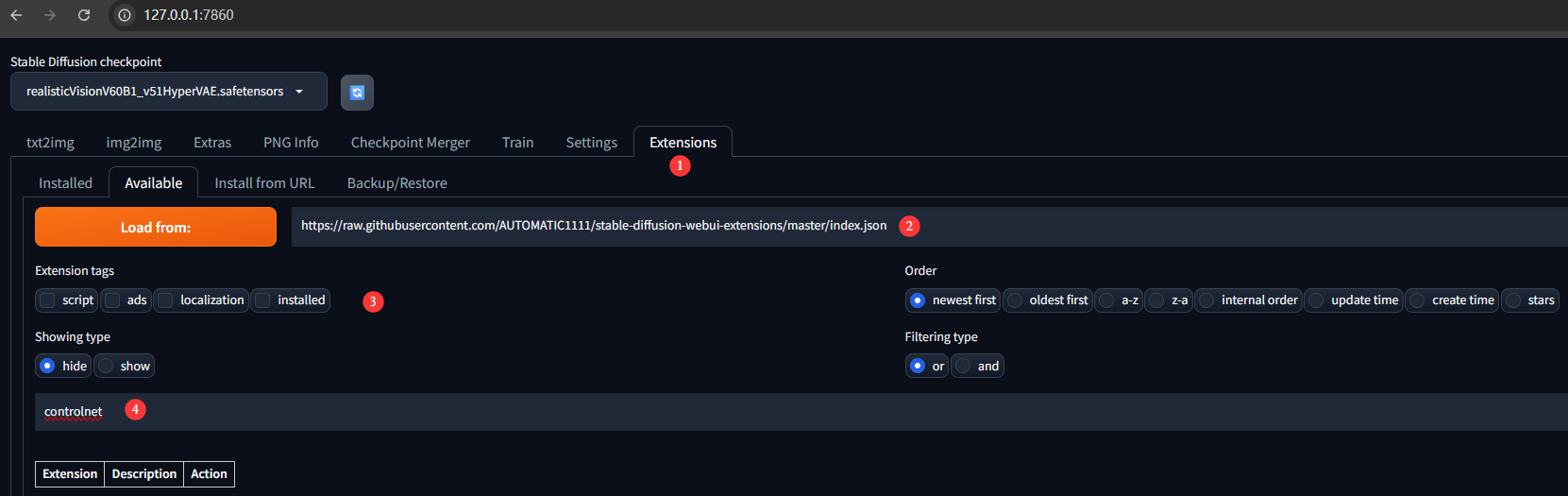
然后直接搜索controlnet,然后找到如下插件,点击install,为了保证顺利安装,请提前配置好梯子。
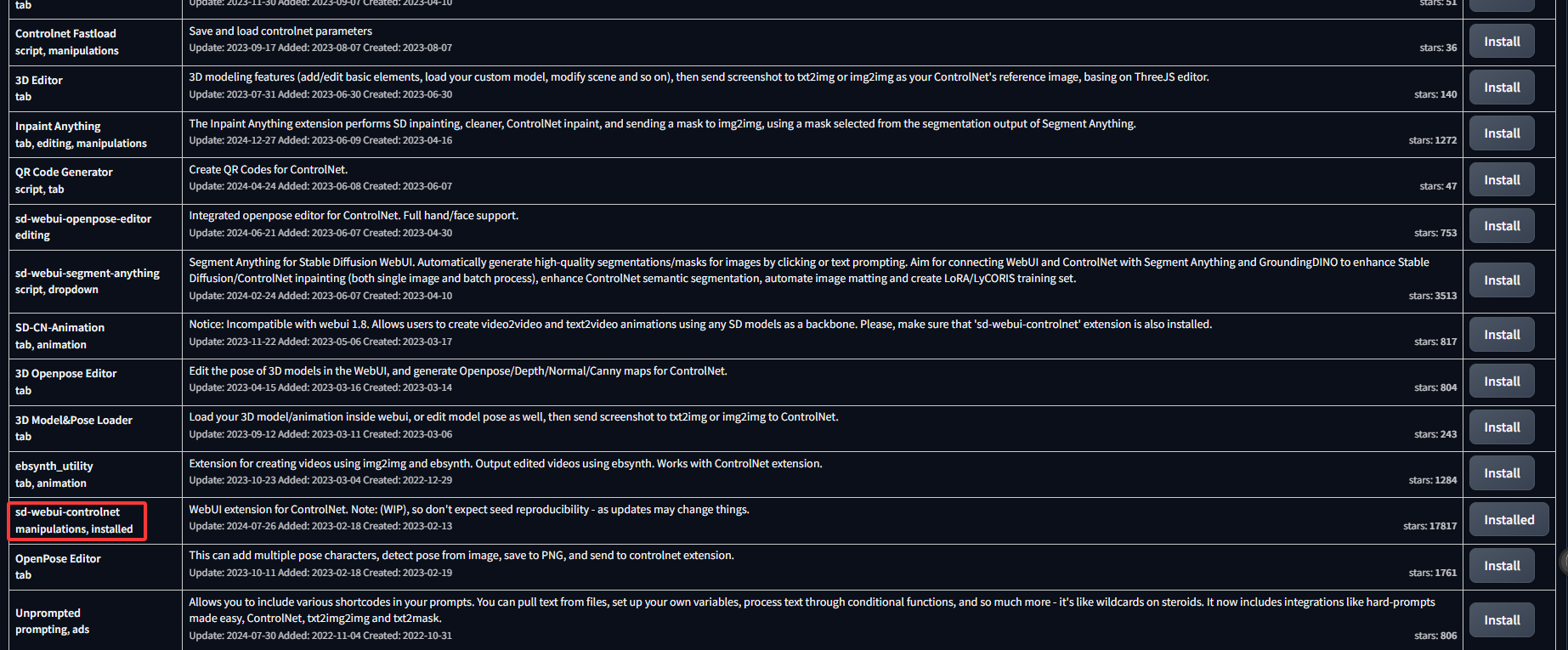
下载完重启sdwebui以加载插件,另外参考1中还提供了另一种下载安装方式,有兴趣的请直接参考相应链接。
2 下载模型
以上已经将最基础ControlNet插件下载安装,要想使用还需要安装相应的模型,可以到这里下载。
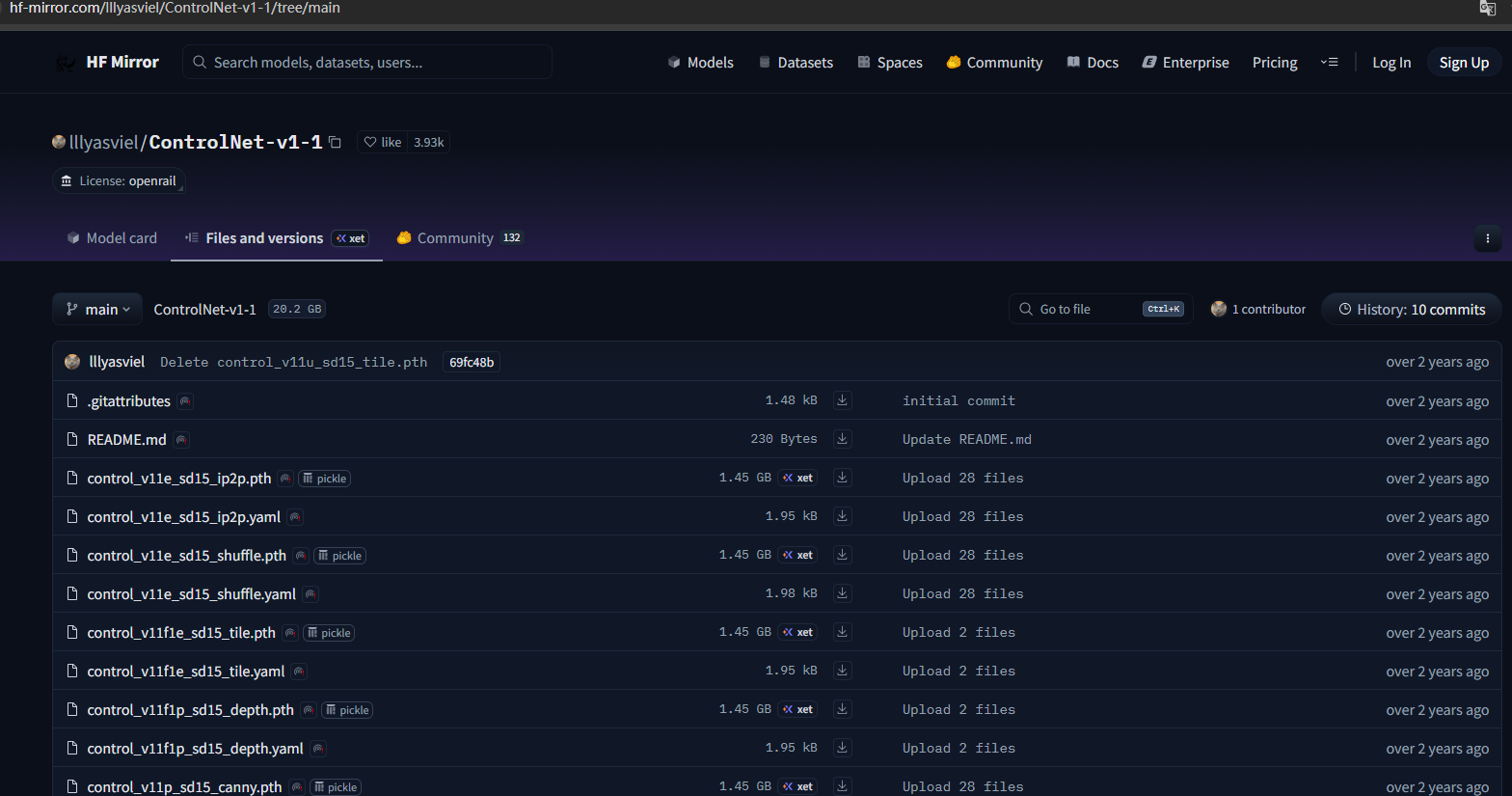 下载时要把两个名字相同但后缀不同的pth和yaml文件一起下载,下载下来后放到"extensions\sd-webui-controlnet\models",例如:
下载时要把两个名字相同但后缀不同的pth和yaml文件一起下载,下载下来后放到"extensions\sd-webui-controlnet\models",例如:
~/work/ai/stable-diffusion-webui/extensions/sd-webui-controlnet/models最后重启sdwebui,可见所有模型已经加载:
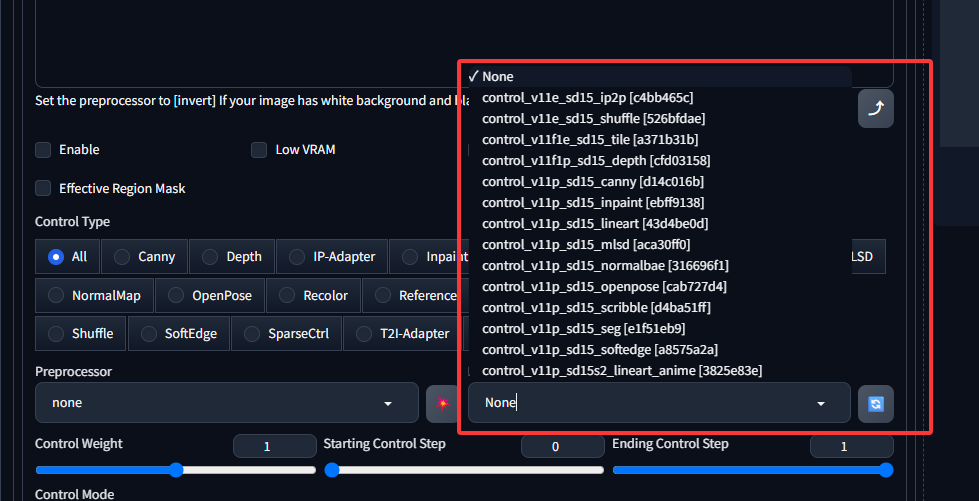
2 界面主要功能区介绍
在带有ControlNet的图像训练过程中,一共有2种条件会作用到生成图像上,其一是提示词(prompt),另一个就是由ControlNet引入的各种自定义条件(Condition)。以下是ControlNet对应模型的一个命名规则,需要注意的是名字带有p的是稳定版本,表示可用于生产可放心使用。

接下来围绕以下4部分对ControlNet的使用进行说明。
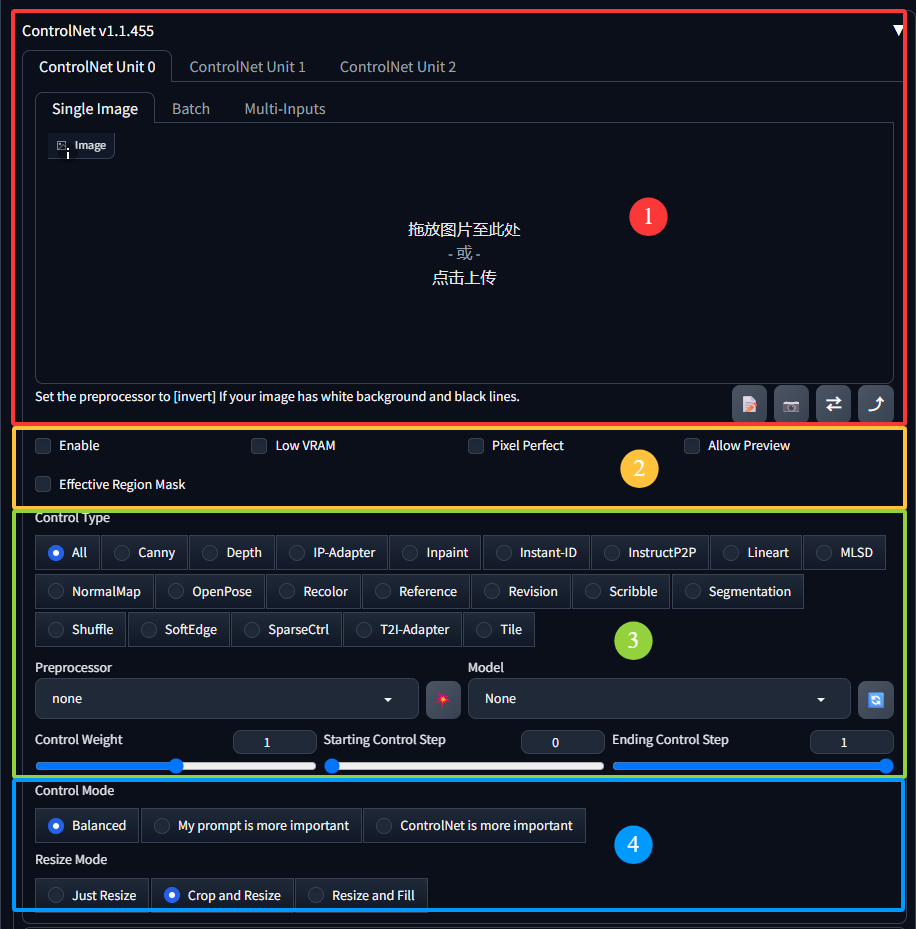
2.1 导入参考图
这里可以首先上传一副参考图像,也就是说,这张图是让Controlnet去结合具体的模型,引导控制图片的生成。
2.2 关键选项
在该部分有几个关键选项按钮,它们的作用如下:
1)"Enable"(启用)
作用:勾选此选项后,才会激活当前ControlNet单元(如ControlNet Unit 0)的功能。如果不勾选,当前ControlNet单元不会对图像生成过程产生任何影响,相当于 "关闭" 该单元。
2)"Low VRAM"(低显存模式)
作用:当电脑的显卡显存(VRAM)容量较小,运行ControlNet时可能出现显存不足的情况,勾选该选项后,ControlNet 会采用更节省显存的计算方式来工作,以适配低显存的硬件环境,但可能会在一定程度上影响处理速度或效果的精细度。
3)"Pixel Perfect"(像素完美)
作用:勾选后,ControlNet会更精准地根据输入图像的像素级细节来进行控制。它会尽量保证生成图像与输入图像在像素对应关系、细节还原等方面达到更精确的匹配,让控制效果更贴合输入图像的细微特征。
4)"Allow Preview"(允许预览)
作用:勾选该选项后,在进行ControlNet相关处理(如预处理输入图像、生成控制特征图等)时,会允许用户预览中间过程的图像或特征图,方便用户查看ControlNet对输入图像的处理效果,以便及时调整参数或输入图像。
5)"Effective Region Mask"(有效区域掩码)
作用:用于指定ControlNet作用的有效区域。通过设置掩码,可以让ControlNet只对输入图像中的特定区域进行控制,而忽略其他区域,从而实现更有针对性的局部控制效果,比如只修改图像中的某一部分,而保持其他部分不变。
2.3 选择控制模型
其中Control Type表示控制类型,选择任一种控制类型,下面对应的是细分的预处理器Preprocessor和模型Model设置。最后该区域下面还有三个选项:
Control Weight:权重,表示使用ControlNet生成图片的权重占比影响,默认为1。
Starting Control Step:开始介入的步数,上限为1,举例,如果数值为0.2,意思是图片绘制到20%的时候,ControlNet才开始介入影响绘画。
Ending Cotrol Step:结束介入的步数,上限也为1,举例,如果数值为0.9,意思是图片绘制到90%的时候,ControlNet结束介入影响绘画。
2.4 控制及缩放模式
Control Mode有三个选项分别是:平衡、描述词更重要、ControlNet更重要。需要根据输出图片结果来调整选择,一般默认"平衡"项。
Resize Mode是页面缩放选项,其三个选项含义如下:
Just Resize(仅调整大小)
含义:该选项会按照指定的尺寸直接对输入图像进行缩放,以适配模型的输入要求。在缩放过程中,会保持图像的宽高比不变。例如,如果原始图像是一个长宽比较大的长方形,在缩放后,它依然会是一个长宽比相同的长方形,不会对图像进行裁剪或填充额外内容。
应用场景:当你希望完整保留输入图像的所有内容,且不改变图像的原始比例关系时使用。比如,对于一些具有完整场景且元素位置关系很重要的图像,不想因为裁剪或填充破坏其整体性,就可以选择这个模式。
Crop and Resize(裁剪并调整大小)
含义:首先,该模式会根据设定的目标尺寸,对输入图像进行裁剪,通常会裁剪掉图像边缘的部分内容,以使其符合特定的宽高比,然后再将裁剪后的图像缩放到目标尺寸。例如,若目标尺寸的宽高比和原始图像不同,可能会裁掉原始图像的左右两侧或者上下部分,然后再进行缩放操作。
应用场景:当你更关注图像中的某一核心区域,且可以接受去掉图像边缘部分内容时使用。比如,输入图像中有一个人物,但人物周围有较多无关的背景,你可以通过这种模式裁剪掉无关背景,然后将人物部分缩放到合适大小,以突出主体。
Resize and Fill(调整大小并填充)
含义:先将输入图像按照宽高比进行缩放,使图像的宽度或高度(取决于哪个维度先达到目标尺寸)达到设定的目标尺寸,然后对于未填满目标尺寸的部分,使用指定的颜色(通常是黑色或白色,具体取决于软件设置)进行填充。例如,原始图像是正方形,而目标尺寸是长方形,图像会先缩放到长方形的短边长度,然后在长边方向上用指定颜色填充空白区域。
应用场景:当你需要严格按照特定尺寸输出图像,同时又要保留原始图像的完整内容和比例关系时使用。比如,在需要生成固定尺寸的海报、插画等场景中,使用这种模式可以确保图像内容完整,同时满足尺寸要求。
3 使用详解
当前1.1版本ControlNet支持14种模型,每种模型都有其各自的特点,按模型的控图方向可分为4种类型,分别是轮廓类、景深类、对象类和重绘类。

3.1 轮廓类
轮廓类指的是通过元素轮廓来限制画面内容,轮廓类模型有Canny硬边缘、MLSD直线、Lineart真实线稿、Lineart_anime动漫线稿、SoftEdge软边缘、Scribble涂鸦、Segmentation语义分割这7种,且每种模型都配有相应的预处理器,由于算法和版本差异,同一模型可能提供多种预处理器供用户自行选择。
1 Canny硬边缘
以下基于Canny边缘检测进行详细介绍,该模型源自图象处理领域的边缘检测算法,可很好识别出图像内各对象的边缘轮廓,常用于生成线稿。它主要配置以下3个参数:
Resolution(分辨率):数值越高越精细,也越吃显存,但如果数值太低生成的线条也会很粗糙,默认512,具体设置时需根据素材大小和实际情况来做权衡。
Low Threshold(低阈值):一个灰度值界限,用于初步筛选可能属于边缘的像素点。在 Canny 边缘检测算法中,当一个像素点的梯度值(反映像素点灰度变化的程度,灰度变化越大,梯度值越高 )大于或等于低阈值时,该像素点就有可能被标记为边缘点。但仅仅大于低阈值还不能确定它一定是边缘点,因为图像中一些噪声点或者非重要的灰度变化也可能导致梯度值超过低阈值。低阈值主要用于 "捕捉" 潜在的边缘信息,尽量减少边缘的遗漏。如果低阈值设置得过低,可能会将大量噪声点或无关的灰度变化误判为边缘,导致检测出过多不必要的边缘(即边缘过于杂乱);而如果设置得过高,就可能会遗漏一些真正的边缘细节,使得检测出的边缘不完整。
High Threshold(高阈值):一个灰度值界限,用于确定那些 "确凿无疑" 的边缘点。当一个像素点的梯度值大于或等于高阈值时,该像素点会被直接确定为边缘点。并且,与这些确定的边缘点相连通(在一定的邻域范围内)、梯度值大于低阈值的像素点,也会被认为是边缘点。高阈值的主要作用是确保检测出的边缘是真正显著的、重要的边缘,减少虚假边缘的出现。如果高阈值设置得过高,只有极少数梯度值非常大的像素点才会被认定为边缘点,这样可能会导致检测出的边缘过于稀疏,丢失很多关键的边缘信息;而如果设置得过低,就无法有效过滤掉不重要的边缘和噪声,导致边缘检测结果不够精确。
在使用 canny 进行预处理时,提取的图像像素边缘线会被上述2个阈值参数划分为强边缘、弱边缘和非边缘 3 类,其中强边缘会直接保留,而非边缘的线稿会被忽略,处于中间弱边缘范围的线稿则会进行计算筛选。以下面这张图为例,预处理过程中检测到3条边缘线,其中D点位于非边缘区域,因此直接被排除,而A点位于强边缘区域被保留。虽然B、C点都位于弱边缘区域,但由于 B 点和 A 点是直接相连的,因此 B 点也被保留,而与C点相连的线全都位于弱边缘区域所以被排除。由此得到画面中最终被保留的边缘线只有 AB 这条线。
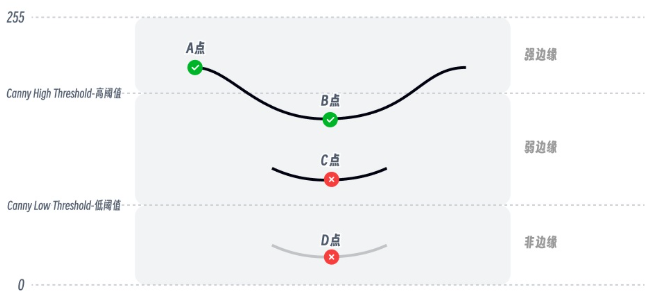
在实际应用中,通常需要合理搭配低阈值和高阈值。一般来说,高阈值要大于低阈值, 常见的经验取值是高阈值为低阈值的2 - 3倍。通过调整这两个阈值,可以在边缘检测的完整性和准确性之间找到一个平衡,以获得符合需求的边缘检测结果,从而让 ControlNet 更精准地根据边缘信息生成图像。 例如,在生成线稿风格的图像时,合适的阈值设置能确保生成的图像线条既完整又清晰,不会出现多余杂乱的线条或者线条缺失的情况。
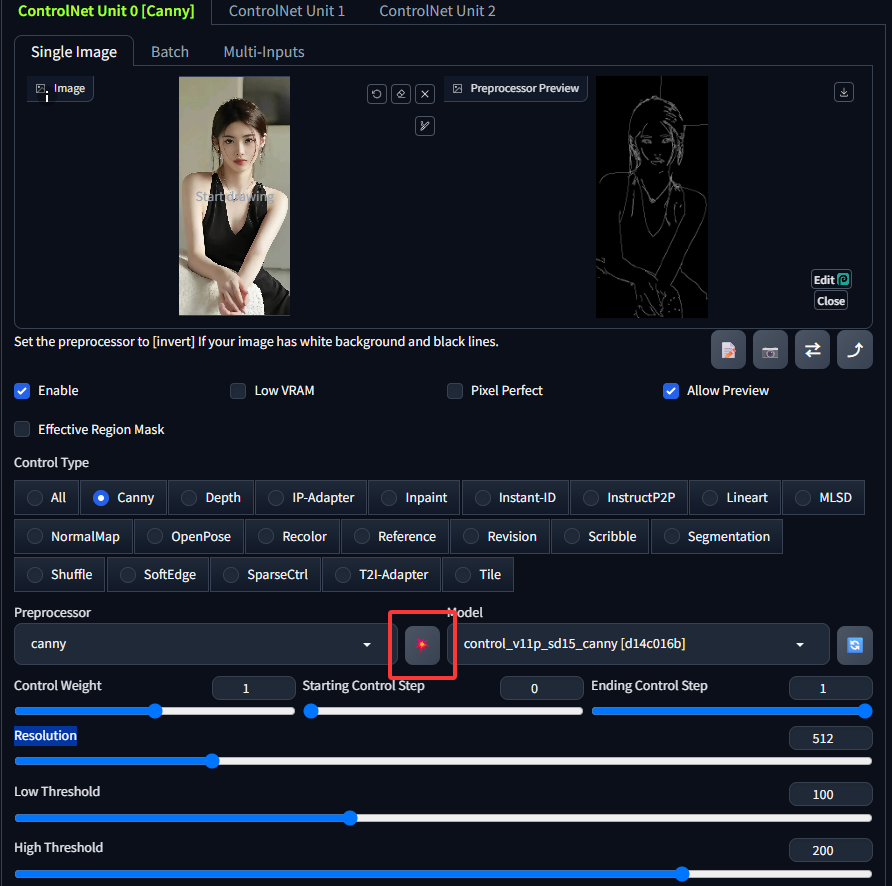
点击中间的按钮可以预览预处理后的轮廓线。可以在此基础上结合Stable Diffusion重新生成图象,例如核心提示词(Prompt)如下:
photorealistic, ultra-detailed, 8k, high resolution,
a beautiful young woman (22 years old), fair skin with subtle blush,
long wavy chestnut hair with soft highlights, bright almond-shaped eyes (warm brown color, clear and shiny),
full lips with natural pink lipstick, sharp jawline, delicate nose负提示词(Negative Prompt)如下:
lowres, blurry, bad anatomy, bad hands, missing fingers, extra fingers,
mutated hands, deformed, ugly, disfigured, malformed face,
watermark, text, signature, username, logo,
worst quality, low quality, normal quality, jpeg artifacts,
cartoon, anime, 3d render, doll, plastic skin, unrealistic模型使用kimchiMix V4,其他核心配置如图所示,最终生成的图片如下:
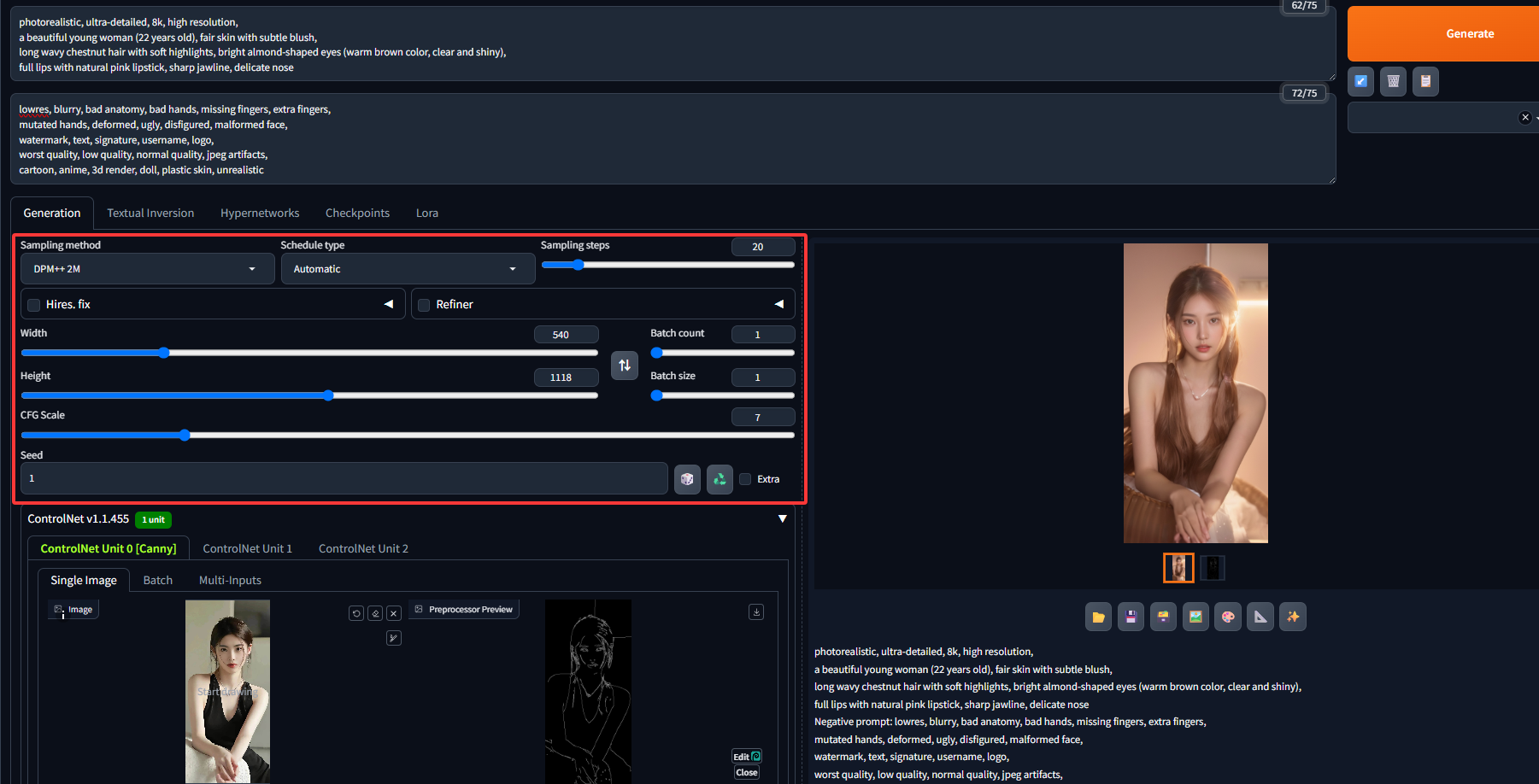 可见生成的图片是在边缘检测的基础上生成的,从而在很大程度上加强了生成的"可控性"。
可见生成的图片是在边缘检测的基础上生成的,从而在很大程度上加强了生成的"可控性"。
2 MLSD直线边缘
MLSD(Modulated Line Segment Detection,调制线段检测)提取的都是画面中的直线边缘,在下图中可以看到MLSD预处理后只会保留画面中的直线特征,而忽略曲线特征。
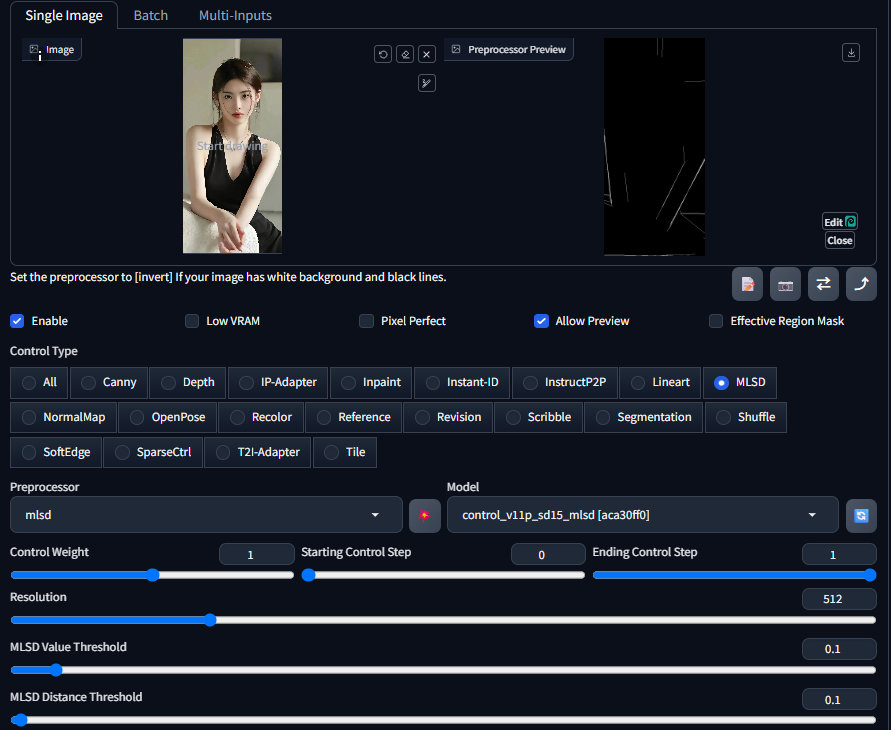
因此MLSD多用于提取物体的线型几何边界,最典型的就是几何建筑、室内设计、路桥设计等领域。MLSD预处理器同样也有自己的定制参数,分别是MLSD Value Threshold强度阈值和MLSD Distance Threshold长度阈值。MLSD阈值控制的是2个不同方向的参数:强度和长度,它们的数值范围都是 0~20 之间。Value强度阈值用于筛选线稿的直线强度,简单来说就是过滤掉其他没那么直的线条,只保留最直的线条。Distance长度阈值则用于筛选线条的长度,即过短的直线会被筛选掉。在画面中有些被识别到的短直线不仅对内容布局和分析没有太大帮助,还可能对最终画面造成干扰,通过长度阈值可以有效过滤掉它们。
3 Lineart线稿
Lineart同样也是对图像边缘线稿的提取,但它的使用场景会更加细分,包括Realistic真实系和Anime动漫系2个方向。
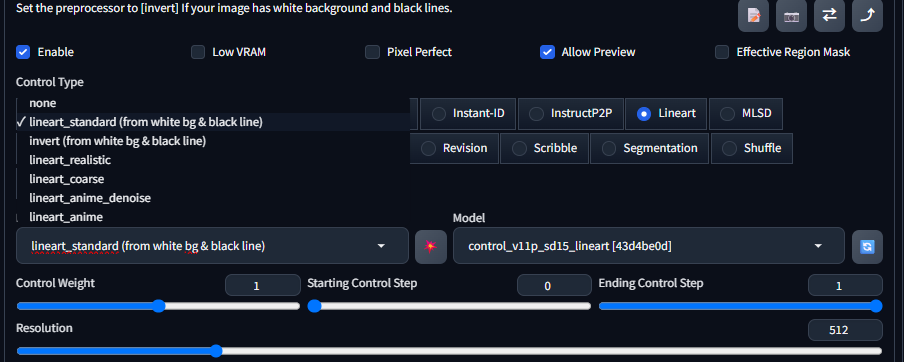
在 ControlNet 插件中,将lineart和lineart_anime种控图模型都放在「Lineart(线稿)」控制类型下,分别用于写实类和动漫类图像绘制,配套的预处理器也有6个之多,其中带有anime字段的预处理器用于动漫类图像特征提取,其他的则是用于写实图像。相比Canny 提取后的线稿类似电脑绘制的硬直线,粗细统一都是1px大小,而Lineart则是有的明显笔触痕迹线稿,更像是现实的手绘稿,可以明显观察到不同边缘下的粗细过渡。虽然官方将Lineart划分为2种风格类型,但并不意味着他们不能混用,实际上我们可以根据效果需求自由选择不同的绘图类型处理器和模型。
4 SoftEdge软边缘
Soft Edge是一种比较特殊的边缘线稿提取方法,它的特点是可以提取带有渐变效果的边缘线条,由此生成的绘图结果画面看起来会更加柔和且过渡自然,它共提供了6种不同的预处理器。
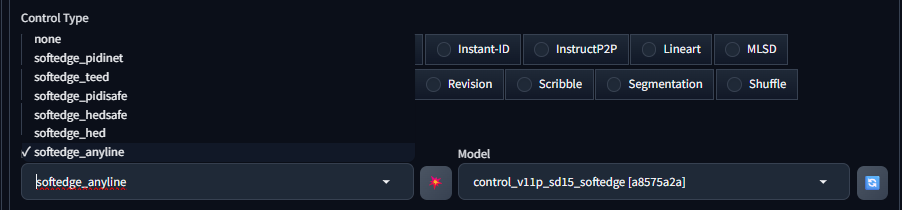
1)softedge_pidinet
原理:基于 PIDinet(一种边缘检测算法)进行开发,它能够检测出图像中较为精细的边缘信息。PIDinet 在边缘检测时,对图像中的结构和细节有较好的捕捉能力,能够区分不同物体的边界。
适用场景:适用于需要保留图像中物体精确边缘信息的场景,比如将一张具有复杂场景的照片转化为线稿风格的图像,它可以清晰地勾勒出各个物体的轮廓,包括人物、建筑、植物等的边缘,使得生成的图像在结构上比较准确。
2)softedge_teed
原理:采用了特定的技术来优化边缘检测的结果,在识别图像边缘时,注重边缘的连续性和流畅性,对一些噪声和不规则的像素变化有一定的抑制作用,从而得到相对平滑的边缘输出。
适用场景:在生成一些风格较为柔和、边缘不需要过于尖锐的图像时比较有用。例如在生成卡通风格的插画时,它可以生成圆润、流畅的线条,避免出现过于生硬或锯齿状的边缘,让图像看起来更加自然和谐。
3)softedge_pidsafe
原理:可能是在 PIDinet 的基础上进行了安全相关的优化,比如在检测边缘时,对可能出现的误检、错检情况进行了一定的修正和过滤,提高边缘检测结果的可靠性和稳定性。
适用场景:对于对边缘检测准确性要求较高的场景,如工业设计图纸的边缘提取、医学影像中特定组织的边缘识别等。在这些场景中,错误的边缘检测可能会导致严重的后果,而 softedge_pidsafe 可以降低这种风险。
4)softedge_hedsafe
原理:基于 HED(Holistically-Nested Edge Detection,整体嵌套边缘检测)算法进行改进,并增加了安全相关的处理机制。HED 本身是一种性能较好的边缘检测算法,能够检测出图像中不同尺度和层次的边缘,softedge_hedsafe 在此基础上进一步优化,减少误检和漏检的情况。
适用场景:适用于对图像边缘完整性和准确性都有较高要求的场景,如艺术创作中的精细线稿生成、图像修复中边缘的匹配等。它可以在复杂的图像内容中准确地检测出边缘,并且在处理过程中尽量减少对原始图像信息的破坏。
5)softedge_hed
原理:直接基于 HED 算法,能够从图像中提取出丰富的边缘信息,包括物体的轮廓、纹理边缘等。它可以检测出不同强度和方向的边缘,并且在多尺度上进行分析,以适应不同大小物体的边缘检测需求。
适用场景:在需要全面获取图像边缘信息的场景中表现出色,例如在图像风格转换任务中,将一张照片转换为具有特定风格的绘画作品时,softedge_hed 可以提供较为完整的边缘基础,帮助生成的图像在结构上更贴近原始图像。
6)softedge_anyline
原理:致力于能够处理各种类型的线条信息,无论是清晰的轮廓线、模糊的边界线,还是一些具有艺术风格的线条,它都能够进行有效的检测和提取。这种模型可能采用了更加灵活和通用的算法,以适应不同来源和质量的图像输入。
适用场景:非常适合用于处理手绘草图、涂鸦风格的图像,或者是一些边缘信息不清晰、不规范的图像。比如将用户随意绘制的草图转化为具有一定风格的正式插画,softedge_anyline 可以很好地利用草图中的线条信息,生成符合预期的图像。
5 Scribble涂鸦边缘
Scribble涂鸦,也可称作Sketch草图,同样是一款手绘效果的控图类型,但它检测生成的预处理图更像是蜡笔涂鸦的线稿,在控图效果上更加自由。
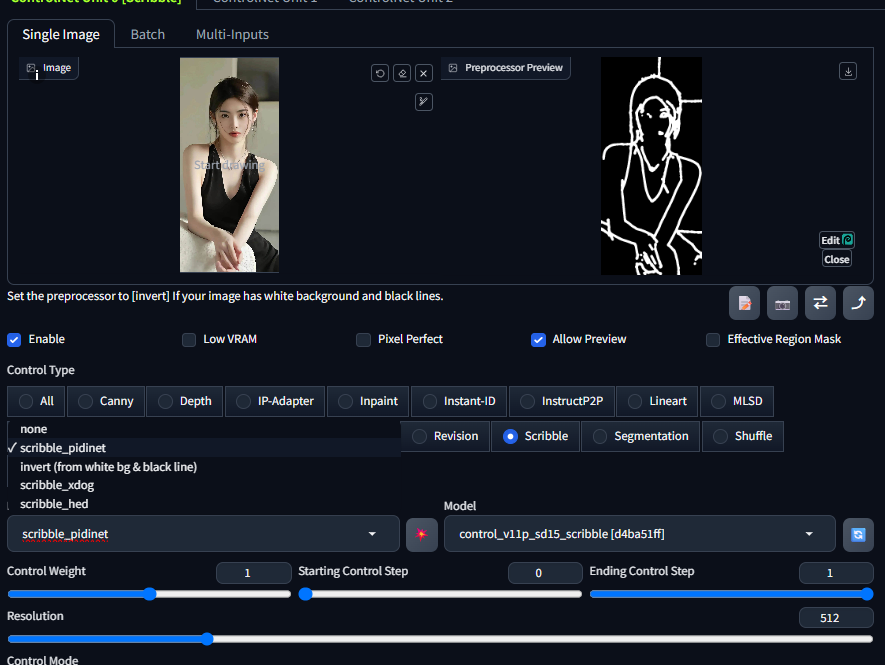
1)scribble_pidinet
原理:基于PIDinet算法开发,PIDinet是一种高效的边缘检测算法。scribble_pidinet预处理器会利用该算法检测输入图像中的边缘信息,并将其简化为类似涂鸦的线条。它能够识别出图像中物体的主要轮廓和关键结构,去除一些不必要的细节,从而生成简洁的涂鸦线条图。
特点和优势:对复杂图像的处理能力较强,能够在保留图像主要结构的同时,过滤掉过多的细节干扰。生成的涂鸦线条相对比较精准,能较好地反映物体的形状和位置关系,适合用于需要精确控制图像轮廓的场景。
适用场景:在将照片转换为具有简洁线条风格的插画时非常有用,例如将人物照片转化为卡通风格的人物线稿,或者将风景照片转化为简约的风景轮廓图 。
2)invert (from white bg & black line)
原理:这并不是严格意义上基于某种算法进行涂鸦线条提取的预处理器,而是一种对图像颜色进行反转的操作,专门针对背景为白色、线条为黑色的图像。当输入图像符合这种颜色模式时,通过这个预处理器可以将其转换为背景为黑色、线条为白色的图像,以适配后续模型的输入要求。
特点和优势:操作简单直接,能够快速调整图像的颜色模式,方便与其他基于黑色线条输入的涂鸦模型或算法配合使用,提高工作效率。
适用场景:适用于那些通过手动绘制或其他方式得到的白底黑线涂鸦图像,在使用ControlNet进行进一步处理之前,先通过这个预处理器进行颜色转换。
3)scribble_xdog
原理:基于XDoG(eXtended Difference of Gaussians,扩展高斯差分)算法,这是一种用于边缘检测和图像风格化的技术。scribble_xdog预处理器利用XDoG算法的特性,对输入图像进行处理,生成具有独特风格的涂鸦线条。它可以模拟人类手绘涂鸦的效果,使生成的线条带有一定的随机性和艺术感。
特点和优势:生成的涂鸦线条具有很强的艺术风格,线条粗细变化自然,能给人一种手绘的感觉。对于追求艺术化、个性化涂鸦效果的应用场景,它能够提供非常独特的视觉体验。
适用场景:在艺术创作领域,如生成具有艺术感的海报、插画的草图阶段,或者在设计具有个性化风格的UI界面元素时,scribble_xdog可以帮助设计师快速获得具有创意的线条稿。
4)scribble_hed
原理:基于HED(Holistically-Nested Edge Detection,整体嵌套边缘检测)算法。HED是一种性能优越的边缘检测方法,能够在多尺度上对图像进行边缘检测,提取出丰富的边缘信息。scribble_hed预处理器会将HED检测到的边缘信息进行简化和抽象,转化为涂鸦风格的线条表示。
特点和优势:能够检测到图像中较为完整和细致的边缘信息,生成的涂鸦线条相对比较丰富,能较好地保留图像中的细节特征。在需要保留较多图像细节的涂鸦转换中表现出色。
适用场景:当需要将具有复杂细节的图像转换为涂鸦风格,同时又希望保留一定细节信息时,比如将一幅精细的工笔画转化为涂鸦风格的作品,scribble_hed可以在简化图像的同时,尽量保留画面中的关键细节。
6 Seg语义分割
Segmentation的完整名称是Semantic Segmentation语义分割,很多时候简称为Seg。和以上其他线稿类控制类型不同,它可以在检测内容轮廓的同时将画面划分为不同区块,并对区块赋予语义标注,从而实现更加精准的控图效果。
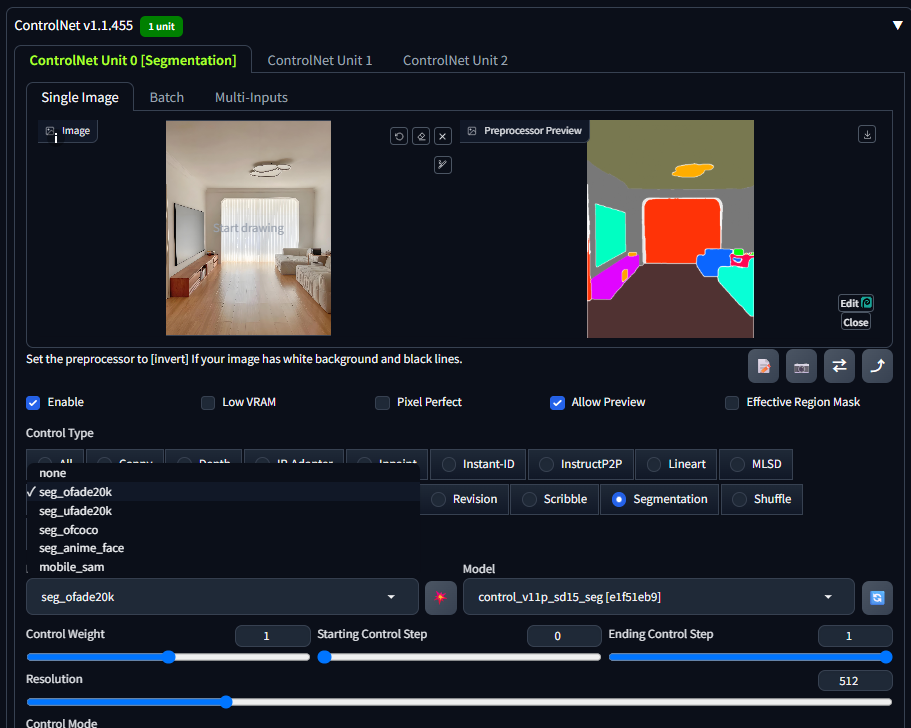
Seg预处理器检测后的图像包含了不同颜色的板块图,就像现实生活中的区块地图。画面中不同的内容会被赋予相应的颜色,这样限定区块的方式有点类似局部重绘的效果,在生成图像时模型会在对应色块范围内生成特定对象,从而实现更加准确的内容还原。
3.2 景深类
前面的轮廓类都是在二维平面角度的图像检测,有没有可以体现三维层面的控图类型呢?这就不得不提景深类ControlNet模型了。景深一词是指图像中物体和镜头之间的距离,简单来说这类模型可以体现元素间的前后关系,包括Depth深度和NormalMap法线贴图这2 种老牌模型。
1 Depth
深度图也被称为距离影像,可以将从图像采集器到场景中各点的距离(深度)作为像素值的图像,它可以直接体现画面中物体的三维深度关系。学习过三维动画知识的朋友应该听说过深度图,该类图像中只有黑白两种颜色,距离镜头越近则颜色越浅(白色),距离镜头越近则颜色越深(黑色)。
Depth模型可以提取图像中元素的前后景关系生成深度图,再将其复用到绘制图像中,因此当画面中物体前后关系不够清晰时,可以通过Depth模型来辅助控制。下图中可以看到通过深度图很好的还原了建筑中的空间景深关系。
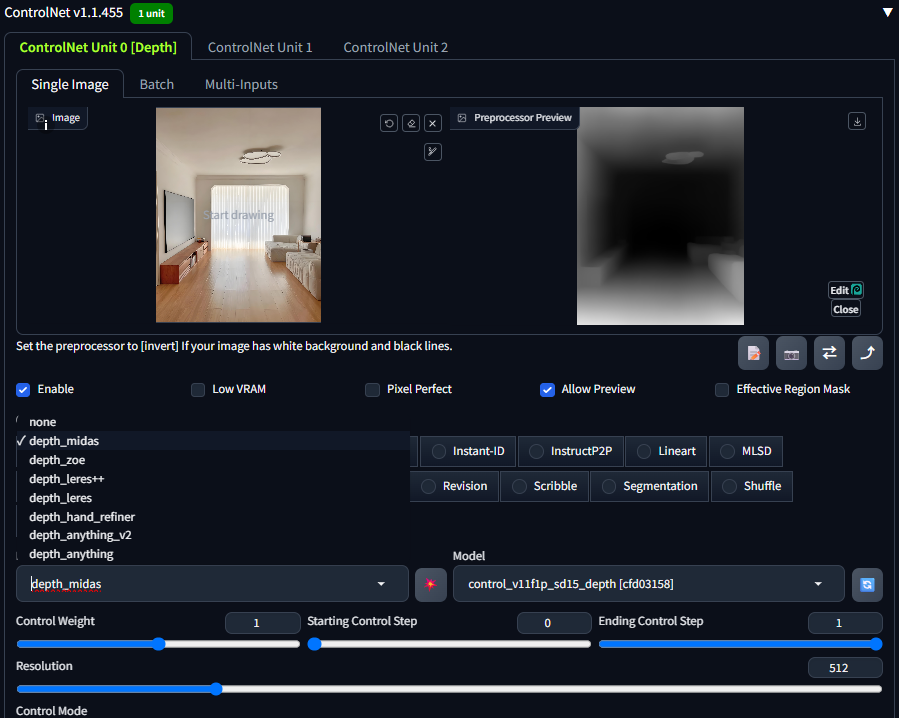
根据预处理器算法的不同,Depth 在最终成像上也有差异,实际使用时大家可以根据预处理的深度图来判断哪种深度关系呈现更加合适。
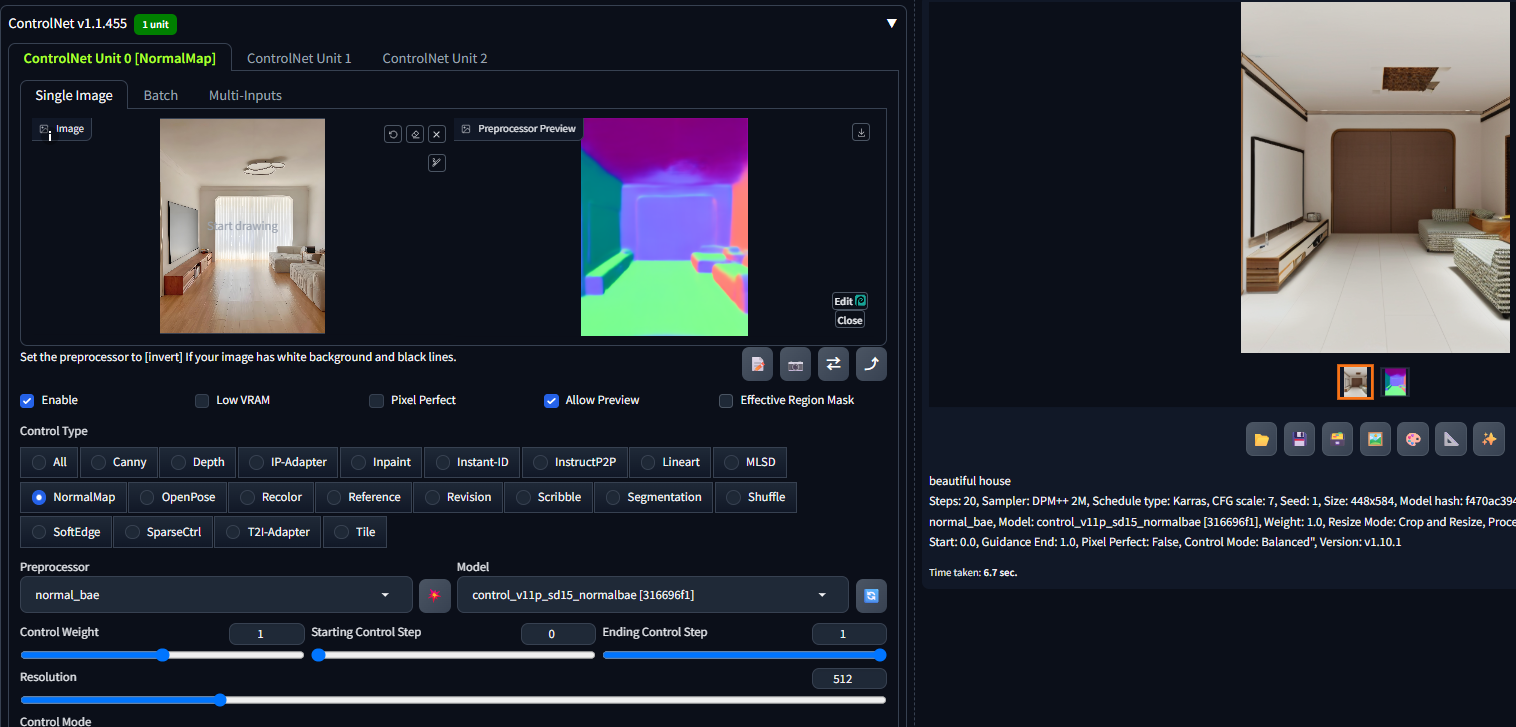
2 NormalMap法线贴图
另一种可以体现景深关系的图像叫NormalMap法线贴图,要理解它的工作原理,我们需要先回顾下法线的概念。在中学时期有学过法线,它是垂直与平面的一条向量,因此储存了该平面方向和角度等信息。通过在物体凹凸表面的每个点上均绘制法线,再将其储存到 RGB的颜色通道中,其中R红色、G绿色、B蓝色分别对应了三维场景中XYX空间坐标系,这样就能实现通过颜色来反映物体表面的光影效果,而由此得到的纹理图我们将其称为法线贴图。由于法线贴图可以实现在不改变物体真实结构的基础上也能反映光影分布的效果,被广泛应用在CG动画渲染和游戏制作等领域。
ControlNet的NormalMap模型就是根据画面中的光影信息,从而模拟出物体表面的凹凸细节,实现准确还原画面内容布局,因此 NormalMap 多用于体现物体表面更加真实的光影细节。
3.3 对象类
OpenPose作为唯一一款专门用来控制人物肢体和表情特征的关键模型,它被广泛用于人物图像的绘制,常用的预处理器及其简介如下图所示:

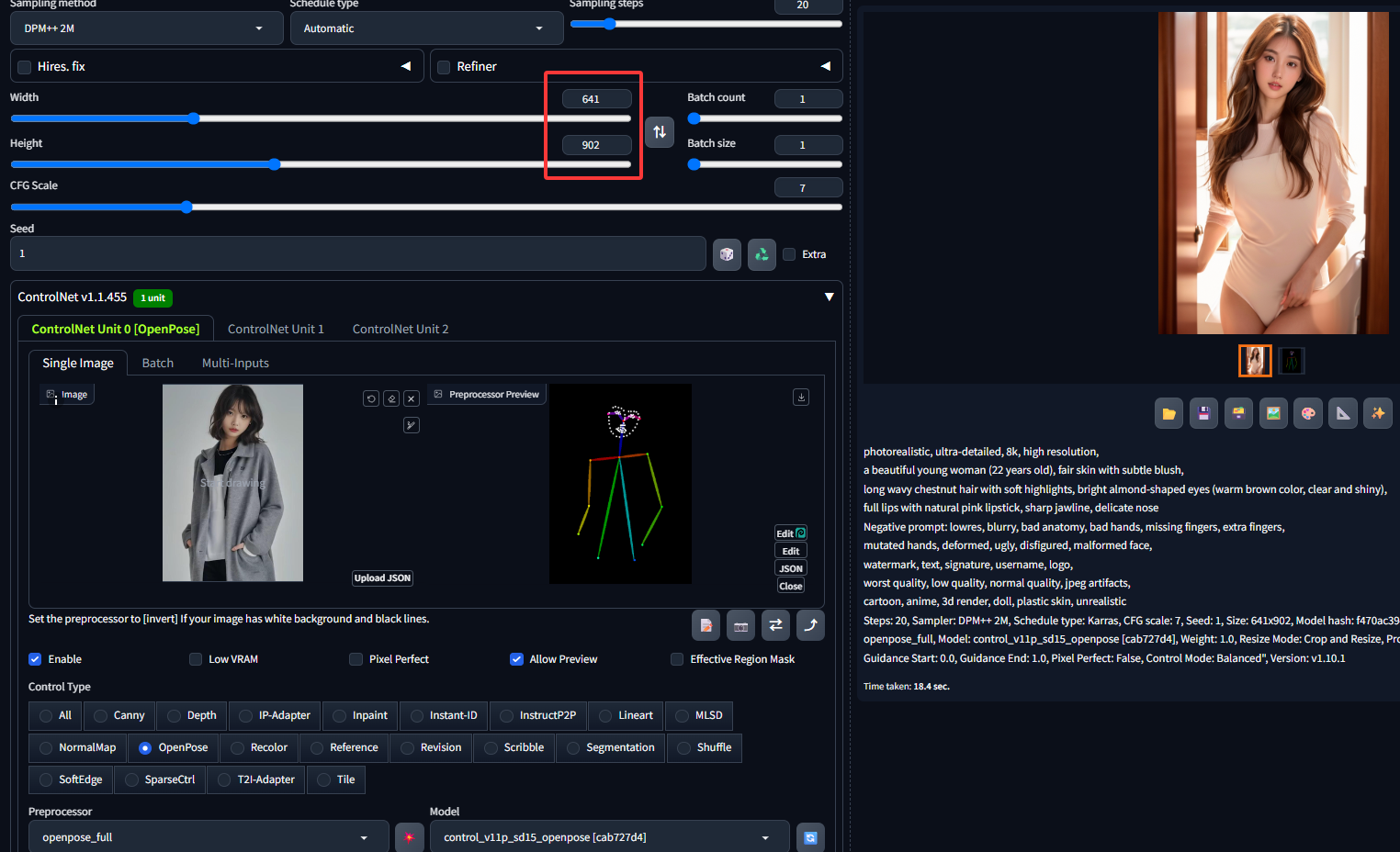
OpenPose姿态检测预处理器full,用于生成了一个基于节点和连线的骨骼火柴人的形象。相较于其他固定角色姿势的controlnet方案来说,这种技术的优势是支持多个OpenPose骨架组合成一个图像,达到精确控制多角色同屏的效果。此外由于还支持通过插件手动调节骨骼节点,也就便利了喜欢自已定义动作的同学。所有这些辅助骨骼信息会形成ControlNet的输入条件(condition)从而影响和引导稳定扩散模型的生成过程,获得符合预设姿势的生成图。提示词、模型及主要配置不变,仅仅修改分辨率为新导入图片的分辨率,在姿态检测的基础上重新生成图片,效果如下:
直接通过右侧火柴人上面的"Edit"按钮对姿态进行调整:
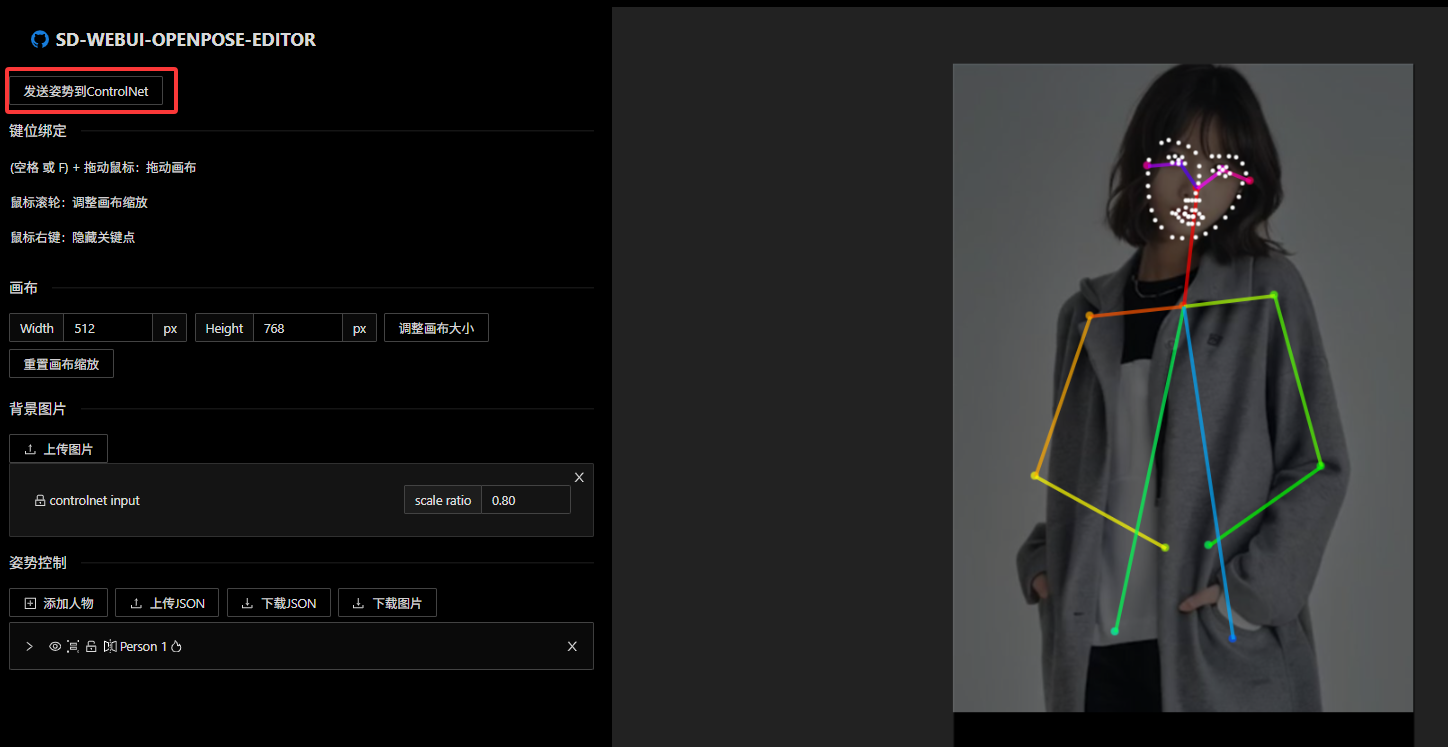
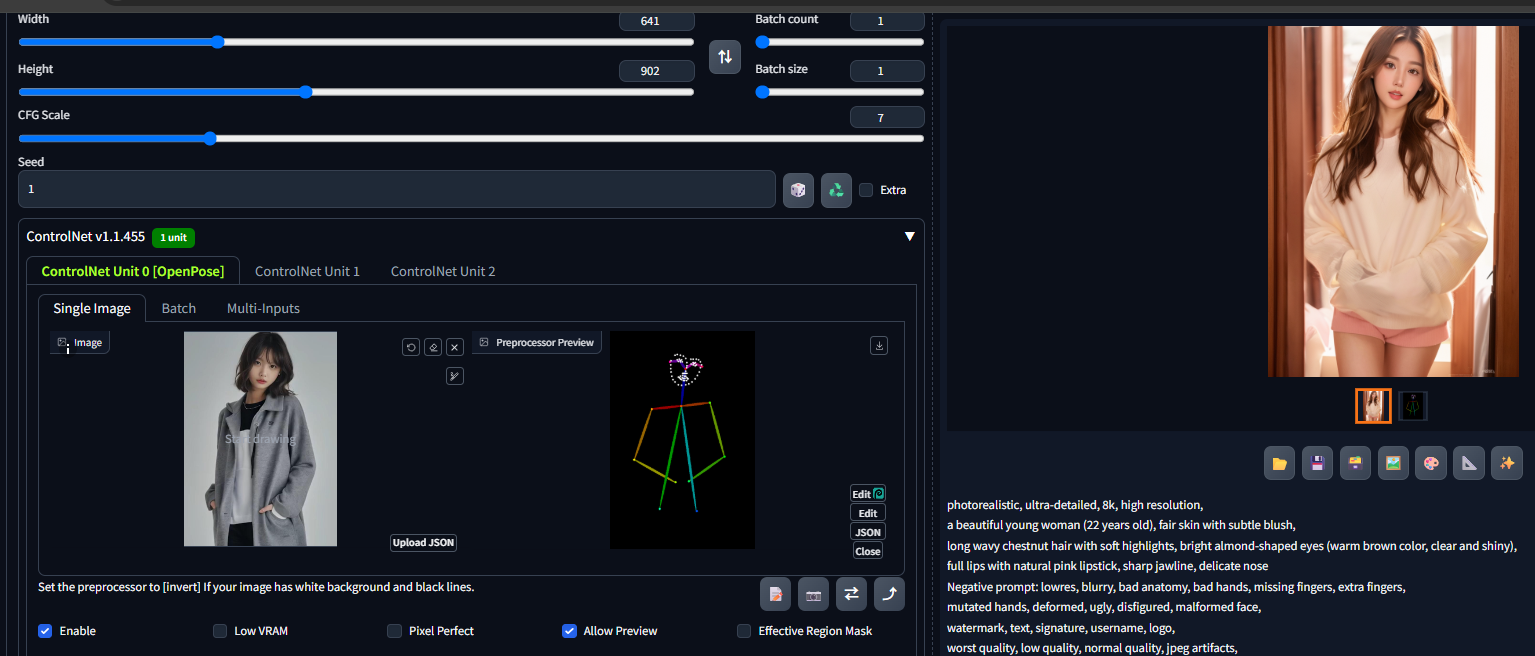
调整完成后再"发送姿势到ControlNet",保持原有配置再次进行生成,从结果可见已经根据新的姿态生成新的图象,如下图所示。当然在上图中还可以进行"添加人物","上传JSON"等更多操作,以实现多人物融合生成。
3.4 重绘类
接着是最后的重绘类模型,在ControlNet中这类重绘模型是对原生图生图功能的延伸和拓展。
1 Inpaint局部重绘
先来看看我们熟悉的局部重绘 ,ControlNet中的Inpaint相当于更换了原生图生图的算法,在使用时还是受重绘幅度等参数的影响。如下图的案例中我们使用默认的重绘幅度对美女脸部进行了重绘:
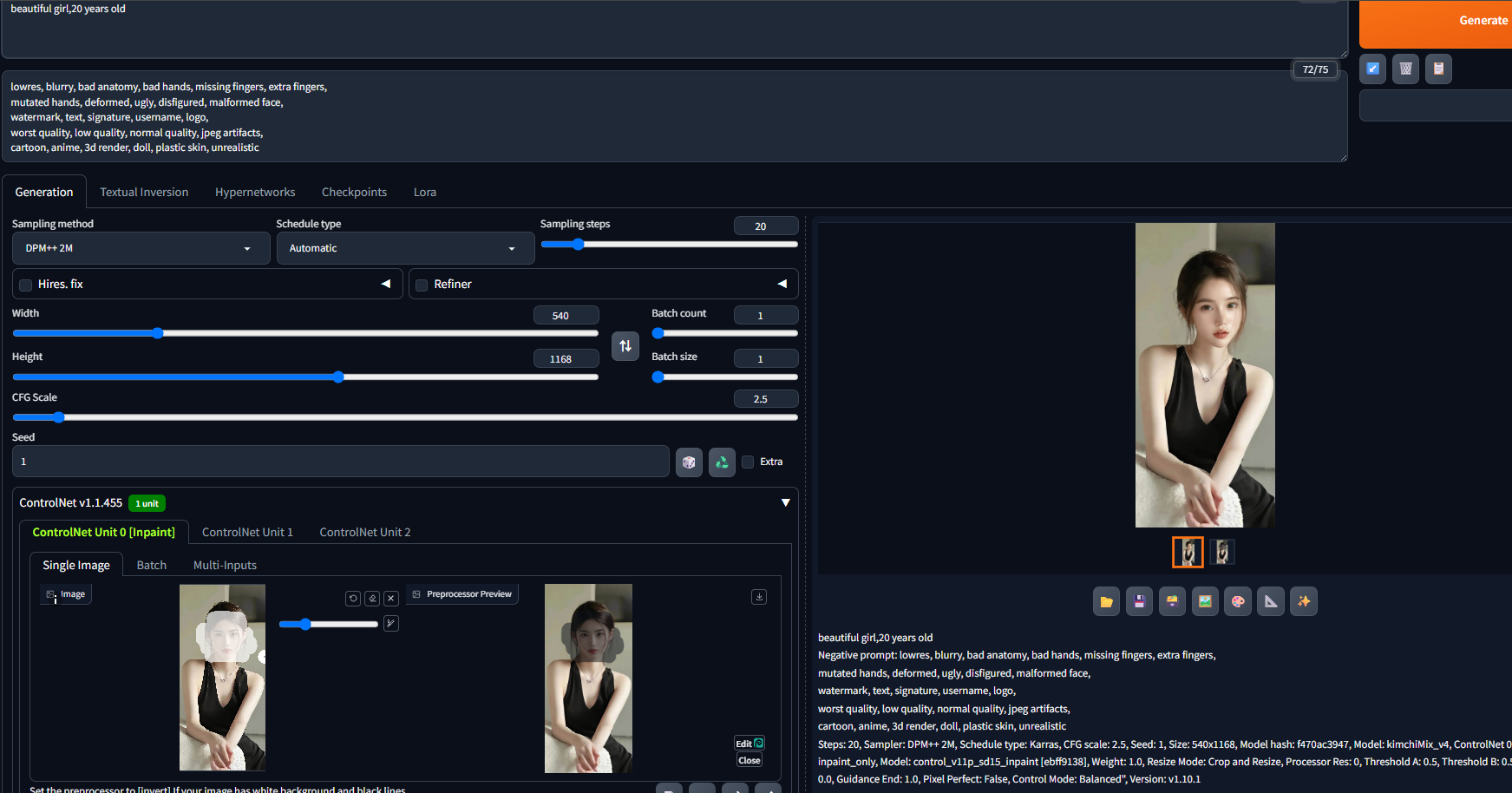
局部重绘这里提供了3种预处理器,Global_Harmonious、only和only+lama,通过实际测试来看整体出图效果上差异不大。
2 Tile分块
在SD开源这大半年中,绘制超分辨率的高清大图一直是很多极客玩家的追求,但限于显卡高昂的价格和算力瓶颈,通过WebUI直出图的方式始终难以达到满意的目标。后来聪明的开发者想到Tile分块绘制的处理方法,原理就是将超大尺寸的图像切割为显卡可以支持的小尺寸图片进行挨个绘制,再将其拼接成完整的大图,虽然绘图时间被拉长,但极大的提升了显卡性能的上限,真正意义上实现了小内存显卡绘制高清大图的操作。

但这个过程中始终有个问题困扰着很多开发者,那就是分块后的小图始终难以摆脱全局提示词的影响。举个例子,我们的提示词是 1girl,当图像分割为 16 块进行绘制时,每个块都会被识别成一张独立的图片,导致每个块中可能都会单独绘制一个女孩。而 ControlNet Tile 巧妙的解决了这个问题。在绘制图像时启用 Tile 模型,它会主动识别单独块中的语义信息,减少全局提示的影响。具体来说,这个过程中 Tile 进行了 2 种处理方式:
1)忽略原有图像中的细节并生成新的细节。
2)如果小方块的原有语义和提示词不匹配,则会忽略全局提示词,转而使用局部的上下文来引导绘图。
在之前图生图给大家介绍重绘幅度参数时,有提到增大重绘幅度可以明显提升画面细节,但问题是一旦设定重绘幅度画面内容很容易就发生难以预料的变化,而配合Tile进行控图就能完美的解决这个问题,因为Tile模型的最大特点就是在优化图像细节的同时不会影响画面结构。
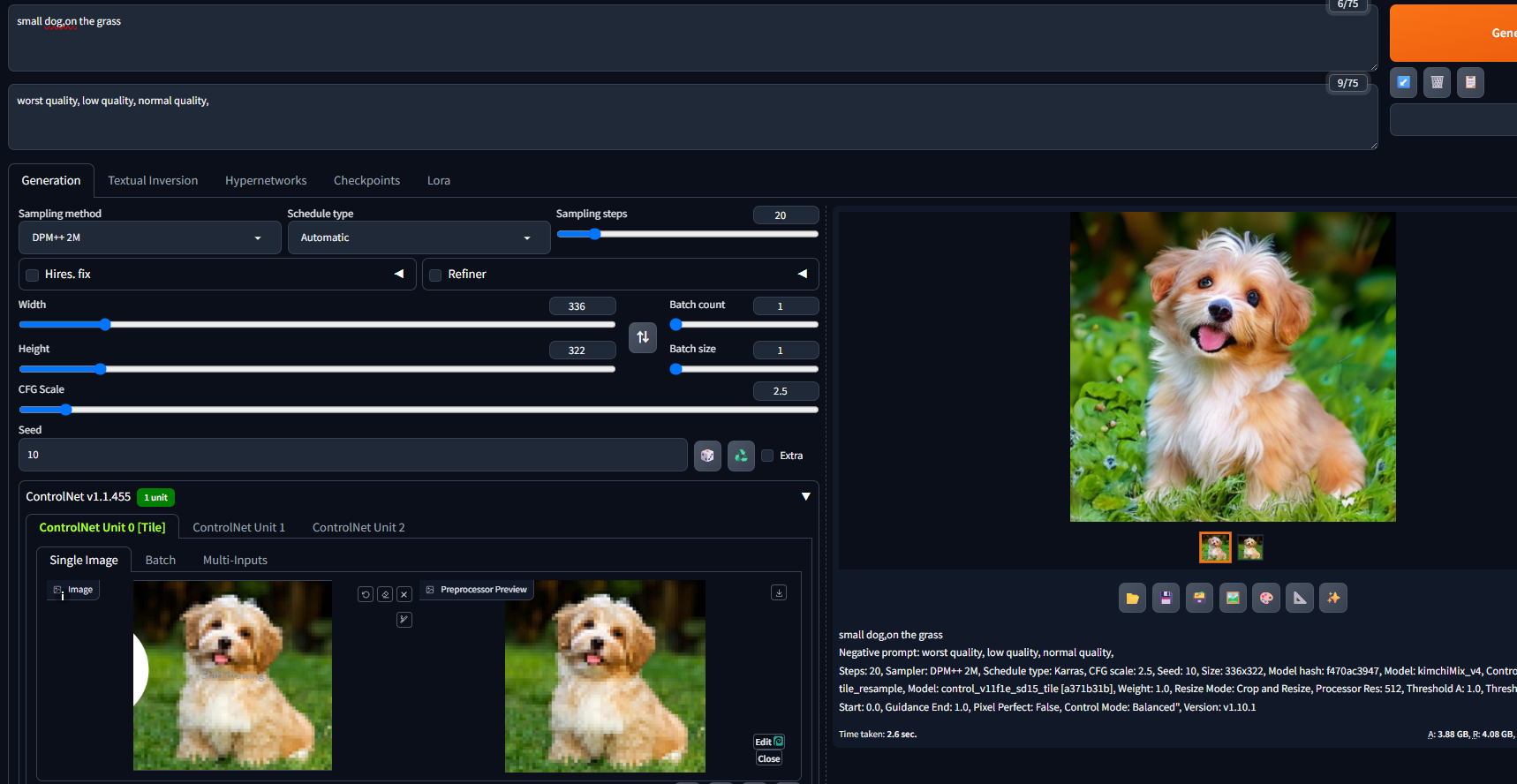
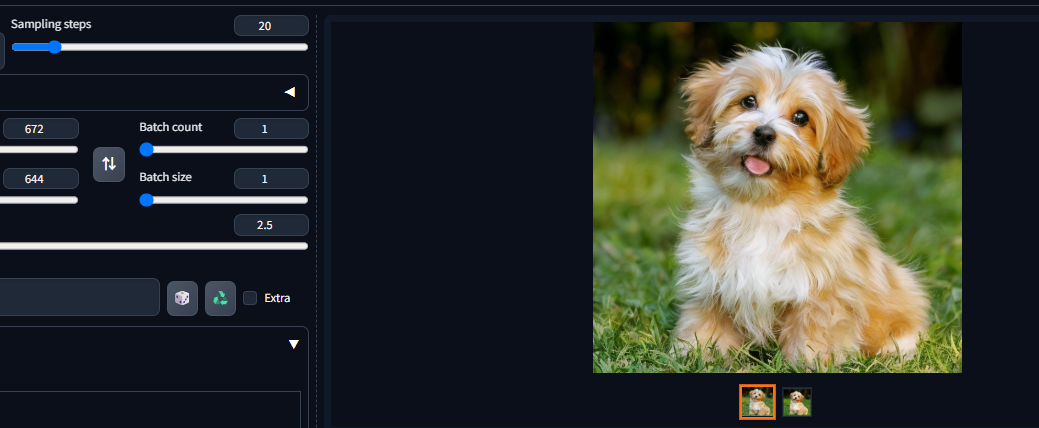
基于以上特点,ControlNet Tile被广泛用于图像细节修复和高清放大,最典型的就是配合Tile Diffusion等插件实现4k、8k图的超分放大,相较于传统放大,Tile可以结合周围内容为图像增加更多合理细节。理论上来说,只要分得块足够多,配合Tile可以绘制任意尺寸的超大图。例如保持其他配置不变,只是将分辨率翻倍,则可以生成更为清晰的图片(狗的毛发细节更新清晰):
3 InstructP2P指导图生图
InstructP2P的全称为Instruct Pix2Pix指导图生图,使用的是Instruct Pix2Pix数据集训练的ControlNet。它的功能可以说和图生图基本一样,会直接参考原图的信息特征进行重绘,因此并不需要单独的预处理器即可直接使用。IP2P目前还处于试验阶段,并不是一种成熟的 ControlNet 模型,平时使用并不多。
4 Shuffle随机洗牌
随机洗牌是非常特殊的控图类型,它的功能相当于将参考图的所有信息特征随机打乱再进行重组,生成的图像在结构、内容等方面和原图都可能不同,但在风格上你依旧能看到一丝关联(耷拉着的小耳朵)。
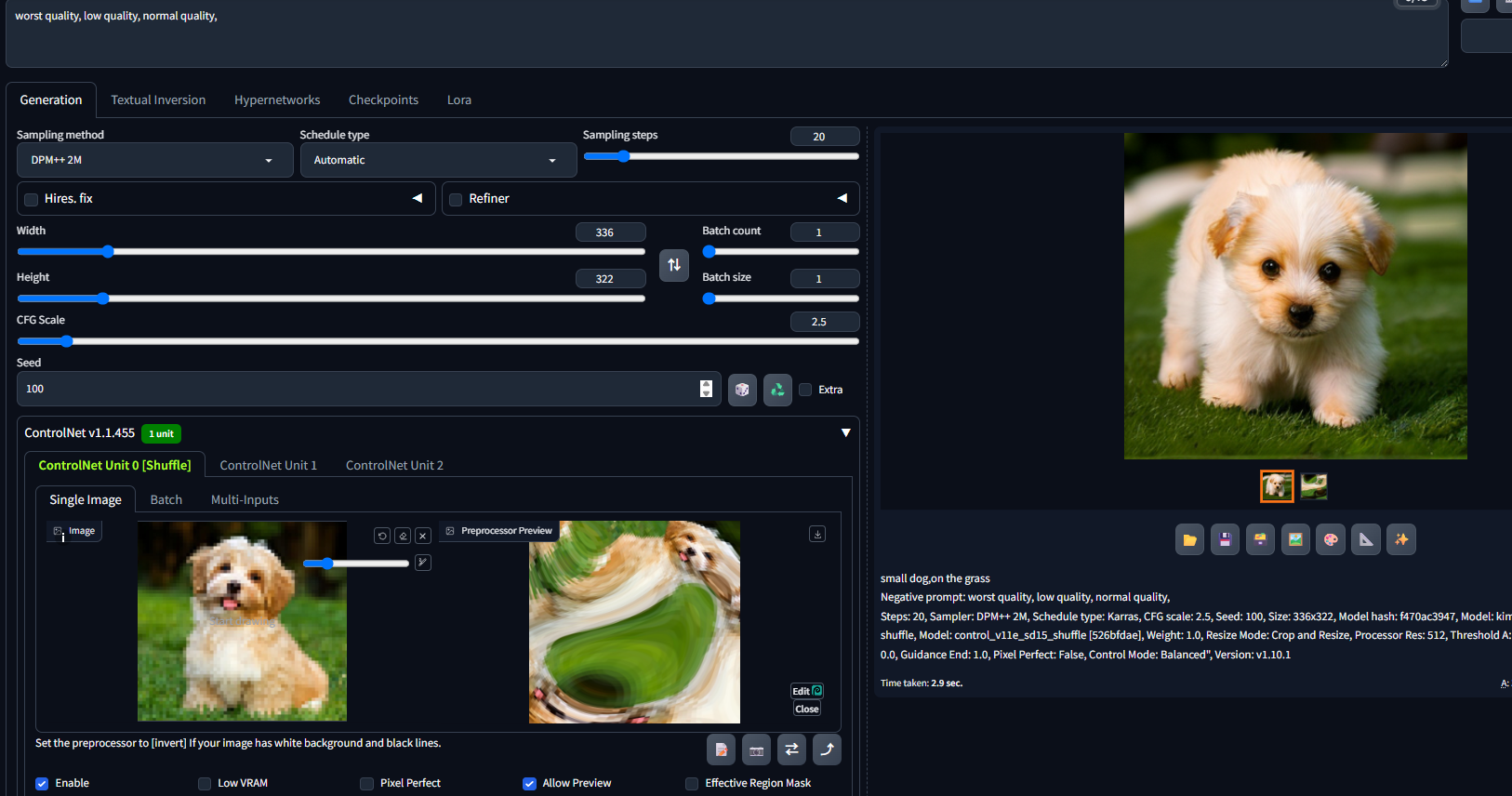
不同于其他预处理器,Shuffle在提取信息特征时完全随机,因此会收到种子值的影响,当种子值不同时预处理后的图像也会是千奇百怪。Shuffle的使用场景并不多,因为它的控图稳定性可以说所有ControlNet模型中最差的一种,你可以将它当作是另类的抽卡神器,用它来获取灵感也是不错的选择。
以上是官方模型,参考3文章还在第3部分介绍了社区模型Reference、Recolor、T2I-Adapter等的解析及使用,感兴趣的可以直接阅读相应内容。