arm上的kafka测试
-
- [1. 我的任务](#1. 我的任务)
- [2. 前置知识](#2. 前置知识)
-
- [2.1 消息队列](#2.1 消息队列)
- [2.2 Kafka简介](#2.2 Kafka简介)
- [3. ARM架构](#3. ARM架构)
-
- [3.1 安装**Kafka和Zookeeper**](#3.1 安装Kafka和Zookeeper)
- [3.2 运行Kafka](#3.2 运行Kafka)
- [3.3 **性能测试**](#3.3 性能测试)
-
- [3.3.1 测试结果](#3.3.1 测试结果)
- [3.4 功能测试](#3.4 功能测试)
-
- [3.4.1 测试结果](#3.4.1 测试结果)
- [3.5 问题与解决](#3.5 问题与解决)
- [4. RISC-V架构](#4. RISC-V架构)
-
- [4.1 问题](#4.1 问题)
- [4.2 部分解决](#4.2 部分解决)
- [5. 实验总结](#5. 实验总结)
1. 我的任务
我的任务是进行大数据组件Kafka在ARM架构Kunpeng 920服务器和RISC-V架构SG2042服务器上的功能支持与性能测试。我完成了Kafka在Kunpeng 920服务器上的性能测试,记录了表格中要求的所有性能数据,并进行了Topic相关的功能测试;然而在RISC-V架构遇见了JDK环境问题导致Kafka无法运行,没有进行性能测试和功能测试。
2. 前置知识
2.1 消息队列
kafka是一个分布式的基于发布/订阅模式的消息队列,我通过阅读博客和实践,重点了解了消息队列概念、Kafka简介和在性能测试中使用到的逻辑概念topic,内容如下:
消息队列就是将需要传输的数据存放在队列中,可用于解耦复杂系统,属于生产者-消费者模型,有以下两种模式:
-
点对点模式:每个消息只有一个接收者(Consumer)(即一旦被消费,消息就不再在消息队列中);发送者和接收者间没有依赖性,发送者发送消息之后,不管有没有接收者在运行,都不会影响到发送者下次发送消息;接收者在成功接收消息之后需向队列应答成功,以便消息队列删除当前接收的消息;
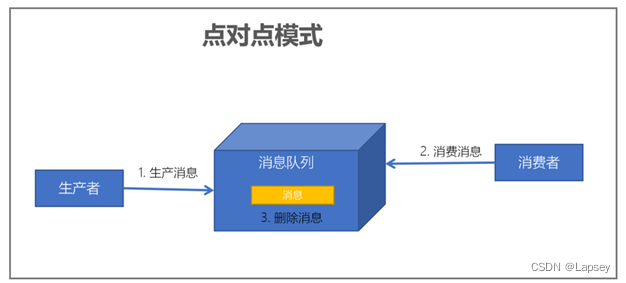
-
发布/订阅模式:每个消息可以有多个订阅者;发布者和订阅者之间有时间上的依赖性。针对某个主题(Topic)的订阅者,它必须创建一个订阅者之后,才能消费发布者的消息。为了消费消息,订阅者需要提前 订阅该角色主题,并保持在线运行;
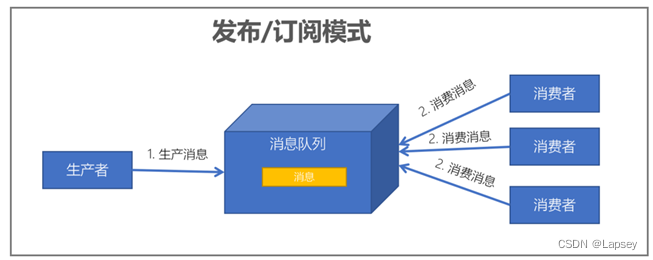
2.2 Kafka简介
我们通常将Apache Kafka用在两类程序:1. 建立实时数据管道,以可靠地在系统或应用程序之间获取数据;2. 构建实时流应用程序,以转换或响应数据流。模型如下: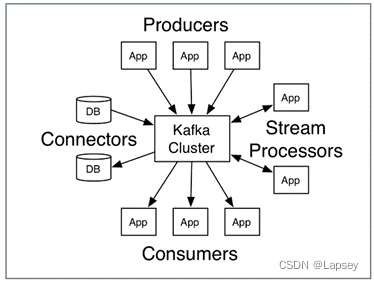
-
Producers:可以有很多的应用程序,将消息数据放入到Kafka集群中。
-
Consumers:可以有很多的应用程序,将消息数据从Kafka集群中拉取出来。
-
Connectors:Kafka的连接器可以将数据库中的数据导入 到Kafka,也可以将Kafka的数据导出到数据库中。
-
Stream Processors:流处理器可以Kafka拉取 数据,也可以将数据写入到Kafka中。
Kafka 的 topic 是一个逻辑概念,用于对消息进行分类。在 Kafka 中,消息以流的形式组织,而 topic 就是这些消息流的名称。每个 topic 可以被视为一个消息类别或者消息队列。用途如下:
-
消息分类:topic 允许你将消息按照某种特定的类别进行分组。例如,一个公司的 Kafka 集群可能会有多个 topic,分别用于存储用户行为日志、系统监控数据、交易记录等。
-
数据持久化:Kafka 是一个持久化的消息系统,存储在 topic 中的消息会保留在磁盘上,直到它们被消费或者超过了设置的保留策略。
-
分区:为了能够横向扩展和并行处理,每个 Kafka topic 可以被分割成多个分区(partitions)。分区允许多个生产者和消费者并发地读写数据,提高了系统的吞吐量。
-
复制:为了提高数据的可靠性和可用性,每个分区可以被复制到多个 broker 上。Kafka 通过复制因子(replication factor)来定义每个分区的副本数量。
-
消费者组:Kafka 支持消费者组(consumer groups)的概念,允许多个消费者实例协调工作,共同消费同一个 topic 中的消息。
-
消息顺序:在同一个分区内,Kafka 保证消息的顺序。如果应用需要严格的顺序保证,可以通过单分区或者有序的分区键来实现。
-
保留策略:Kafka 允许你设置消息的保留时间或大小,超过这个时间或大小的消息将被删除。这有助于控制存储使用。
-
创建和删除:你可以使用 Kafka 提供的命令行工具或 API 来创建和删除 topic。
-
配置:topic 可以有自己的配置,如保留时间、清理策略、最小和最大消息大小等。
3. ARM架构
3.1 安装Kafka和Zookeeper
- 安装与解压
shell
wget https://archive.apache.org/dist/kafka/2.2.0/kafka_2.12-2.2.0.tgz
tar -zxvf kafka_2.12-2.2.0.tgz
#openjdk使用的毕昇自带的8u412
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
tar -zxvf zookeeper-3.4.6.tar.gz- 在~/.bash_profile中添加环境变量
shell
export KAFKA_HOME=~/kafka_2.12-2.2.0
export PATH=$KAFKA_HOME/bin:$PATH
export ZOOKEEPER_HOME=~/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH- 配置config/server.properties,修改的内容如下
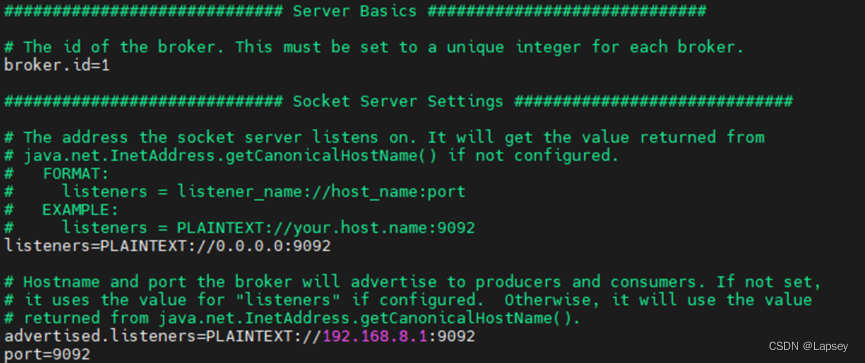
3.2 运行Kafka
-
先启动Zookeeper:
bin/zookeeper-server-start.sh config/zookeeper.properties -
然后启动Kafka服务:
bin/kafka-server-start.sh config/server.properties
-
测试是否成功启动:在服务器上打开一个生产者,然后把输入的每行数据发送到Kafka中,再打开一个消费者,当有数据往Kafka的test主题发送消息,这边就会进行消费。
shellbin/kafka-console-producer.sh --broker-list localhost:9092 --topic test #后面光标提示数据数据,然后回车就会发送到kafka中了 bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning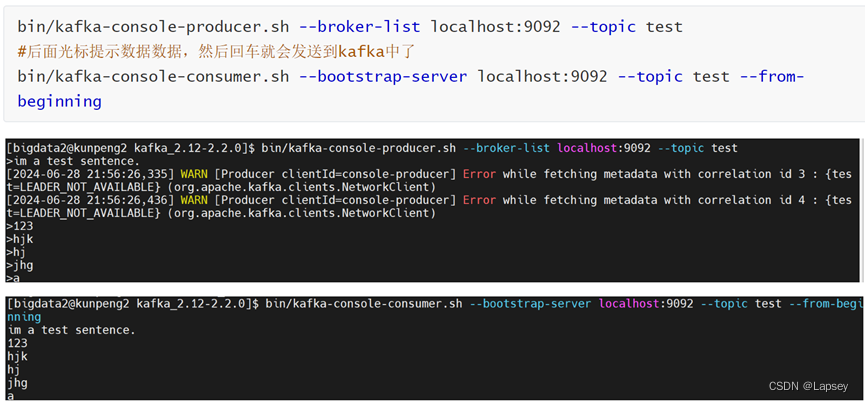
3.3 性能测试
参考教程。
-
创建topic:创建名为
test-rep-one,分区为6,复制因子为1的主题。数据的保留时间为1小时。bash$ bin/kafka-topics.sh \ --create \ --topic test-rep-one \ --partitions 6 \ --replication-factor 1 \ --config retention.ms=86400000 \ --bootstrap-server localhost:9092 -
使用不同的生产者性能测试脚本。以下示例将使用上面创建的主题来存储300万条数据,每条消息的大小为1KB。
-throughput设为-1时表示消息会尽快生成。bash$ bin/kafka-producer-perf-test.sh \ --topic test-rep-one \ --throughput -1 \ --num-records 3000000 \ --record-size 1024 \ --producer-props acks=all bootstrap.servers=localhost:9092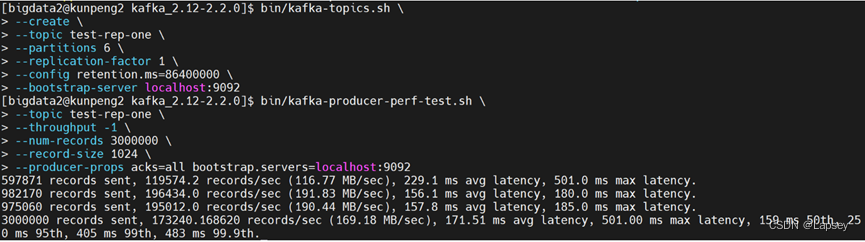
-
测试消费者性能。
bash$ bin/kafka-consumer-perf-test.sh \ --topic test-rep-one \ --broker-list localhost:9092 \ --messages 3000000

-
加入公共指标:对于kafka-producer-perf-test.sh和kafka-consumer-perf-test.sh,将第2、3步的命令添加在脚本后即可;而对于kafka-topics.sh,我选择了列举topics的命令进行测试:
performance_counter_920.sh "bin/kafka-topics.sh --list --bootstrap-server localhost:9092" ./。因为每次测试的结果都不同,我未记录第2、3步中的结果,公共和非公共性能指标均记录自本次结果,运行截图如下:
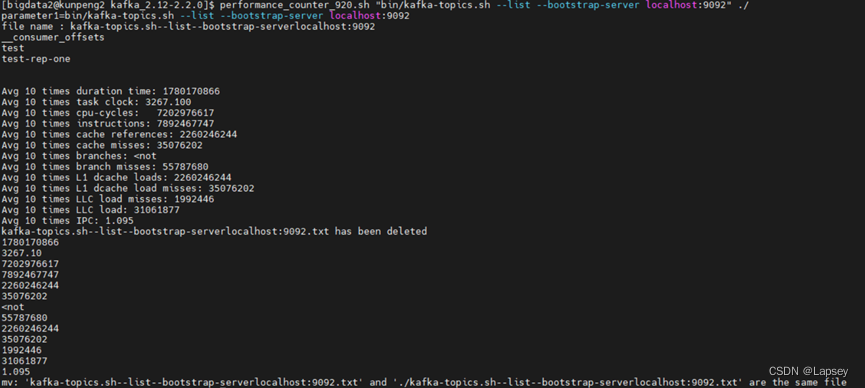
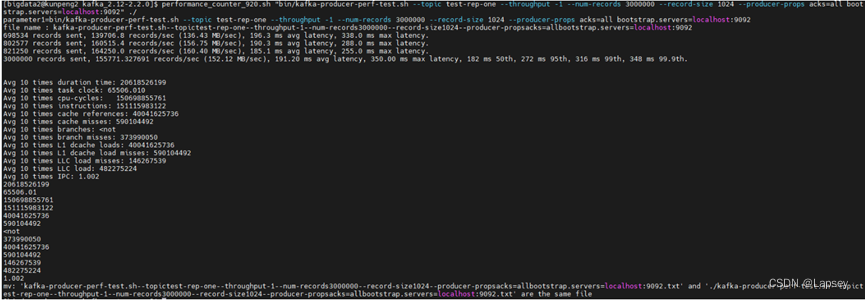
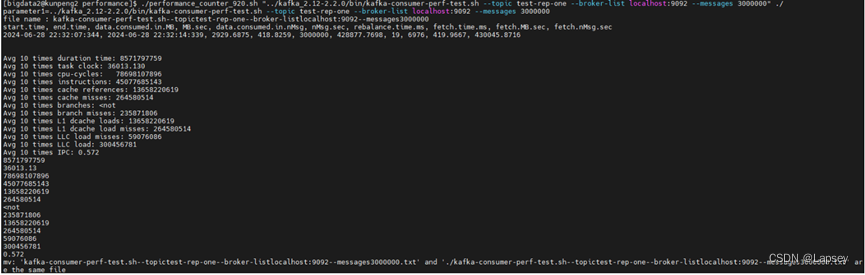
因为组长在bash_profile配了这个,所以系统 会在该路径找sh脚本,就无需进入performance目录下执行了

3.3.1 测试结果
| 比较类目 | CPU | ARM(鲲鹏920-7260) |
|---|---|---|
| kafka-topics.sh | duration_time | 1780170866 |
| kafka-topics.sh | task-clock | 3267.100 |
| kafka-topics.sh | cycles | 7202976617 |
| kafka-topics.sh | instructions | 7892467747 |
| kafka-topics.sh | cache-references | 2260246244 |
| kafka-topics.sh | cache-misses | 35076202 |
| kafka-topics.sh | branches | <not |
| kafka-topics.sh | branch-misses | 55787680 |
| kafka-topics.sh | L1-dcache-loads | 2260246244 |
| kafka-topics.sh | L1-dcache-load-misses | 35076202 |
| kafka-topics.sh | LLC load misses | 1992446 |
| kafka-topics.sh | LLC load | 31061877 |
| kafka-topics.sh | IPC | 1.095 |
| kafka-producer-perf-test.sh | duration_time | 20618526199 |
| kafka-producer-perf-test.sh | task-clock | 65506.01 |
| kafka-producer-perf-test.sh | cycles | 150698855761 |
| kafka-producer-perf-test.sh | instructions | 151115983122 |
| kafka-producer-perf-test.sh | cache-references | 40041625736 |
| kafka-producer-perf-test.sh | cache-misses | 590104492 |
| kafka-producer-perf-test.sh | branches | <not |
| kafka-producer-perf-test.sh | branch-misses | 373990050 |
| kafka-producer-perf-test.sh | L1-dcache-loads | 40041625736 |
| kafka-producer-perf-test.sh | L1-dcache-load-misses | 590104492 |
| kafka-producer-perf-test.sh | LLC load misses | 146267539 |
| kafka-producer-perf-test.sh | LLC load | 482275224 |
| kafka-producer-perf-test.sh | IPC | 1.002 |
| kafka-producer-perf-test.sh | records sent | 3000000 records sent |
| kafka-producer-perf-test.sh | average throughput | 155771.327691 records/sec |
| kafka-producer-perf-test.sh | throughput rate | 152.12MB/sec |
| kafka-producer-perf-test.sh | avg latency | 191.20ms |
| kafka-producer-perf-test.sh | max latency | 350.00ms |
| kafka-producer-perf-test.sh | 50th latency | 182ms |
| kafka-producer-perf-test.sh | 95th latency | 272ms |
| kafka-producer-perf-test.sh | 99th latency | 316ms |
| kafka-producer-perf-test.sh | 99.9th latency | 348ms |
| kafka-consumer-perf-test.sh | duration_time | 8571797759 |
| kafka-consumer-perf-test.sh | task-clock | 36013.13 |
| kafka-consumer-perf-test.sh | cycles | 78698107896 |
| kafka-consumer-perf-test.sh | instructions | 45077685143 |
| kafka-consumer-perf-test.sh | cache-references | 13658220619 |
| kafka-consumer-perf-test.sh | cache-misses | 26480514 |
| kafka-consumer-perf-test.sh | branches | <not |
| kafka-consumer-perf-test.sh | branch-misses | 235871806 |
| kafka-consumer-perf-test.sh | L1-dcache-loads | 13658220619 |
| kafka-consumer-perf-test.sh | L1-dcache-load-misses | 264580514 |
| kafka-consumer-perf-test.sh | LLC load misses | 59076086 |
| kafka-consumer-perf-test.sh | LLC load | 300456781 |
| kafka-consumer-perf-test.sh | IPC | 0.572 |
| kafka-consumer-perf-test.sh | average throughput | 428877.7698 records/sec |
| kafka-consumer-perf-test.sh | throughput rate | 418.8259MB/sec |
3.4 功能测试
因为时间的原因,我只测试了topic相关的部分功能,运行截图如下:
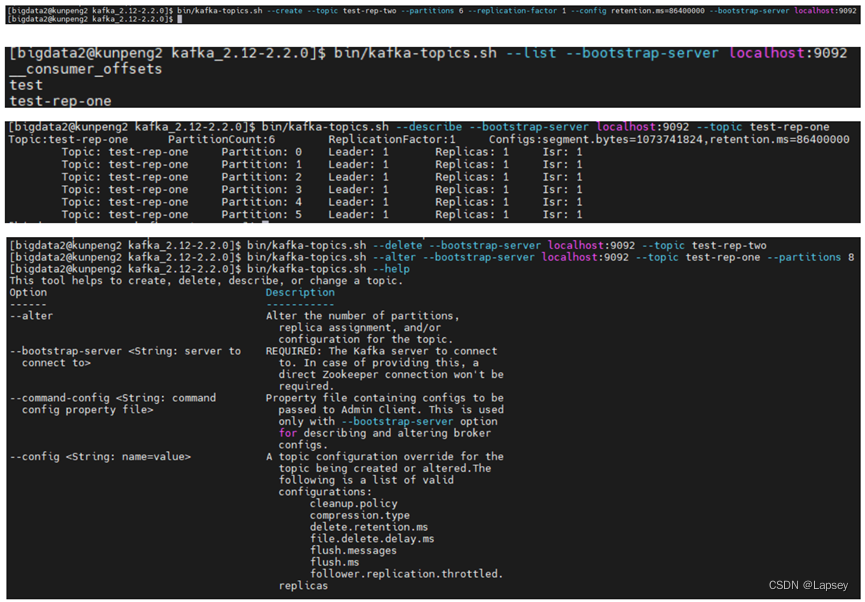
3.4.1 测试结果
| CPU功能测试项 | introduction | note | command | PASS | ARM-result |
|---|---|---|---|---|---|
| topics | |||||
| topics alter | 修改topic | 修改分区数时,仅能增加分区个数。若是用其减少 partition 个数,则会报错 | bin/kafka-topics.sh --alter --bootstrap-server localhost:9092 --topic test-rep-one --partitions 8 | Y | 没有返回值,则说明修改成功 |
| topics config | 创建topic的覆盖配置 | bin/kafka-topics.sh --create --topic test-rep-one --partitions 6 --replication-factor 1 --config retention.ms=86400000 --bootstrap-server localhost:9092 | Y | ||
| topics create | 创建topic | bin/kafka-topics.sh --create --topic test-rep-one --partitions 6 --replication-factor 1 --config retention.ms=86400000 --bootstrap-server localhost:9092 | Y | 没有返回值,则说明创建成功 | |
| topics delete | 删除topic | bin/kafka-topics.sh --delete --bootstrap-server localhost:9092 --topic test-rep-two | Y | 没有返回值,则说明删除成功 | |
| topics delete-config | 删除topic的覆盖配置 | bin/kafka-topics.sh --zookeeper localhost:9092 --alter --topic test-rep-one --delete-config retention.ms | Y | ||
| topics describe | 查看指定topic明细 | bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic test-rep-one | Y | Topic:test-rep-one PartitionCount:6 ReplicationFactor:1 Configs:segment.bytes=1073741824,retention.ms=86400000 Topic: test-rep-one Partition: 0 Leader: 1 Replicas: 1 Isr: 1 Topic: test-rep-one Partition: 1 Leader: 1 Replicas: 1 Isr: 1 Topic: test-rep-one Partition: 2 Leader: 1 Replicas: 1 Isr: 1 Topic: test-rep-one Partition: 3 Leader: 1 Replicas: 1 Isr: 1 Topic: test-rep-one Partition: 4 Leader: 1 Replicas: 1 Isr: 1 Topic: test-rep-one Partition: 5 Leader: 1 Replicas: 1 Isr: 1 | |
| topics help | 显示kafka-topics.sh的帮助信息 | bin/kafka-topics.sh --help | Y | 太长了,为了格式已删除 | |
| topics list | 查看 Topic 列表 | bin/kafka-topics.sh --list --bootstrap-server localhost:9092 | Y | __consumer_offsets test test-rep-one | |
| topics partitions | 指定分区数 | bin/kafka-topics.sh --create --topic test-rep-one --partitions 6 --replication-factor 1 --config retention.ms=86400000 --bootstrap-server localhost:9092 | Y | 没有返回值,则说明创建成功 | |
| topics replica-assignment | |||||
| topics replication-factor | 指定复制因子 | bin/kafka-topics.sh --create --topic test-rep-one --partitions 6 --replication-factor 1 --config retention.ms=86400000 --bootstrap-server localhost:9092 | Y | 没有返回值,则说明创建成功 | |
| topics topic | |||||
| topics topics-with-overrides | |||||
| topics unavailable-partitions | |||||
| topics under-replicated-partitions | |||||
| topics zookeeper | bin/kafka-topics.sh --zookeeper localhost:9092 --alter --topic test-rep-one --delete-config retention.ms | Y |
3.5 问题与解决
-
安装完kafka集群后,程序创建topic时报错could not be established. Broker may not be available:https://www.cnblogs.com/charkey/p/16143422.html
-
kafka启动出错:原因是没有杀死进程https://blog.csdn.net/qq_38612955/article/details/81206284
4. RISC-V架构
4.1 问题
环境配置上除了config/server.properties中的IP地址不同,其他都一样。
在运行时首先遇见了"egrep is obsolescent using grep -e"的报错信息,将kafka-run-class.sh中的egrep替换成了grep -E后解决。
然后就一直有cannot execute binary file: Exec format error的报错,使用su root无法解决。应该是使用了其他架构编译好的二进制包的问题,试图下载gradle编译源代码,发现gradle也有环境不兼容的问题。可以看到是因为RV上的jdk环境有问题。

发现虽然有自带的jdk环境,但是使用不了: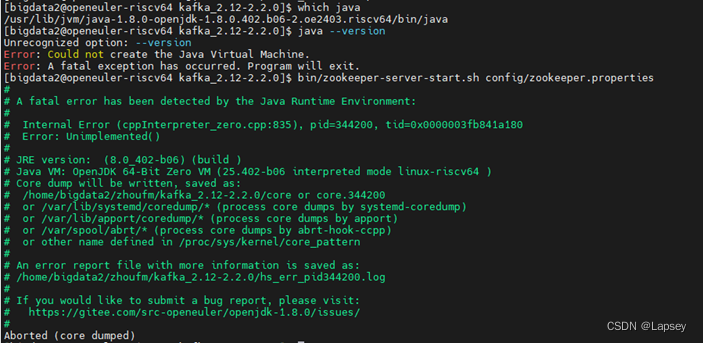
试图安装欧拉镜像的jdk,然后替换环境变量,但是安装rpm有问题,最后失败,未配置好Kafka环境。

4.2 部分解决
4.1 问题与解决
-
rv环境下用不了ls等命令:直接执行:
export PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin -
使用grep查找文件内容,定位问题:

5. 实验总结
我的心得是在不同架构下部署同一框架是困难的,不同指令集与体系架构都有不同的特性,这也是做对比实验的意义所在。
我的不足是对RISC-V环境下软件的部署与运行依然较陌生,比如交叉编译;以及时间管理有问题,导致功能测试只做了一小部分,也没有写自动化脚本。
TODO:以后学习shell自动化脚本编写,可参考https://gitee.com/LearningEulixOS/pages/tree/main/src/content/posts/2024-01