1. 背景
1.1. 接手老系统
最近我们又接手了一套老系统,老系统的迭代效率和稳定性较差,我们打算做重构改造,但重构周期较长,在改造完成之前还有大量的需求迭代。因此我们打算先从稳定性和迭代效率出发做一些微小的升级,其中一项效率提升便是升级编译工具 和 GCC 版本。 老系统使用 Autotools 编译工具链,而我们新服务通常采用 bazel,bazel 在构建速度、依赖描述、工具链等方面有很大优势。我们决定将老系统的编译工具迁移到 bazel,同时也从 GCC4 升级到 GCC8。
1.2. 升级 bazel 和 GCC8
老系统经过多年的迭代,其依赖关系有大量的冗余,经过数天的处理,最终我们梳理出干净准确的依赖关系图,并升级为 bazel + GCC8。其中部分迭代较少的老仓库,采用 bazel 的 configure_make 工具引入,迭代较多的仓库则直接用 bazel 改造。在完成老系统全链路服务的改造之后,我们发现其中一个服务出现了内存泄漏。
2. 内存泄漏现象
2.1. 发现内存泄漏
内存泄漏出现在一个名为 Xxx 的服务上,它负责做图片 CPU 特征计算并将结果写入 HBase,是一个多进程服务,一个进程通常使用 7G 左右的内存,而内存泄漏的时候,流量高峰期半小时可以涨到 20G+。
2.2. 定位到泄漏版本和临时规避措施
首先,我们调查近期修改的版本,发现是升级 bazel 和 GCC8 引入的,这次修改代码量较多。
但仔细分析代码,发现多半是一些 namespace、include 之类的编译错误修改,没有改动业务逻辑,从代码修改上看不出来有内存泄漏。然后,经过一系列的调查和尝试,我们发现使用 bazel 和 GCC4 不会有内存泄漏,因此我们临时将主干代码降级到 GCC4,优先解决线上问题。
3. 内存泄漏原因和避开方法
通过降级到 GCC4 解决了线上内存泄漏,但这不是治本的方法,我们通过层层深入,终于将问题分析清楚并在 GCC8 下解决,下面对结论做简要说明。
3.1. 这是 GCC8 O1~O3 编译优化的 BUG
通过 jemalloc、代码日志、GDB 等工具和手段,发现代码有异常抛出的某种场景下,编译器为异常堆栈展开代码做了不合适的性能优化,使得引用计数对象析构时,没有对计数减一,导致内存无法释放。 触发编译器 BUG 的示例代码:
/**
* @file bug_example.cc
* @brief GCC8 编译器优化导致内存泄漏的示例代码
* O1\O2\O3 都会触发 bug
* g++ bug_example.cc -O3 -g -std=c++17 -o bug_example.out
*
* 使用 5.x 版本的 jemalloc 验证:
* 1、编译:g++ bug_example.cc -O3 -g -std=c++17 -L./jemalloc/lib -ljemalloc -ldl -lpthread -o bug_example.out
* 2、运行:MALLOC_CONF=prof_leak:true,lg_prof_sample:0,prof_final:true ./bug_example.out
*/
#include <iostream>
#include <stdexcept>
#include <string>
#include <vector>
// 为方便介绍,简化掉侵入式智能指针的部分代码
// 引用计数
class Counted {
public:
virtual ~Counted() = default;
Counted* retain() {
++count_;
return this;
}
void release() {
if (--count_ == 0) {
count_ = 0xDEADF001; // 去掉这一行可以解决 GCC8 编译器优化 BUG
// 加一个日志打印,也可以解决 GCC8 编译器优化 BUG
// std::cerr << "delete Counted,this=" << this << std::endl;
delete this;
}
}
private:
unsigned int count_ = 0;
};
// 智能指针模板
template <typename T>
class Ref {
public:
explicit Ref(T* obj = nullptr) { reset(obj); }
Ref(const Ref<T>& other) { reset(other.object_); }
~Ref() {
if (object_ != nullptr) {
object_->release();
}
}
void reset(T* obj) {
if (obj != nullptr) {
obj->retain();
}
if (object_ != nullptr) {
object_->release();
}
object_ = obj;
}
private:
T* object_ = nullptr;
};
// 业务类型
class MyType : public Counted {
public:
MyType() {
for (int i = 0; i != 10000; ++i) {
something_.emplace_back(std::to_string(i));
}
std::cerr << __FUNCTION__ << std::endl;
}
~MyType() { std::cerr << __FUNCTION__ << std::endl; }
private:
std::vector<std::string> something_;
};
// 包了两层智能指针对象之后,在有异常时,会触发 GCC8 编译器 BUG
// 注:如果智能指针采用 const&,不会触发 BUG
void Exception_FuncWrapperLevel2(Ref<MyType> obj) { throw std::runtime_error("my exception..."); }
void Exception_FuncWrapperLevel1(Ref<MyType> obj) { Exception_FuncWrapperLevel2(obj); }
void RunWithExceptionUnwind() {
try {
Ref<MyType> obj(new MyType);
Exception_FuncWrapperLevel1(obj);
} catch (const std::exception& e) {
std::cerr << "catch exception=" << e.what() << std::endl;
}
}
// 正常调用,不会触发 BUG
void Normal_FuncWrapperLevel2(Ref<MyType> obj) {}
void Normal_FuncWrapperLevel1(Ref<MyType> obj) { Normal_FuncWrapperLevel2(obj); }
int RunNormal() {
try {
Ref<MyType> obj(new MyType);
Normal_FuncWrapperLevel1(obj);
} catch (const std::exception& e) {
std::cerr << e.what() << std::endl;
}
return 0;
}
int main() {
std::cerr << "----bug call----start" << std::endl;
RunWithExceptionUnwind();
std::cerr << "----normal call----start" << std::endl;
RunNormal();
}
/*
输出:
----bug call----start
MyType
catch exception=my exception...
----normal call----start
MyType
~MyType
*/错误编译优化后的汇编代码:
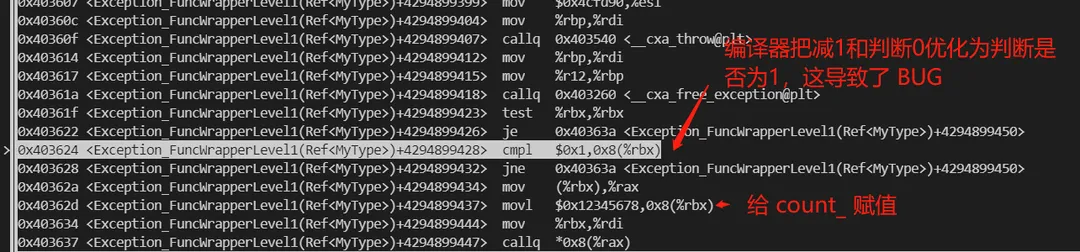
3.2. BUG 的避开方法
如示例代码注释所述,在引用计数的析构函数中加一行日志,或者去掉对 count_ 的赋值,或者使用 const& 传参,都可以阻止编译器优化。甚至可以将编译优化去掉,使用 O0 做编译,也能解决。
void release() {
if (--count_ == 0) {
count_ = 0xDEADF001; // 去掉这一行可以解决 GCC8 编译器优化 BUG
// 加一个日志打印,也可以解决 GCC8 编译器优化 BUG
// std::cerr << "delete Counted,this=" << this << std::endl;
delete this;
}
}3.3. 常见的编程指南也能帮助我们避开 BUG
如果我们遵循常见的编程指南,也能避开这个 BUG。具体包括以下常见代码实践:
- 减少对象的隐藏拷贝。在传递引用计数对象时,可以使用 const&,消除 Ref 对象的拷贝。
- 使用成熟的库,避免重造轮子。可以使用 std::enable_shared_from_this 和 std::shared_ptr 来代替自定义的侵入式智能指针。
- 慎重使用异常。异常有很多注意事项,譬如要和 RAII 配合,要考虑是否影响性能等,对开发者的能力有较高要求,因此很多项目都禁用异常。
3.4. 升级到 GCC 新版本
升级到 GCC9+ 的版本也可以解决该 BUG。
4.内存泄漏定位的经验分享
本章对内存泄漏定位过程做详细介绍,方便想复用调查经验或者想了解调查过程的同事。
4.1. 使用 jemalloc 定位问题函数
jemalloc 自带的内存分析工具功能强大,效率极高,推荐使用。
(1)源码编译 jemalloc,并开启 --enable-prof 编译选项。
WORKSPACE:
load("@bazel_tools//tools/build_defs/repo:http.bzl", "http_archive")
http_archive(
name = "rules_foreign_cc",
strip_prefix = "rules_foreign_cc-0.10.1",
url = "https://github.com/bazelbuild/rules_foreign_cc/archive/0.10.1.tar.gz",
)
load("@rules_foreign_cc//foreign_cc:repositories.bzl", "rules_foreign_cc_dependencies")
rules_foreign_cc_dependencies()
all_content = """filegroup(
name = "all",
srcs = glob(["**"]),
visibility = ["//visibility:public"]
)
"""
http_archive(
name = "jemalloc",
build_file_content = all_content,
strip_prefix = "jemalloc-5.3.0",
urls = ["https://github.com/jemalloc/jemalloc/archive/refs/tags/5.3.0.tar.gz"],
)BUILD:
configure_make(
name = "jemalloc",
autoconf = True,
autoconf_options = ["-i"],
configure_in_place = True,
configure_options = ["--enable-prof"],
lib_source = "@jemalloc//:all",
targets = ["-j12", "install"],
out_include_dir = "include",
out_lib_dir = "lib",
out_static_libs = [
"libjemalloc.a",
],
)注:编译产物还有 jeprof,可以用于分析内存分配情况,拷贝出来备用。
(2)Xxxx 使用自己编译的 jemalloc,并开启定期 dump 堆分配信息。
# 开启性能分析,并每新增 1G 内存 dump 内存分配信息
export MALLOC_CONF="prof:true,lg_prof_interval:30"
./Xxxx config.conf(3)对比两次堆分配信息,确认内存泄漏函数
首先,生成 pdf:
./jeprof --show_bytes --pdf a.out jeprof.1.0.f.heap > a.pdf
./jeprof --show_bytes --pdf a.out jeprof.2.0.f.heap > b.pdf然后,对比 a、b 两次内存分配图,可以看到在 Xxxx 类的 read_mem 函数里出现内存泄漏。
(涉及公司业务代码,pdf 对比图略)
结合 pdf 的提示,找到具体代码中的位置。
(涉及公司业务代码,代码具体位置截图略)
4.2. 模拟现场确认 BUG 的普遍性
(1)进一步查看源码,确认这是一个侵入式智能指针,即引用计数挂在业务类型上,类似使用 std::enable_shared_from_this。通过添加日志,确认在 decode() 函数里抛出异常后,引用计数出错。
(涉及公司业务代码,添加日志确认引用计数出错相关代码截图略)
(2)引用计数+两层函数调用+抛出异常模拟
见本文第三章的示例代码,通过该代码的模拟可以复现 BUG,确认该 BUG 具有普遍性。同时测试也显示,业务代码中加一行日志代码,可以修复该 BUG:

4.3. 使用 GDB 调试确认问题指令
为什么引用计数会出错,是析构函数没有调用,还是其他原因?GDB 定位到具体位置:

常用指令如下:
- 启动:gdb ./a.out
- 在析构函数代码附近打断点:break main.cc: 28
- 显示汇编指令:layout asm
- 单步执行汇编:si、ni
4.4. GCC 社区有类似的异常堆栈展开 BUG 反馈
optimized code does not call destructor while unwinding after exception
这个 BUG 在 函数带有 throw(int) 描述时,才会触发。实测显示:
- GCC4.8.5 无 BUG
- GCC8.3.1 有 BUG
- GCC12.2.0 无 BUG
但社区反馈的这个 BUG 和本文涉及的 BUG 也有很多不一样的点,仅有共同点:都和异常相关;在 GCC12.2.0 上都修复了。
5. 附录------走过的弯路
上面的调查过程看起来很流畅,因为这是我优化过的,中间简化了很多非必要的步骤,实际上调查过程很曲折。我们试过很多种方案,最终才产出上面提到的最佳调查路线,下面对走过的弯路做介绍,也许在你的场景下,弯路是直路。
(1)会是框架的内存池导致的吗?Xxxx 服务采用古老的 ACE 框架(ACE · GitHub),起初怀疑是使用了 ACE 的内存分配接口导致。阅读使用接口和 ACE 内存分配相关源码后,确认未使用内存池,其内存操作接口仅是 new\delete 的二次封装而已。
(2)会是 new 和 delete 没有配套使用导致的吗?Xxxx 服务的代码较为随意,且有浓郁的 C 语言风格,基本没用 C++ 类型的构造函数来管理内存。代码中,new 出来的 byte 数组有用 free 释放的,也有用 delete 释放的,通过 demo 代码实测,new/delete/malloc/free 等内存申请和释放函数在操作 byte 数组内存时,混用不会导致内存泄漏。
(3)会是进程没有及时归还给操作系统导致的吗?去年在搜索内容架构重构项目(见文章:微服务回归单体,代码行数减少75%,性能提升1300%)中,我们遇到了回收的内存未及时归还操作系统的案例。而在本项目中,尝试使用 mallo_trim 或者 jemalloc,内存上涨速度放缓,但最终还是会内存泄漏。
(4)会是 jemalloc 没有归还导致的吗?前年我们在开发搜索中台时,曾经遇到过使用 jemalloc 的服务内存释放不及时问题。在引入 backgroud_thread,或者修改内存回收系数 page ratio,或者调整 arenas 个数,都没有效果。仔细观察也会发现 active 的页面数一直在涨,说明程序代码在申请内存之后,确实没有释放。
注1:page ratio 系数说明:我们系统自带的 jemalloc 版本为 3.6.0,采用的是较老的内存回收设计,默认 active: dirty < 8:1 时会触发内存归还操作系统。
注2:arenas 个数说明:默认会开启 4 * CPU核心数个 arenas,如果只有一个 CPU 则只会有一个 arenas。一个线程只会映射到一个 arena
(5)会是代码有 BUG 吗?
Xxxx 服务的代码 C 语言风格较浓,大部分代码没有使用 RAII 来降低内存管理负担,并且内存申请和释放较难一眼看明白:内存申请在 A 类里,内存释放在很远的 B 类上,在这上面做迭代开发,心智负担较重,稍微不注意就会出现内存泄漏。我们用 ASan 扫内存泄漏,确实发现一些极少跑到的分支没有释放内存,但这些分支 BUG 修复之后,依然存在内存泄漏。
注:本文 2024.06.26 首发在公司内网,为方便全网知识检索发布到外网,发布时部分业务相关代码和截图做了隐藏处理。