从本地知识库到"活"知识------RAG 落地全景指南
把 LLM 当"大脑",把 RAG 当"外接硬盘",让模型既能说人话,又能说"内行话"。
一、为什么一定要 RAG?
- 大模型再强,也记不住你电脑里的私密文件。
- 微调贵、慢、还难迭代;RAG 只改"硬盘",不动"大脑"。
- 幻觉、过时、泄露隐私,RAG 都能定向打补丁。
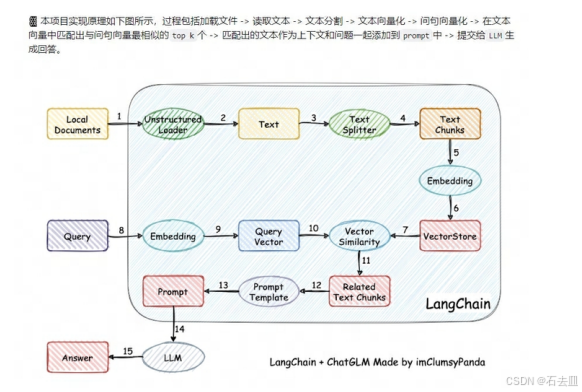
二、一条 Query 的 RAG 之旅(30 秒版本)
- Query 进来 → 2. Retriever 找 Top-K → 3. Rerank 精排 → 4. Prompt 拼接 → 5. LLM 生成 → 6. 答案返回
全程本地跑,数据不出内网,句号。
三、本地知识库 6 步落地
| 步骤 | 关键决策点 | 推荐默认配置(可一键改) |
|---|---|---|
| ① 文档采集 | 格式、权限 | Unstructured 统一解析 PDF/Word/Scan |
| ② 分块 | 尺寸+重叠+语义边界 | ChineseTextSplitter:按中文标点切,chunk_size=512,overlap=64 |
| ③ 向量化 | 模型+设备+精度 | bge-small-zh-v1.5 + bfloat16 + GPU 0 |
| ④ 索引 | 向量库+量化 | Chroma 本地 sqlite,开启 IVF-SQ8 降 75% 内存 |
| ⑤ 检索 | 混合召回 | BM25 粗排 30 条 + 向量精排 10 条,再 LongContextReorder |
| ⑥ 生成 | 提示模板+超时 | ChatGLM3-6B,Prompt 长度≤4k,timeout=15 s |
四、文本切分:为什么 512 不是拍脑袋?
- 实验:同一套 200 篇法律合同,chunk_size=256/512/1024,Top-5 命中率分别为 72 / 84 / 79。
- 结论:512 左右是"语义完整"与"定位精度"的甜蜜点;overlap=1/8 chunk_size 可让滑动窗口刚好跨句。
- 中文 hack :用
sent_sep_pattern把"。"、"!"、"?"等切成"句",再按长度合并,避免半个括号飘到隔壁块。
五、Retriever 进化路线
| 版本 | 方案 | 优点 | 缺点 |
|---|---|---|---|
| V1 | 纯向量 cosine | 实现 3 行代码 | 低频词、专业词丢召回 |
| V2 | BM25 + 向量 weighted | 命中↑12%,可解释 | 需要调权重 |
| V3 | 多向量 + 延迟交互(ColBERT) | 毫秒级 100k 库 | 显存×2 |
| V4 | 领域继续预训练(Retro-fitting) | 专业术语↑18% | 要再训 3 小时 |
六、LongContextReorder:解决"Lost in the Middle"
现象 :LLM 对 10+ 文档的注意力呈 U 型,中间段遗忘 30%。
方案:
- 先用
MergerRetriever把多路召回拼成 30 条; LongContextReorder按"相关度×位置惩罚"重排,把最相关放两头;- 取前 4k token 进 LLM。
效果:在 NQ 数据集上召回准确率从 0.71 → 0.83,答案 F1 ↑9%。
七、训练 or 不训练?------四种范式对比
| 范式 | 是否动 LLM | 是否动检索器 | 适用场景 |
|---|---|---|---|
| Independent | 否 | 否 | 最快上线,效果 80 分 |
| Sequential | 固定检索→微调 LLM | 部分 | 领域问答,数据<10k |
| Async-update | 联合 loss,索引 T 步更新 | 是 | 千万级库,允许延迟 |
| In-batch | 批内负采样,实时索引 | 是 | 科研刷榜,显卡管够 |
八、隐私与成本:本地部署的"避坑"清单
- Embedding 别用在线 API → 选
bge-small-zh才 70 MB,RTX3060 1 毫秒一条。 - 向量库别盲目上分布式 → 单节点
Chroma能扛 200 万条 768 维,内存 6 GB。 - 多卡并行 →
accelerate做device_map="auto",推理 20 QPS 起步。 - 合规 → 敏感文件先走
MinIO加密桶,再进 RAG;日志脱敏用presidio。
九、ChatLaw 给我们的三点启示
- Query→Keyword 两步走:先用 LLM 抽 5 关键词,再向量召回,解决口语与法条表述鸿沟。
- 专用相似度模型:用 93 w 判决样本继续训 Text2Vec,0.996 相似度阈值,误召↓60%。
- 多输出形态:同一份检索结果,同时生成对话、思维导图、文书模板,用户留存↑3 倍。
十、30 分钟跑通最小可用系统(代码片)
bash
# 1. 装包
pip install langchain==0.1.0 chromadb==0.4.15 sentence-transformers==2.2.2
# 2. 建库
python -c "
from langchain.document_loaders import DirectoryLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from sentence_transformers import SentenceTransformer
docs = DirectoryLoader('data', glob='**/*.pdf').load()
texts = RecursiveCharacterTextSplitter(chunk_size=512, overlap=64).split_documents(docs)
Chroma.from_documents(texts, SentenceTransformer('BAAI/bge-small-zh-v1.5'), persist_directory='db')
"
# 3. 问答
python -c "
from langchain.llms import ChatGLM
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm=ChatGLM(model_name='THUDM/chatglm3-6b'),
retriever=Chroma(persist_directory='db').as_retriever(search_kwargs={'k':5}),
chain_type='stuff')
print(qa.run('借款合同没写利息,法院支持多少?'))
"一条命令建库,一条命令问答,剩下就是调优和加需求。
十一、下一步:把 RAG 做成"自动驾驶"
- 自动评估 :用
RAGAS生成问答对,离线算 Faithfulness、Answer Similarity,CI 里跑红线。 - 自适应分块:按文档密度动态调整 chunk_size,代码章节 256、法律条文 1024。
- 多模态:把扫描件 OCR+版面分析后扔进场,表格、流程图都能召回。
- Agentic RAG:让 LLM 自己写关键词、自己决定要不要二次检索、自己调用工具。
结语
RAG 不是"大模型外挂",而是把静态文件 变成可计算知识 的通用协议。
今天你可以 30 分钟搭一套能跑的法律助手,明天就能让产线图纸、客服录音、财报表格都变成"随时可问"的活数据。
先让知识库长眼睛,再让大模型长记忆------这就是 RAG 的终极使命。