并发控制
并发控制的重要性
并发控制是数据库管理系统中的一个核心概念,它确保在多用户环境中,对数据库的并发访问不会破坏数据的完整性和一致性。
当多个用户同时对数据库进行读写操作时,如果缺乏有效的并发控制机制,可能会导致数据更新的竞态条件,从而引发数据不一致的问题。例如,如果两个事务同时增加同一账户的余额,而没有适当的锁定机制,可能会导致余额被错误地增加多次或一次都未增加。
因此,通过并发控制,数据库能够安全地处理多个事务,保证数据的准确性和可靠性。
并发控制与ACID原则
ACID原则是数据库事务的四个基本属性:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。并发控制直接关联到这些属性的实现:
-
原子性:确保事务中的所有操作要么全部完成,要么全部不完成,通过并发控制可以避免事务的部分执行对数据库状态的影响。
-
一致性:保证事务执行的结果必须使数据库从一个一致的状态转移到另一个一致的状态,通过并发控制防止了违反业务规则的事务提交。
-
隔离性:确保并发执行的事务之间不会互相影响,每个事务都像在独立运行一样,通过锁机制和MVCC等并发控制技术实现。
-
持久性:一旦事务提交,它对数据库的改变就是永久性的,即使系统发生故障也不会丢失,通过并发控制确保在事务提交前数据已经正确写入数据库。
串行化与并行执行的权衡
串行化是最高的事务隔离级别,它通过序列化所有的事务,确保它们一个接一个地执行,从而避免了并发执行可能引起的问题。然而,串行化虽然能够提供最严格的隔离性,但会大大降低系统的并发能力,导致性能瓶颈。
与此相对的是并行执行,它允许多个事务同时执行,从而提高数据库的吞吐量和响应速度。但是,如果并行执行没有得到适当的控制,可能会导致数据异常,如脏读、不可重复读和幻读。
因此,数据库系统需要在串行化和并行执行之间找到平衡点。这通常通过使用不同的隔离级别和并发控制技术来实现,例如:
-
使用锁机制来控制对数据的访问,确保事务在修改数据时不会相互干扰。
-
采用MVCC等技术,允许读取操作不受写入操作的影响,同时保持数据的一致性视图。
通过这些技术,数据库可以在保证ACID属性的同时,提供较高的并发性能,满足现代应用对高并发处理能力的需求。
事务隔离级别
上面提到的知识点已经是开发人员在备考面试时几乎都会掌握的基本内容。接下来,我将通过实际操作金仓数据库来回顾这些知识点。在这里,我会总结另一个事务隔离级别,并讨论在不同隔离级别下可能出现的脏读、不可重复读和幻读现象。这样可以更深入地理解它们对数据库操作的影响。
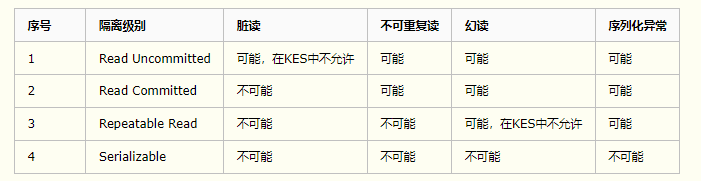
特别需要强调的是,在KES数据库中,Read Uncommitted隔离级别下不允许出现脏读现象,而Repeatable Read隔离级别则会防止幻读的发生。既然这些情况已经被明确提出,我们有必要实际实施一下,以验证这些说法是否属实。
首先看下默认的事务级别:

有三种可以修改事务级别的方式。第一种是直接修改配置文件;第二种是在当前会话中修改隔离级别;第三种是在当前事务中修改隔离级别。为了演示方便,我们选择使用第三种方式。那么,我们可以开始了。
脏读(Dirty Read)
脏读指的是一个事务读取了另一个事务尚未提交的数据更改的现象。在KES数据库中,默认的隔离级别通常为已提交读,因此通常不会发生脏读。然而,为了演示脏读的情况,我们可以假设将隔离级别设置为读未提交(Read Uncommitted)。这样一来,一个事务可以读取到另一个事务尚未提交的数据变更,导致可能出现不一致的读取结果。

当然,我们的KES数据库目前并不支持这种操作,但这个想法确实很有前途。我们可以尝试一下。首先,我们可以同时启动这两个事务。
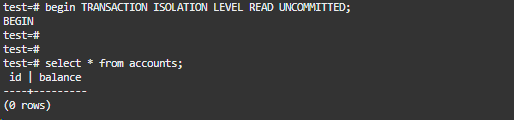
事务1和2都操作:
begin TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
当事务1尝试查看数据时,并未发现任何相关记录。
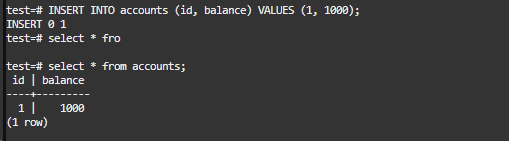
事务2插入一条数据:
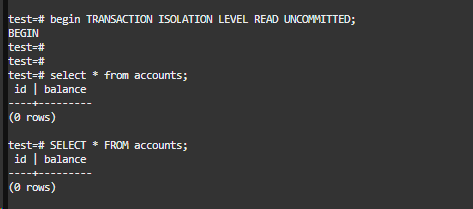
事务1查询一下,还是没有,发现KES确实不存在脏读的情况:
不可重复读
它发生在一个事务读取了某个数据项,然后在同一事务中再次尝试读取同一数据项时,如果另一个并发事务已经更新了这个数据项,那么第一个事务将读取到不同的值。
在不可重复读的情况下,一个事务的读取操作可能会得到不同的结果,即使这些读取是在同一个事务的上下文中执行的。这违背了事务的隔离性原则,因为事务应该与其他并发事务的操作隔离开来。

事务1
-
开始事务,并读取某个数据项。
-
再次尝试读取同一数据项。
-- 事务1开始
begin TRANSACTION ISOLATION LEVEL READ committed;-- 读取账户的初始余额
SELECT balance FROM accounts WHERE id = 1;-- ... 事务1尚未提交 ...
-- 再次读取账户余额,期望得到相同的结果
SELECT balance FROM accounts WHERE id = 1;
效果如下:
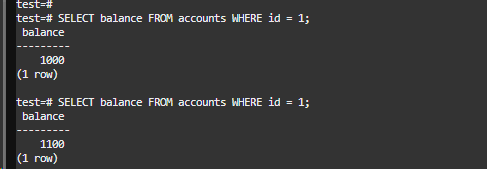
事务2
-
开始另一个事务,并更新相同的数据项。
-
提交事务。
-- 事务2开始
begin TRANSACTION ISOLATION LEVEL READ committed;-- 更新账户余额
UPDATE accounts SET balance = balance + 100 WHERE id = 1;-- 提交事务2的更改
COMMIT;
效果如下:
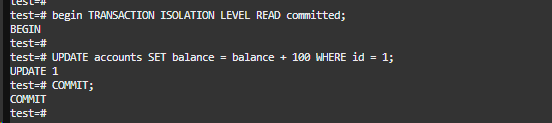
幻读
幻读发生在一个事务在读取某个范围内的记录时,另一个事务插入了新的记录,导致第一个事务重新读取时,似乎出现了"幻影"记录。

SQL示例
-- 事务1:选择某个范围内的记录
begin transaction isolation level repeatable read ;
SELECT * FROM accounts WHERE id BETWEEN 1 AND 5;
-- 事务2:插入新的记录
begin transaction isolation level repeatable read ;
INSERT INTO accounts (id, balance) VALUES (2, 1000);
COMMIT;
-- 事务1再次选择,可能会看到新插入的记录(幻读)
SELECT * FROM accounts WHERE id BETWEEN 1 AND 6;
COMMIT;当我们讨论这个逻辑时,我们可以进行演示,因为官方KES文档表明,在可重复读隔离级别下,正常情况下不会出现幻读。这意味着我们可以验证这一点。
插入演示-事务一
可以看到,在我们提交事务之前,无法看到已插入的记录。因此,这次验证表明,在KES中,即使在可重复读隔离级别下,也已经成功地消除了幻读现象。
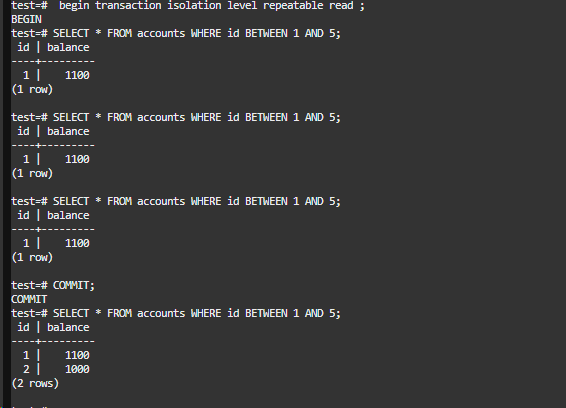
插入演示-事务二
事务二的操作非常简单,仅仅是在可重复读隔离级别下创建了一条数据并成功提交了事务。
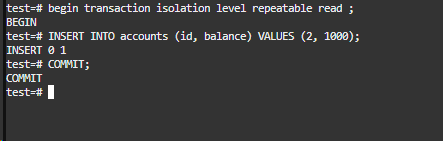
当然,让我们进一步演示删除操作,以确认在此操作中是否也能有效避免幻读现象。
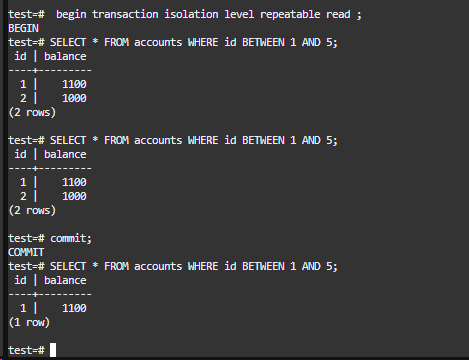
删除演示-事务一
这里我们同样进行了演示,直接将隔离级别设置为可重复读,并执行了查询,但没有提交事务。我们观察到在操作过程中没有出现任何变化,成功地避免了幻读现象。
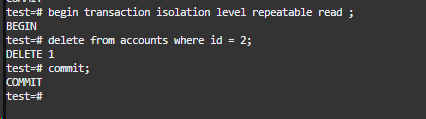
删除演示-事务二
开启后隔离级别后,执行了一个删除操作,并将其提交给数据库。
总结
本文深入探讨了KES数据库中的并发控制机制和事务隔离级别的重要性及实施方法。我们从并发控制的基本概念出发,详细解释了ACID原则如何通过不同的隔离级别得以实现,以及在串行化与并行执行之间的权衡取舍。通过实际操作和示例,我们展示了不同隔离级别下可能出现的脏读、不可重复读和幻读现象,以及KES数据库是如何应对这些问题的。
随着现代应用对高并发处理能力需求的增加,正确理解并实施良好的并发控制策略变得尤为重要。通过本文的学习,读者可以更好地理解如何通过合适的隔离级别和并发控制技术来平衡数据的一致性和性能需求,从而确保数据库操作的准确性和可靠性。
在接下来的实际操作中,我们将继续探索不同隔离级别的实际影响,验证理论知识的应用,并进一步完善对数据库管理与优化的理解。
文章转载自: ++努力的小雨++