目录
- [196. 删除重复的电子邮箱](#196. 删除重复的电子邮箱)
- [73. 矩阵置零](#73. 矩阵置零)
- [105. 从前序与中序遍历序列构造二叉树](#105. 从前序与中序遍历序列构造二叉树)
196. 删除重复的电子邮箱
题目链接
表
- 表
Person的字段为id和email。
要求
编写解决方案 删除 所有重复的电子邮件,只保留一个具有最小 id 的唯一电子邮件。
(对于 SQL 用户,请注意你应该编写一个 DELETE 语句而不是 SELECT 语句。)
(对于 Pandas 用户,请注意你应该直接修改 Person 表。)
运行脚本后,显示的答案是 Person 表。驱动程序将首先编译并运行您的代码片段,然后再显示 Person 表。Person 表的最终顺序 无关紧要 。
知识点
delete:删除数据。形式上类似于select。
思路
保留一个具有最小 id 的唯一电子邮件意味着删除所有 比最小 id 的电子邮件的 id 大 且 与其 email 相同 的电子邮件,所以可以使用多表"查询",首先得限制两个表的 email 相同,然后删除 id 大的那些数据即可。
代码
sql
delete
p_big
from
Person p_big,
Person p_small
where
p_big.email = p_small.email
and
p_big.id > p_small.id73. 矩阵置零
题目链接
标签
数组 哈希表 矩阵
简单版
思路
如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。这意味着只需要用两个数组,分别存储这行和这列是否有0 ,如果这行有0 ,则将这行元素置零;如果这列有0,则将这列元素置零。
代码
java
class Solution {
public void setZeroes(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
boolean[] isRow0 = new boolean[m];
boolean[] isCol0 = new boolean[n];
// 检查每一行和每一列是否有为0的数字
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (matrix[i][j] == 0) {
isRow0[i] = true;
isCol0[j] = true;
}
}
}
// 置零
for (int i = 0; i < m; i++) {
if (isRow0[i]) {
for (int j = 0; j < n; j++) {
matrix[i][j] = 0;
}
}
}
for (int j = 0; j < n; j++) {
if (isCol0[j]) {
for (int i = 0; i < m; i++) {
matrix[i][j] = 0;
}
}
}
}
}优化版
思路
可以将统计每行每列是否有0的数组放到原矩阵中,这里使用每行的第一个元素(列首)和每列的第一个元素(行首)来统计当前行是否有0 和当前列是否有0 ,如果有0 ,则列首或行首置为0 。然后对"整个"(从第二行到最后一行,从第二列到最后一列的)矩阵进行扫描,如果这行第一个元素或这列第一个元素是0,则将该元素置零。
那么问题就来了,既然在此处修改了第一行和第一列,那么该如何判断原始的第一行和第一列是否需要置零呢?使用两个变量提前对第一行和第一列进行判断即可。在 对"整个"(从第二行到最后一行,从第二列到最后一列的)矩阵进行扫描 完毕后,对第一行和第一列进行操作,如果原先第一行有0 ,则将第一行置零;如果原先第一列有0,则将第一列置零。
注意:这样做不会破坏原矩阵(或者说不影响结果),因为如果某行(或某列)有0,那么这行(或这列)的所有元素都需要被置零。
代码
java
class Solution {
public void setZeroes(int[][] matrix) {
int m = matrix.length, n = matrix[0].length;
boolean isFirstRow0 = false, isFirstCol0 = false;
// 检查第一列是否有为0的数字
for (int i = 0; i < m; i++) {
if (matrix[i][0] == 0) {
isFirstCol0 = true;
break;
}
}
// 检查第一行是否有为0的数字
for (int i = 0; i < n; i++) {
if (matrix[0][i] == 0) {
isFirstRow0 = true;
break;
}
}
// 检查 第二行到最后一行 第二列到最后一列 是否有为0的数字
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (matrix[i][j] == 0) { // 如果有重复数字
matrix[i][0] = matrix[0][j] = 0; // 则将本矩阵的 行首 和 列首 记为0
}
}
}
// 将 第二行到最后一行 第二列到最后一列 的元素置零
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (matrix[i][0] == 0 || matrix[0][j] == 0) { // 如果 本行首 或 本列首 被置零
matrix[i][j] = 0; // 则将该元素置为0
}
}
}
// 如果原先矩阵的第一行有0,则将第一行置零
if (isFirstRow0) {
for (int j = 0; j < n; j++) {
matrix[0][j] = 0;
}
}
// 如果原先矩阵的第一列有0,则将第一行置零
if (isFirstCol0) {
for (int i = 0; i < m; i++) {
matrix[i][0] = 0;
}
}
}
}105. 从前序与中序遍历序列构造二叉树
题目链接
标签
树 数组 哈希表 分治 二叉树
思路
注意:如果遍历的结果中有相同的元素,则无法构造二叉树,所以本题中的遍历结果都是无重复值的。
先来思考一下只有中序遍历应该如何构造二叉树?众所周知,中序遍历是先遍历左子树、再处理本节点、最后遍历右子树,所以说在中序遍历的结果中,中间元素是父节点(前提是它左子树的节点数等于右子树的节点数),中间元素的左子区间为它的左子树,中间元素的右子区间为它的右子树。
根据中间节点把整个遍历结果拆分为两个子区间,这两个子区间也有这样的性质:子区间的中间元素是父节点(前提是它左子树的节点数等于右子树的节点数),中间元素的左子区间为它的左子树,右子区间为它的右子树。
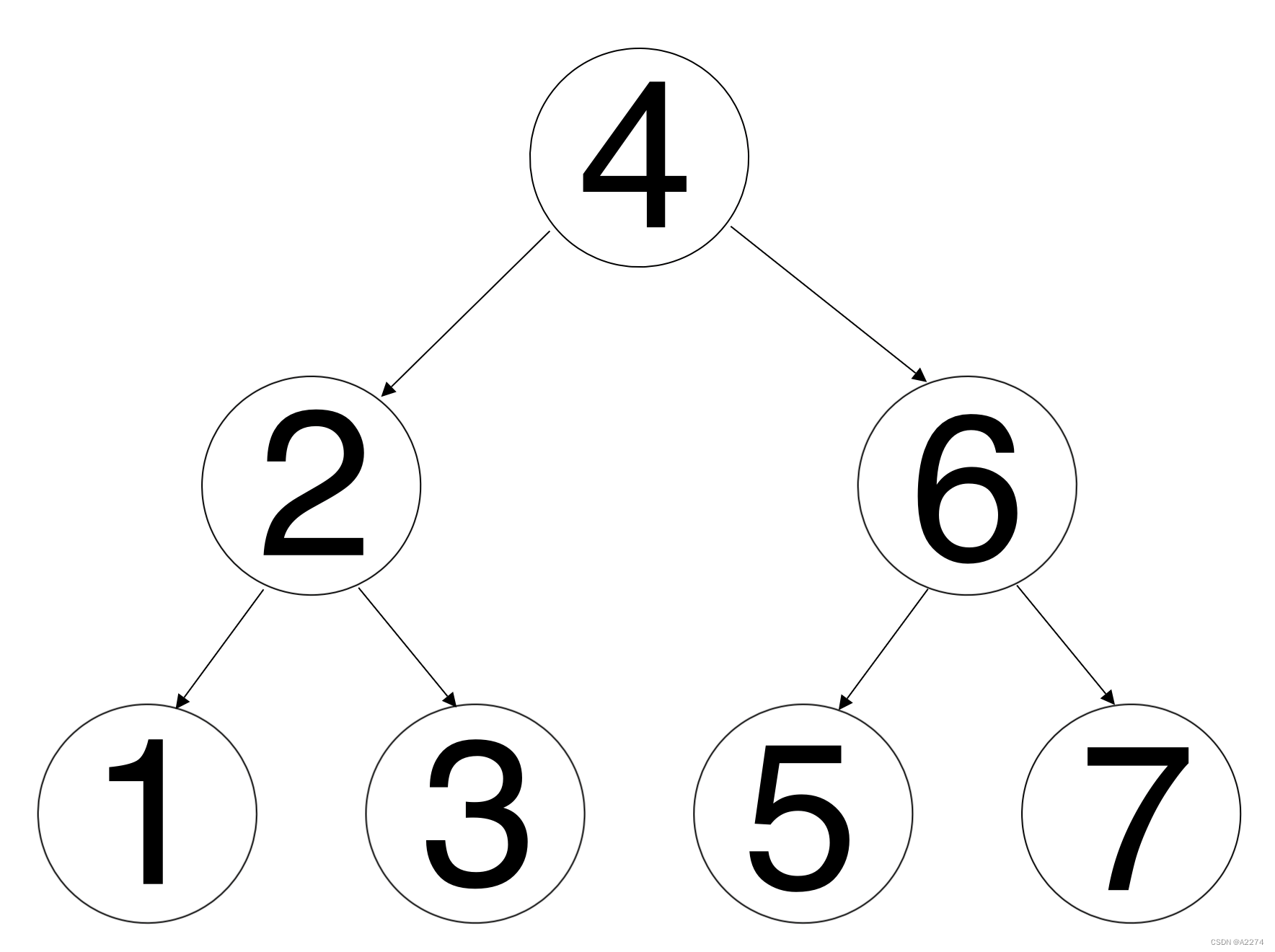
例如底下的二叉树,它的中序遍历结果为[1, 2, 3, 4, 5, 6, 7],第一个父节点(根节点)为4,然后分出[1, 2, 3]和[5, 6, 7]这两个子区间。在[1, 2, 3]中找到父节点2,在[5, 6, 7]中找到父节点6,接着将区间分为长度为1的子区间。此时直接将这个值作为叶子节点(没有子节点的节点)即可。
既然只需要知道中序遍历就能够构造二叉树,那为什么还要前序遍历的结果?这是因为存在一种二叉树,这种二叉树有些节点只有一个子节点,就不能确定哪个节点是父节点。
比如底下的二叉树,它的中序遍历结果为[2, 3, 4, 5, 6, 7],此时就不能轻易地将4作为第一个父节点了,因为4的左右子树的节点数不相等。所以只知道中序遍历的结果是无法构造二叉树的,因为无法确定父节点。
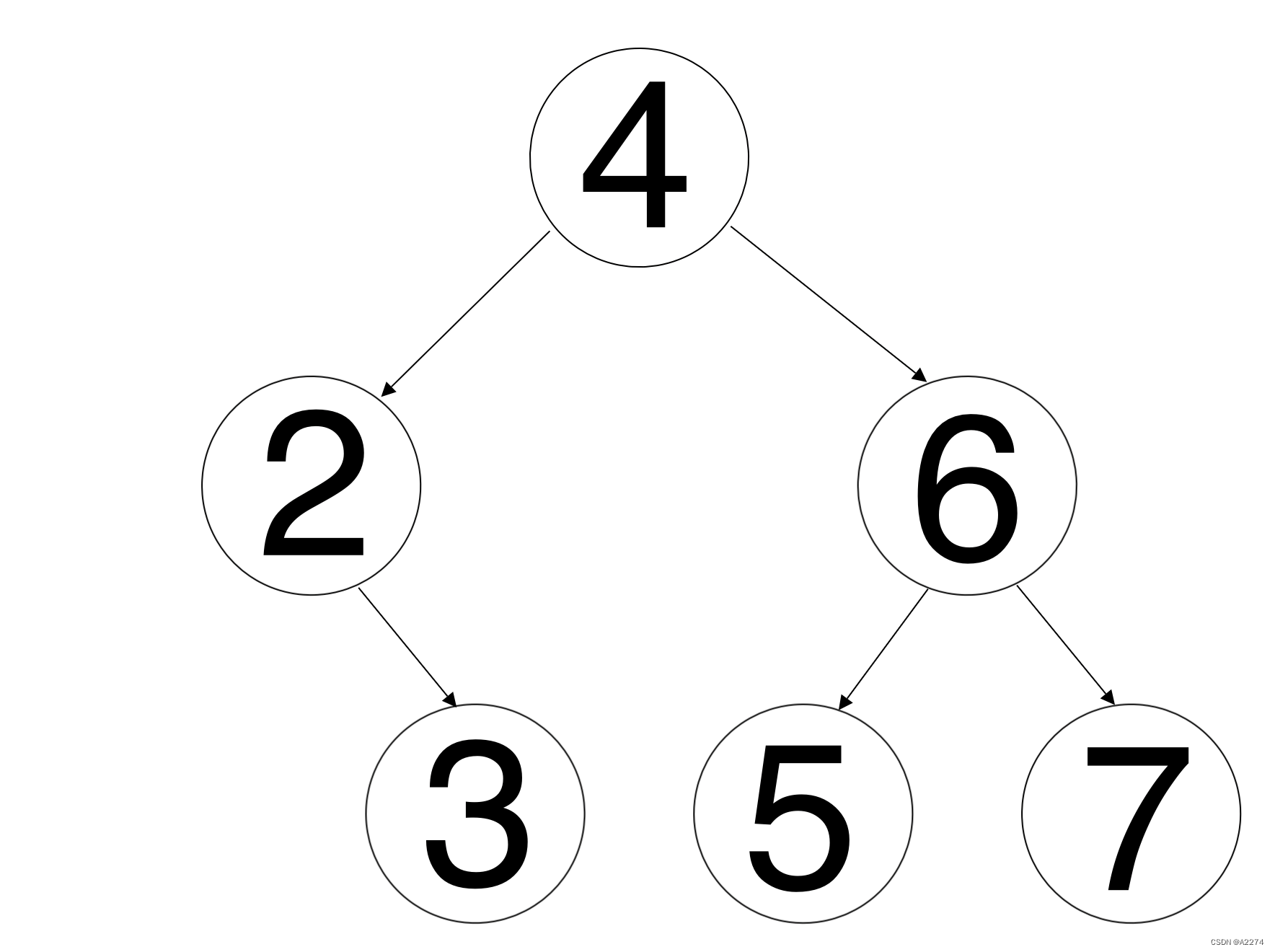
在前序遍历的结果[4, 2, 3, 6, 5, 7]中,第一个元素4就是第一个父节点,然后在中序遍历的结果[2, 3, 4, 5, 6, 7]中寻找父节点,并划分左子树[2, 3]和右子树[5, 6, 7]。
发现左子树含有的元素[2, 3] 和 前序遍历结果[4, 2, 3, 6, 5, 7]去掉父节点4后截取前2个元素(2是左子树的长度)的结果[2, 3]含有的元素 恰好相同,右子树含有的元素[5, 6, 7] 和 前序遍历结果[4, 2, 3, 6, 5, 7]去掉父节点4后截取后3个元素(3是右子树的长度)的结果[6, 5, 7]含有的元素 恰好相同。
所以构造二叉树的策略就确定了:将前序遍历区间内第一个值作为二叉树的父节点,在中序遍历的结果中寻找这个值,然后将这个值左边的区间定义为左子树,右边的区间定义为右子树,接着将前序遍历的结果也进行划分,去除第一个元素后,将前n(n是中序遍历划分的左子树的长度)个元素作为左子树,将后m(m是中序遍历划分的右子树的长度)个元素作为右子树。划分完这两个数组后,分别构造左子树和右子树。
代码
java
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
if (preorder.length == 0) { // 如果preorder的长度为0
return null; // 则退出递归
}
int parentValue = preorder[0]; // 记录父节点的值
TreeNode parent = new TreeNode(parentValue); // 以preorder的第一个值作为父节点
for (int i = 0; i < preorder.length; i++) {
if (inorder[i] == parentValue) { // 如果在inorder中找到父节点
int[] preLeft = Arrays.copyOfRange(preorder, 1, i + 1); // 截取preorder的左子树区间
int[] preRight = Arrays.copyOfRange(preorder, i + 1, inorder.length); // 截取preorder的右子树区间
int[] inLeft = Arrays.copyOfRange(inorder, 0, i); // 截取inorder的左子树区间
int[] inRight = Arrays.copyOfRange(inorder, i + 1, inorder.length); // 截取inorder的右子树区间
parent.left = buildTree(preLeft, inLeft); // 构造左子树
parent.right = buildTree(preRight, inRight); // 构造右子树
break;
}
}
return parent; // 返回本轮递归的父节点
}
}