文章目录
现象
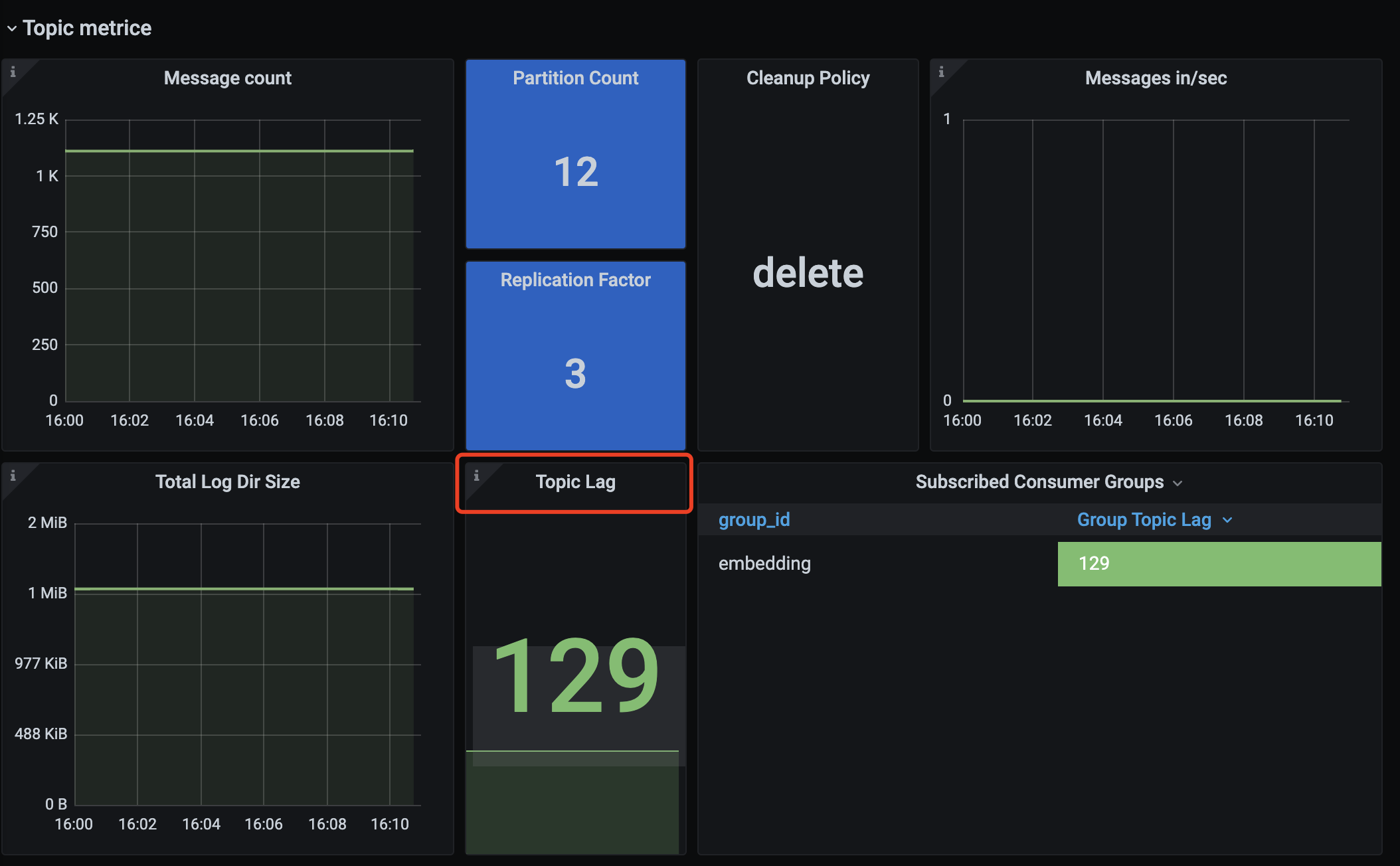
用户反馈消费者出现消息积压,并且通过日志看,一直重复消费,且没有报错日志。
业务背景
- 用户的消费者是一个将文件做Embedding的任务,(由于AI技术的兴起,大量文档需要做RAG);
- Embedding是一个比较耗时的过程,如果文件大,耗时会更长;
- 消费者使用的是push模式、手动提交offset的方式;
- 由于耗时比较长,将提交offset的超时时间改成了2小时;
- 服务运行一段时间,QPS不高(个位数),压力不大。
排查过程
- 从监控中看,消费者有了100多条积压,并且持续了很长时间;
- 从业务上,有一个用户同一时间上传了大量大文件;
- 只有一个消费者,服务端瞬间产生大量消息,同一时间推送给了消费者;
- 消费者处理Embedding任务超过两小时,导致这一批消息提交offset超时;
- 服务端认为客户端处理消息失败,一直进行重新推送,所以造成了没报错,但是一直重复消费的情况。
Push与Pull
MQ的消费模式可以大致分为两种,一种是推Push,一种是拉Pull。
- Push是服务端主动推送消息给客户端,优点是及时性较好,但如果客户端没有做好流控,一旦服务端推送大量消息到客户端时,就会导致客户端消息堆积甚至崩溃。
- Pull是客户端需要主动到服务端取数据,优点是客户端可以依据自己的消费能力进行消费,但拉取的频率也需要用户自己控制,拉取频繁容易造成服务端和客户端的压力,拉取间隔长又容易造成消费不及时。