目录
[1. 使用Hive创建数据库test](#1. 使用Hive创建数据库test)
[2. 检索数据库(模糊查看),检索形如'te*'的数据库](#2. 检索数据库(模糊查看),检索形如’te*’的数据库)
[3. 查看数据库test详情](#3. 查看数据库test详情)
[4. 删除数据库test](#4. 删除数据库test)
[5. 创建一个学生数据库Stus,在其中创建一个内部表Student,表格包含两列:学号(字符型),姓名(字符型)](#5. 创建一个学生数据库Stus,在其中创建一个内部表Student,表格包含两列:学号(字符型),姓名(字符型))
[6. 修改表student表结构,添加新的一列:年龄,整数型](#6. 修改表student表结构,添加新的一列:年龄,整数型)
[7. 创建一个表格名为employees,列名和数据类型根据常用习惯系定义,其表结构能载入如下格式的数据,并映射为表结构对应的字段。](#7. 创建一个表格名为employees,列名和数据类型根据常用习惯系定义,其表结构能载入如下格式的数据,并映射为表结构对应的字段。)
[1. 统计每个uid的查询次数](#1. 统计每个uid的查询次数)
[2. 搜索关键字内容包含'仙剑'超过三次的用户id](#2. 搜索关键字内容包含‘仙剑’超过三次的用户id)
[3. 统计不重复的uid的行数](#3. 统计不重复的uid的行数)
一、Hive的基本操作
1. 使用Hive创建数据库test
sql
create database test;
show databases; //查看数据库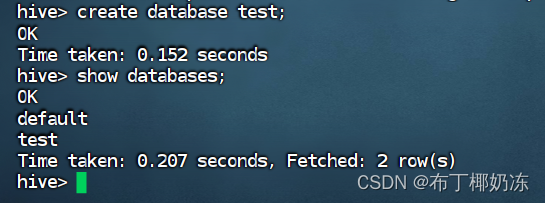
2. 检索数据库(模糊查看),检索形如'te*'的数据库
sql
show database like 'te*';3. 查看数据库test详情
sql
describe database test;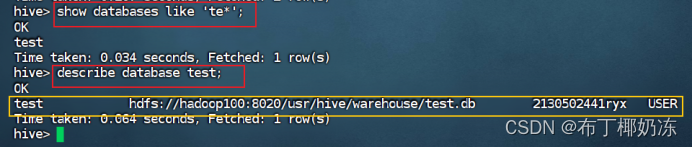
4. 删除数据库test
sql
drop database test;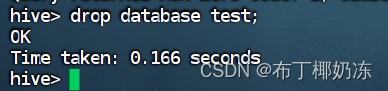
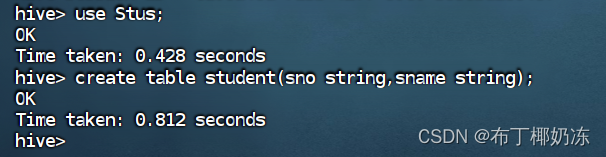
5. 创建一个学生数据库Stus,在其中创建一个内部表Student,表格包含两列:学号(字符型),姓名(字符型)
sql
create database Stus;
use Stus;
create table student(
sno string,
sname string
);
6. 修改表student表结构,添加新的一列:年龄,整数型
sql
alter table student add column(sage int);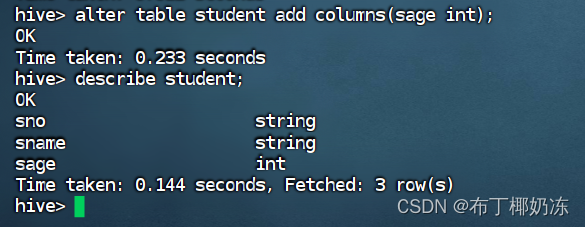
7. 创建一个表格名为employees,列名和数据类型根据常用习惯系定义,其表结构能载入如下格式的数据,并映射为表结构对应的字段。
1,hengdian,1000.0,13872787890,Zhejiang
2,hengqin,1234.0,18739292798,Guangdong
3,baishui,8797.0,13490980090,Hunan
写出创建表格的语句,并使用load语句将上述数据内容载入表结构,该数据以文本文件的形式存放在本地文件系统,请自行用vi编辑器编辑。
data.txt

创建表的语法:
sql
create table employees(
eno string,
ename string,
esal float,
phone string,
address string )
row format delimited
fields terminated by ',' ;
sql
descripe employees;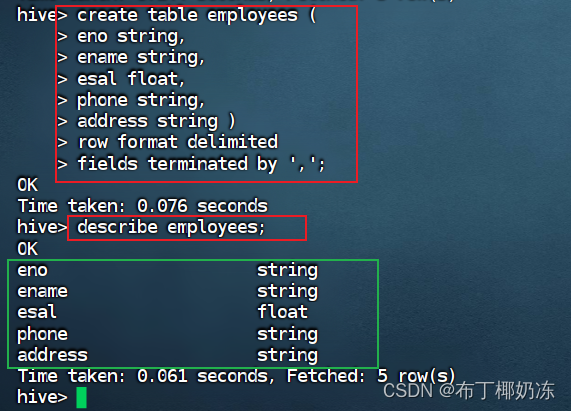
导入本地数据语法:
sql
load data local inpath '/home/gdpu/data.txt' into table employees;
sql
select * from employees; 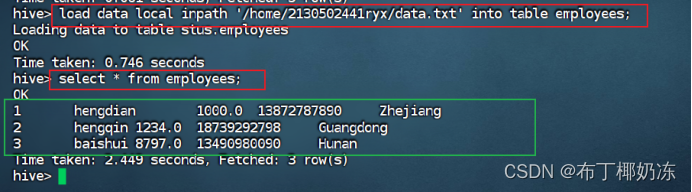
二、Sogou日志数据分析
请完成创建外部表格并关联sogou的500w数据,使用HiveQL完成下列数据分析。写出Hive语句和执行结果。
sql
create table sogou2024 (
times string,
uid string,
keyword string,
ranks int,
orders int,
URL string )
row format delimited
fields terminated by '\t';
sql
load data inpath 'hdfs://hadoop100:8020/sogou.500w.utf8' into table sogou2024;
sql
select * from sogou2024 limit 10; //验证是否导入成功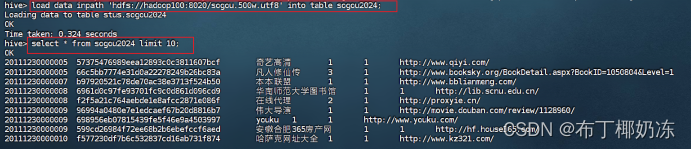
1. 统计每个uid的查询次数
sql
select uid, count(*) as cnt from sogou2024 group by uid;
下面的截图是执行结果的最后一部分,结果有135万多行。

2. 搜索关键字内容包含'仙剑'超过三次的用户id
sql
select uid
from sogou2024
where keyword like'%仙剑%'group by uid
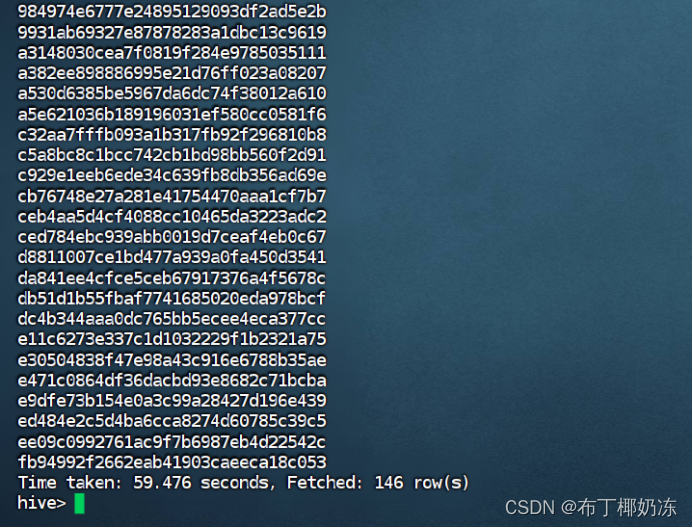
having count(*) > 3 ;
运行截图 :
3. 统计不重复的uid的行数
sql
select count(distinct uid) as unique_uid_count
from sogou2024;
运行截图:

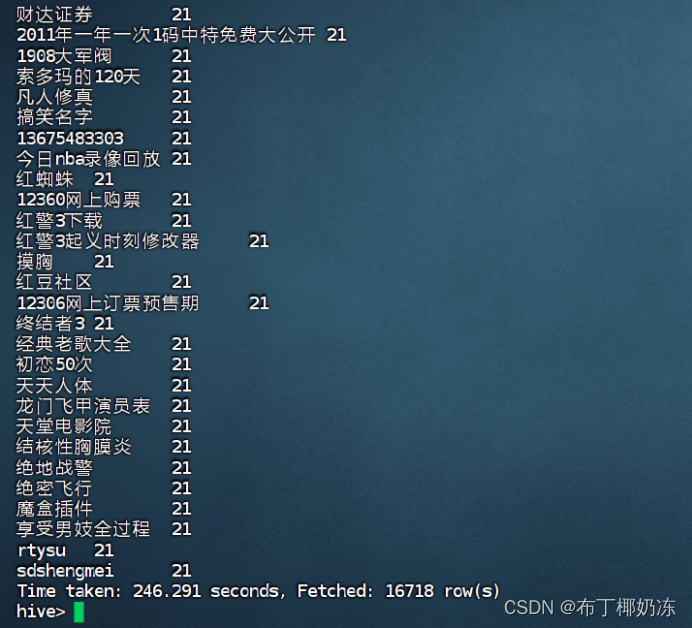
- 统计搜索的关键字词频,找出查询频度超过20的关键词和其频度,按照频度从高到低排列。
sql
select keyword , count(*) as frequency
from sogou2024
group by keyword
having count(*) > 20
order by frequency desc;
运行截图: