智领云自主研发的开源轻量级Kubernetes数据平台,即Kubernetes Data Platform (简称KDP),能够为用户提供在Kubernetes上的一站式云原生数据集成与开发平台。在最新的v1.1.0版本中,用户可借助 KDP 平台上开箱即用的 Airflow、AirByte、Flink、Kafka、MySQL、ClickHouse、Superset 等开源组件快速搭建实时、半实时或批量采集、处理、分析的数据流水线以及可视化报表展示,可视化展示效果 如下:
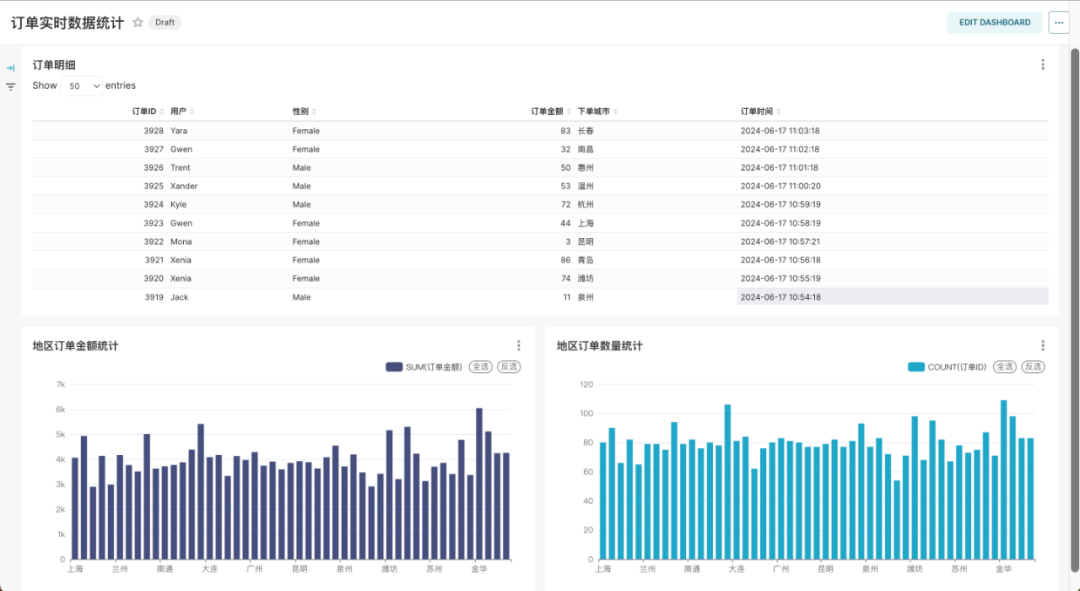
以下我们将介绍一个实时订单数据流水线从数据采集到数据处理,最后到可视化展示的详细建设流程。
1.流水线设计
借助 KDP 平台的开源组件 Airflow、MySQL、Flink、Kafka、ClickHouse、Superset 完成数据实时采集处理及可视化分析,架构如下:
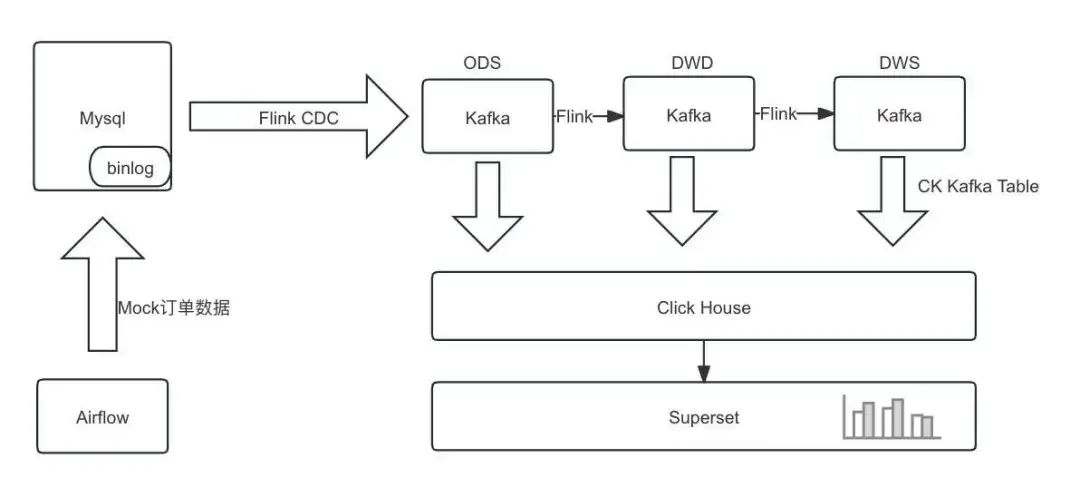
1.1 数据流
-
直接使用Flink构建实时数仓,由Flink进行清洗加工转换和聚合汇总,将各层结果集写入Kafka中;
-
ClickHouse从Kafka分别订阅各层数据,将各层数据持久化到ClickHouse中,用于之后的查询分析。
1.2 数据表
本次分析数据基于mock数据,包含数据实时采集处理及可视化分析:
- 消费者表:customers
|--------|------|
| 字段 | 字段说明 |
| id | 用户ID |
| name | 姓名 |
| age | 年龄 |
| gender | 性别 |
- 订单表:orders
|---------------|------|
| 字段 | 字段说明 |
| order_id | 订单ID |
| order_revenue | 订单金额 |
| order_region | 下单地区 |
| customer_id | 用户ID |
| create_time | 下单时间 |
1.3 环境说明
在 KDP 页面安装如下组件并完成组件的 QuickStart:
-
MySQL: 实时数据数据源及 Superset/Airflow 元数据库,安装时需要开启binlog
-
Kafka: 数据采集sink
-
Flink: 数据采集及数据处理
-
ClickHouse: 数据存储
-
Superset: 数据可视化
-
Airflow: 作业调度
2. 数据集成与处理
文中使用的账号密码信息请根据实际集群配置进行修改。
2.1 创建MySQL表
2.2 创建 Kafka Topic
进入Kafka broker pod,执行命令创建 Topic,也可以通过Kafka manager 页面创建,以下为进入pod并通过命令行创建的示例:
sql
export BOOTSTRAP="kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092"
bin/kafka-topics.sh --create \
--topic ods-order \
--replication-factor 3 \
--partitions 10 \
--bootstrap-server $BOOTSTRAP
bin/kafka-topics.sh --create \
--topic ods-customers \
--replication-factor 3 \
--partitions 10 \
--bootstrap-server $BOOTSTRAP
bin/kafka-topics.sh --create \
--topic dwd-order-customer-valid \
--replication-factor 3 \
--partitions 10 \
--bootstrap-server $BOOTSTRAP
bin/kafka-topics.sh --create \
--topic dws-agg-by-region \
--replication-factor 3 \
--partitions 10 \
--bootstrap-server $BOOTSTRAP2.3 创建 ClickHouse 表
进入clickhouse pod,使用`clickhouse-client`执行命令创建表,以下为建表语句:
sql
CREATE DATABASE IF NOT EXISTS kdp_demo;
USE kdp_demo;
-- kafka_dwd_order_customer_valid
CREATE TABLE IF NOT EXISTS kdp_demo.dwd_order_customer_valid (
order_id Int32,
order_revenue Float32,
order_region String,
create_time DateTime,
customer_id Int32,
customer_age Float32,
customer_name String,
customer_gender String
) ENGINE = MergeTree()
ORDER BY order_id;
CREATE TABLE kdp_demo.kafka_dwd_order_customer_valid (
order_id Int32,
order_revenue Float32,
order_region String,
create_time DateTime,
customer_id Int32,
customer_age Float32,
customer_name String,
customer_gender String
) ENGINE = Kafka
SETTINGS
kafka_broker_list = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
kafka_topic_list = 'dwd-order-customer-valid',
kafka_group_name = 'clickhouse_group',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n';
CREATE MATERIALIZED VIEW kdp_demo.mv_dwd_order_customer_valid TO kdp_demo.dwd_order_customer_valid AS
SELECT
order_id,
order_revenue,
order_region,
create_time,
customer_id,
customer_age,
customer_name,
customer_gender
FROM kdp_demo.kafka_dwd_order_customer_valid;
-- kafka_dws_agg_by_region
CREATE TABLE IF NOT EXISTS kdp_demo.dws_agg_by_region (
order_region String,
order_cnt Int64,
order_total_revenue Float32
) ENGINE = ReplacingMergeTree()
ORDER BY order_region;
CREATE TABLE kdp_demo.kafka_dws_agg_by_region (
order_region String,
order_cnt Int64,
order_total_revenue Float32
) ENGINE = Kafka
SETTINGS
kafka_broker_list = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
kafka_topic_list = 'dws-agg-by-region',
kafka_group_name = 'clickhouse_group',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n';
CREATE MATERIALIZED VIEW kdp_demo.mv_dws_agg_by_region TO kdp_demo.dws_agg_by_region AS
SELECT
order_region,
order_cnt,
order_total_revenue
FROM kdp_demo.kafka_dws_agg_by_region;2.4 创建 Flink SQL 作业
2.4.1 SQL部分
sql
CREATE DATABASE IF NOT EXISTS `default_catalog`.`kdp_demo`;
-- create source tables
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`orders_src`(
`order_id` INT NOT NULL,
`order_revenue` FLOAT NOT NULL,
`order_region` STRING NOT NULL,
`customer_id` INT NOT NULL,
`create_time` TIMESTAMP,
PRIMARY KEY(`order_id`) NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = 'kdp-data-mysql',
'port' = '3306',
'username' = 'bdos_dba',
'password' = 'KdpDba!mysql123',
'database-name' = 'kdp_demo',
'table-name' = 'orders'
);
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`customers_src` (
`id` INT NOT NULL,
`age` FLOAT NOT NULL,
`name` STRING NOT NULL,
`gender` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with (
'connector' = 'mysql-cdc',
'hostname' = 'kdp-data-mysql',
'port' = '3306',
'username' = 'bdos_dba',
'password' = 'KdpDba!mysql123',
'database-name' = 'kdp_demo',
'table-name' = 'customers'
);
-- create ods dwd and dws tables
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`ods_order_table` (
`order_id` INT,
`order_revenue` FLOAT,
`order_region` VARCHAR(40),
`customer_id` INT,
`create_time` TIMESTAMP,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'ods-order',
'properties.bootstrap.servers' = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
'key.format' = 'json',
'value.format' = 'json'
);
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`ods_customers_table` (
`customer_id` INT,
`customer_age` FLOAT,
`customer_name` STRING,
`gender` STRING,
PRIMARY KEY (customer_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'ods-customers',
'properties.bootstrap.servers' = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
'key.format' = 'json',
'value.format' = 'json'
);
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`dwd_order_customer_valid` (
`order_id` INT,
`order_revenue` FLOAT,
`order_region` STRING,
`create_time` TIMESTAMP,
`customer_id` INT,
`customer_age` FLOAT,
`customer_name` STRING,
`customer_gender` STRING,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'dwd-order-customer-valid',
'properties.bootstrap.servers' = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
'key.format' = 'json',
'value.format' = 'json'
);
CREATE TABLE IF NOT EXISTS `default_catalog`.`kdp_demo`.`dws_agg_by_region` (
`order_region` VARCHAR(40),
`order_cnt` BIGINT,
`order_total_revenue` FLOAT,
PRIMARY KEY (order_region) NOT ENFORCED
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'dws-agg-by-region',
'properties.bootstrap.servers' = 'kafka-3-cluster-kafka-0.kafka-3-cluster-kafka-brokers.kdp-data.svc.cluster.local:9092',
'key.format' = 'json',
'value.format' = 'json'
);
USE kdp_demo;
-- EXECUTE STATEMENT SET
-- BEGIN
INSERT INTO ods_order_table SELECT * FROM orders_src;
INSERT INTO ods_customers_table SELECT * FROM customers_src;
INSERT INTO
dwd_order_customer_valid
SELECT
o.order_id,
o.order_revenue,
o.order_region,
o.create_time,
c.id as customer_id,
c.age as customer_age,
c.name as customer_name,
c.gender as customer_gender
FROM
customers_src c
JOIN orders_src o ON c.id = o.customer_id
WHERE
c.id <> -1;
INSERT INTO
dws_agg_by_region
SELECT
order_region,
count(*) as order_cnt,
sum(order_revenue) as order_total_revenue
FROM
dwd_order_customer_valid
GROUP BY
order_region;
-- END;2.4.2 使用 StreamPark 创建 Flink SQL 作业
具体使用参考 StreamPark 文档。
maven 依赖:
xml
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>3.0.1</version>
</dependency>2.5 创建 Airflow DAG
2.5.1 DAG 文件部分
python
import random
from datetime import timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago
default_args = {
'owner': 'admin',
'depends_on_past': False,
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
}
dag = DAG(
'kdp_demo_order_data_insert',
description='Insert into orders by using random data',
schedule_interval=timedelta(minutes=1),
start_date=days_ago(1),
catchup=False,
tags=['kdp-example'],
)
# MySQL connection info
mysql_host = 'kdp-data-mysql'
mysql_db = 'kdp_demo'
mysql_user = 'bdos_dba'
mysql_password = 'KdpDba!mysql123'
mysql_port = '3306'
cities = ["北京", "上海", "广州", "深圳", "成都", "杭州", "重庆", "武汉", "西安", "苏州", "天津", "南京", "郑州",
"长沙", "东莞", "青岛", "宁波", "沈阳", "昆明", "合肥", "大连", "厦门", "哈尔滨", "福州", "济南", "温州",
"佛山", "南昌", "长春", "贵阳", "南宁", "金华", "石家庄", "常州", "泉州", "南通", "太原", "徐州", "嘉兴",
"乌鲁木齐", "惠州", "珠海", "扬州", "兰州", "烟台", "汕头", "潍坊", "保定", "海口"]
city = random.choice(cities)
consumer_id = random.randint(1, 100)
order_revenue = random.randint(1, 100)
# 插入数据的 BashOperator
insert_data_orders = BashOperator(
task_id='insert_data_orders',
bash_command=f'''
mysql -h {mysql_host} -P {mysql_port} -u {mysql_user} -p{mysql_password} {mysql_db} -e "
INSERT INTO orders(order_revenue,order_region,customer_id) VALUES({order_revenue},'{city}',{consumer_id});"
''',
dag=dag,
)
insert_data_orders2.5.2 DAG 说明及执行
当前Airflow安装时,需要指定可访问的git 仓库地址,因此需要将 Airflow DAG 提交到 Git 仓库中。每分钟向orders表插入一条数据。
2.6 数据验证
使用ClickHouse验证数据:
(1)进入ClickHouse客户端
apache
clickhouse-client
# default pass: ckdba.123(2)执行查询
sql
SELECT * FROM kdp_demo.dwd_order_customer_valid;
SELECT count(*) FROM kdp_demo.dwd_order_customer_valid;(3)对比验证MySQL中数据是否一致
sql
select count(*) from kdp_demo.orders;3. 数据可视化
在2.6中数据验证通过后,可以通过Superset进行数据可视化展示。使用账号`admin/admin`登录Superset页面(注意添加本地 Host 解析):http://superset-kdp-data.kdp-e2e.io
3.1 创建图表
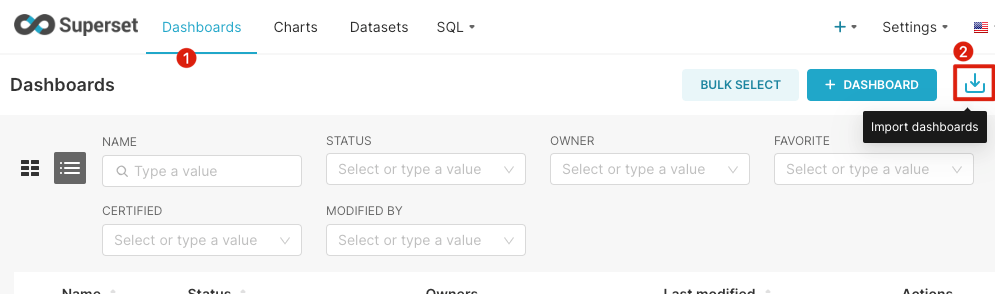
导入我们制作好的图表:
(1)选择下载的文件导入
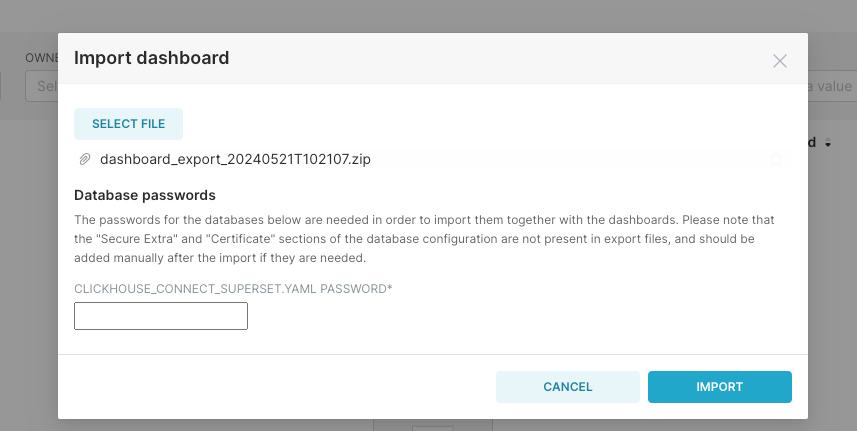
(2)输入 ClickHouse 的用户`default`的默认密码`ckdba.123`:
3.2 效果展示
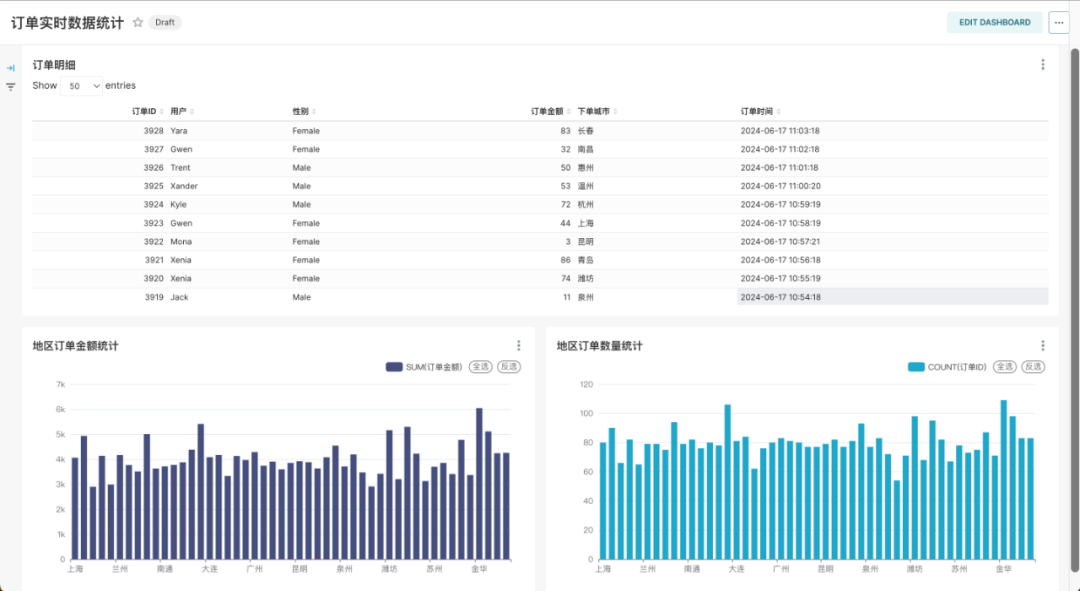
最终的实时订单数据图表展示如下,随着订单数据的更新,图表中的数据也会实时更新:
快速体验
🚀GitHub项目:
https://github.com/linktimecloud/kubernetes-data-platform
欢迎您参与开源社区的建设🤝
- FIN -

更多精彩推 荐