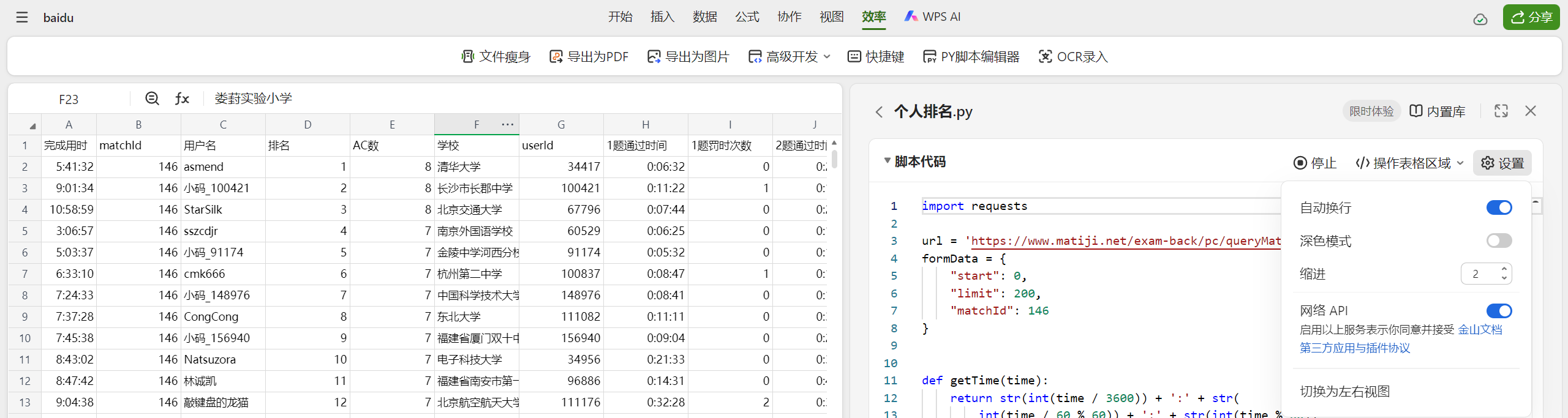
运行效果
手动拉取
如果手动查找,那么只能通过翻页的方式,每页10行(外加一行自己)。
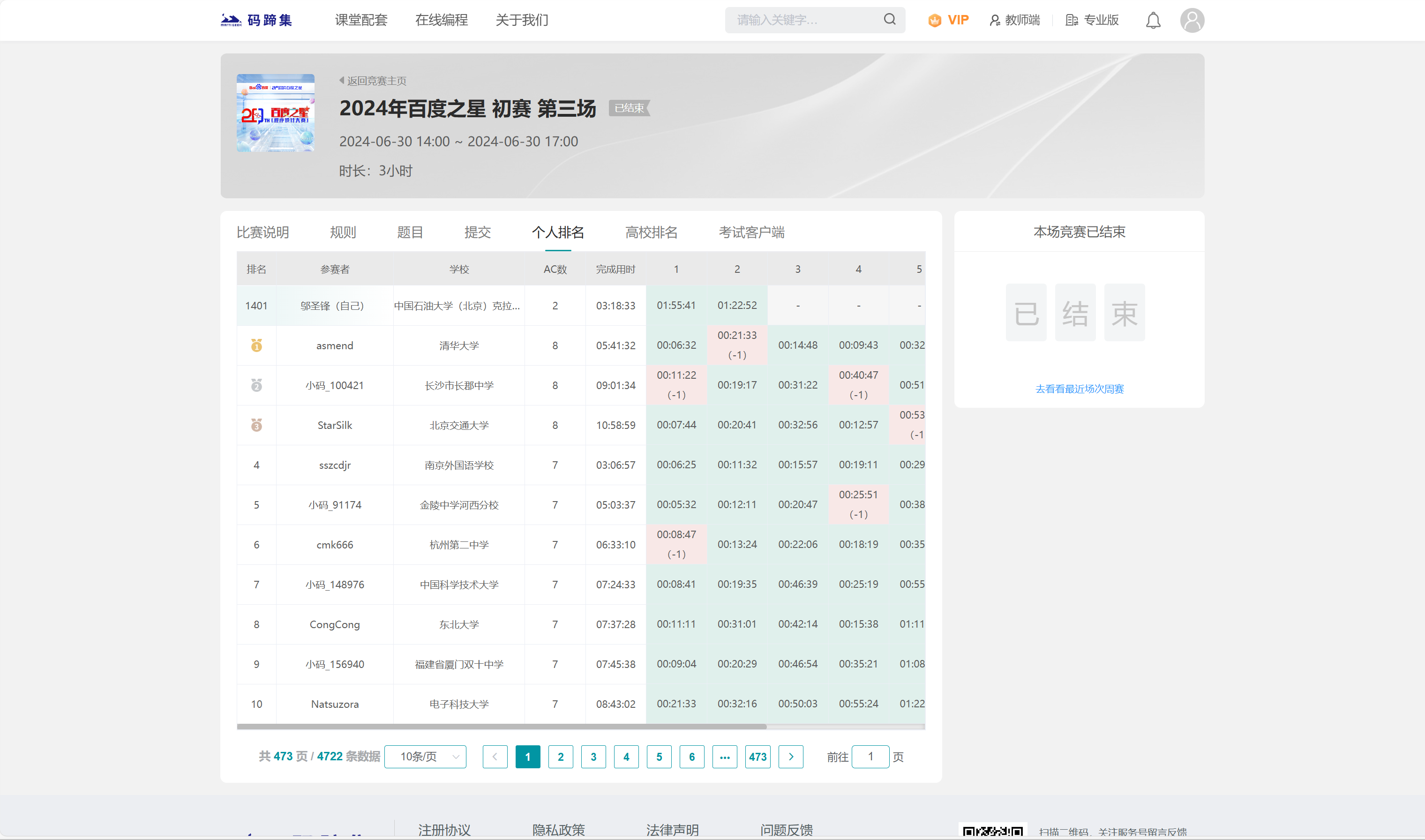
爬取效果预览
本脚本爬取了个人排名和高校排名,可以借助WPS或MS Office的表格工具方便分析数据(开盒)。
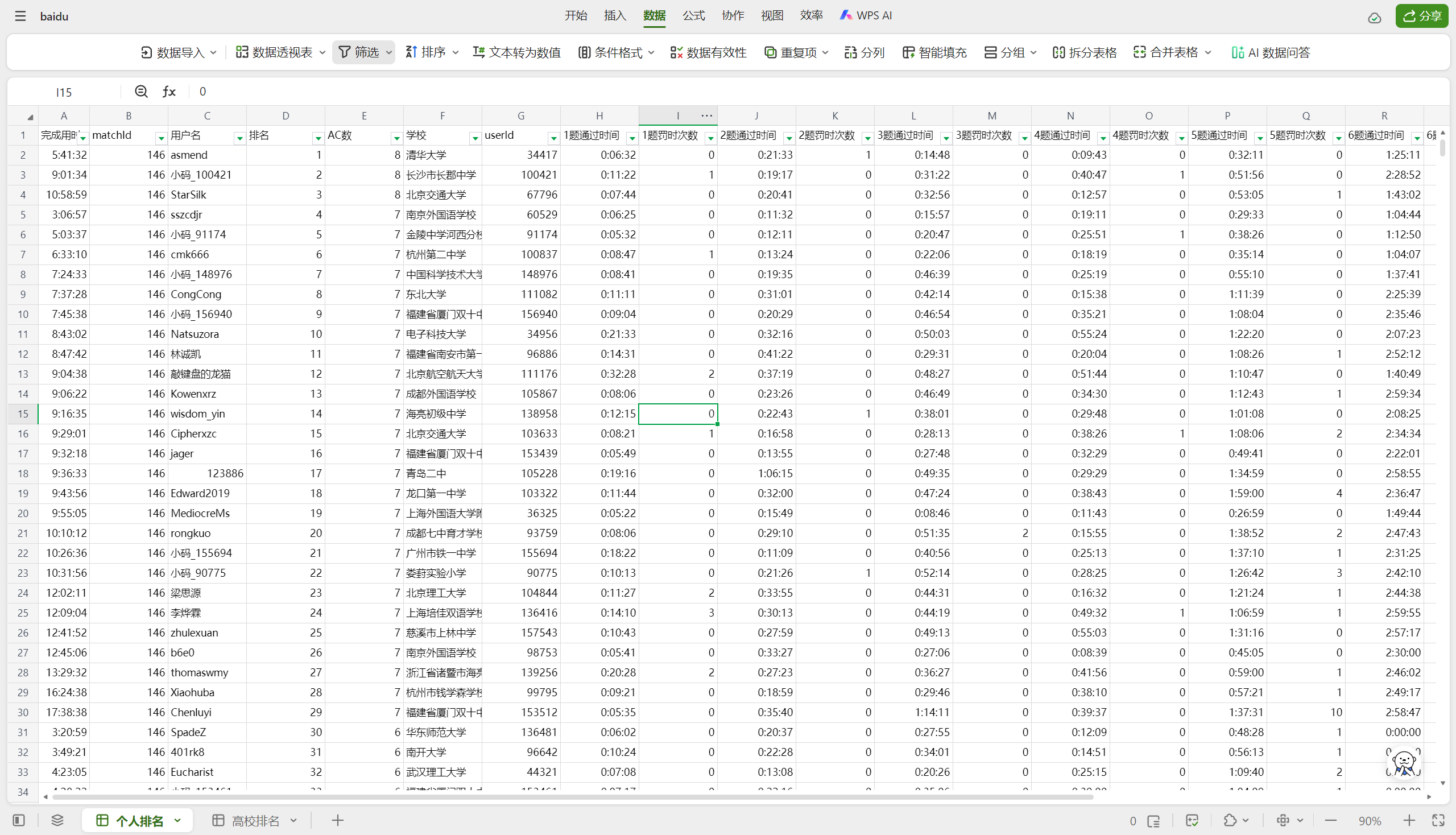
原理支撑
前提:
- WPS表格支持py环境,并封装了方便的表格工具
过程:
- 通过py模拟用户请求,将返回值对对象的形式封装
- 打印对象,找规律,将需要的信息重新封装
- 写入WPS表格
抠榜单接口
打开开发人员工具,默认快捷键是F12。
不同的浏览器,页面可以不一样,需要切换到"网络"标签下。
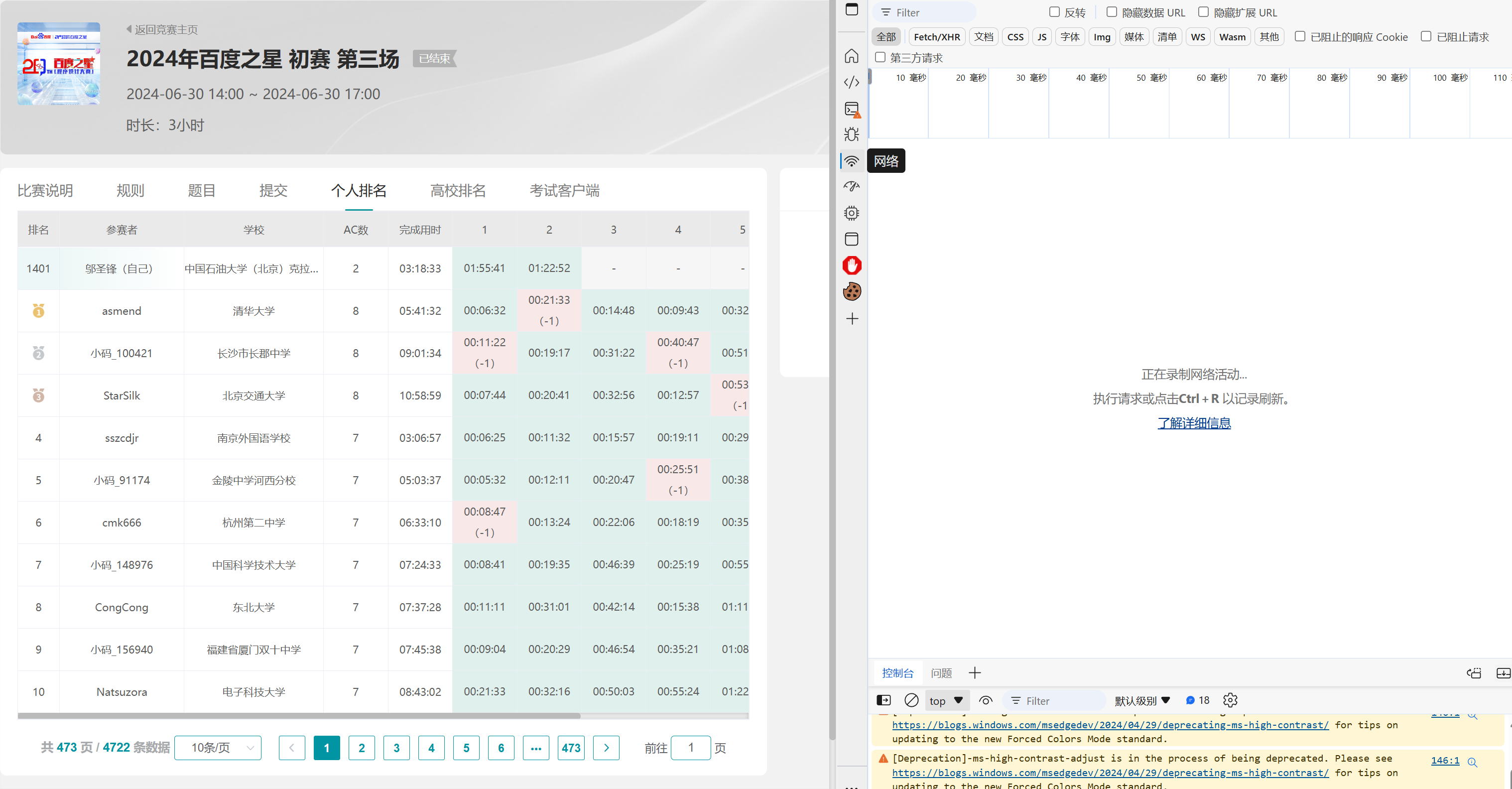
获取接口URL
切换分页:切换到第2页和第3页。每次切换,浏览器都发送了一个名为queryMatchRankListById.do的请求。
可见相应内容含广州市铁一中学字段。根据返回的内容,可以暂定为所求的榜单接口。
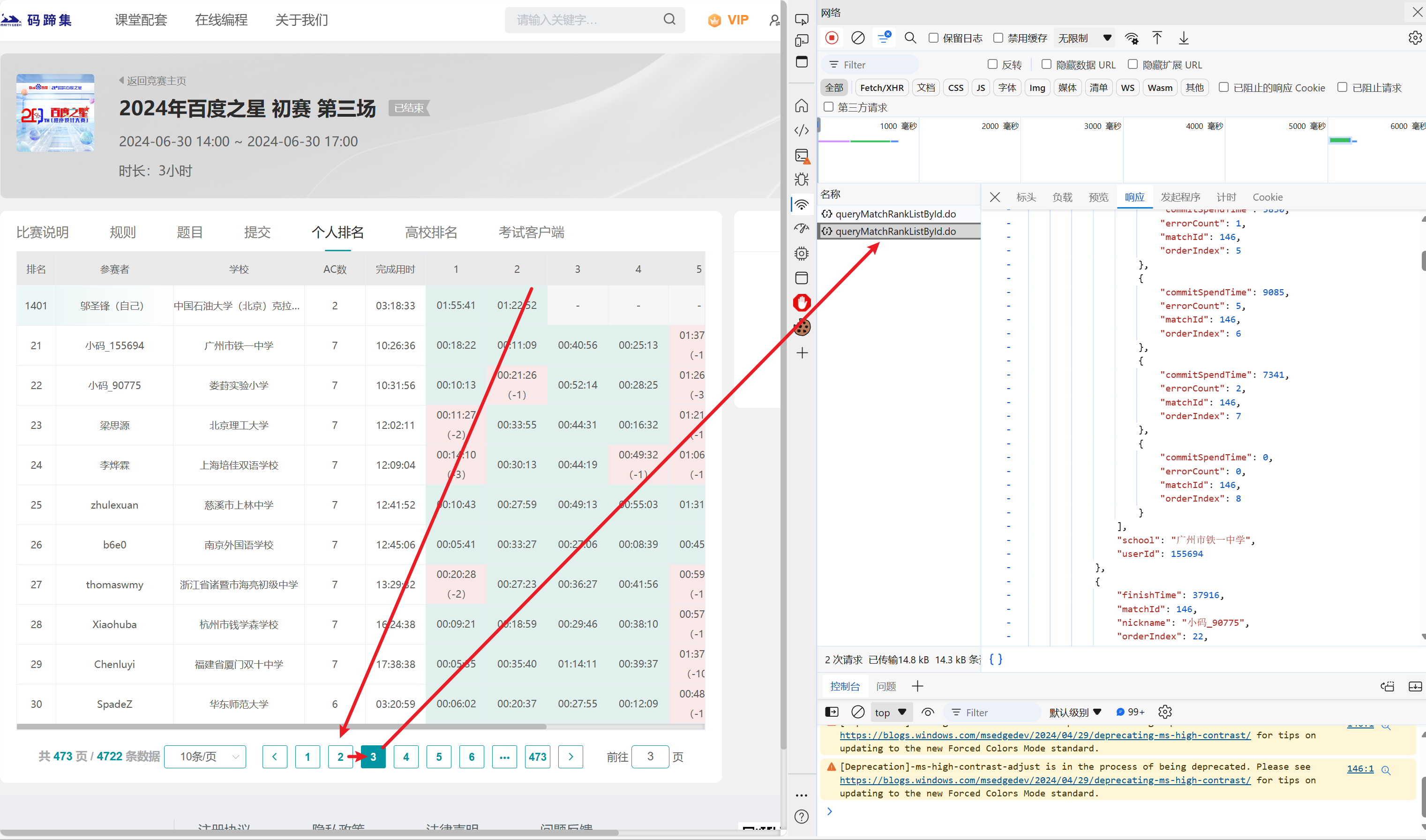
判断请求方式
切换到标头标签下,可见:
- URL为:
https://www.matiji.net/exam-back/pc/queryMatchRankListById.do - 方法为:
POST

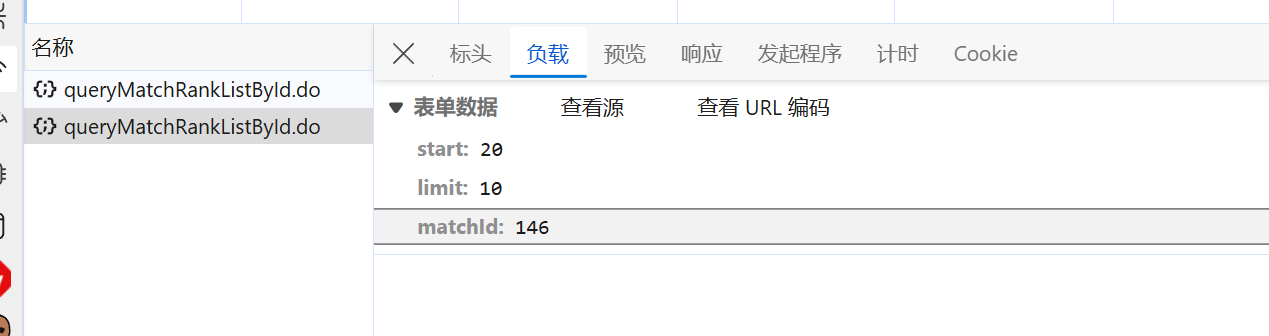
判断请求负载
切换到负载标签下,可见携带了三个参数,根据单词,可以推测语义为:
start:从哪开始limit:获取几条matchId:哪个比赛
负载方式是"表单数据"
验证接口
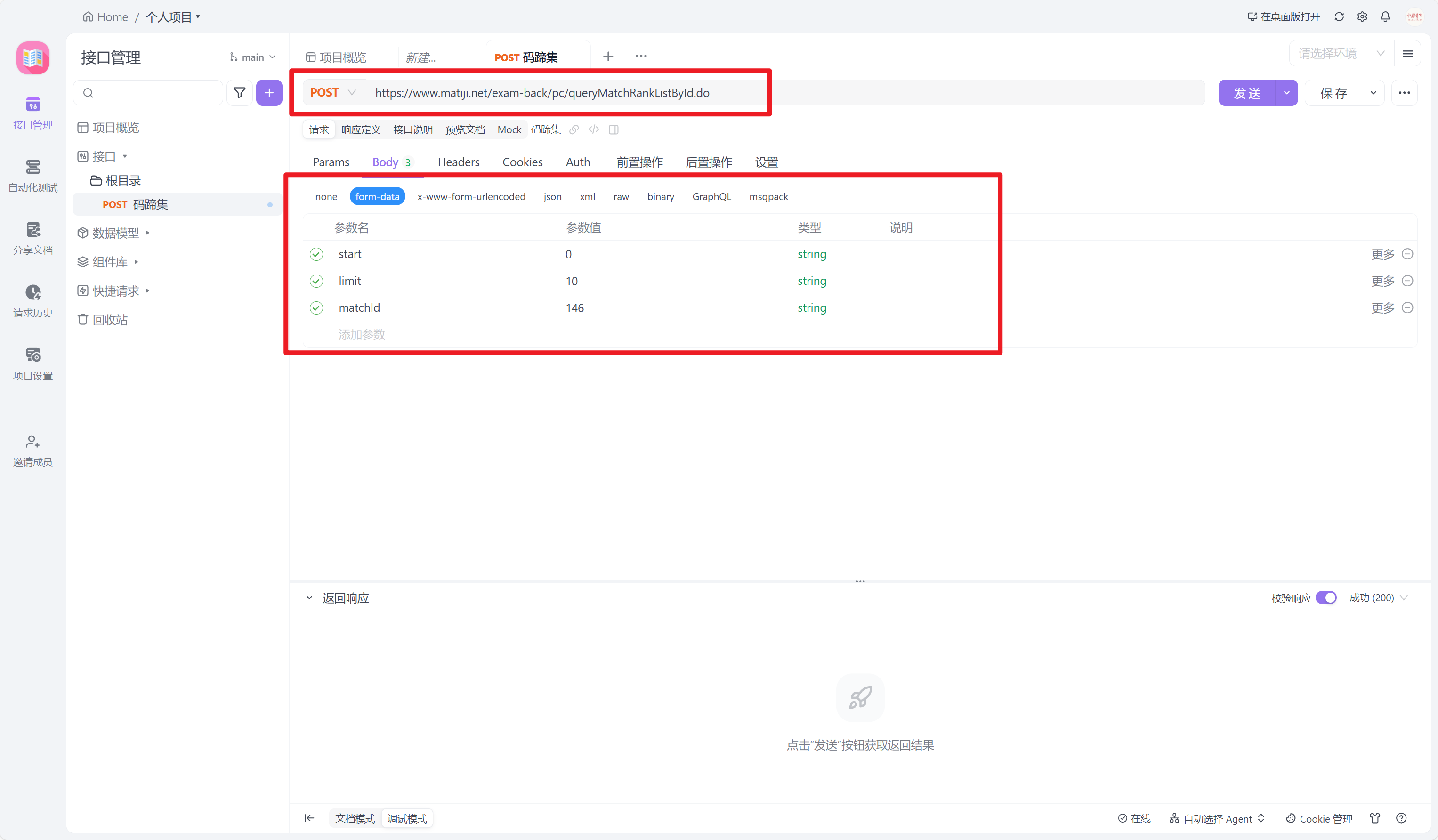
打开apifox,填入提取到的信息。
注意截图中被框选的地方。
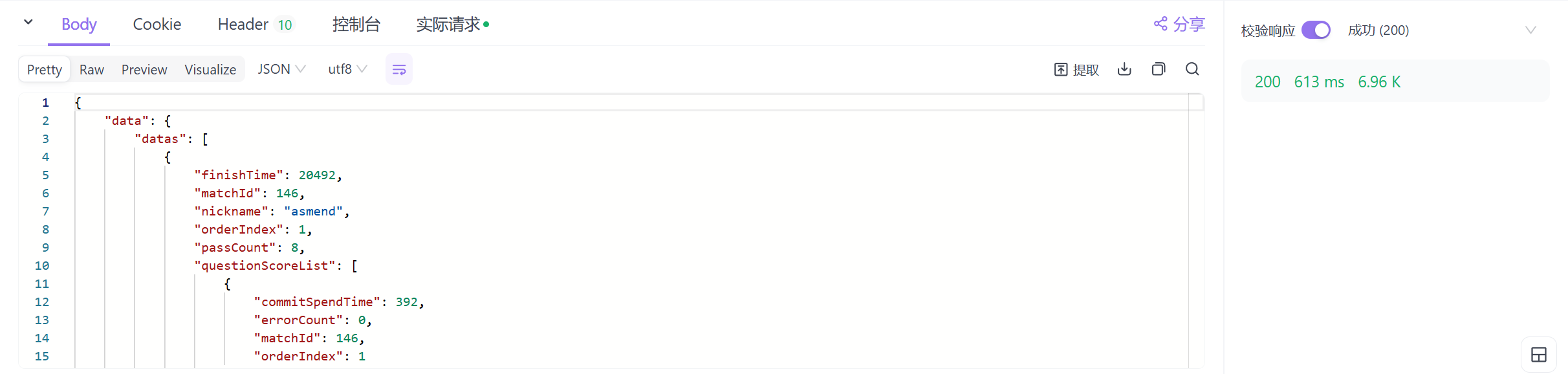
发送请求,可见得到了正确的响应。
部分接口还需要携带额外参数,来验证请求。需要不断调试。
py拉取个人排名
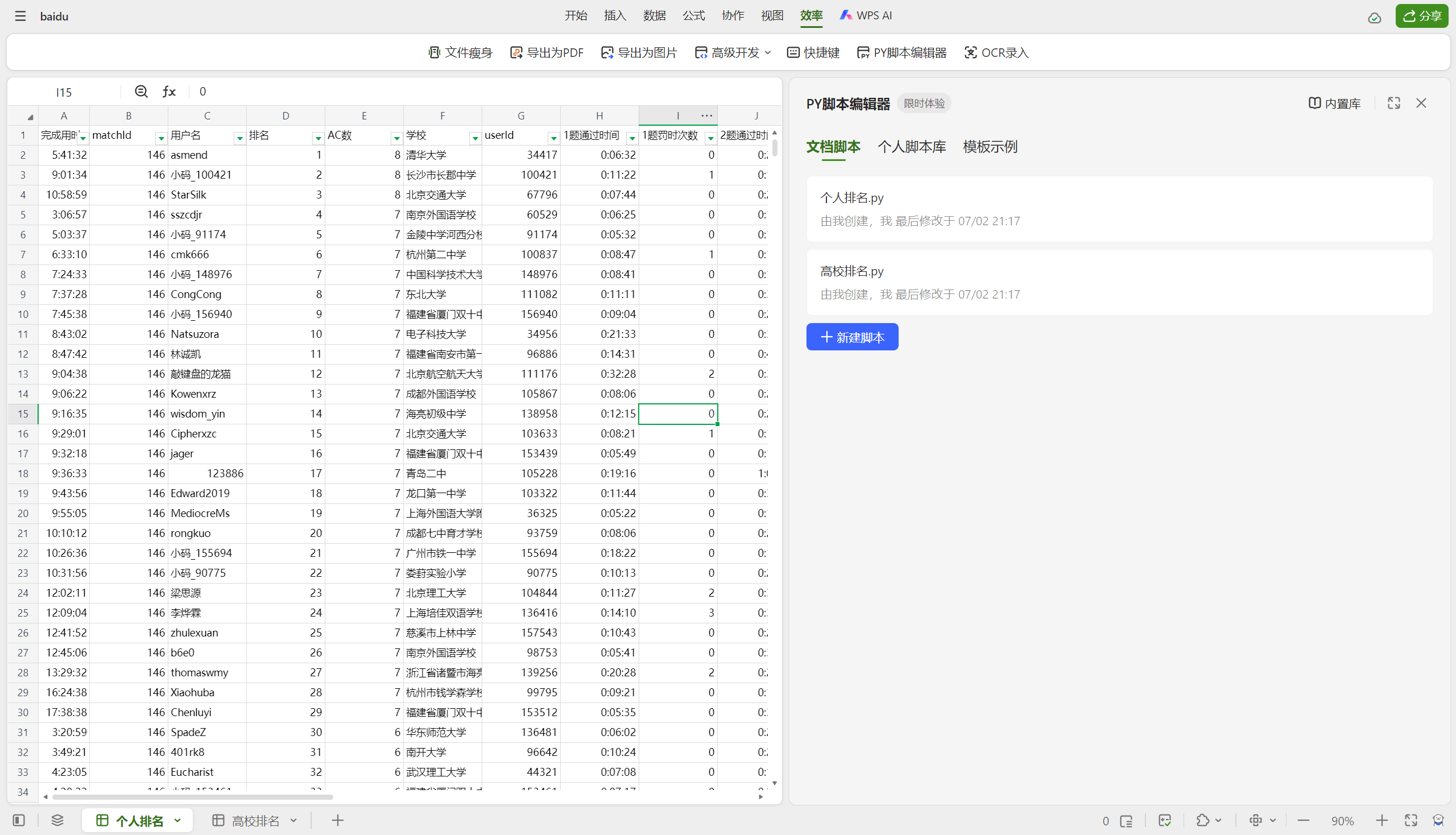
WPS的py环境
新建"智能表格",而不是"Office表格"。
在"效率"中,找到"PY脚本编辑器"。
引入配置
python
import requests
url = 'https://www.matiji.net/exam-back/pc/queryMatchRankListById.do'
formData = {
"start": 0,
"limit": 200,
"matchId": 146
}引入requests包是为了发送HTTP请求。
将URL和请求负载分别封装,是为了方便之后的调试。
定义时间格式化函数
接口返回的时间是一个大整数。
而网页显示的是一个hh:mm:ss格式的字符串。
需要格式化。
python
def getTime(time):
return str(int(time / 3600)) + ':' + str(
int(time / 60 % 60)) + ':' + str(int(time % 60))轮询榜单
在循环开头定义结束条件。
结束条件通过调试接口获取:
- 在榜单正常获取是,
error_no值为0
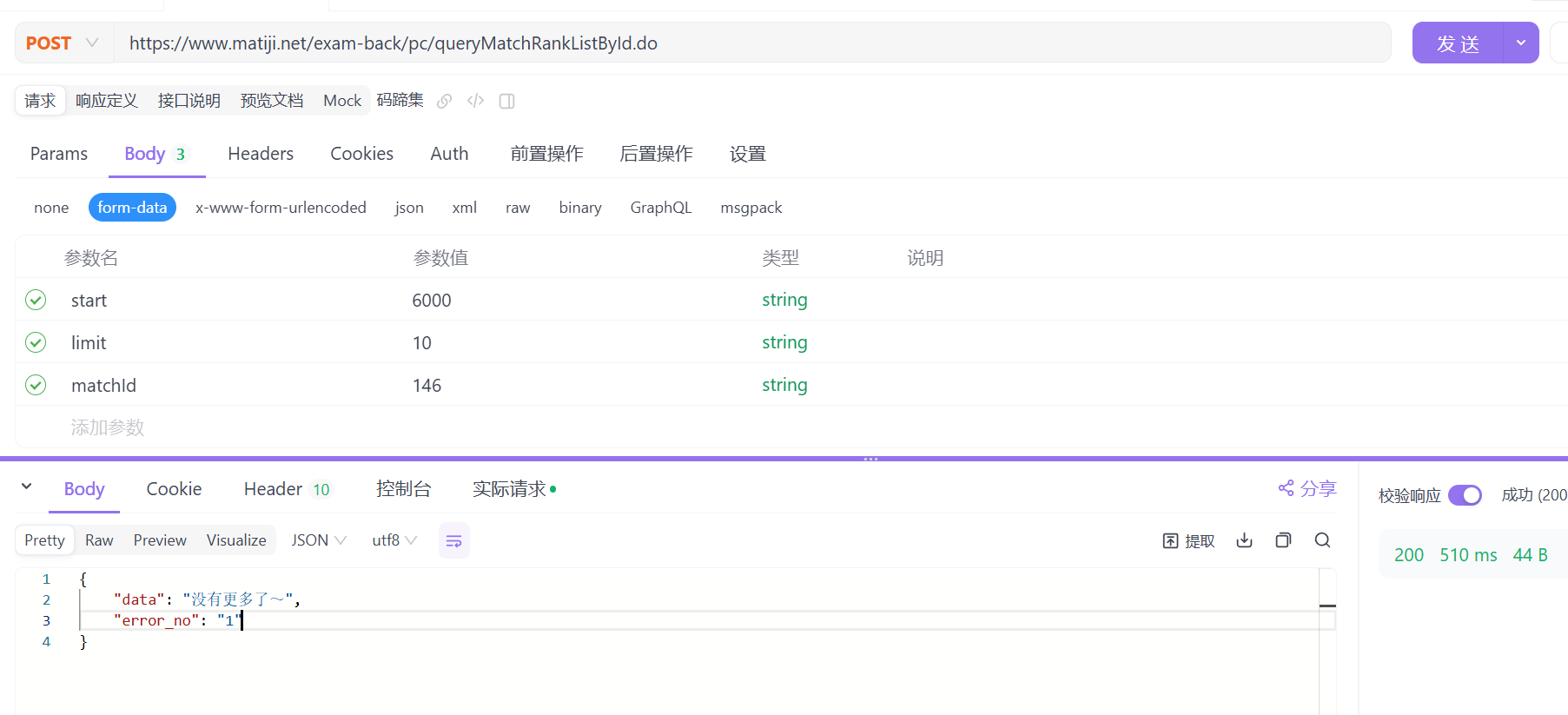
对于当前轮次的响应,需要调用.json(),以对象的方式获取响应数据。
cur用于维护下一行,将当前批次的数据插入到合理的位置。
python
cur = 0
while True:
response = requests.post(url, data=formData).json()
if response['error_no'] != '0':
exit(0)
输出结果同Apifox。
取出单行数据
当前查询返回的是10个人的信息。
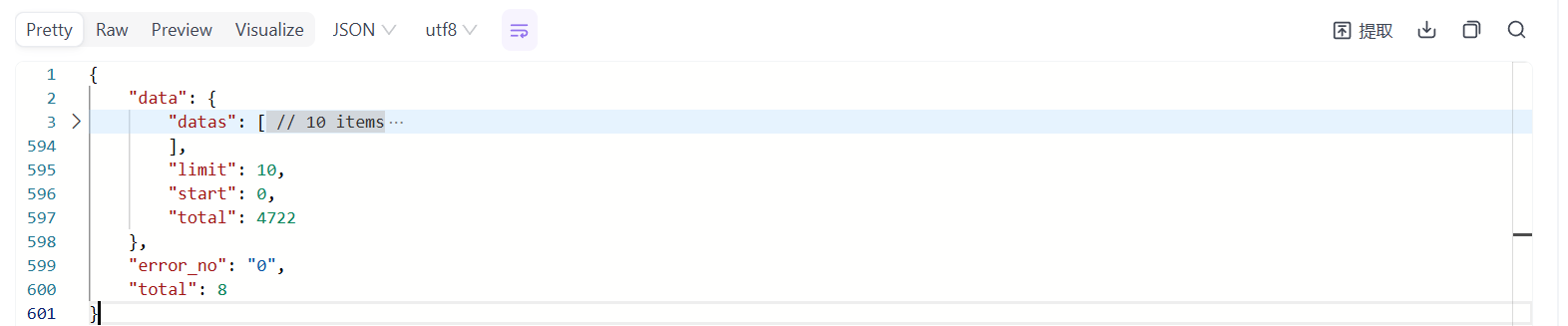
以数组的方式存储在.data.datas中,需要逐项取出格式化。
python
xslxList = []
for data in response['data']['datas']:
tempData = {}
tempData['完成用时'] = getTime(data.get('finishTime', 0))
tempData['matchId'] = data.get('matchId', 0)
tempData['用户名'] = data.get('nickname', '')
tempData['排名'] = data.get('orderIndex', 0)
tempData['AC数'] = data.get('passCount', 0)
tempData['学校'] = data.get('school', '')
tempData['userId'] = data.get('userId', 0)xslxList一个列表,用于存储当前批次的数据,以及表头(如果是第一次写入)
tempData一个字典,用于临时存储每个用户的详细信息和成绩
处理题目数据
datas是一个列表,数据项questionScoreList也是一个列表。
写入表格要求"维度相同",需要拆成单个键值对。
python
if 'questionScoreList' in data:
for questionScore in data['questionScoreList']:
orderIndex = questionScore['orderIndex']
tempData[str(orderIndex) + '题通过时间'] = getTime(questionScore['commitSpendTime'])
tempData[str(orderIndex) + '题罚时次数'] = questionScore['errorCount']
else:
for i in range(1, 9):
tempData[str(i) + '题通过时间'] = 0
tempData[str(i) + '题罚时次数'] = 0亲测爆零选手不含questionScoreList字段,也需要初始化,否则会插入失败。
将处理完的用户插入到列表中。
如果是第一行,需要特判,多插一行表头。
python
if cur == 0 and len(xslxList) == 0:
xslxList.append(list(tempData.keys()))
xslxList.append(list(tempData.values()))写入表格
在WPS中写入表格不需要引第三方库,WPS封装了更简单的实现方法。
python
write_xl(xslxList, "A" + str(1 + cur),sheet_name="个人排名")
cur += len(xslxList)
formData['start'] = cur - 1插入表格之后需要维护cur和formData,确保正确地访问下一批次,并插入到正确的位置。
完整py代码
亲测官方没有限制limit参数,或者限制不大。
一次性请求多条也不会被拉黑。
使用之前需要开启网络API。
cpp
import requests
url = 'https://www.matiji.net/exam-back/pc/queryMatchRankListById.do'
formData = {
"start": 0,
"limit": 200,
"matchId": 146
}
def getTime(time):
return str(int(time / 3600)) + ':' + str(
int(time / 60 % 60)) + ':' + str(int(time % 60))
cur = 0
while True:
response = requests.post(url, data=formData).json()
if response['error_no'] != '0':
exit(0)
xslxList = []
for data in response['data']['datas']:
tempData = {}
tempData['完成用时'] = getTime(data.get('finishTime', 0))
tempData['matchId'] = data.get('matchId', 0)
tempData['用户名'] = data.get('nickname', '')
tempData['排名'] = data.get('orderIndex', 0)
tempData['AC数'] = data.get('passCount', 0)
tempData['学校'] = data.get('school', '')
tempData['userId'] = data.get('userId', 0)
if 'questionScoreList' in data:
for questionScore in data['questionScoreList']:
orderIndex = questionScore['orderIndex']
tempData[str(orderIndex) + '题通过时间'] = getTime(questionScore['commitSpendTime'])
tempData[str(orderIndex) + '题罚时次数'] = questionScore['errorCount']
else:
for i in range(1, 9):
tempData[str(i) + '题通过时间'] = 0
tempData[str(i) + '题罚时次数'] = 0
if cur == 0 and len(xslxList) == 0:
xslxList.append(list(tempData.keys()))
xslxList.append(list(tempData.values()))
write_xl(xslxList, "A" + str(1 + cur),sheet_name="个人排名")
cur += len(xslxList)
formData['start'] = cur - 1py拉取高校排名
高校排名比个人排名简单,没有嵌套列表。
python
import requests
url = 'https://www.matiji.net/exam-back/pc/queryMatchSchoolRankListById.do'
formData = {
"start": 0,
"limit": 100,
"matchId": 146
}
cur = 0
while True:
response = requests.post(url, data=formData).json()
if response['error_no'] != '0':
exit(0)
xslxList = []
for data in response['data']['datas']:
tempData = {}
tempData['排名'] = data['orderIndex']
tempData['学校'] = data['school']
tempData['参赛人数'] = data.get('totalUser',0)
tempData['AC数'] = data.get('totalAc',0)
if cur == 0 and len(xslxList) == 0:
xslxList.append(list(tempData.keys()))
xslxList.append(list(tempData.values()))
write_xl(xslxList, "A" + str(1 + cur),sheet_name='高校排名')
cur += len(xslxList)
formData['start'] = cur - 1当前排名
截止写到这一行的时候,已拉取的最新排名: