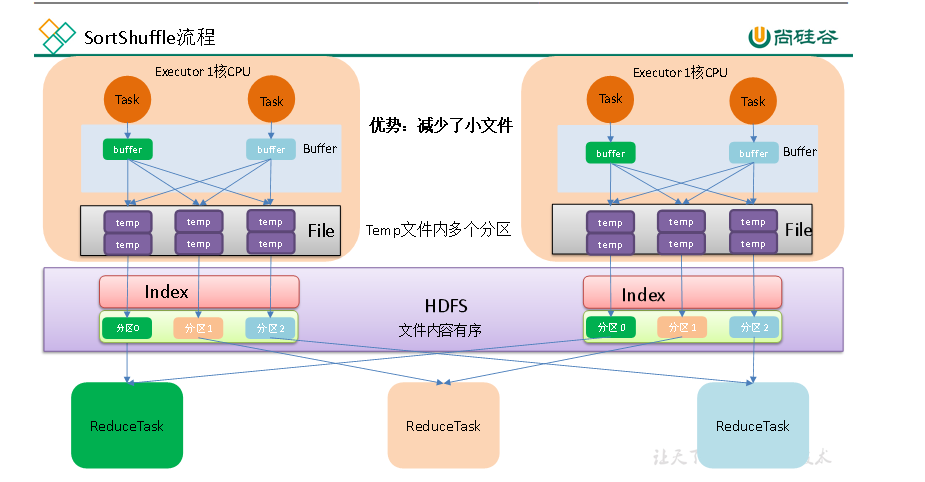
写入的简单流程:
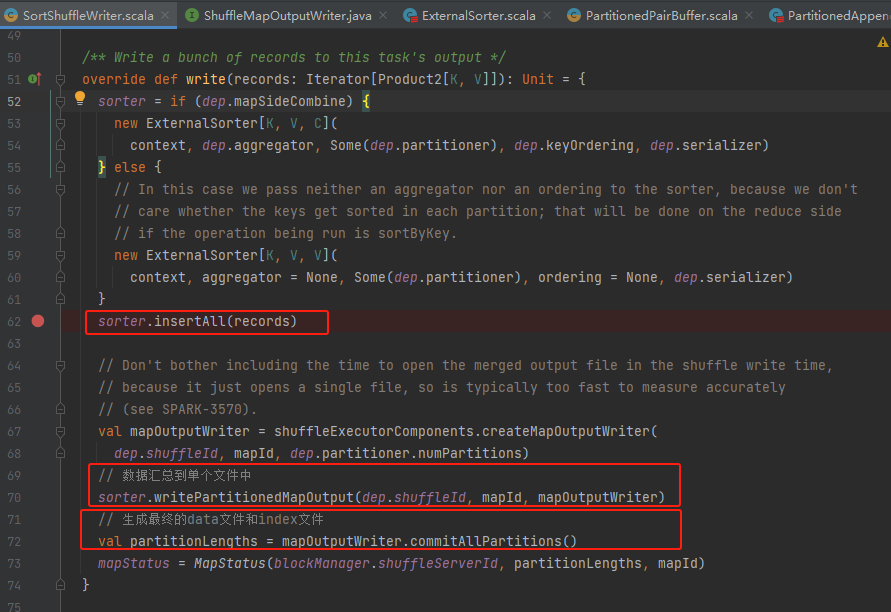
1.生成ExternalSorter对象
2.将消息都是插入ExternalSorter对象中
3.获取到mapOutputWriter,将中间产生的临时文件合并到一个临时文件
4.生成最后的data文件和index文件
可以看到写入的重点类是ExternalSorter对象
ExternalSorter
基本功能:对(k,v)进行排序,中间可能存在合并操作,最后生成(k,c)。
- 使用partitioner对key进行分区
- 在每个分区中使用Comparator进行排序
- 输出一个单独的文件,每个分区对应这个文件中的一段范围。
如果禁用了合并操作,类型C必须等于V
这个类的工作流程如下:
- 使用数据,反复填充内存缓冲区。如果是可以合并的数据,则使用PartitionedAppendOnlyMap;如果不合并,则使用PartitionedPairBuffer。在这些缓冲区中,我们首先按分区ID对元素进行排序,然后可能还会按键进行排序。为了避免对每个键多次调用分区器,我们将分区ID与每条记录一同存储。
- 当每个缓冲区达到内存限制时,会将其spill到文件中。这个文件首先按分区ID排序,如果需要做聚合操作,其次可能按键或键的哈希码排序。对于每个文件,跟踪每个分区在内存中的对象数量,因此不必为每个元素都写出分区ID。
- 当用户请求迭代器或文件输出时,溢写的文件会与任何剩余的内存数据一起被合并,使用上述定义的相同排序顺序(除非排序和聚合都被禁用)。如果需要按键进行聚合,我们或者从ordering参数中使用全序,或者读取具有相同哈希码的键并相互比较它们的相等性来合并值。
- 用户在结束时应调用stop()方法来删除所有中间文件。
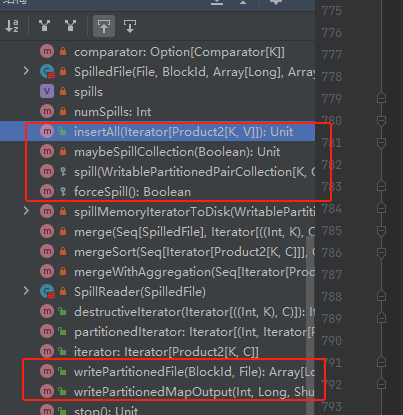
缓存buffer:PartitionedAppendOnlyMap、PartitionedPairBuffer
关键方法:insertAll、maybeSpillCollection、spill、writePartitionedMapOutput

PartitionedPairBuffer
capacity 容量
curSize 当前放入的数据量
data 数组,存储的数据,(k,v)占用数组的两个位置
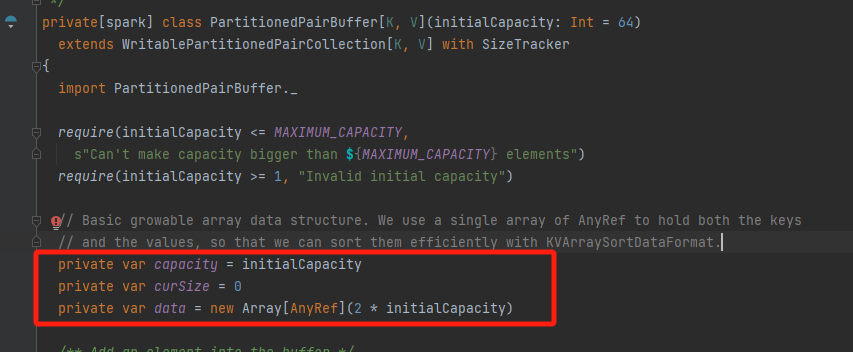
insert
如果容量达到瓶颈就进行扩容。
先存key,再存value。再调用afterUpdate
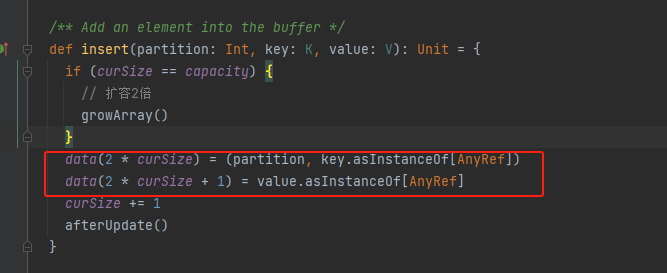
afterUpdate
numUpdates数据插入/更新次数
nextSampleNum下一次采样的次数
更新numUpdates,如果达到采样次数,执行采样takeSample
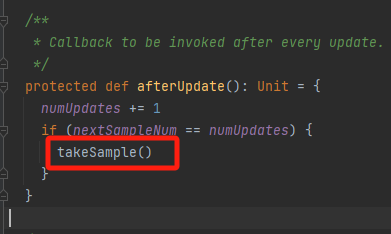
takeSample
samples中只存两个样品数据,用来计算每次更新的差值。
采样的时候要移除多余的数据。更新下一次采样的数据量。
estimateSize
预估大小。
最后一个样品的lastSize+bytesPerUpdate*新增的更新次数。
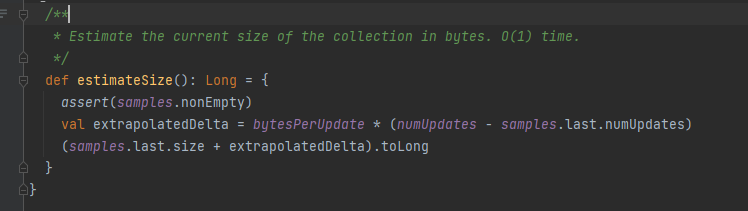
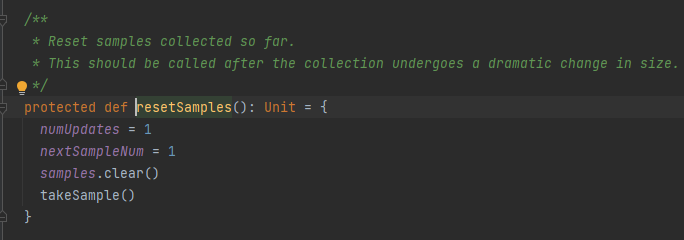
resetSamples
重新进行采样。
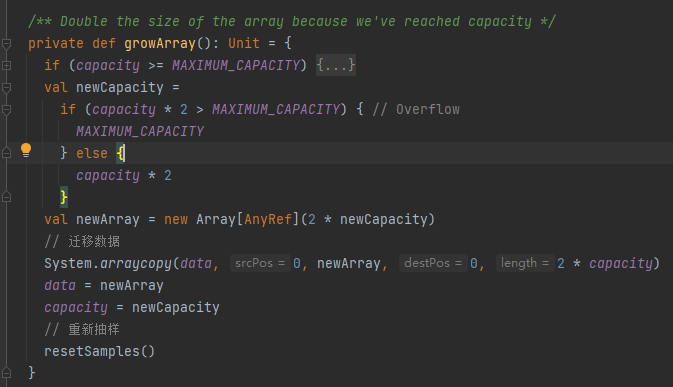
growArray
扩容2倍容量,迁移数据,重启采样
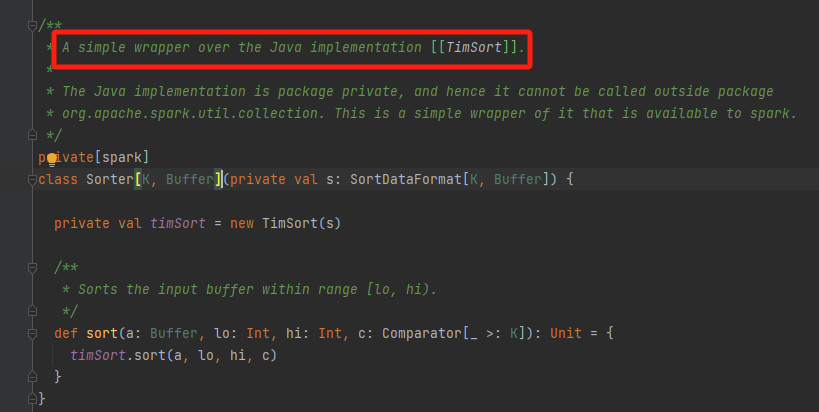
partitionedDestructiveSortedIterator
生成比较器comparator,调用sort对缓存的数据进行排序。

sorter是使用TimSort进行排序的。
TimSort介绍: https://zhuanlan.zhihu.com/p/695042849
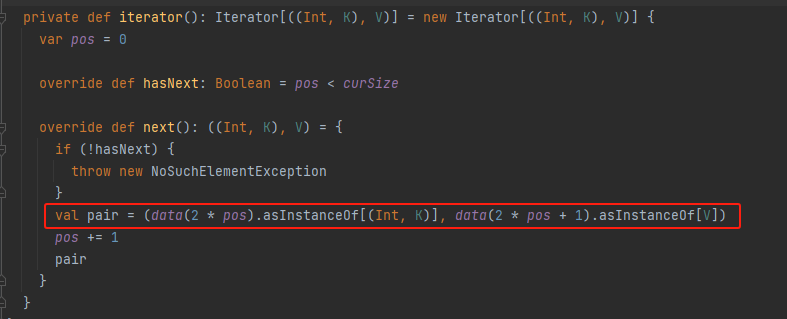
iterator
用pos计算剩余量。
data(2 * pos)为key,data(2 * pos+1) 为value
PartitionedAppendOnlyMap
存储数据用的数组data,里面的元素是key0, value0, key1, value1, key2, value2...

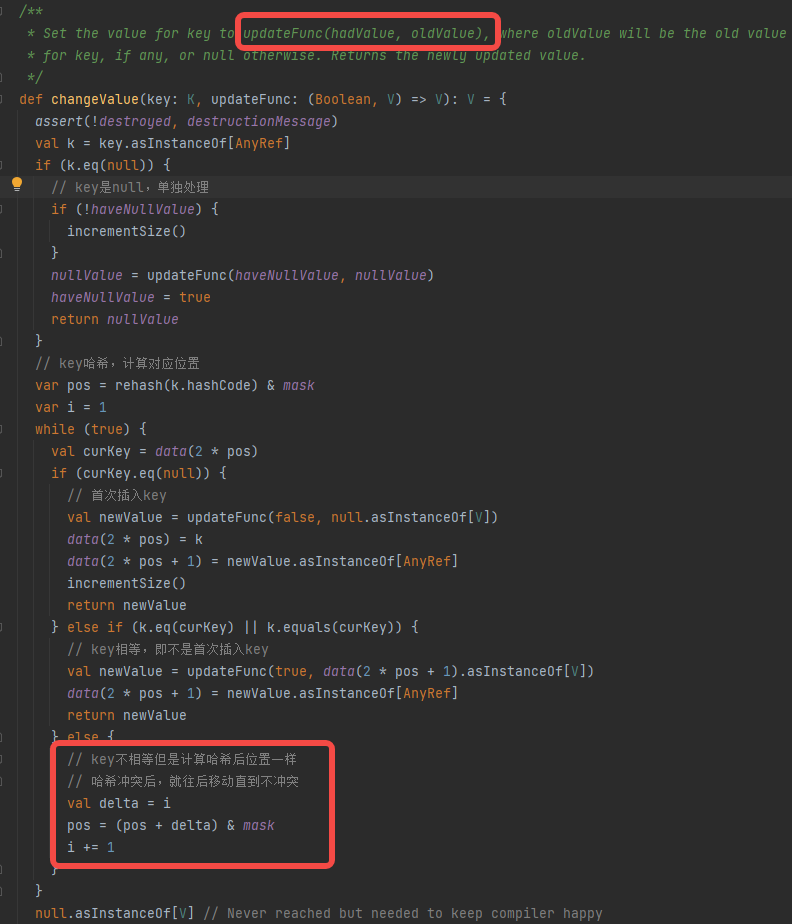
changeValue
PartitionedAppendOnlyMap插入数据不再是追加,而是有一个相同key合并值的过程。
- key是null,返回null,不进行存储
- key首次插入,更新data中的对应的kv值
- key非首次插入,更新data中合并的的新value
- key发生哈希冲突,就向后加1,直到不冲突
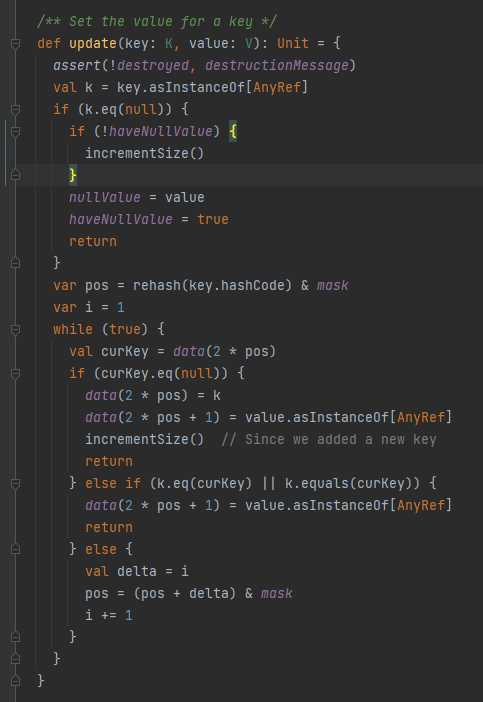
update
跟changeValue类似。
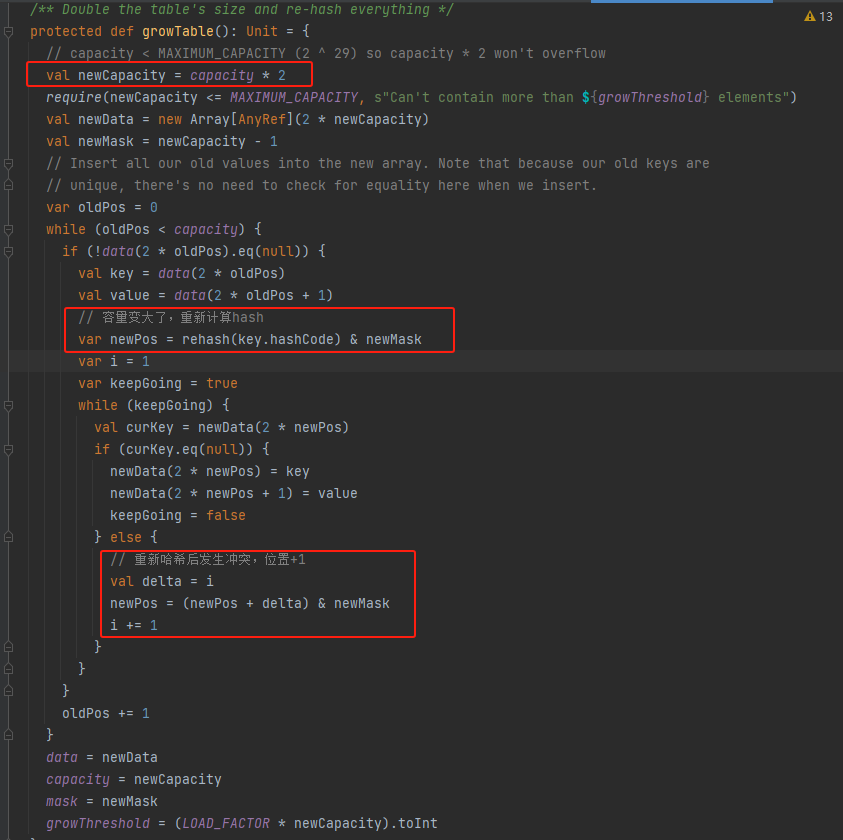
growTable
比较简单,就是容量扩大两倍,将旧的kv值重新计算hash插入到新的数组中,如果发生hash冲突就不断向后移动一位。
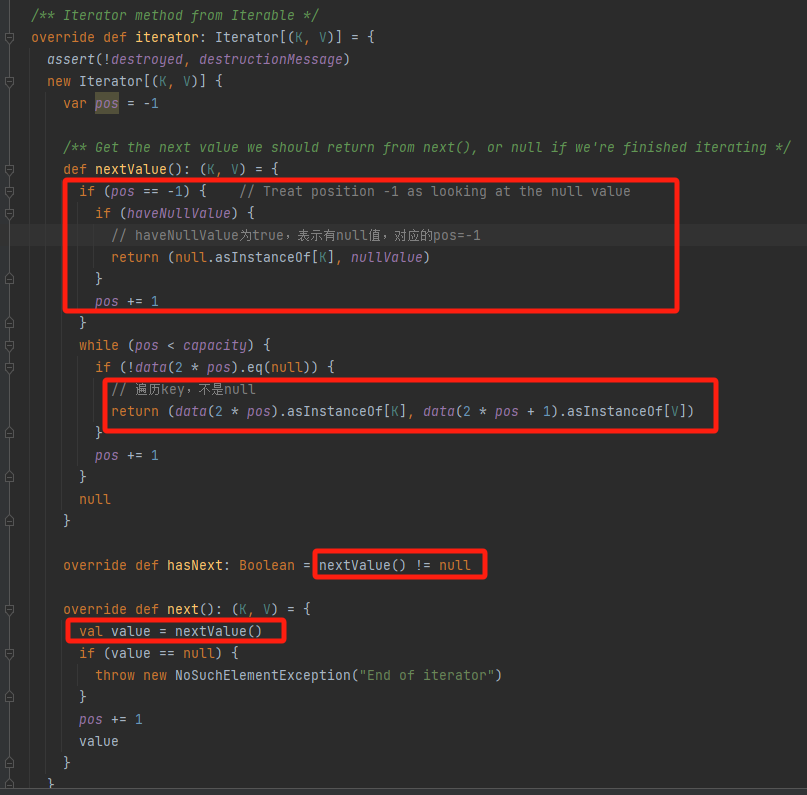
iterator
核心方法是nextValue,在nextValue中,遍历data数组的对应key值,要求不是null,表明这个位置是有值的。
如果有key为null,要求pos=-1且haveNullValue=true
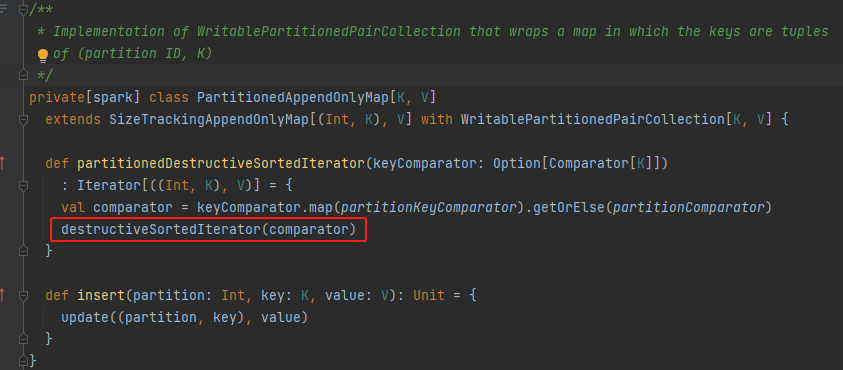
partitionedDestructiveSortedIterator
调用destructiveSortedIterator方法
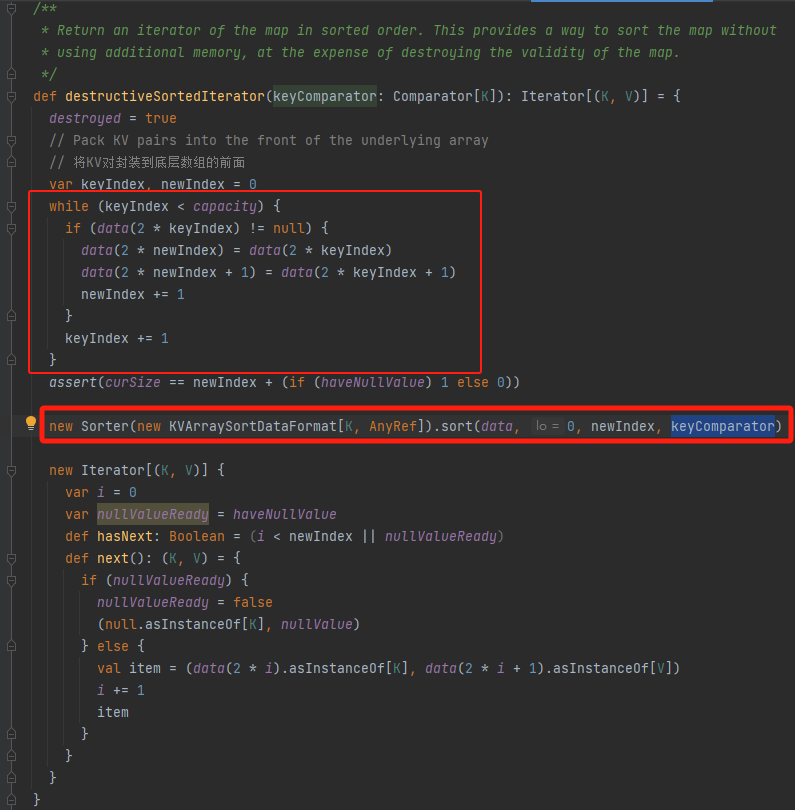
destructiveSortedIterator
data数组中元素是分散的,首先将数组中的元素都集中到数组的前面。后面就跟PartitionedPairBuffer的partitionedDestructiveSortedIterator方法一样使用TimeSort进行排序。
采样相关方法
跟上面的PartitionedPairBuffer的采样相关方法一样。
spill相关方法
入口方法是maybeSpillCollection
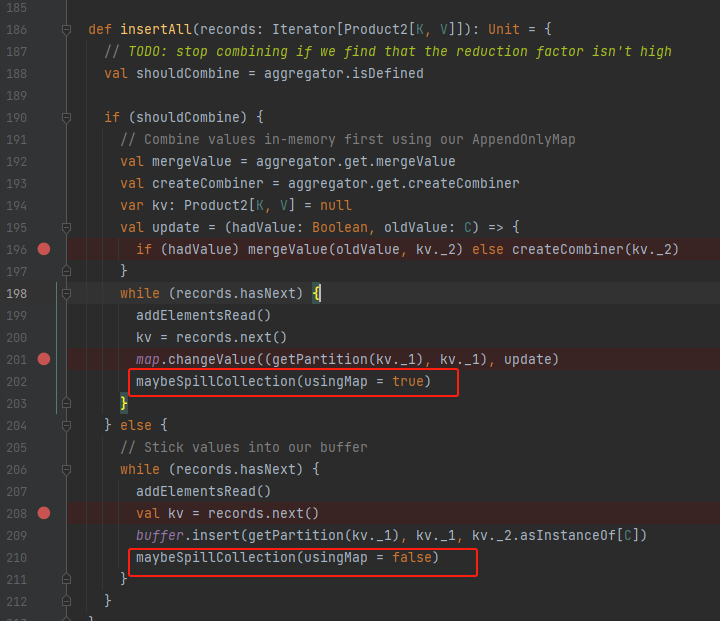
maybeSpillCollection
不论使用的数据结构是buffer还是map,都是计算消耗的容量,再调用maybeSpill方法,最后重新初始化化对应数据结构。可以想到maybeSpill中就将缓存的数据放到了本地。
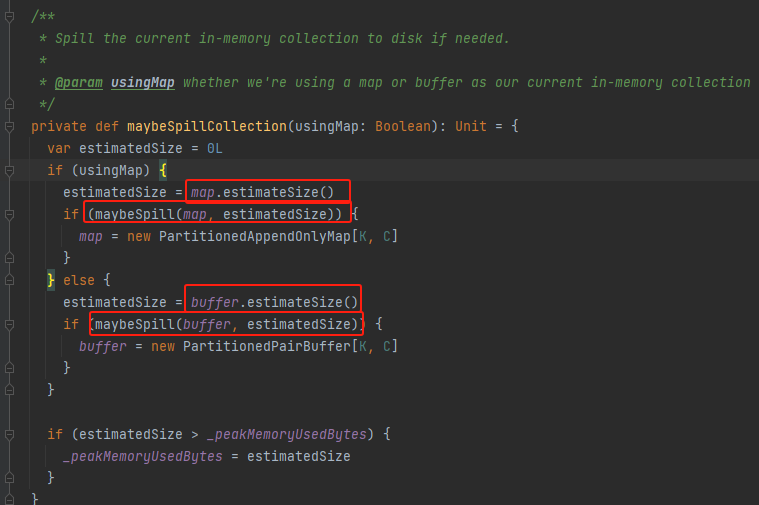
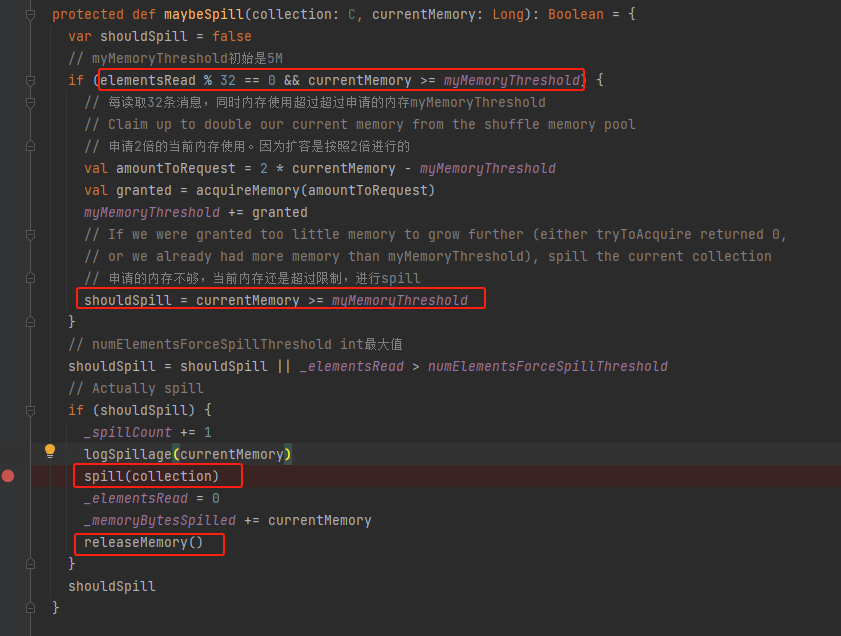
maybeSpill
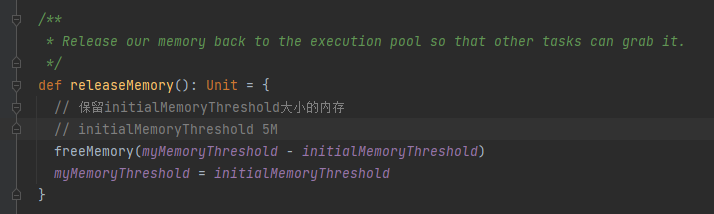
每32条数据就进行一次内存使用情况判断。如果当前使用内存超过了限制,就先申请新的内存,按照两倍的内存使用量申请,不一定申请到足量的内存。申请后还是内存使用超过了限制,就进行spill,调用spill方法,同时调用releaseMemory释放内存。
releaseMemory
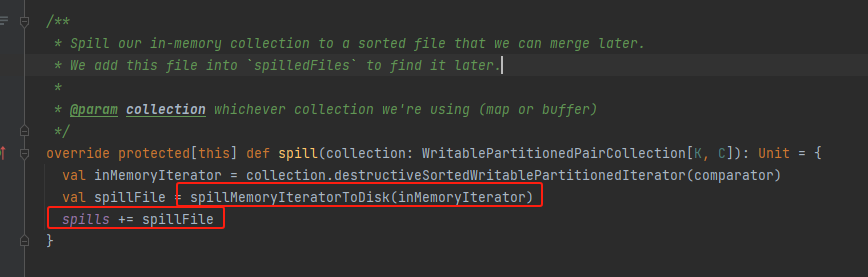
spill
调用destructiveSortedWritablePartitionedIterator方法返回排好序的分区迭代器。
调用spillMemoryIteratorToDisk将数据溢写到磁盘上
最后将生成的文件记录到spills中
destructiveSortedWritablePartitionedIterator
调用对应数据结构的partitionedDestructiveSortedIterator方法返回排序的迭代器。
就是上面的PartitionedPairBuffer和PartitionedAppendOnlyMap的partitionedDestructiveSortedIterator方法。
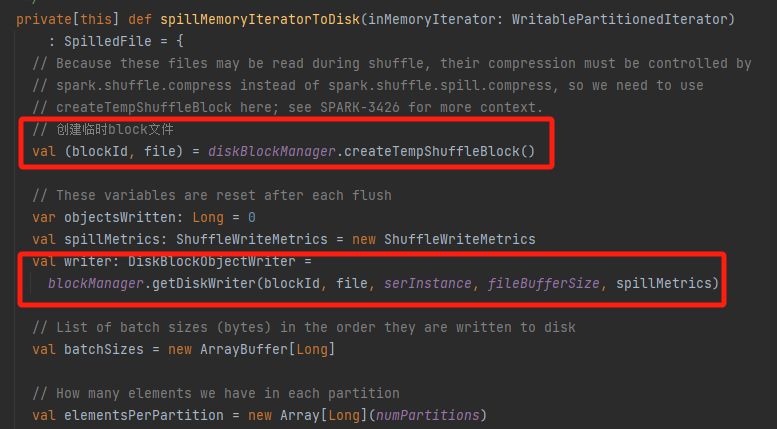
spillMemoryIteratorToDisk
创建临时文件,生成对应的writer
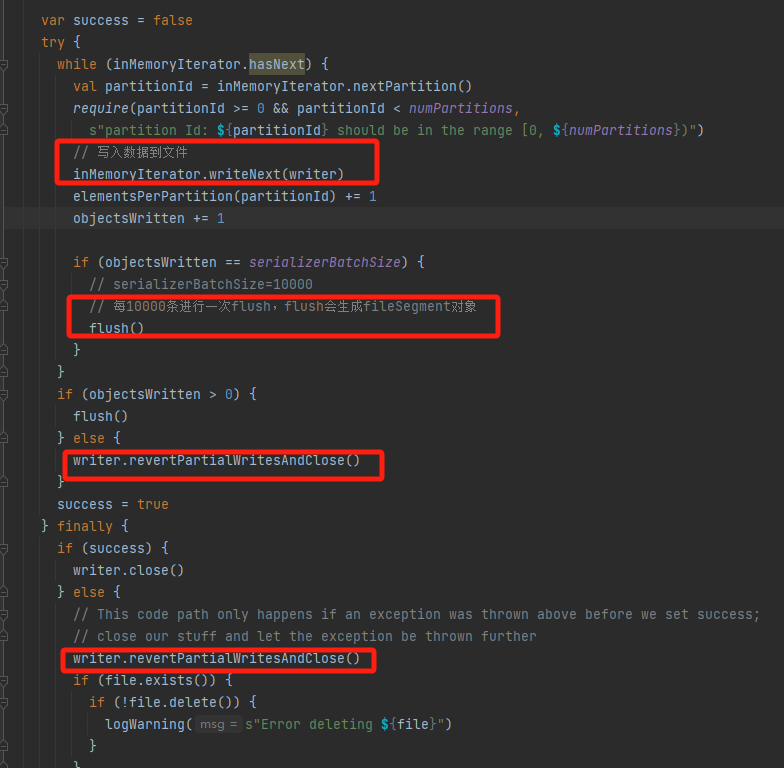
遍历将数据写入的文件中,每10000条进行一次flush。
如果失败了,调用revertPartialWritesAndClose进行回滚。
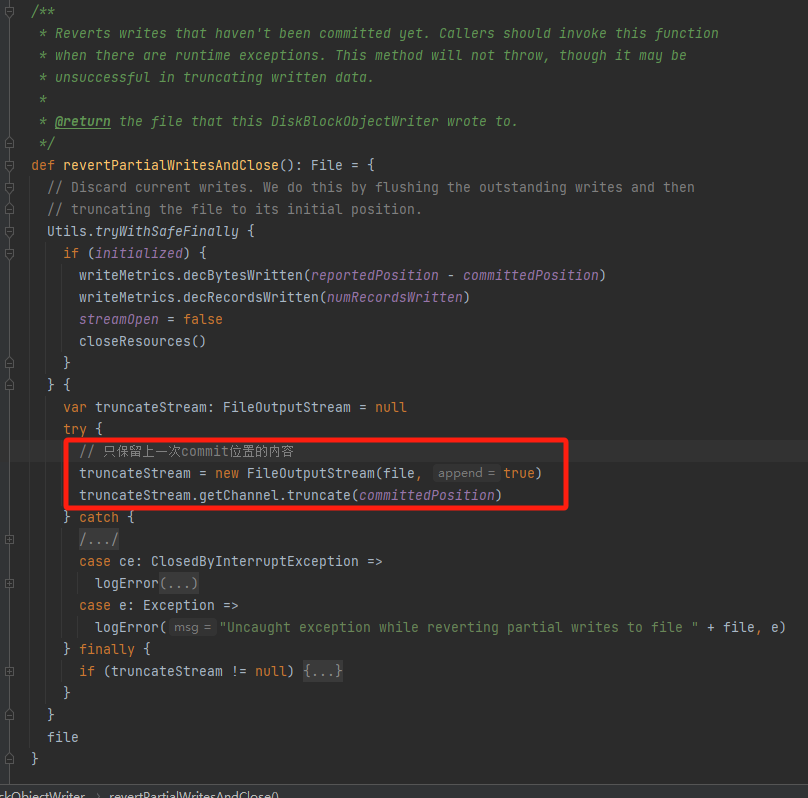
revertPartialWritesAndClose
如果这次写入出现问题,使用这个方法。回滚写入,只保留截止到上一次写入的内容。
writePartitionedMapOutput
将排好序的缓存和文件合并成一个文件输出。
spills为空,即没有产生排序文件。将缓存中数据生成排好序的迭代器,遍历写入到文件中。
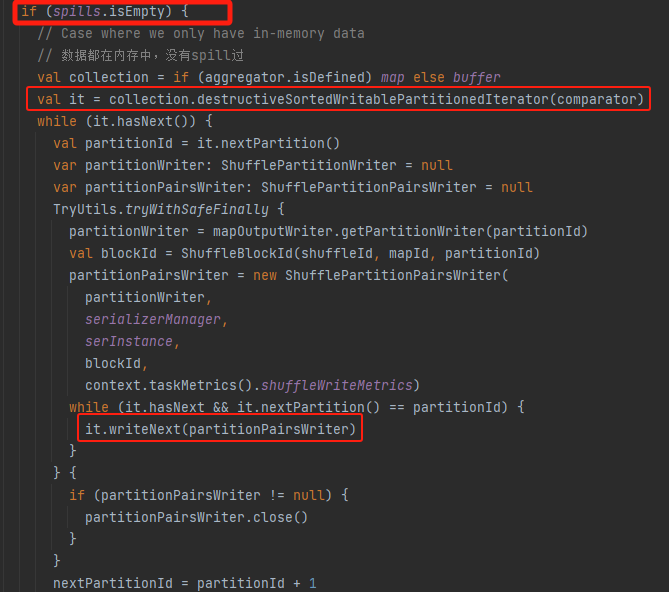
存在排好序的文件。则需要调用partitionedIterator方法将文件数据和缓存的数据进行合并,再遍历输出。
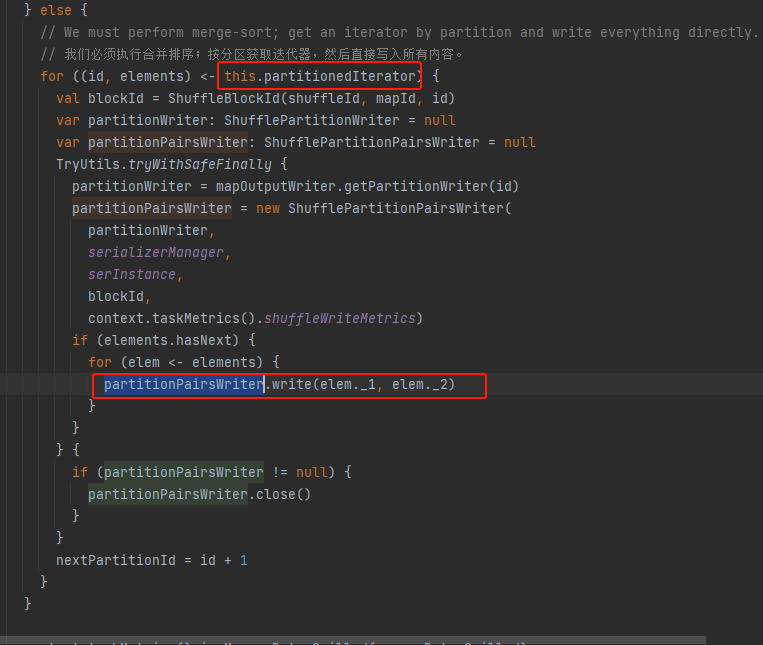
partitionedIterator
调用merge方法合并内存和文件数据
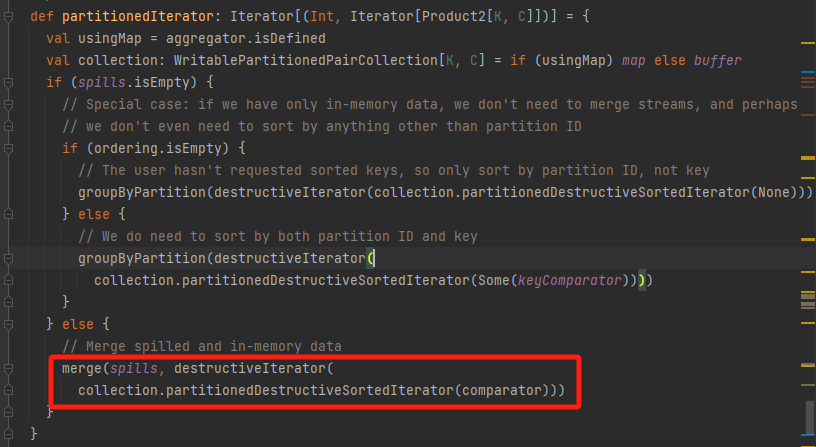
merge
merge的第一个参数是spilled文件,第二个参数是内存缓存的数据。
流程是遍历分区,取出对应分区的spilled文件中和缓存中的数据。
根据情况进行聚合或者排序等操作后输出合并后的排好序的文件。
mergeSort
使用堆排序,但是heap中存放的是已经排好序的iterator。
最小值就是heap中首个iterator中的第一个元素。
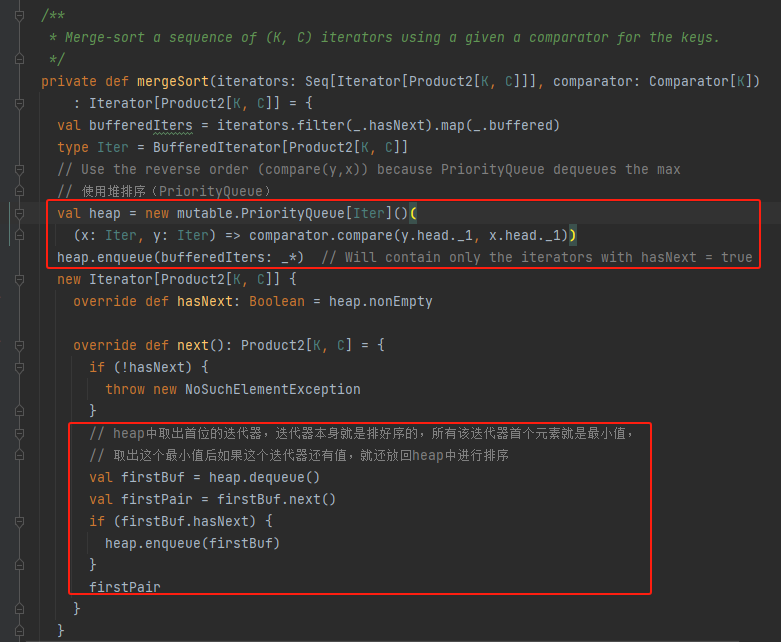
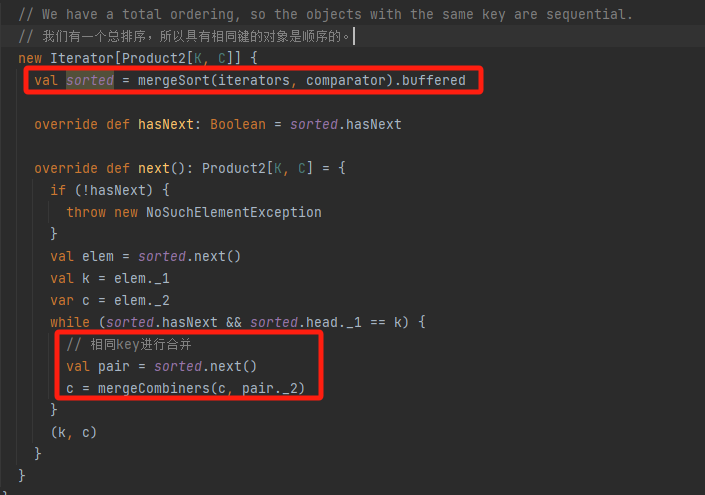
mergeWithAggregation
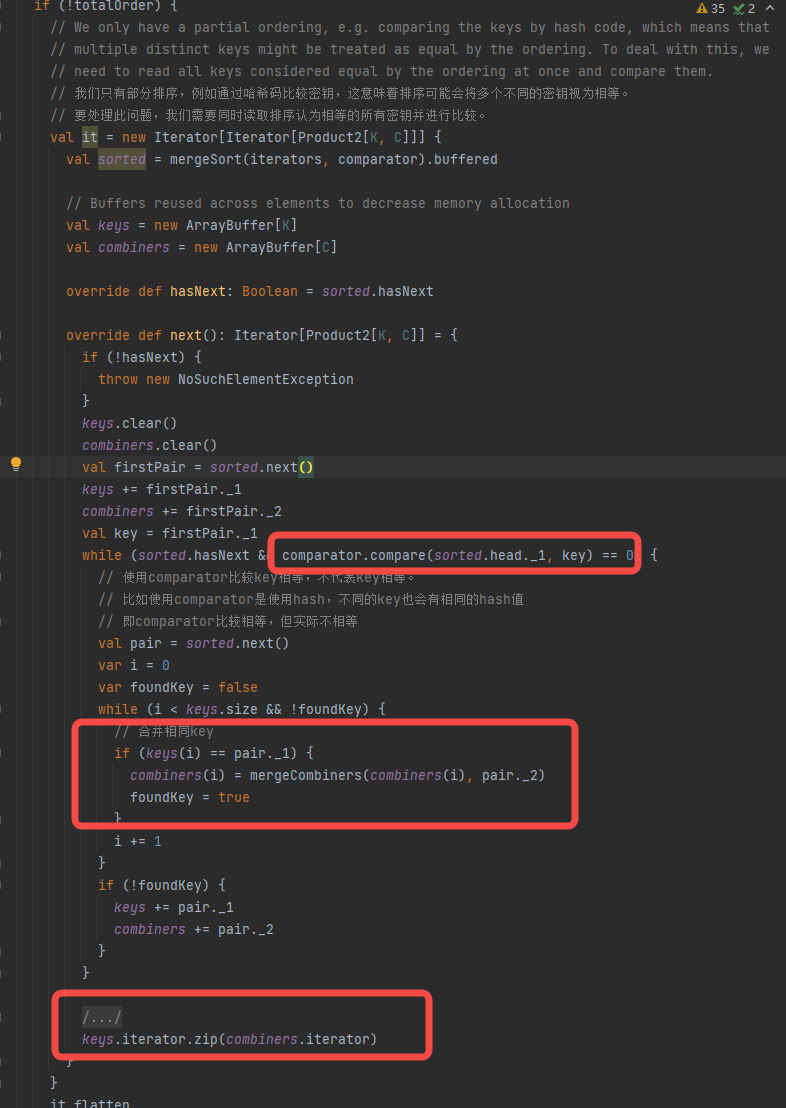
有总排序,这样相同的key会在一起。
调用mergeSort将iterators合并成一个排好序的iterator。
next方法就是遍历key出来全部的值,进行合并后输出,因为是全局有序,不需要遍历iterator全部数据。
没有总排序
跟上面流程类似,先得到合并的iterator,但是它不是全局有序的。存在不同的key在comparator比较下相等,如使用hash进行比较,因此存在 aaabaaa 这种情况的key分布。
在获取相同key对应的值的时候需要遍历iterator的使用comparator和equal进行比较数据,再进行合并。返回值是一个comparator相同有可能key不同的key组成的iterator