一、synchronized 原理
1.1 基本特点:
结合上面的锁策略,我们就可以总结出,synchronized 具有以下特性(只考虑 JDK 1.8):
-
开始时是乐观锁,如果锁冲突频繁,就转换为悲观锁。
-
开始是轻量级锁实现,如果锁被持有的时间较长,就转换成重量级锁。
-
实现轻量级锁的时候大概率用到的自旋锁策略。
-
是一种不公平锁。
-
是一种可重入锁。
-
不是读写锁。
1.2 加锁工作过程:
JVM 将 synchronized 锁分为无锁、偏向锁、轻量级锁、重量级锁状态。会根据情况,进行依次升级。
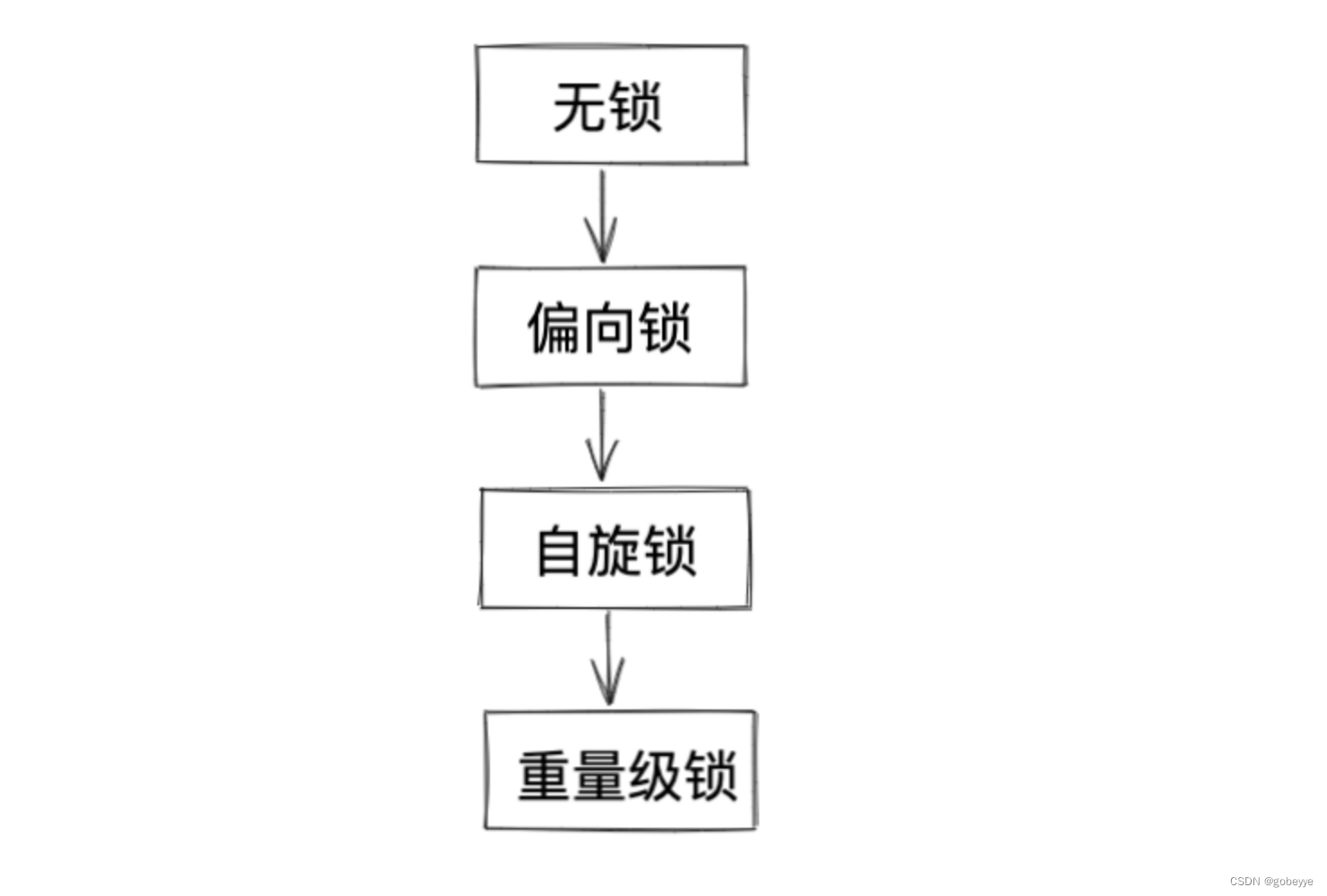
1.2.1 偏向锁:
第一个尝试加锁的线程,优先进入偏向锁状态。 偏向锁不是真的 "加锁",只是给对象头中做一个 "偏向锁的标记",记录这个锁属于哪个线程。如果后续没有其他线程来竞争该锁,那么就不用进行其他同步操作了(避免了加锁解锁的开销)。如果后续有其他线程来竞争该锁(刚才已经在锁对象中记录了当前锁属于哪个线程了,很容易识别当前申请锁的线程是不是之前记录的线程),那就取消原来的偏向锁状态,进入一般的轻量级锁状态。偏向锁本质上相当于 "延迟加锁"。能不加锁就不加锁,尽量来避免不必要的加锁开销。但是该做的标记还是得做的,否则无法区分何时需要真正加锁。
1.2.2 轻量级锁:
随着其他线程进入竞争,偏向锁状态被消除,进入轻量级锁状态(自适应的自旋锁)。此处的轻量级锁就是通过 CAS 来实现。通过 CAS 检查并更新一块内存(比如 null => 该线程引用)如果更新成功,则认为加锁成功,如果更新失败,则认为锁被占用,继续自旋式的等待(并不放弃CPU)。
自旋操作是一直让 CPU 空转,比较浪费 CPU 资源。因此此处的自旋不会一直持续进行,而是达到一定的时间 / 重试次数,就不再自旋了。也就是所谓的 "自适应" 。
1.2.3 重量级锁:
如果竞争进一步激烈,自旋不能快速获取到锁状态,就会膨胀为重量级锁。此处的重量级锁就是指用到内核提供的 mutex 。
执行加锁操作,先进入内核态,在内核态判定当前锁是否已经被占用,如果该锁没有占用,则加锁成功,并切换回用户态,如果该锁被占用,则加锁失败。此时线程进入锁的等待队列,挂起等待被操作系统唤醒。经历了一系列的沧海桑田,这个锁被其他线程释放了,操作系统也想起了这个被挂起的线程,于是唤醒这个线程,尝试重新获取锁。
1.3 锁消除:
编译器 + JVM 判断锁是否可消除。 如果可以,就直接消除。
锁消除常常运用在:有些应用程序的代码中,用到了 synchronized,但其实没有在多线程环境下。(例如 StringBuffer)
java
StringBuffer sb = new StringBuffer();
sb.append("a");
sb.append("b");
sb.append("c");
sb.append("d");此时每个 append 的调用都会涉及加锁和解锁,但如果只是在单线程中执行这个代码,那么这些加锁解锁操作是没有必要的,白白浪费了一些资源开销。
1.4 锁粗化:
一段逻辑中如果出现多次加锁解锁,编译器 + JVM 会自动进行锁的粗化。 锁粗化这里涉及一个概念粒度(不是力度):加锁的范围内,包含代码的多少,包含的代码越多,就认为锁的粒度就越粗,反之,锁的粒度就越细。
综上可以看到,synchronized 的策略是比较复杂的,在背后做了很多事情,目的为了让程序猿哪怕啥都不懂,也不至于写出特别慢的程序。JVM 开发者为了 Java 程序猿操碎了心。
1.5 面试题:
- 什么是偏向锁?
答:偏向锁不是真的加锁,而只是在锁的对象头中记录⼀个标记(记录该锁所属的线程)。如果没有其他线程参与竞争锁,那么就不会真正执行加锁操作,从而降低程序开销。⼀旦真的涉及到其他的线程竞争,再取消偏向锁状态,进入轻量级锁状态。
- synchronized 实现原理是什么?
答:刚开始是一个标记,遇到所冲突升级成轻量级锁,采用自旋锁的方式实现,随着锁冲突的升级,锁升级为重量级锁,采用挂起等待锁的方式,来实现锁。
二、JUC(java.util.concurrent)的常见类
在 java.util.concurrent 中放了和多线程相关的组件。
2.1 Callable 接口:
Callable 是⼀个接口,相当于把线程封装了⼀个 "返回值"。方便程序猿借助多线程的方式计算结果。可以认为是一个带返回参数的 runnable 。里面要重写的方法是 call( )。
- 理解 Callable 和 FutureTask:
Callable 和 Runnable 相对,都是描述一个 "任务"。Callable 描述的是带有返回值的任务,Runnable
描述的是不带返回值的任务。Callable 通常需要搭配 FutureTask 来使用 FutureTask 用来保存 Callable 的返回结果。因为 Callable 往往是在另⼀个线程中执行的,啥时候执行完并不确定。FutureTask 就可以负责这个等待结果出来的工作(如果在 futureTask.get()线程还没执行完毕就会阻塞等待)。
FutureTask 可以直接传入 Thread 的构造方法当中,于是我们掌握的 Thread 的构造方式又多了一种。
我们可以将它们的关系理解成吃麻辣烫的情形:去吃麻辣烫,Callable 就是菜篮,重写的 call 方法里面就是点的菜,当餐点好后,前台会给你一张 "小票" ,后厨开始工作(Thread 启动)。这个小票就是 FutureTask,后面我们可以随时凭这张小票去查看自己的这份麻辣烫做出来了没有(线程是否执行完毕)。
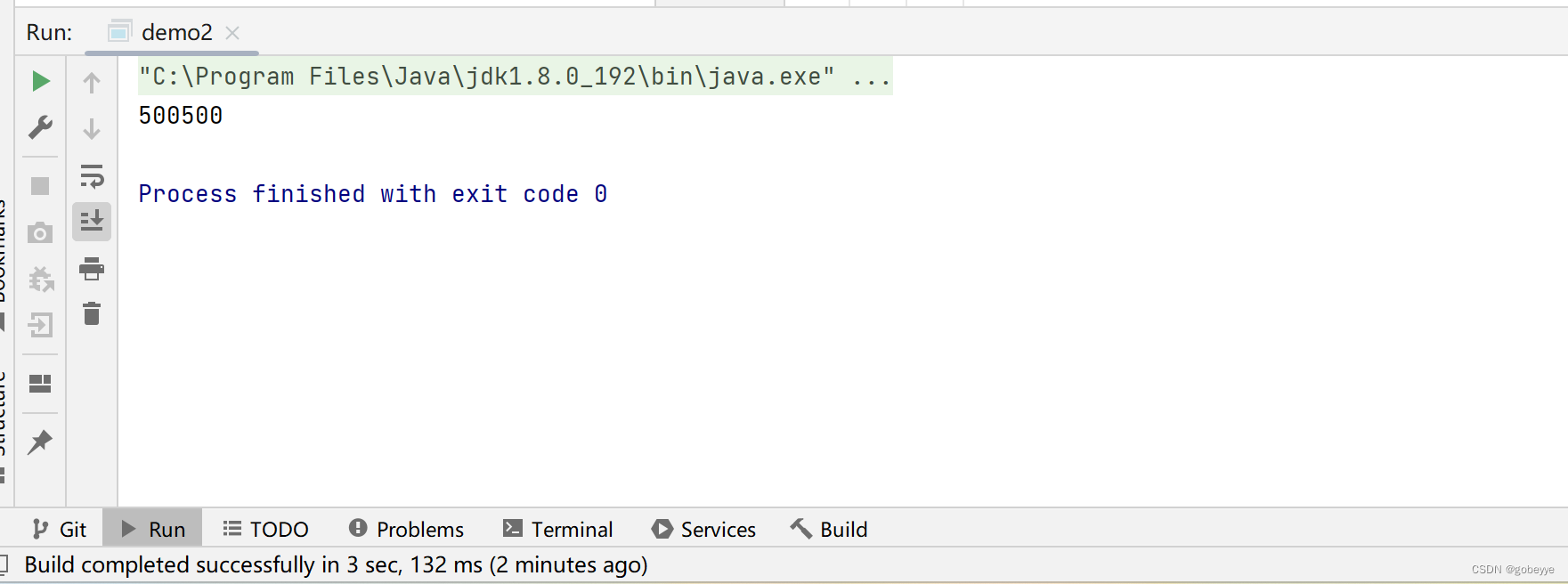
演示案例:创建线程计算 1 + 2 + 3 + ... + 1000,使用 Callable 版本。
java
import java.util.concurrent.*;
public class demo2 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Callable<Integer> callable = new Callable<Integer>() {//菜篮子
int result = 0;
@Override
public Integer call() throws Exception {//菜
for(int i = 1;i <= 1000;i++){
result += i;
}
return result;
}
};
FutureTask<Integer> futureTask = new FutureTask<>(callable);//小票
Thread t1 = new Thread(futureTask);//后厨
t1.start();//后厨开始工作
t1.join();
System.out.println(futureTask.get());//小票取餐
}
}案例演示效果如下:
2.2 ReentrantLock:
顾名思义:可重入互斥锁和 synchronized 定位类似,都是用来实现互斥效果,保证线程安全。
- ReentrantLock 的用法:
- lock():加锁,如果获取不到锁就死等。
- trylock(超时时间):加锁,如果获取不到锁,等待⼀定的时间之后就放弃加锁。
- unlock():解锁。
随着版本的升级 synchronized 越来越好用了,ReentrantLock 就渐渐的用的少了,但是这里我们还是要学习,就说明其相对于 synchronized 有着一些特有的优势:
- ReentrantLock 与 synchronized 的区别:
- synchronized 是一个关键字,是 JVM 内部实现的(大概率是基于 C++ 实现)。ReentrantLock 是标准库的一个类,在 JVM 外实现的(基于 Java 实现)。
- synchronized 使用时不需要手动释放锁。ReentrantLock 使用时需要手动释放,使用起来更灵活但是也容易遗漏 unlock。
- synchronized 在申请锁失败时,会死等。ReentrantLock 可以通过 trylock 的方式等待一段时间就放弃。
- synchronized 是非公平锁,ReentrantLock 默认是非公平锁,可以通过构造方法传入一个 true 开启公平锁模式。
- 更强大的唤醒机制。synchronized 是通过 Object类 的 wait / notify 实现等待-唤醒。每次唤醒的是一个随机等待的线程。ReentrantLock 搭配 Condition 类实现等待-唤醒,可以更精确控制唤醒某个指定的线程。
如何选择使用哪个锁?
- 锁竞争不激烈的时候,使用 synchronized,效率更高,自动释放更方便。
- 锁竞争激烈的时候,使用 ReentrantLock,搭配 trylock 更灵活控制加锁的行为,而不是死等。
- 如果需要使用公平锁,使用 ReentrantLock。
2.3 原子类:
原子类内部用的是 CAS 实现,所以性能要比加锁实现 i++ 高很多。原子类有以下几个:

由于此模块在上一章多线程进阶(1)的 CAS 的应用中已经详细解释,这里就不再赘述。
2.4 Semaphore 信号量:
信号量,用来表示 "可用资源的个数"。本质上就是一个计数器。
- 理解信号量:
可以把信号量想象成是停车场的展示牌:当前有车位 100 个。表示有 100个可用资源。当有车开进去的时候,就相当于申请一个可用资源,可用车位就 -1(这个称为信号量的 P操作)当有车开出来的时候,就相当于释放一个可用资源,可用车位就 +1(这个称为信号量的 V 操作)如果计数器的值已经为 0了,还尝试申请资源,就会阻塞等待,直到有其他线程释放资源。
Semaphore 的 PV 操作中的加减计数器操作都是原子的,可以在多线程环境下直接使用。
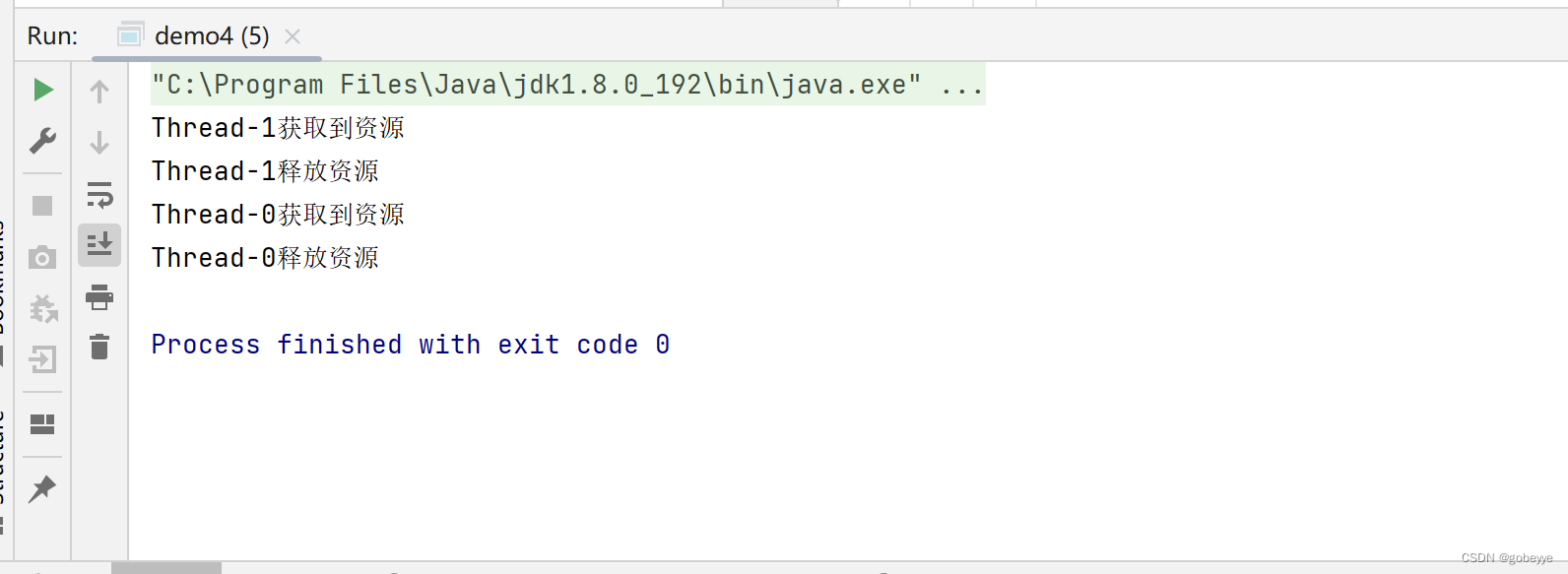
- 代码案例演示:
java
import java.util.concurrent.*;
public class demo4 {
public static void main(String[] args) {
Semaphore semaphore = new Semaphore(1);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
semaphore.acquire();
System.out.println(Thread.currentThread().getName() + "获取到资源");
} catch (InterruptedException e) {
throw new RuntimeException(e);
};
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "释放资源");
semaphore.release();
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();t2.start();
}
}- 案例演示结果如下:
只有在资源还有剩余的情况下进行 acquire 才不会进行阻塞。
在信号量为 1 是可以将其当作锁来使用。锁可以看成是 semaphore 的特例。
2.5 CountDownLatch:
同时等待 N 个任务执行结束。
当我们把一个任务拆分成很多个的时候,可以通过这个工具类来识别任务是否整体执行完毕了。
使用过程:构造 CountDownLatch 实例,初始化 10 表示有 10 个任务需要完成。每个任务执行完毕,都调用 latch.countDown() 。在 CountDownLatch 内部的计数器同时自减,主线程中使用latch.await();阻塞等待。所有任务执行完毕,相当于计数器为 0 了,解除阻塞。好处是如果是多个线程不用写多个 join()。
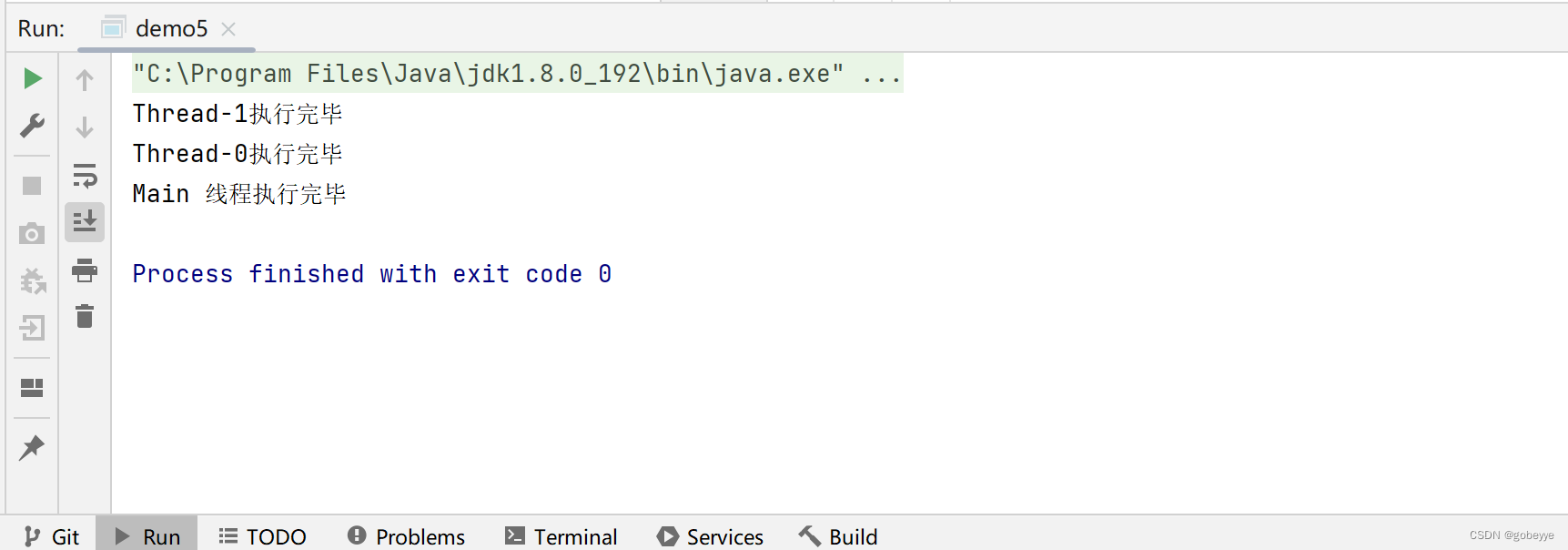
案例演示:
java
import java.util.concurrent.CountDownLatch;
public class demo5 {
public static void main(String[] args) throws InterruptedException {
CountDownLatch latch = new CountDownLatch(2);
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "执行完毕");
latch.countDown();
}
};
Thread t1 = new Thread(runnable);
Thread t2 = new Thread(runnable);
t1.start();t2.start();
latch.await();
System.out.println("Main 线程执行完毕");
}
}效果如下:
Main 线程会等待 Thread 1,2 执行完毕后,再继续执行。
三、线程安全的集合类
原来的集合类,大部分都不是线程安全的。(Vector,Stack,HashTable,是线程安全的(不建议用),其他的集合类不是线程安全的)。
3.1 多线程环境使用 ArrayList:
-
自己使用同步机制(synchronized 或者 ReentrantLock)
-
Collections.synchronizedList(new ArrayList):synchronizedList 是标准库提供的一个基于 synchronized 进行线程同步的 List.synchronizedList 的关键操作上都带有 synchronized。
-
使用 CopyOnWriteArrayList :当我们往一个容器中添加元素的时候,不直接往当前容器添加,而是先将当前容器进行 Copy,复制出一个新的容器,然后在新的容器里面添加元素,添加完元素之后,再将原容器的引用指向新的容器。
这样做的好处是我们可以对 CopyOnWrite 容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以 CopyOnWrite 容器也是一种读写分离的思想,读和写不同的容器。
优点:在读多写少的场景下,性能很高,不需要加锁竞争。
缺点:1. 占用内存较多。2. 新写的数据不能被第一时间读取到。
3.2 多线程环境使用队列:
-
ArrayBlockingQueue:基于数组实现的阻塞队列。
-
LinkedBlockingQueue:基于链表实现的阻塞队列。
-
PriorityBlockingQueue:基于堆实现的带优先级的阻塞队列。
-
TransferQueue:最多只包含一个元素的阻塞队列。
3.3 多线程环境使用哈希表:
HashMap 本身不是线程安全的。在多线程环境下使用哈希表可以使用:Hashtable(不推荐使用),ConcurrentHashMap(推荐使用这个)。
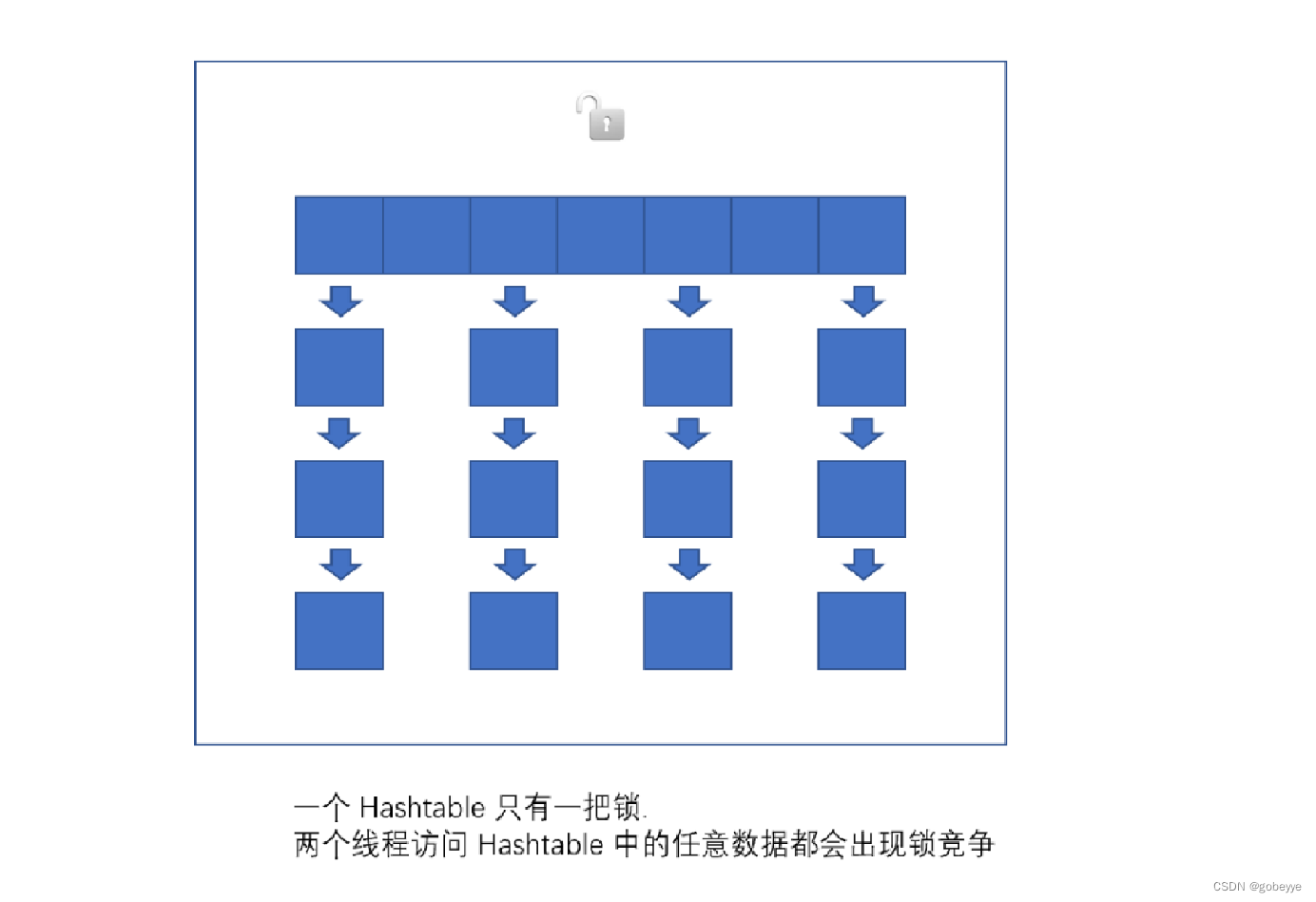
3.3.1 Hashtable:
只是简单的把关键方法加上了 synchronized 关键字。

这相当于直接针对 Hashtable 对象本省加锁。不推荐使用这个的原因如下:
如果多线程访问同⼀个 Hashtable 就会直接造成锁冲突(冲突率太高了)。
size 属性也是通过 synchronized 来控制同步,也是比较慢的。
⼀旦触发扩容,就由该线程完成整个扩容过程。这个过程会涉及到大量的元素拷贝,效率会非常低。
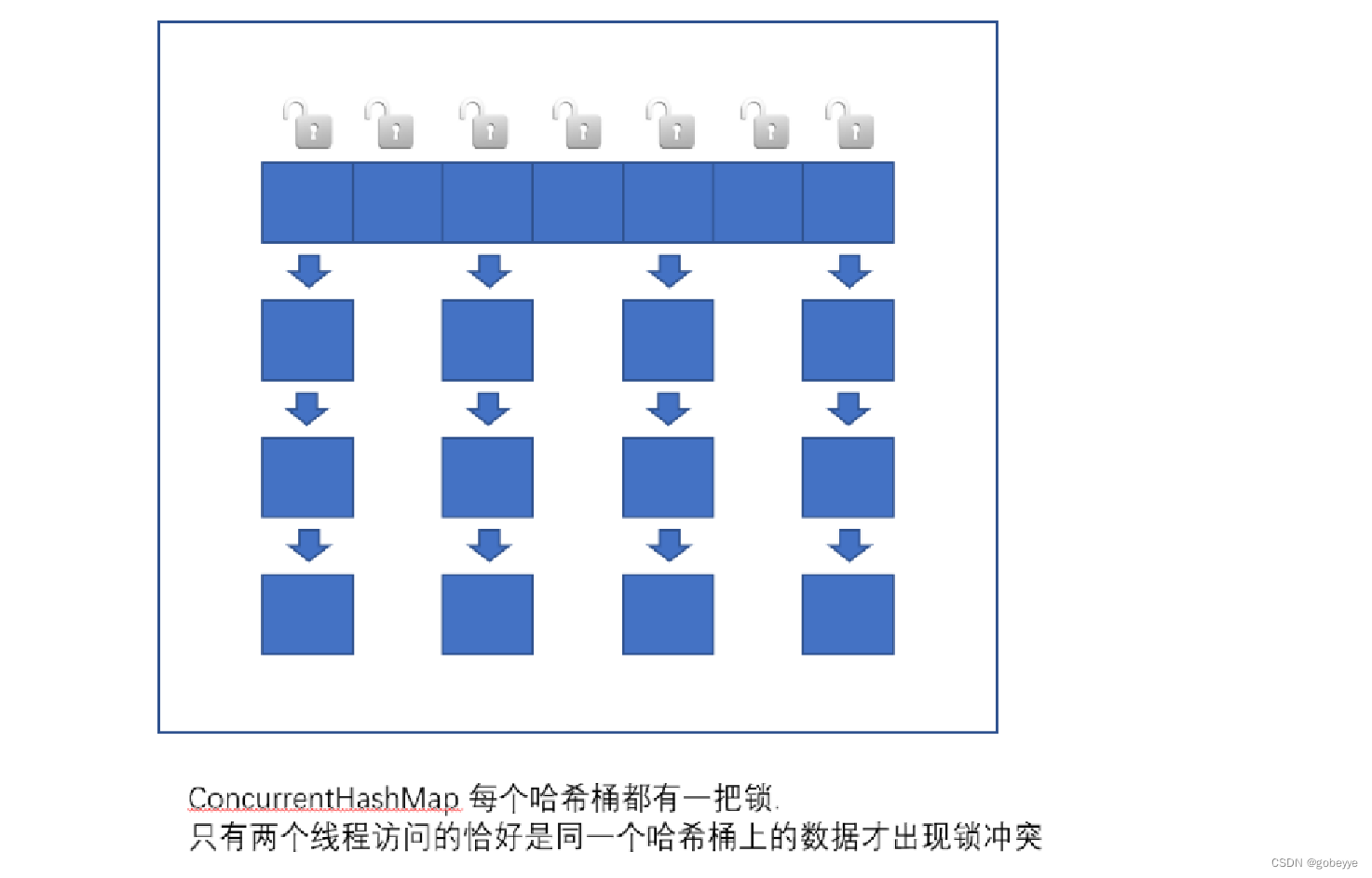
3.3.2 ConcurrentHashMap:
相比于 Hashtable 做出了一系列的改进和优化。以 Java1.8 为例:
读操作没有加锁(但是使用了 volatile 保证从内存读取结果),只对写操作进行加锁,加锁的方式仍然是用 synchronized,但不是锁整个对象,而是 "锁桶" (用每个链表的头结点作为锁对象))大大降低了锁冲突的概率。
充分利用 CAS 特性。比如 size 属性通过 CAS 来更新。避免出现重量级锁的情况。
优化了扩容方式:化整为零。
发现需要扩容的线程,只需要创建⼀个新的数组,同时只搬几个元素过去。扩容期间,新老数组同时存在。后续每个来操作 ConcurrentHashMap 的线程,都会参与搬家的过程。每个操作负责搬运一小部分元素。搬完最后一个元素再把老数组删掉。这个期间,插入只往新数组中加。这个期间,查找需要同时查新数组和老数组。
结语:
其实写博客不仅仅是为了教大家,同时这也有利于我巩固知识点,和做一个学习的总结,由于作者水平有限,对文章有任何问题还请指出,非常感谢。如果大家有所收获的话还请不要吝啬你们的点赞收藏和关注,这可以激励我写出更加优秀的文章。
