一、思路
Prometheus监控Etcd集群,是没有对应的exporter,而 由CoreOS公司开发的Operator,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统,可以实现监控etcd。
用自定义的方式来对 Kubernetes 集群进行监控,但是还是有一些缺陷,比如 Prometheus、AlertManager 这些组件服务本身的高可用,当然我们也完全可以用自定义的方式来实现这些需求,我们也知道 Prometheus 在代码上就已经对 Kubernetes 有了原生的支持,可以通过服务发现的形式来自动监控集群,因此我们可以使用另外一种更加高级的方式来部署 Prometheus:Operator 框架。
安装方法:
第一步 安装 Prometheus Operator
第二步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第三步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第四步确保 Service 对象可以正确获取到 metrics 数据
二、安装 Prometheus Operator
Operator是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识,比如创建一个数据库的Operator,则必须对创建的数据库的各种运维方式非常了解,创建Operator的关键是CRD(自定义资源)的设计。
CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在YAML文件里定义的那些spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
- 资源:对象的状态定义
- 控制器:观测、分析和行动,以调节资源的分布
当然我们如果有对应的需求也完全可以自己去实现一个Operator,接下来我们就来给大家详细介绍下Prometheus-Operator的使用方法。
介绍
首先我们先来了解下Prometheus-Operator的架构图:
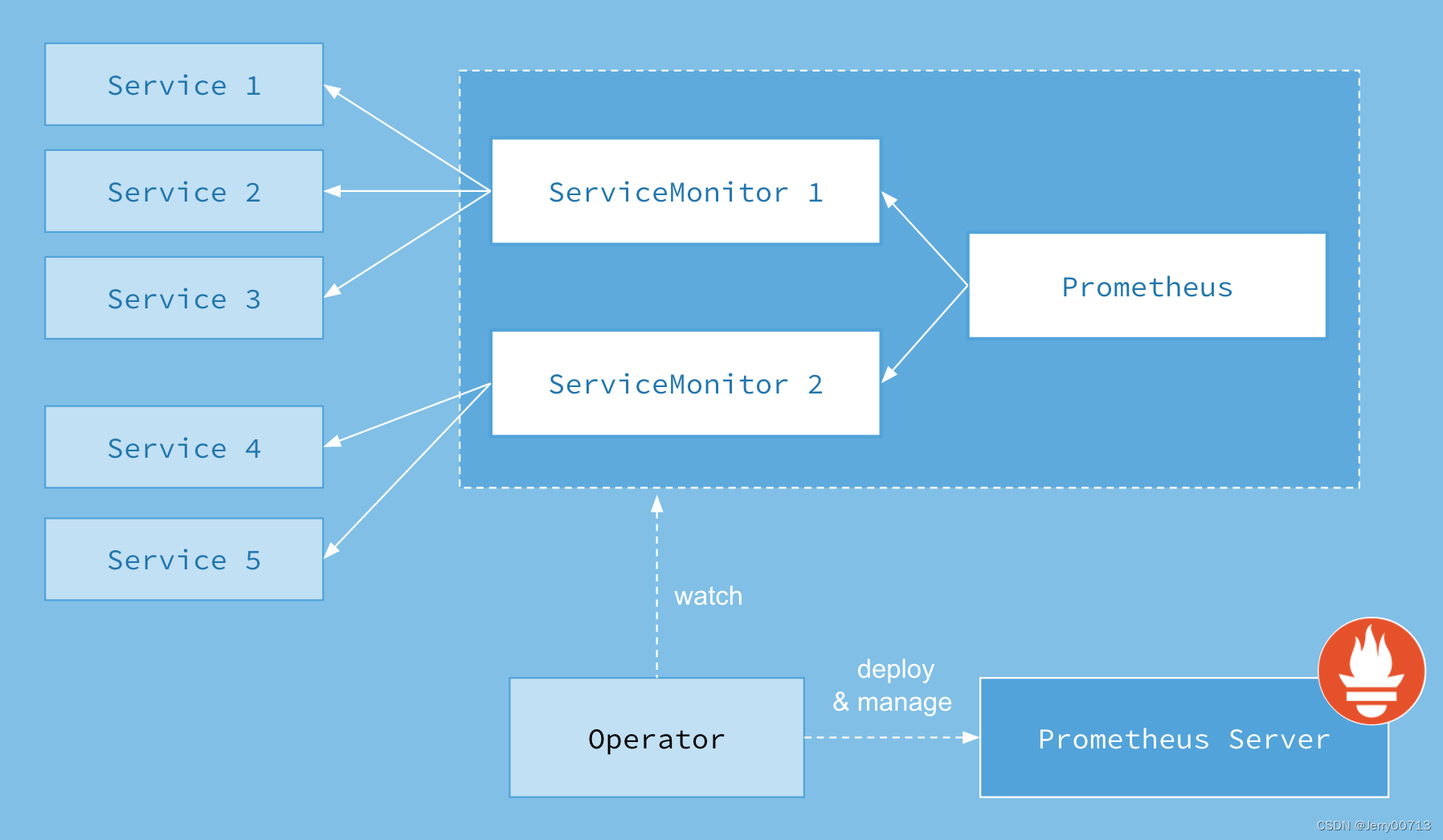
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter前面我们已经学习了,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
安装
我们这里直接通过 Prometheus-Operator 的源码来进行安装,当然也可以用 Helm 来进行一键安装,我们采用源码安装可以去了解更多的实现细节。首页将源码 Clone 下来:GitHub - prometheus-operator/prometheus-operator: Prometheus Operator creates/configures/manages Prometheus clusters atop Kubernetes
注意版本,由于我的k8s是1.21,所以选择了release-0.9

$ git clone https://github.com/coreos/kube-prometheus.git
$ cd manifests
$ ls
00namespace-namespace.yaml node-exporter-clusterRole.yaml
0prometheus-operator-0alertmanagerCustomResourceDefinition.yaml node-exporter-daemonset.yaml
......最新的版本官方将资源prometheus-operator/contrib/kube-prometheus at main · prometheus-operator/prometheus-operator · GitHub迁移到了独立的 git 仓库中:GitHub - prometheus-operator/kube-prometheus: Use Prometheus to monitor Kubernetes and applications running on Kubernetes
注意,老版本中进入到 manifests 目录下面,这个目录下面包含我们所有的资源清单文件, prometheus-serviceMonitorKubelet.yaml 默认情况下,这个 ServiceMonitor 是关联的 kubelet 的10250端口去采集的节点数据,如果这个 metrics 数据已经迁移到其他只读端口上面去了,数据已经迁移到10255这个只读端口上面去了,我们只需要将文件中的https-metrics更改成http-metrics即可,这个在 Prometheus-Operator 对节点端点同步的代码中有相关定义,感兴趣的可以点此查看完整代码:
Subsets: []v1.EndpointSubset{
{
Ports: []v1.EndpointPort{
{
Name: "https-metrics",
Port: 10250,
},
{
Name: "http-metrics",
Port: 10255,
},
{
Name: "cadvisor",
Port: 4194,
},
},
},
},正式部署:
[root@master prometheus-operator]# kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready control-plane,master 514d v1.21.1
slave01 Ready <none> 513d v1.21.1
slave02 Ready <none> 513d v1.21.1
unzip kube-prometheus-release-0.9.zip
cd kube-prometheus-release-0.9/
注意,一定先部署manifests/setup,否则会如下错误
[root@master kube-prometheus-release-0.8]# kubectl create -f manifests/setup
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
service/prometheus-operator created
serviceaccount/prometheus-operator created
[root@master kube-prometheus-release-0.8]# kubectl get pod -A -owide -n monitoring
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
monitoring prometheus-operator-7775c66ccf-mwtx6 2/2 Running 0 54s 172.7.1.36 slave01 <none> <none>root@master kube-prometheus-release-0.8# kubectl create -f manifests/
alertmanager.monitoring.coreos.com/main created
Warning: policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
poddisruptionbudget.policy/alertmanager-main created
prometheusrule.monitoring.coreos.com/alertmanager-main-rules created
secret/alertmanager-main created
service/alertmanager-main created
serviceaccount/alertmanager-main created
servicemonitor.monitoring.coreos.com/alertmanager created
clusterrole.rbac.authorization.k8s.io/blackbox-exporter created
clusterrolebinding.rbac.authorization.k8s.io/blackbox-exporter created
configmap/blackbox-exporter-configuration created
deployment.apps/blackbox-exporter created
service/blackbox-exporter created
serviceaccount/blackbox-exporter created
servicemonitor.monitoring.coreos.com/blackbox-exporter created
secret/grafana-datasources created
configmap/grafana-dashboard-apiserver created
configmap/grafana-dashboard-cluster-total created
configmap/grafana-dashboard-controller-manager created
configmap/grafana-dashboard-k8s-resources-cluster created
configmap/grafana-dashboard-k8s-resources-namespace created
configmap/grafana-dashboard-k8s-resources-node created
configmap/grafana-dashboard-k8s-resources-pod created
configmap/grafana-dashboard-k8s-resources-workload created
configmap/grafana-dashboard-k8s-resources-workloads-namespace created
configmap/grafana-dashboard-kubelet created
configmap/grafana-dashboard-namespace-by-pod created
configmap/grafana-dashboard-namespace-by-workload created
configmap/grafana-dashboard-node-cluster-rsrc-use created
configmap/grafana-dashboard-node-rsrc-use created
configmap/grafana-dashboard-nodes created
configmap/grafana-dashboard-persistentvolumesusage created
configmap/grafana-dashboard-pod-total created
configmap/grafana-dashboard-prometheus-remote-write created
configmap/grafana-dashboard-prometheus created
configmap/grafana-dashboard-proxy created
configmap/grafana-dashboard-scheduler created
configmap/grafana-dashboard-statefulset created
configmap/grafana-dashboard-workload-total created
configmap/grafana-dashboards created
deployment.apps/grafana created
service/grafana created
serviceaccount/grafana created
servicemonitor.monitoring.coreos.com/grafana created
prometheusrule.monitoring.coreos.com/kube-prometheus-rules created
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
deployment.apps/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kube-state-metrics-rules created
service/kube-state-metrics created
serviceaccount/kube-state-metrics created
servicemonitor.monitoring.coreos.com/kube-state-metrics created
prometheusrule.monitoring.coreos.com/kubernetes-monitoring-rules created
servicemonitor.monitoring.coreos.com/kube-apiserver created
servicemonitor.monitoring.coreos.com/coredns created
servicemonitor.monitoring.coreos.com/kube-controller-manager created
servicemonitor.monitoring.coreos.com/kube-scheduler created
servicemonitor.monitoring.coreos.com/kubelet created
clusterrole.rbac.authorization.k8s.io/node-exporter created
clusterrolebinding.rbac.authorization.k8s.io/node-exporter created
daemonset.apps/node-exporter created
prometheusrule.monitoring.coreos.com/node-exporter-rules created
service/node-exporter created
serviceaccount/node-exporter created
servicemonitor.monitoring.coreos.com/node-exporter created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
clusterrole.rbac.authorization.k8s.io/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-adapter created
clusterrolebinding.rbac.authorization.k8s.io/resource-metrics:system:auth-delegator created
clusterrole.rbac.authorization.k8s.io/resource-metrics-server-resources created
configmap/adapter-config created
deployment.apps/prometheus-adapter created
poddisruptionbudget.policy/prometheus-adapter created
rolebinding.rbac.authorization.k8s.io/resource-metrics-auth-reader created
service/prometheus-adapter created
serviceaccount/prometheus-adapter created
servicemonitor.monitoring.coreos.com/prometheus-adapter created
clusterrole.rbac.authorization.k8s.io/prometheus-k8s created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-k8s created
prometheusrule.monitoring.coreos.com/prometheus-operator-rules created
servicemonitor.monitoring.coreos.com/prometheus-operator created
poddisruptionbudget.policy/prometheus-k8s created
prometheus.monitoring.coreos.com/k8s created
prometheusrule.monitoring.coreos.com/prometheus-k8s-prometheus-rules created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s-config created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
rolebinding.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s-config created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
role.rbac.authorization.k8s.io/prometheus-k8s created
service/prometheus-k8s created
serviceaccount/prometheus-k8s created
servicemonitor.monitoring.coreos.com/prometheus-k8s created部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建8个 CRD 资源对象:
[root@master kube-prometheus-release-0.8]# kubectl get crd |grep coreos
alertmanagerconfigs.monitoring.coreos.com 2024-06-28T17:03:27Z
alertmanagers.monitoring.coreos.com 2024-06-28T17:03:27Z
podmonitors.monitoring.coreos.com 2024-06-28T17:03:27Z
probes.monitoring.coreos.com 2024-06-28T17:03:27Z
prometheuses.monitoring.coreos.com 2024-06-28T17:03:27Z
prometheusrules.monitoring.coreos.com 2024-06-28T17:03:27Z
servicemonitors.monitoring.coreos.com 2024-06-28T17:03:28Z
thanosrulers.monitoring.coreos.com 2024-06-28T17:03:28Z可以在 monitoring 命名空间下面查看所有的 Pod,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的:
[root@master kube-prometheus-release-0.8]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 12m
alertmanager-main-1 2/2 Running 0 12m
alertmanager-main-2 2/2 Running 0 12m
blackbox-exporter-55c457d5fb-wn54c 3/3 Running 0 12m
grafana-6dd5b5f65-7j675 1/1 Running 0 12m
kube-state-metrics-76f6cb7996-bsdvz 3/3 Running 0 12m
node-exporter-db24s 2/2 Running 0 12m
node-exporter-k2xd9 2/2 Running 0 12m
node-exporter-kblxs 2/2 Running 0 12m
prometheus-adapter-59df95d9f5-5r2gw 1/1 Running 0 12m
prometheus-adapter-59df95d9f5-6f449 1/1 Running 0 12m
prometheus-k8s-0 2/2 Running 1 12m
prometheus-k8s-1 2/2 Running 1 12m
prometheus-operator-7775c66ccf-mwtx6 2/2 Running 0 14m查看创建的 Service:
[root@master kube-prometheus-release-0.8]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.101.163.190 <none> 9093/TCP 21m
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 21m
blackbox-exporter ClusterIP 10.107.221.88 <none> 9115/TCP,19115/TCP 21m
grafana ClusterIP 10.109.100.129 <none> 3000/TCP 21m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 21m
node-exporter ClusterIP None <none> 9100/TCP 21m
prometheus-adapter ClusterIP 10.108.203.228 <none> 443/TCP 21m
prometheus-k8s ClusterIP 10.104.101.86 <none> 9090/TCP 21m
prometheus-operated ClusterIP None <none> 9090/TCP 21m
prometheus-operator ClusterIP None <none> 8443/TCP 23m可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service,我们这里为了简单,直接使用 NodePort 类型的服务即可,编辑 grafana 和 prometheus-k8s 这两个 Service,将服务类型更改为 NodePort:
$ kubectl edit svc grafana -n monitoring
$ kubectl edit svc prometheus-k8s -n monitoring
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.98.191.31 <none> 3000:32333/TCP 23h
prometheus-k8s NodePort 10.107.105.53 <none> 9090:30166/TCP 23h或者通过ingress方式也行,这里就不多过解释
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: prometheus-k8s
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: prometheus-k8s.od.com
http:
paths:
- backend:
service:
name: prometheus-k8s
port:
number: 9090
path: /
pathType: Prefix配置grafana
[root@master ~]# kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.98.97.216 <none> 9093/TCP 156m
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 156m
blackbox-exporter ClusterIP 10.109.140.175 <none> 9115/TCP,19115/TCP 156m
grafana ClusterIP 10.111.120.8 <none> 3000/TCP 156m
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 156m
node-exporter ClusterIP None <none> 9100/TCP 156m
prometheus-adapter ClusterIP 10.97.255.204 <none> 443/TCP 156m
prometheus-k8s ClusterIP 10.100.253.0 <none> 9090/TCP 156m
prometheus-operated ClusterIP None <none> 9090/TCP 156m
prometheus-operator ClusterIP None <none> 8443/TCP 158m
[root@master ~]# curl 10.111.120.8:3000
<a href="/login">Found</a>.
[root@master ~]# vi ingress.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: grafana-k8s
namespace: monitoring
spec:
ingressClassName: nginx
rules:
- host: grafana-k8s.od.com
http:
paths:
- backend:
service:
name: grafana
port:
number: 3000
path: /
pathType: Prefix
[root@master ~]# kubectl apply -f ingress.yaml
ingress.networking.k8s.io/grafana-k8s created
访问Prometheus
可以发现Prometheus Operator已经给我们监控了好多服务
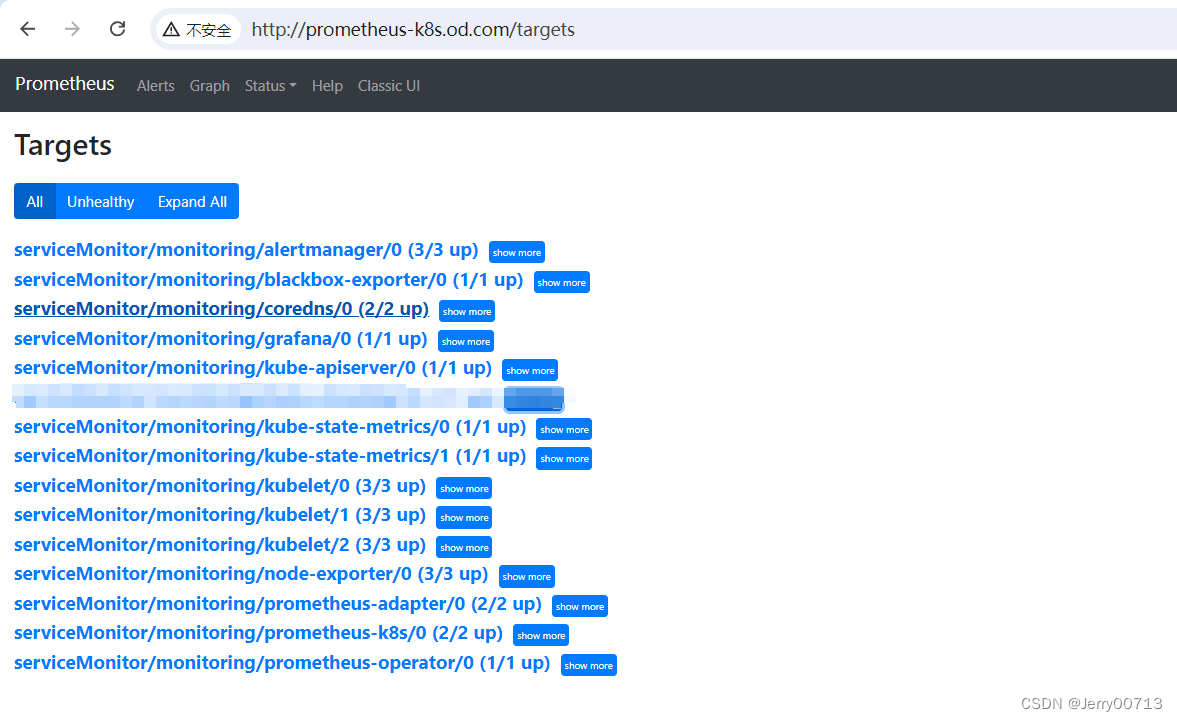
通过promethues的Configuration
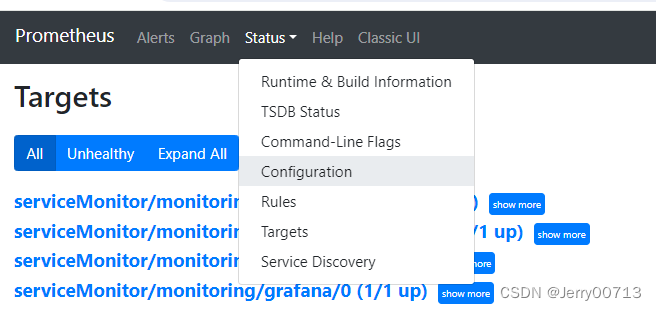
job_name是这些
- job_name: serviceMonitor/monitoring/alertmanager/0
- job_name: serviceMonitor/monitoring/blackbox-exporter/0
- job_name: serviceMonitor/monitoring/kube-apiserver/0
- job_name: serviceMonitor/monitoring/kube-state-metrics/0
- job_name: serviceMonitor/monitoring/kube-state-metrics/1
- job_name: serviceMonitor/monitoring/kubelet/0
- job_name: serviceMonitor/monitoring/kubelet/1
- job_name: serviceMonitor/monitoring/kubelet/2
- job_name: serviceMonitor/monitoring/node-exporter/0
- job_name: serviceMonitor/monitoring/prometheus-adapter/0
- job_name: serviceMonitor/monitoring/prometheus-k8s/0
- job_name: serviceMonitor/monitoring/prometheus-operator/0
- job_name: serviceMonitor/monitoring/kube-scheduler/0
- job_name: serviceMonitor/monitoring/kube-controller-manager/0通过对比发现了少了kube-scheduler kube-controller-manager。
通过查看ServerMonitor,也发现已经配置了kube-scheduler kube-controller-manager
[root@master mnt]# kubectl get ServiceMonitor -n monitoring
NAME AGE
alertmanager 45h
blackbox-exporter 45h
coredns 45h
grafana 45h
kube-apiserver 45h
kube-controller-manager 45h
kube-scheduler 45h
kube-state-metrics 45h
kubelet 45h
node-exporter 45h
prometheus-adapter 45h
prometheus-k8s 45h
prometheus-operator 45h如上图中其他的服务kubelet 能被监控,是应为定义了ServiceMonitor ,而ServiceMonitor 需要跟service绑定。
[root@master ~]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 516d
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 2d11hkube-controller-manager 和 kube-scheduler 这两个系统组件,和 ServiceMonitor 的定义有关系,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)
kubectl get serviceMonitor kube-scheduler -n monitoring -oyaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
creationTimestamp: "2024-07-01T02:44:33Z"
generation: 1
labels:
app.kubernetes.io/name: kube-scheduler # 定义
name: kube-scheduler
namespace: monitoring
resourceVersion: "879124"
uid: 635e9c40-6aca-4b01-9c82-09e5436c0212
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s # 每30s获取一次信息
port: https-metrics # 对应service的端口名
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector: # 表示去匹配某一命名空间中的service,如果想从所有的namespace中匹配用any:
matchNames:
- kube-system
selector:
matchLabels: 匹配的 Service 的labels,如果使用mathLabels,则下面的所有标签都匹配时才会匹配该service,如果使用matchExpressions,则至少匹配一个标签的service都会被选择
app.kubernetes.io/name: kube-scheduler上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有app.kubernetes.io/name: kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service:(prometheus-kubeSchedulerService.yaml)
[root@master mnt]# kubectl get svc -n kube-system
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 516d
kubelet ClusterIP None <none> 10250/TCP,10255/TCP,4194/TCP 45h
[root@master mnt]#
[root@master mnt]#vi service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-scheduler # 要跟ServiceMonitor定义一致,# 必须和上面的 ServiceMonitor 下面的 matchLabels 保持一致
name: kube-scheduler
namespace: kube-system
spec:
ports:
- name: https-metrics # 注意这里跟ServiceMonitor中定义的名字一样
port: 10251 # 10251是kube-scheduler组件 metrics 数据所在的端口,10252是kube-controller-manager组件的监控数据所在端口。
protocol: TCP
targetPort: 10251
selector:
component: kube-scheduler # 此处是在spec.ports,说明selector是选择的是pod的lables,在下文这种,通过查看kube-scheduler的lables就是这也,就代表他连接的是pod kube-scheduler
[root@master mnt]#kubectl apply -f service.yaml其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,selector下面配置的是component=kube-scheduler,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduelr 这个 Pod:
kubectl describe pod kube-scheduler-master -n kube-system
Priority Class Name: system-node-critical
Node: master/192.168.206.10
Start Time: Mon, 01 Jul 2024 09:25:28 +0800
Labels: component=kube-scheduler
tier=control-plane
Annotations: kubernetes.io/config.hash: b7c68738b74c821ccea799a016e1ffa5
kubernetes.io/config.mirror: b7c68738b74c821ccea799a016e1ffa5
kubernetes.io/config.seen: 2024-07-01T01:48:11.325892523+08:00
kubernetes.io/config.source: file
我们可以看到这个 Pod 具有component=kube-scheduler和tier=control-plane这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了,直接创建即可:
[root@master ~]# kubectl get svc -n kube-system -l app.kubernetes.io/name=kube-scheduler
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kube-scheduler ClusterIP 10.102.85.153 <none> 10259/TCP 13h
kubectl label nodes master app.kubernetes.io/name=kube-scheduler创建完成后,隔一小会儿后去 prometheus 查看 targets 下面 kube-scheduler 的状态:


我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在127.0.0.1上面的,而上面我们这个地方是想通过节点的 IP 去访问,所以访问被拒绝了,我们只要把 kube-scheduler 绑定的地址更改成0.0.0.0即可满足要求,由于 kube-scheduler 是以静态 Pod 的形式运行在集群中的,所以我们只需要更改静态 Pod 目录下面对应的 YAML 文件即可:
ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml将 kube-scheduler.yaml 文件中-command的--address地址更改成0.0.0.0:并且将port=0注释
containers:
- command:
- kube-scheduler
- --leader-elect=true
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --address=0.0.0.0
# - --port=0 # 如果为0,则不提供 HTTP 服务,--secure-port 默认值:10259,通过身份验证和授权为 HTTPS 服务的端口,如果为 0,则不提供 HTTPS。更改后重启kubelet服务,更改后 kube-scheduler 会自动重启,重启完成后再去查看 Prometheus 上面的采集目标就正常了。
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-scheduler 这个 target :

如上报错是因为1.21.1版本,需要注意现在版本默认的安全端口是10259
kubectl edit svc kube-scheduler -n kube-system
spec:
ports:
- name: https-metrics
port: 10259
protocol: TCP
targetPort: 10259
selector:
component: kube-scheduler  \
\
部署 kube-controller-manager 组件的监控
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/name: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
spec:
ports:
- name: https-metrics
port: 10257
protocol: TCP
targetPort: 10257
selector:
component: kube-scheduler然后将 kube-controller-manager 静态 Pod 的资源清单文件中的参数 --bind-address=127.0.0.1 更改为 --bind-address=0.0.0.0。 注释 - --port=0
cat /etc/kubernetes/manifests/kube-controller-manager.yaml
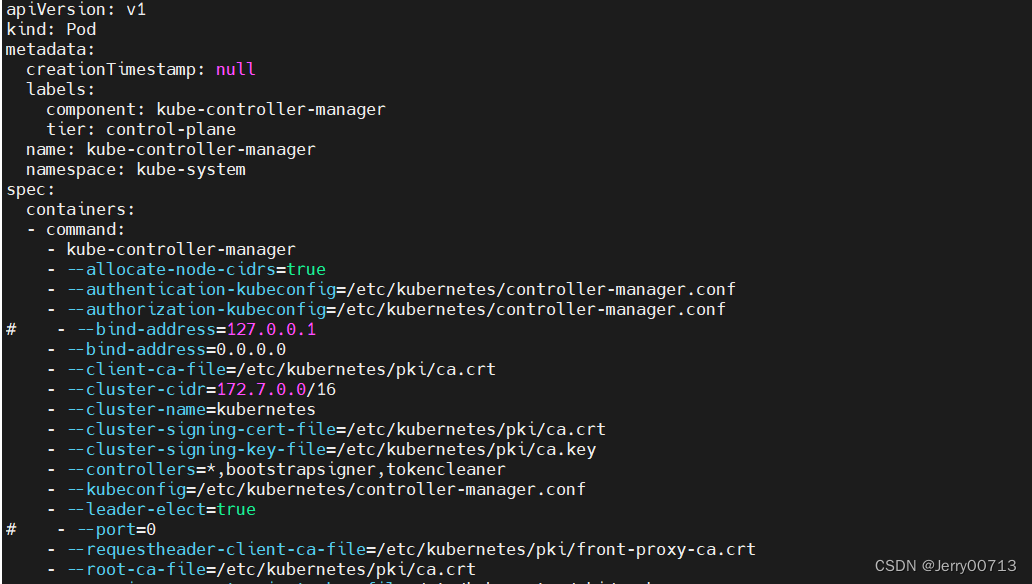
更改后重启kubelet服务,更改后 kube-controller-manager会自动重启,重启完成后再去查看 Prometheus 上面的采集目标就正常了
上面的监控数据配置完成后,现在我们可以去查看下 grafana 下面的 dashboard,同样使用上面的 NodePort 访问即可,第一次登录使用 admin:admin 登录即可,进入首页后,可以发现已经和我们的 Prometheus 数据源关联上了,正常来说可以看到一些监控图表了:
三、监控 Etcd
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第三步确保 Service 对象可以正确获取到 metrics 数据
创建secrets资源
首先我们将需要使用到的证书通过 secret 对象保存到集群中去:(在 etcd 运行的节点)
获取证书,kubedm部署的
[root@master ~]# kubectl get pods -n kube-system | grep etcd
etcd-master 1/1 Running 44 516d
[root@master ~]# kubectl describe pod etcd-master -n kube-system
Name: etcd-master
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Node: master/192.168.206.10
Start Time: Mon, 01 Jul 2024 09:25:28 +0800
Labels: component=etcd
tier=control-plane
Annotations: kubeadm.kubernetes.io/etcd.advertise-client-urls: https://192.168.206.10:2379
kubernetes.io/config.hash: 4718945d29e49afeeca8a4ab35b6b412
kubernetes.io/config.mirror: 4718945d29e49afeeca8a4ab35b6b412
kubernetes.io/config.seen: 2023-01-31T22:04:39.591063123+08:00
kubernetes.io/config.source: file
Status: Running
IP: 192.168.206.10
IPs:
IP: 192.168.206.10
Controlled By: Node/master
Containers:
etcd:
Container ID: docker://c7124102ca9389940ca148b835be0327f11506b05885aff1c634a308f309f200
Image: registry.aliyuncs.com/google_containers/etcd:3.4.13-0
Image ID: docker-pullable://registry.aliyuncs.com/google_containers/etcd@sha256:4ad90a11b55313b182afc186b9876c8e891531b8db4c9bf1541953021618d0e2
Port: <none>
Host Port: <none>
Command:
etcd
--advertise-client-urls=https://192.168.206.10:2379
--cert-file=/etc/kubernetes/pki/etcd/server.crt
--client-cert-auth=true
--data-dir=/var/lib/etcd
--initial-advertise-peer-urls=https://192.168.206.10:2380
--initial-cluster=master=https://192.168.206.10:2380
--key-file=/etc/kubernetes/pki/etcd/server.key
--listen-client-urls=https://127.0.0.1:2379,https://192.168.206.10:2379
--listen-metrics-urls=http://127.0.0.1:2381
--listen-peer-urls=https://192.168.206.10:2380
--name=master
--peer-cert-file=/etc/kubernetes/pki/etcd/peer.crt
--peer-client-cert-auth=true
--peer-key-file=/etc/kubernetes/pki/etcd/peer.key
--peer-trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
--snapshot-count=10000
--trusted-ca-file=/etc/kubernetes/pki/etcd/ca.crt
State: Running
Started: Mon, 01 Jul 2024 11:59:47 +0800
Last State: Terminated
Reason: Error
Exit Code: 255
Started: Mon, 01 Jul 2024 09:25:30 +0800
Finished: Mon, 01 Jul 2024 11:59:37 +0800
Ready: True
Restart Count: 44可以看到 ETCD 的证书文件在 Kubernetes Master 节点的 "/etc/kubernetes/pki/etcd/" 文件夹下。
将证书存入 Kubernetes
#创建secret资源
kubectl create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.crt --from-file=/etc/kubernetes/pki/etcd/healthcheck-client.key --from-file=/etc/kubernetes/pki/etcd/ca.crt -n monitoring查看刚刚创建的资源
[root@master ~]# kubectl get secret etcd-certs -n monitoring
NAME TYPE DATA AGE
etcd-certs Opaque 3 9s
[root@master ~]#将证书挂入 Prometheus
编译Prometheus资源,将etcd证书导入
[root@master ~]# kubectl get prometheus -n monitoring
NAME VERSION REPLICAS AGE
k8s 2.29.1 2 3h20m
[root@master ~]# kubectl edit prometheus k8s -n monitoring
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
creationTimestamp: "2024-07-01T02:44:34Z"
generation: 2
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
prometheus: k8s
name: k8s
namespace: monitoring
resourceVersion: "905177"
uid: 3ad2b674-458c-4918-907a-337e838ffd53
spec:
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.29.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.29.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
secrets: #------新增证书配置,将etcd证书挂入
- etcd-certs
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.29.1
[root@master ~]#等到pod重启后,进入pod查看是否可以看到证书
[root@master ~]# kubectl get pod -owide -n monitoring
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
alertmanager-main-0 2/2 Running 0 3h26m 172.7.2.119 slave02 <none> <none>
alertmanager-main-1 2/2 Running 0 3h26m 172.7.2.118 slave02 <none> <none>
alertmanager-main-2 2/2 Running 0 3h26m 172.7.1.108 slave01 <none> <none>
blackbox-exporter-6798fb5bb4-pf7tw 3/3 Running 0 3h26m 172.7.2.122 slave02 <none> <none>
grafana-7476b4c65b-bv62x 1/1 Running 0 3h26m 172.7.2.120 slave02 <none> <none>
kube-state-metrics-74964b6cd4-9tldk 3/3 Running 0 3h26m 172.7.1.109 slave01 <none> <none>
node-exporter-5lw2w 2/2 Running 0 3h26m 192.168.206.12 slave02 <none> <none>
node-exporter-g546z 2/2 Running 2 3h26m 192.168.206.10 master <none> <none>
node-exporter-gwhdr 2/2 Running 0 3h26m 192.168.206.11 slave01 <none> <none>
prometheus-adapter-8587b9cf9b-qzgmt 1/1 Running 0 3h26m 172.7.2.121 slave02 <none> <none>
prometheus-adapter-8587b9cf9b-rmmlk 1/1 Running 0 3h26m 172.7.1.110 slave01 <none> <none>
prometheus-k8s-0 2/2 Running 0 86s 172.7.2.124 slave02 <none> <none>
prometheus-k8s-1 2/2 Running 0 91s 172.7.1.112 slave01 <none> <none>
prometheus-operator-75d9b475d9-zshf7 2/2 Running 0 3h28m 172.7.1.106 slave01 <none> <none>
[root@master ~]# kubectl exec -it -n monitoring prometheus-k8s-0 -- /bin/sh
/prometheus $ ls -l /etc/prometheus/secrets/etcd-certs/
total 0
lrwxrwxrwx 1 root 2000 13 Jul 1 06:09 ca.crt -> ..data/ca.crt
lrwxrwxrwx 1 root 2000 29 Jul 1 06:09 healthcheck-client.crt -> ..data/healthcheck-client.crt
lrwxrwxrwx 1 root 2000 29 Jul 1 06:09 healthcheck-client.key -> ..data/healthcheck-client.key
/prometheus $创建 Etcd Service & Endpoints
因为 ETCD 是独立于集群之外的,所以我们需要创建一个 Endpoints 将其代理到 Kubernetes 集群,然后创建一个 Service 绑定 Endpoints,然后 Kubernetes 集群的应用就可以访问 ETCD 了。
root@master \~# vi etcd-service.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None #设置为None,不分配Service IP
ports:
- name: port
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.206.10 #Etcd 所在节点的IP
ports:
- port: 2379 #Etcd 端口号
如果是集群就是
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 11.0.64.5
- ip: 11.0.64.6
- ip: 11.0.64.7
ports:
- name: port
port: 2379
protocol: TCP
[root@master ~]# kubectl apply -f etcd-service.yaml
service/etcd-k8s created
endpoints/etcd-k8s created
[root@master ~]#创建 ServiceMonitor
创建 Prometheus 监控资源,配置用于监控 Etcd 参数。
vi etcd-monitor.yaml
$ vim prometheus-serviceMonitorEtcd.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: etcd-k8s
namespace: monitoring
labels:
k8s-app: etcd-k8s
spec:
jobLabel: k8s-app
endpoints:
- port: port
interval: 30s
scheme: https
tlsConfig:
caFile: /etc/prometheus/secrets/etcd-certs/ca.crt
certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt
keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key
insecureSkipVerify: true
selector:
matchLabels:
k8s-app: etcd
namespaceSelector:
matchNames:
- kube-system
$ kubectl apply -f etcd-monitor.yaml上面我们在 monitoring 命名空间下面创建了名为 etcd-k8s 的 ServiceMonitor 对象,基本属性和前面章节中的一致,匹配 kube-system 这个命名空间下面的具有 k8s-app=etcd 这个 label 标签的 Service,jobLabel 表示用于检索 job 任务名称的标签,和前面不太一样的地方是 endpoints 属性的写法,配置上访问 etcd 的相关证书,endpoints 属性下面可以配置很多抓取的参数,比如 relabel、proxyUrl,tlsConfig 表示用于配置抓取监控数据端点的 tls 认证,由于证书 serverName 和 etcd 中签发的可能不匹配,所以加上了 insecureSkipVerify=true
Prometheus 的 Dashboard
中查看 targets,便会有 etcd 的监控项
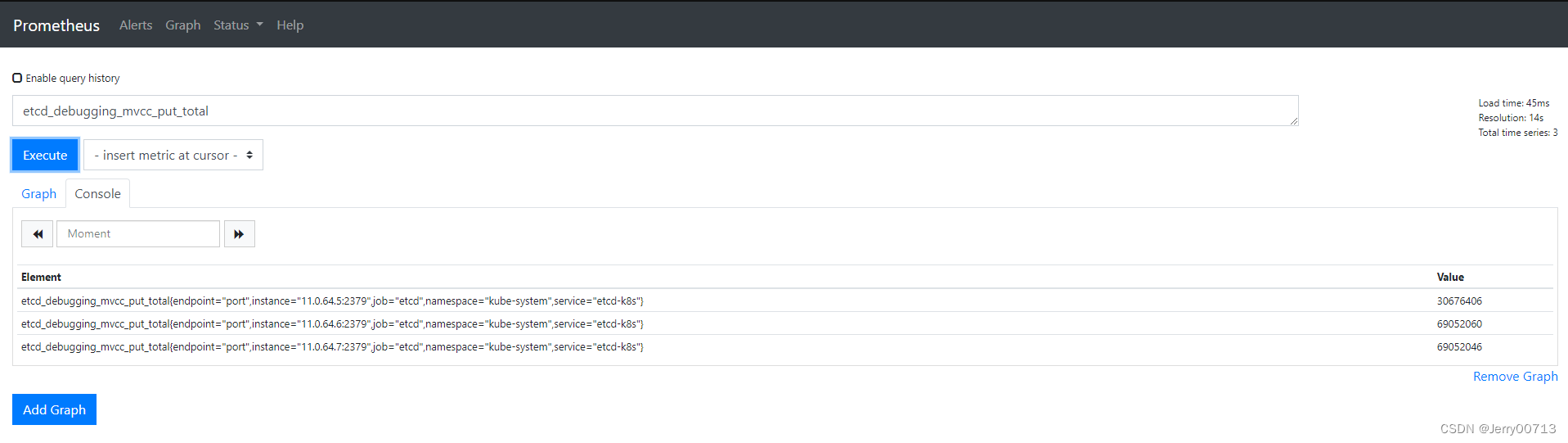
修改prometheus的时间
~]# docker tag quay.io/prometheus/prometheus:v2.29.1 quay.io/prometheus/prometheus-bak:v2.29.1
~]# vi Dockerfile
FROM quay.io/prometheus/prometheus-bak:v2.29.1
USER root
RUN /bin/cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone
~]# docker build -t quay.io/prometheus/prometheus:v2.29.1 .Grafana 引入 ETCD 仪表盘
数据采集到后,可以在 grafana 中导入编号为3070的 dashboard,获取到 etcd 的监控图表。

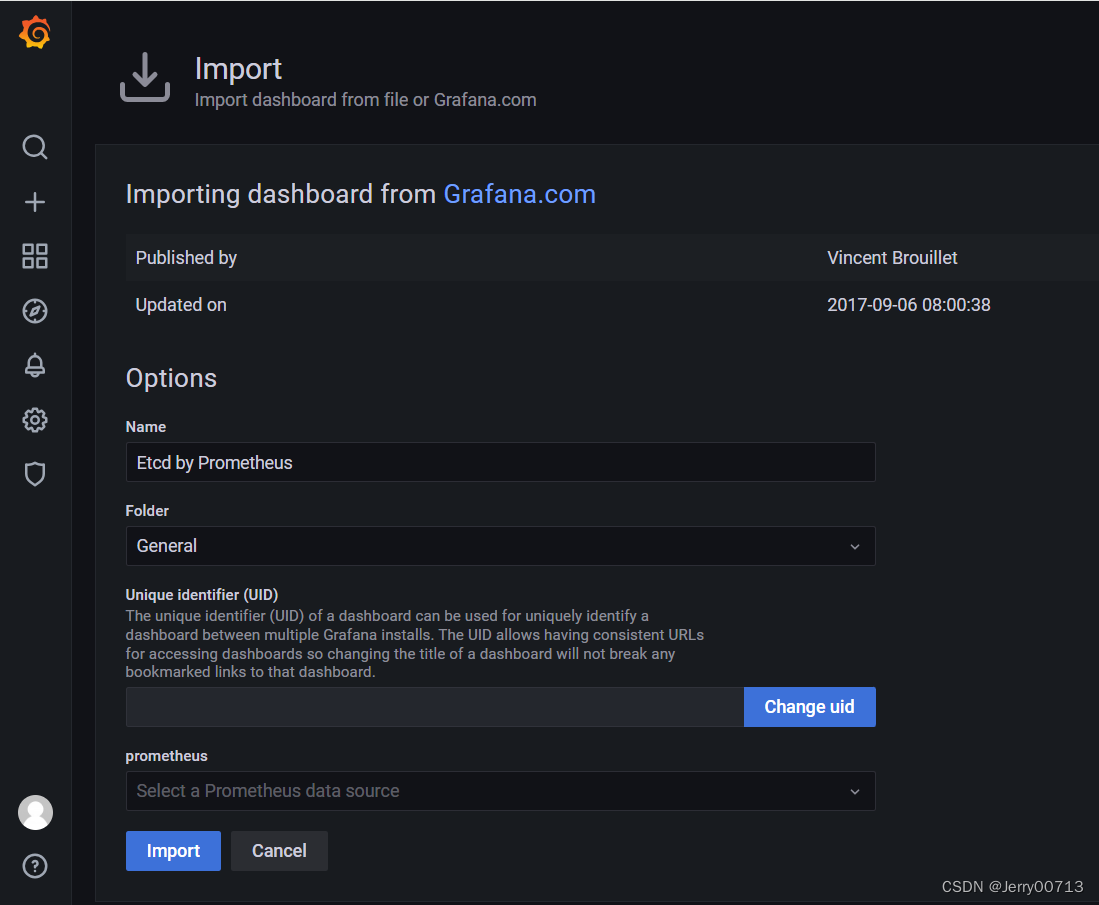
Grafana 持久化数据的能力
通过查看发现竟然将Grafana数据挂载emptyDir:可实现Pod中的容器之间共享目录数据,但没有持久化数据的能力,存储卷会随着Pod生命周期结束而一起删除
kubectl get delpoyment grafana -n monitoring

此处通过动态pvc进行挂载
vim grafana-p.yaml
apiVersion: v1 kind: PersistentVolumeClaim metadata: name: grafana-nfs-pvc namespace: monitoring spec: accessModes: - ReadWriteMany storageClassName: nfs-client-storageclass resources: requests: storage: 1Gikubectl apply -f grafana-p.yaml
kubectl edit delpoyment grafana -n monitoring
- emptyDir:{} name: grafana-storage - name: grafana-storage persistentVolumeClaim: claimName: grafana-nfs-pvc

异常处理
都不部署完成后,发现了grafana的监控模板中,只有这一块数据
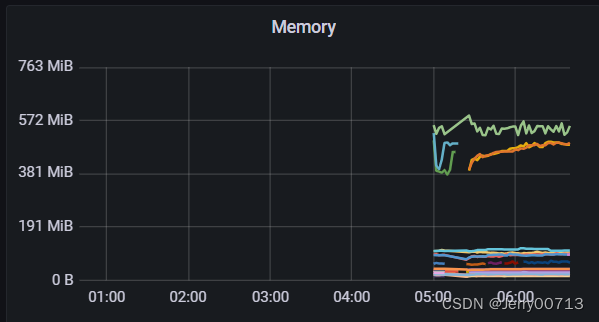
查看其他监控项目数据,是没有的
但是发现etcd的metrice是有数据的

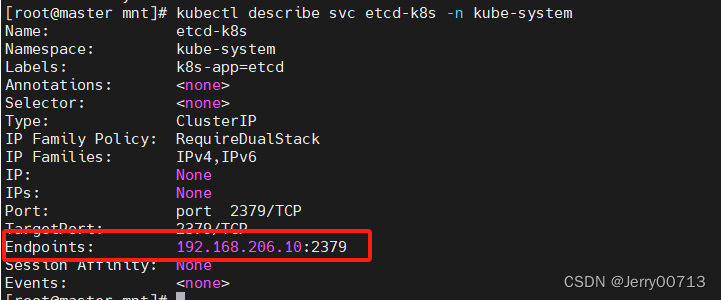
解决方案:问题是因为svc跟endpoint没绑定上
[root@master mnt]# kubectl describe svc etcd-k8s -n kube-system
Name: etcd-k8s
Namespace: kube-system
Labels: k8s-app=etcd
Annotations: <none>
Selector: <none>
Type: ClusterIP
IP Family Policy: RequireDualStack
IP Families: IPv4,IPv6
IP: None
IPs: None
Port: port 2379/TCP
TargetPort: 2379/TCP
Endpoints:
Session Affinity: None
Events: <none>是因为高版本需要Endpoints 写kubelet名称 (kubectl get node)显示的名称
[root@master mnt]# cat etcd-service.yaml
apiVersion: v1
kind: Service
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 2379
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
name: etcd-k8s
namespace: kube-system
labels:
k8s-app: etcd
subsets:
- addresses:
- ip: 192.168.206.10 #etcd节点名称
nodeName: master #kubelet名称 (kubectl get node)显示的名称
ports:
- name: port
port: 2379
protocol: TCP
kubectl apply -f etcd-service.yaml
如果是集群
- addresses:
- ip: 192.168.0.10 #etcd节点名称
nodeName: k8s-01 #kubelet名称 (kubectl get node)显示的名称
- ip: 192.168.0.11
nodeName: k8s-02
- ip: 192.168.0.12
nodeName: k8s-03