
LightGBM(Light Gradient Boosting Machine)是一个梯度提升框架,由微软开发。它用于机器学习中的分类、回归和排序等任务,特别适合处理大规模数据和高维特征。LightGBM的核心是梯度提升决策树(GBDT)算法,但它在此基础上做了多种优化,使其在速度和内存使用方面优于传统的GBDT实现。LightGBM的数学原理基于梯度提升决策树(Gradient Boosting Decision Trees, GBDT),而GBDT本身是一个集成学习算法。
1. 梯度提升决策树(GBDT)
GBDT是通过逐步构建多个决策树,并通过每棵树来纠正前一棵树的错误。具体而言:
-
初始模型:通常从一个简单的模型开始,比如预测所有样本的平均值。
-
残差计算:计算当前模型的残差(即预测值与真实值之间的差异)。
-
决策树训练:训练一棵新的决策树来拟合残差。
-
模型更新:将新决策树的预测值加到当前模型中。
每次迭代的公式为:
其中:
-
是第 次迭代的模型。
-
是学习率,控制每棵树对最终模型的贡献。
-
是第 棵决策树的预测值。
2. LightGBM的改进
LightGBM在GBDT的基础上做了许多优化,以提高训练速度和效率:
(1) 基于直方图的算法
传统的GBDT每次分裂节点时都要对所有特征值进行排序,时间复杂度较高。LightGBM通过将连续特征值离散化成直方图的形式来加速分裂过程。具体步骤如下:
-
构建直方图:将特征值划分成多个bin(桶)。
-
统计每个bin中的样本数量和目标值的总和。
-
选择最佳分裂点:在直方图的基础上计算各个分裂点的增益,选择增益最大的分裂点。
(2) 带深度限制的叶子增长策略
LightGBM采用了一个叫做"Leaf-wise"的策略,而不是传统的"Level-wise"策略:
-
Level-wise:按层次生长,每层增加一层深度。
-
Leaf-wise:每次选择增益最大的叶子进行分裂。
Leaf-wise策略能够更好地减少损失,但容易导致不平衡的树结构。为此,LightGBM引入了最大深度限制,以防止过拟合。
3. 数学公式与损失函数
LightGBM的目标是最小化损失函数,一般情况下使用平方误差或交叉熵损失。以平方误差为例,损失函数为:
其中:
-
是第 个样本的真实值。
-
是模型的预测值。
在每次迭代中,通过计算损失函数的负梯度作为残差,来训练下一棵决策树。这一过程可以看作是用梯度下降法来优化模型参数。
LightGBM通过多种优化方法(如基于直方图的分裂、Leaf-wise的增长策略等),在保留GBDT强大预测能力的同时,提高了训练速度和效率。这些优化方法的数学原理相对复杂,但总体思路仍然是基于梯度提升决策树的框架。
LightGBM的Python实例
我们选择乳腺癌数据集,乳腺癌数据集包含了569个样本,每个样本都有30个特征。这些特征主要描述了细胞核的特性(如半径、质地、周长、面积等),目标变量是样本是否为恶性肿瘤(标记为1)或良性肿瘤(标记为0)。
import lightgbm as lgb # 导入LightGBM库
import pandas as pd # 导入Pandas库,用于数据处理
import numpy as np # 导入Numpy库,用于数值计算
from sklearn.datasets import load_breast_cancer # 从sklearn库导入乳腺癌数据集
from sklearn.model_selection import train_test_split # 导入train_test_split,用于划分数据集
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix # 导入评估指标
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
import seaborn as sns # 导入Seaborn库,用于绘制热力图
# 加载乳腺癌数据集
data = load_breast_cancer()
# 将数据集转换为Pandas DataFrame格式
X = pd.DataFrame(data.data, columns=data.feature_names)
# 将目标变量转换为Pandas Series格式
y = pd.Series(data.target)
# 划分训练集和测试集,80%用于训练,20%用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建LightGBM数据集,用于训练
train_data = lgb.Dataset(X_train, label=y_train)
# 创建LightGBM数据集,用于测试
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# 设置LightGBM模型参数
params = {
'objective': 'binary', # 二分类任务
'metric': 'auc', # 评估指标使用AUC
'boosting_type': 'gbdt', # 使用梯度提升决策树
'num_leaves': 31, # 每棵树的最大叶子数
'learning_rate': 0.05, # 学习率
'feature_fraction': 0.9 # 每次迭代使用90%的特征
}
# 设置早停回调,若验证集上AUC在10轮内没有提升,则停止训练
callbacks = [lgb.early_stopping(stopping_rounds=10)]
# 训练LightGBM模型
bst = lgb.train(params, train_data, num_boost_round=100, valid_sets=[test_data], callbacks=callbacks)
# 使用训练好的模型进行预测
y_pred = bst.predict(X_test, num_iteration=bst.best_iteration)
# 将预测概率转换为二进制分类结果(0或1)
y_pred_binary = (y_pred > 0.5).astype(int)
# 评估模型的准确率
accuracy = accuracy_score(y_test, y_pred_binary)
# 评估模型的ROC AUC值
roc_auc = roc_auc_score(y_test, y_pred)
# 打印模型的准确率和ROC AUC值
print(f'Accuracy: {accuracy:.4f}')
print(f'ROC AUC: {roc_auc:.4f}')
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred_binary)
# 使用Seaborn绘制混淆矩阵的热力图
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=data.target_names, yticklabels=data.target_names)
# 设置混淆矩阵的标签
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
# 显示混淆矩阵图
plt.show()
# 绘制特征重要性图,按分裂次数排序
lgb.plot_importance(bst, max_num_features=10, importance_type='split')
plt.title('Feature Importance (split)')
# 显示特征重要性图
plt.show()
# 绘制特征重要性图,按信息增益排序
lgb.plot_importance(bst, max_num_features=10, importance_type='gain')
plt.title('Feature Importance (gain)')
# 显示特征重要性图
plt.show()
# 输出:
'''
Accuracy: 0.6228
ROC AUC: 0.9689
'''可视化结果:
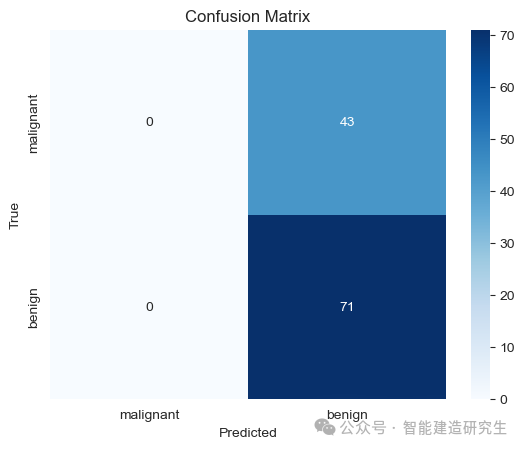
-
混淆矩阵的左上角(第一个象限)显示模型预测为"malignant"且实际也是"malignant"的样本数。在这个矩阵中,该值为0,表示没有正确预测出恶性肿瘤。
-
右上角(第二个象限)显示模型预测为"benign"但实际是"malignant"的样本数。该值为43,表示有43个恶性肿瘤被错误分类为良性肿瘤。
-
左下角(第三个象限)显示模型预测为"malignant"但实际是"benign"的样本数。该值为0,表示没有良性肿瘤被错误分类为恶性肿瘤。
-
右下角(第四个象限)显示模型预测为"benign"且实际也是"benign"的样本数。该值为71,表示有71个良性肿瘤被正确分类为良性肿瘤。
从这个混淆矩阵来看,模型的性能非常不理想。模型无法正确分类恶性肿瘤样本,而能正确分类的只是良性肿瘤。可能需要调整模型参数、增加特征工程或者尝试不同的模型来提高分类性能。
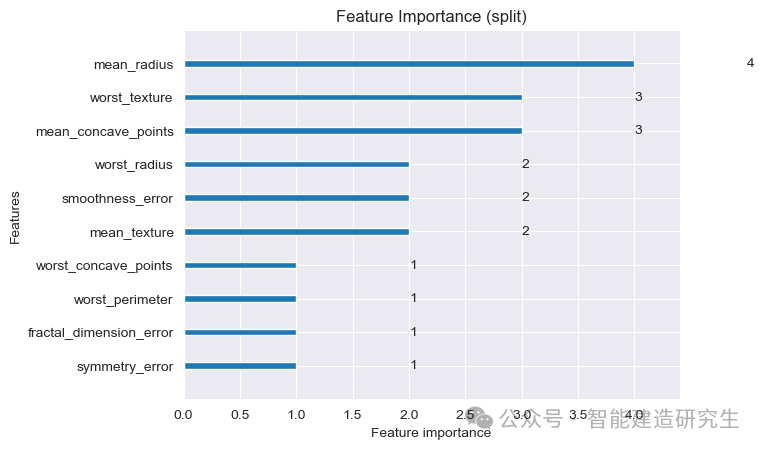
从上图中可知,模型在进行分类时对不同特征的依赖程度如下:
特征重要性最高的前三个特征(按分裂次数)
-
mean_radius(平均半径)
-
分裂次数最多,重要性最高。
-
在决策树中,它是被最频繁用来分裂数据的特征。
-
-
worst_texture(最差质地)
- 分裂次数为3,说明这个特征也是模型中重要的特征之一。
-
mean_concave_points(平均凹点数)
- 分裂次数为3,表明这个特征对模型的分类也有显著影响。
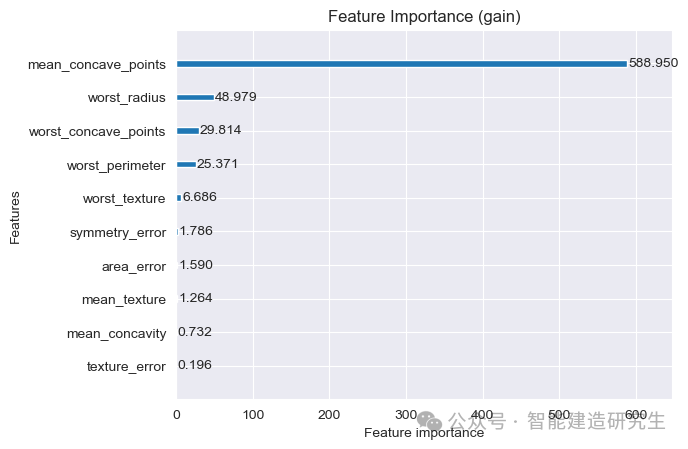
根据特征重要性图(按信息增益排序)来看,模型在进行分类时对不同特征的依赖程度如下:
特征重要性最高的前三个特征(按信息增益排序)
-
mean_concave_points(平均凹点数)
-
信息增益最高,为588.950。
-
这是模型中最重要的特征,对模型决策贡献最大。
-
-
worst_radius(最差半径)
-
信息增益为48.979,显示其在模型中的重要性。
-
这是第二重要的特征。
-
-
worst_concave_points(最差凹点数)
- 信息增益为29.814,表明该特征对模型分类有显著影响。
两种特征重要性的对比
分裂次数(split)重要性
分裂次数(split)重要性显示了每个特征在决策树中被用于分裂的频率。它的用途和意义包括:
-
模型解释性:通过查看哪些特征被频繁使用,可以了解模型在决策过程中更依赖哪些特征。
-
特征选择:高分裂次数的特征通常对模型性能有重要影响,可以作为重要特征保留。
-
特征工程:可以基于这些特征进行进一步的数据处理和特征工程,提高模型的性能。
信息增益(gain)重要性
信息增益(gain)重要性显示了每个特征在决策树中分裂时带来的信息增益。它的用途和意义包括:
-
模型优化:高信息增益的特征对模型的预测性能贡献更大,优化这些特征可以显著提升模型性能。
-
特征选择:信息增益高的特征可以作为模型的核心特征进行保留,而信息增益低的特征可能对模型贡献较小,可以考虑去除。
-
模型解释性:帮助理解哪些特征对模型的决策影响最大,尤其是在关键节点上的决策。
改进后的代码:
import lightgbm as lgb # 导入LightGBM库
import pandas as pd # 导入Pandas库,用于数据处理
import numpy as np # 导入Numpy库,用于数值计算
from sklearn.datasets import load_breast_cancer # 从sklearn库导入乳腺癌数据集
from sklearn.model_selection import train_test_split, GridSearchCV # 导入train_test_split和GridSearchCV,用于划分数据集和交叉验证
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix # 导入评估指标
import matplotlib.pyplot as plt # 导入Matplotlib库,用于绘图
import seaborn as sns # 导入Seaborn库,用于绘制热力图
# 加载乳腺癌数据集
data = load_breast_cancer()
# 将数据集转换为Pandas DataFrame格式
X = pd.DataFrame(data.data, columns=data.feature_names)
# 将目标变量转换为Pandas Series格式
y = pd.Series(data.target)
# 划分训练集和测试集,80%用于训练,20%用于测试
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建LightGBM数据集,用于训练
train_data = lgb.Dataset(X_train, label=y_train)
# 创建LightGBM数据集,用于测试
test_data = lgb.Dataset(X_test, label=y_test, reference=train_data)
# 设置初始参数
params = {
'objective': 'binary', # 二分类任务
'metric': 'auc', # 评估指标使用AUC
'boosting_type': 'gbdt', # 使用梯度提升决策树
'num_leaves': 31, # 每棵树的最大叶子数
'learning_rate': 0.01, # 降低学习率
'feature_fraction': 0.8, # 每次分裂使用80%的特征
'bagging_fraction': 0.8, # 每次训练使用80%的数据
'bagging_freq': 5, # 每5次迭代进行一次重采样
'lambda_l1': 0.1, # L1正则化
'lambda_l2': 0.1 # L2正则化
}
# 设置早停回调,若验证集上AUC在50轮内没有提升,则停止训练
callbacks = [lgb.early_stopping(stopping_rounds=50)]
# 使用交叉验证来选择最佳参数
grid_params = {
'num_leaves': [31, 41, 51], # 叶子节点数的候选值
'learning_rate': [0.01, 0.05, 0.1], # 学习率的候选值
'n_estimators': [100, 200, 500] # 迭代次数的候选值
}
# 创建LGBMClassifier对象
gbm = lgb.LGBMClassifier(**params)
# 使用GridSearchCV进行交叉验证
grid = GridSearchCV(gbm, grid_params, scoring='roc_auc', cv=5)
# 训练模型并寻找最佳参数
grid.fit(X_train, y_train)
# 输出最佳参数
print(f'Best parameters found by grid search are: {grid.best_params_}')
# 使用最佳参数训练模型
best_params = grid.best_params_
# 将最佳参数与初始参数合并,用于训练模型
bst = lgb.train({**params, **best_params}, train_data, num_boost_round=500, valid_sets=[test_data], callbacks=callbacks)
# 预测
y_pred = bst.predict(X_test, num_iteration=bst.best_iteration)
# 将预测概率转换为二进制分类结果(0或1)
y_pred_binary = (y_pred > 0.5).astype(int)
# 评估模型的准确率
accuracy = accuracy_score(y_test, y_pred_binary)
# 评估模型的ROC AUC值
roc_auc = roc_auc_score(y_test, y_pred)
# 打印模型的准确率和ROC AUC值
print(f'Accuracy: {accuracy:.4f}')
print(f'ROC AUC: {roc_auc:.4f}')
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred_binary)
# 使用Seaborn绘制混淆矩阵的热力图
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', xticklabels=data.target_names, yticklabels=data.target_names)
# 设置混淆矩阵的标签
plt.xlabel('Predicted')
plt.ylabel('True')
plt.title('Confusion Matrix')
# 显示混淆矩阵图
plt.show()
# 绘制特征重要性图,按分裂次数排序
lgb.plot_importance(bst, max_num_features=10, importance_type='split')
plt.title('Feature Importance (split)')
# 显示特征重要性图
plt.show()
# 绘制特征重要性图,按信息增益排序
lgb.plot_importance(bst, max_num_features=10, importance_type='gain')
plt.title('Feature Importance (gain)')
# 显示特征重要性图
plt.show()
# 输出
'''
Accuracy: 0.9737
ROC AUC: 0.9951
'''可视化输出结果:
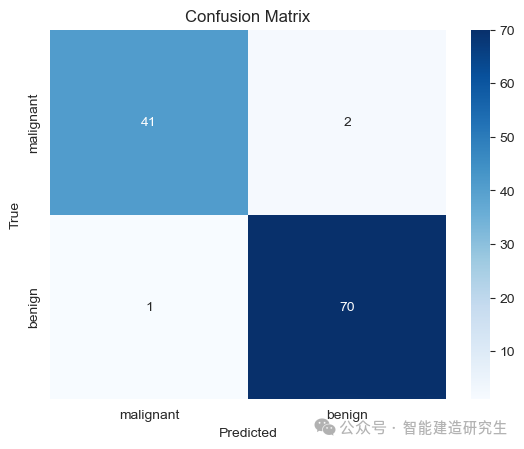
此时模型已经能较为准确地对测试集中的114个细胞样本进行分类。模型正确地将41个恶性肿瘤分类为恶性肿瘤。右上角2表示模型将2个恶性肿瘤错误地分类为良性肿瘤。左下角1表示模型将1个良性肿瘤错误地分类为恶性肿瘤。右下角70表示模型正确地将70个良性肿瘤分类为良性肿瘤。
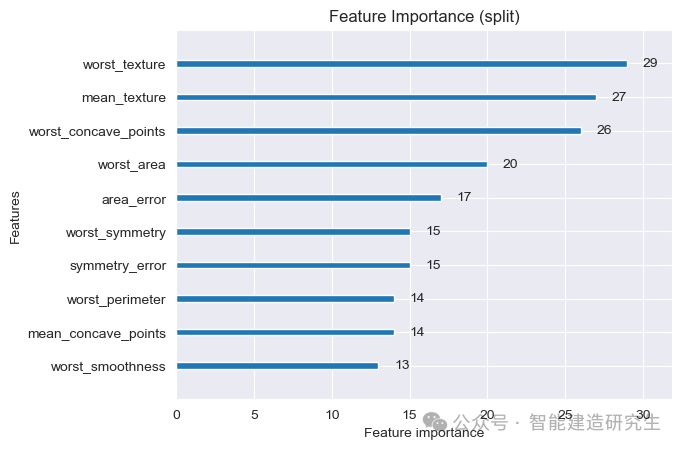
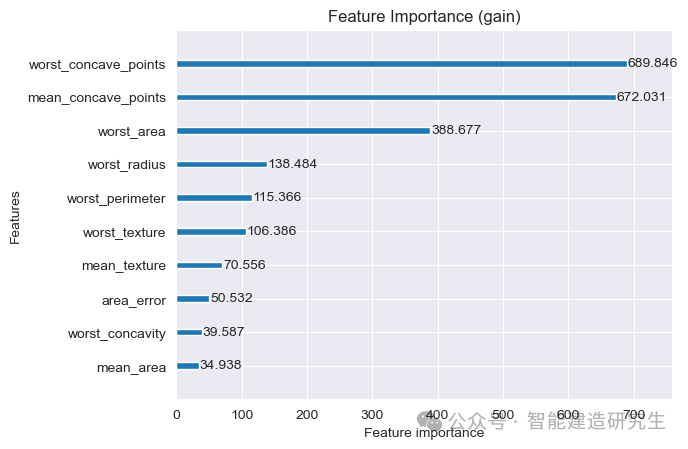
对比与分析
-
模型表现:
-
新模型的混淆矩阵显示分类性能显著提升。准确率、精确率、召回率和F1分数都比之前有明显改善。
-
新模型的准确率为97.37%,比之前的模型(62.3%)高得多,说明调整参数后的模型性能更好。
-
-
特征重要性:
-
按分裂次数 :新的特征重要性图显示了一些特征,如
worst_texture和mean_texture被频繁用于分裂,表明这些特征对模型决策有重要影响。 -
按信息增益 :信息增益高的特征如
worst_concave_points和mean_concave_points对模型决策贡献巨大,表明这些特征在关键节点上提供了大量信息。
-
以上内容总结自网络,如有帮助欢迎转发,我们下次再见!