文章目录
- [1. 前言](#1. 前言)
- [2 故障块的重构(Reconstruct)](#2 故障块的重构(Reconstruct))
-
- [2.1 故障块的状态定义和各个状态的统计信息](#2.1 故障块的状态定义和各个状态的统计信息)
- [2.2 故障文件块的查找收集](#2.2 故障文件块的查找收集)
-
- [2.2.1 Mis Replica的检测](#2.2.1 Mis Replica的检测)
- [2.2.2 延迟队列(postponedMisreplicatedBlocks)的构造和实现](#2.2.2 延迟队列(postponedMisreplicatedBlocks)的构造和实现)
- [2.2.3 待定队列(PendingReconstructionBlock)的构造和实现](#2.2.3 待定队列(PendingReconstructionBlock)的构造和实现)
- [2.2.4 重构队列(neededReconstruction)的构造和实现](#2.2.4 重构队列(neededReconstruction)的构造和实现)
- [2.3 RedundancyMonitor的运行](#2.3 RedundancyMonitor的运行)
- [3. RedundancyMonitor的工作原理](#3. RedundancyMonitor的工作原理)
-
- [3.1 从优先级队列中选择待重构块](#3.1 从优先级队列中选择待重构块)
- [3.2 构建待重构块的统计信息和元数据信息,为选择source节点做准备](#3.2 构建待重构块的统计信息和元数据信息,为选择source节点做准备)
- [3.3 选择target节点](#3.3 选择target节点)
- [3.4 将任务调度出去](#3.4 将任务调度出去)
- [3.5 DataNode对重构任务的处理](#3.5 DataNode对重构任务的处理)
-
- [3.5.1 StripedReader的构造](#3.5.1 StripedReader的构造)
- [3.5.2 StripedReader的初始化](#3.5.2 StripedReader的初始化)
- [3.5.3 StripedWriter的构造](#3.5.3 StripedWriter的构造)
- [3.5.4 StripedWriter的初始化](#3.5.4 StripedWriter的初始化)
- [3.5.5 开始重构](#3.5.5 开始重构)
- [4. 结束](#4. 结束)
1. 前言
本节将会讲解故障块的重构(Reconstruction)的基本流程,
故障块的恢复(Recovery)指的是写数据过程中,由于某些非正常原因,造成最终的块文件没有达到最后的COMPLETE状态,比如,写过程客户端的突然离开,写过程中DataNode的突然当机。
而故障块的重构(Reconstruction)发生在写完成以后,由于系统情况的改变,比如,DataNode宕机,DataNode汇报上来的存储故障,用户手动修改了副本数导致副本数量过多,用户手动进行decommission或者maintenance导致副本的数量变化,都需要进行相关副本的重构。
本文主要讲解整个重构过程,包括:
- NameNode端待重构块的生成过程(包含了各种待重构的情况),
- NameeNode端基于生成的待重构块进行重构工作的调度,
- DataNode端对于重构任务的处理。由于基于副本复制的冗余策略基本上就是数据的拷贝,比较简单,因此,本文偏向于讲解基于纠删码的冗余策略的DataNode端的处理过程。
2 故障块的重构(Reconstruct)
故障块的重构都是基于已经处于BlockUCState.COMPLETE状态的,通过COMPLETE的定义我们知道,意味着重构(Reconstruct)针对的是已经写完成(汇报上来的块副本达到了要求比如最小允许副本数),但是后来块的状态发生问题的那些块。
2.1 故障块的状态定义和各个状态的统计信息
本章节讲解块重构过程中的块状态,这些状态是StoredReplicaState的状态。StoredReplicaState是块已经完成写操作以后的状态阶段中的不同状态,而不是块在写入过程中的状态BlockUCState。
需要区别这个Replica的状态StoredReplicaState和节点的状态(AdminState),这里不再详述。
BlockManager通过方法checkReplicaOnStorage()来统一收集并计算副本状态,并返回一个收集了副本状态信息的对象NumberReplicas。 从NumberReplicas的名字听起来似乎这个类是统计副本的总数量,但是其实这个类是统计在各个状态下的副本数量的分类统计信息。那么,副本会有哪些状态呢?
所有的副本状态被StoredReplicaState表述。顾名思义,StoredReplicaState所表述的副本状态是已经存储下来的副本的整个状态,这些层面的状态一方面是为了给用户的诸如fsck的命令返回副本的统计信息,更重要的,这些状态的统计信息,将用来决定下一步对副本是否需要进行重构的策略,比如副本数是否太低,太低的副本需要进行重构,副本数是否太高,副本数太高的副本需要进行部分的删除。
java
public enum StoredReplicaState {
// live replicas. for a striped block, this value excludes redundant
// replicas for the same internal block
LIVE,
READONLY,
// decommissioning replicas. for a striped block ,this value excludes
// redundant and live replicas for the same internal block.
DECOMMISSIONING,
DECOMMISSIONED,
// We need live ENTERING_MAINTENANCE nodes to continue
// to serve read request while it is being transitioned to live
// IN_MAINTENANCE if these are the only replicas left.
// MAINTENANCE_NOT_FOR_READ == maintenanceReplicas -
// Live ENTERING_MAINTENANCE.
// 当 一个节点处于ENTERING_MAINTENANCE中(还没到达最终的IN_MAINTENANCE), 这个节点上的internal block如果没有其它副本,
// 那么这个node还是会接着serve 这个replica 的读请求。显然,当节点进入到IN_MAINTENANCE中的时候,读请求就不会过来了,
// 因此进入MAINTENANCE_NOT_FOR_READ
MAINTENANCE_NOT_FOR_READ,
// Live ENTERING_MAINTENANCE nodes to serve read requests.
MAINTENANCE_FOR_READ,
CORRUPT,
// excess replicas already tracked by blockmanager's excess map
EXCESS, // 副本数量超过了要求,这些超过要求的replica 最终会被删除
STALESTORAGE,
// for striped blocks only. number of redundant internal block replicas
// that have not been tracked by blockmanager yet (i.e., not in excess)
REDUNDANT
}副本的状态StoredReplicaState是对连续布局和条带布局统一而言的,并不是专指某种布局方式。但是,某些特定状态在两种布局模式下的含义稍有不同。副本每一个状态的具体含义,我们可以从BlockManager构造NumberReplicas对象的方法checkReplicaOnStorage()清楚地看到:
java
private StoredReplicaState checkReplicaOnStorage(NumberReplicas counters,
BlockInfo b, DatanodeStorageInfo storage,
Collection<DatanodeDescriptor> nodesCorrupt, boolean inStartupSafeMode) {
final StoredReplicaState s;
if (storage.getState() == State.NORMAL) {
final DatanodeDescriptor node = storage.getDatanodeDescriptor();
if (nodesCorrupt != null && nodesCorrupt.contains(node)) {
s = StoredReplicaState.CORRUPT;
} else if (inStartupSafeMode) {
s = StoredReplicaState.LIVE;
counters.add(s, 1);
return s;
} else if (node.isDecommissionInProgress()) {
s = StoredReplicaState.DECOMMISSIONING;
} else if (node.isDecommissioned()) {
s = StoredReplicaState.DECOMMISSIONED;
} else if (node.isMaintenance()) {
if (node.isInMaintenance() || !node.isAlive()) {
s = StoredReplicaState.MAINTENANCE_NOT_FOR_READ;
} else {
s = StoredReplicaState.MAINTENANCE_FOR_READ;
}
} else if (isExcess(node, b)) {
s = StoredReplicaState.EXCESS;
} else {
s = StoredReplicaState.LIVE;
}
counters.add(s, 1);
// //如果这个Storage是stale storage,那么,认为这个replica是stale状态,直到收到对应DN的heartbeat
if (storage.areBlockContentsStale()) {
counters.add(StoredReplicaState.STALESTORAGE, 1);
}
} else if (!inStartupSafeMode &&
storage.getState() == State.READ_ONLY_SHARED) {
s = StoredReplicaState.READONLY;
counters.add(s, 1);副本的大部分状态是由这个副本所在的存储状态决定的:
-
LIVE : 就是我们最常见的正常的存活状态。
- 对于条带布局模式,虽然预期是每一个internal block只有一个副本,但是有可能存在某个internal block同时存在LIVE状态和其它状态,在这种情况下,LIVE状态是排他的,即,这个Internal Block只要有一个副本是LIVE,那么我们就认为这个Internal Block的状态是LIVE。关于节点状态的一些去重操作,参考
BlockManager.countLiveAndDecommissioningReplicas()。 - 从代码可以看到,对于与DECOMMISSION或者MAINTENANCE相关的状态,即使此时机器还在线,副本可读,副本状态并不会是LIVE,而是对应的DECOMMISSION或者MAINTENANCE的相关状态。
- 对于条带布局模式,虽然预期是每一个internal block只有一个副本,但是有可能存在某个internal block同时存在LIVE状态和其它状态,在这种情况下,LIVE状态是排他的,即,这个Internal Block只要有一个副本是LIVE,那么我们就认为这个Internal Block的状态是LIVE。关于节点状态的一些去重操作,参考
-
READONLY : 如果replica所在的Storage的类型是StorageType.State.READ_ONLY_SHARED, 那么这个副本的状态就是READONLY。这个READ_ONLY_SHARED是一个特殊的HDFS特性,我看了一下对应的HDFS issue HDFS-5318(issue里面有对应的design doc, 感兴趣的读者可以看看),其大致意思就是将我们传统的通过物理磁盘存储block的方式转移到通过共享存储(NAS, S3等)存储块信息,由于不再存放在某台DataNode上,因此客户端可以通过任意DataNode读取到这个Block。这个READONLY状态和本文的关系不大,不做详细解释。
-
DECOMMISSIONING : 一个机器decommision的过程就意味着上面的replica需要全部转移(copy)到其它机器上,在全部转移完成以前,这个机器上的block都是DECOMMISSIONING的状态。显然,对于一个条带布局的 internal block,如果这个块已经成功转移到其它的Live的机器上,那么这同一个internal block就会在NameNode端同时存在LIVE和DECOMMISSIONING的状态,这时候,NameNode的判定状态是Live状态。关于节点状态的一些去重操作,参考
BlockManager.countLiveAndDecommissioningReplicas()。 -
DECOMMISSIONED: 副本所在的机器已经decommission结束。
-
MAINTENANCE_FOR_READ : 关于机器的maintenance状态,感兴趣的读者可以自行学习,它发生在我们需要暂时将某个节点进行下线或者升级同时又不希望这个节点的短暂下线引起集群大量的副本拷贝的场景。与maintenance相关的状态与读写的关系是:
- 凡是与Maintenance相关的状态(ENTERING_MAINTENANCE或者IN_MAINTENANCE状态),机器都不可能再服务写请求;
- 处于ENTERING_MAINTENANCE状态并且依然存活的机器,是可以服务读请求的;
- 一个机器可能在ENTERING_MAINTENANCE的过程中死亡,这时候显然上面的所有副本也是不可读的;
- 一个机器一旦真正进入了IN_MAINTENANCE状态,无论是否存活,都不会再server任何请求,包括读请求。因为我们将一个机器进入MAINTENANCE的目的大部分都是希望机器短暂停机维修等。
- 所以,只有当一个机器处于ENTERING_MAINTENANCE并且存活,它上面的副本状态才会是MAINTENANCE_FOR_READ
-
MAINTENANCE_NOT_FOR_READ:从上面的分析可以看到,如果一个机器已经进入到IN_MAINTENANCE状态,或者这个机器在ENTERING_MAINTENANCE的状态中死亡,这时候这个机器将拒绝任何请求,包括读请求。
-
CORRUPT : 这个replica所在的机器存储已经CORRUPT。请注意区分Block corrupt和Replica corrupt的区别,当且仅当一个Block的所有的replica都已经corrupt了,那么这个Block会被认为是corrupt。NameNode端corrupt的replica都被一个叫做CorruptReplicasMap的对象管理,存放了所有的corrupted的replica以及对应的Corrupt的原因:
javapublic class CorruptReplicasMap{ /** The corruption reason code */ public enum Reason { NONE, // not specified. ANY, // wildcard reason GENSTAMP_MISMATCH, // mismatch in generation stamps SIZE_MISMATCH, // mismatch in sizes INVALID_STATE, // invalid state CORRUPTION_REPORTED // client or datanode reported the corruption } // 存放了所有corrupt的replica private final Map<Block, Map<DatanodeDescriptor, Reason>> corruptReplicasMap = new HashMap<Block, Map<DatanodeDescriptor, Reason>>();在BlockManager中维护了CorruptReplicasMap的引用,所有corrupt replica都是通过
BlockManager.markReplicaAsCorrupt()来添加到corruptReplicas中的,主要有以下情况:- 来自DataNode的增量块汇报(DatanodeProtocol.blockReceivedAndDelete接口)或者全量块汇报(DatanodeProtocol.blockReport)接口。在收到这些块汇报以后,NameNode会对所有汇报上来的块进行时间戳和size的检测,如果发现汇报上来的块和自己在blockMap中存储的块的时间戳或者size不一致,则认定该块是corrupt块
- 来自DataNode直接汇报的badBlock(通过DatanodeProtocol.reportBadBlocks()),NameNode收到这些会报上来的badBlock会直接通过调用markBlockAsCorrupt()将其标记为corrupt block。DataNode在什么情况下会直接上报badBlocks呢?这主要发生在比如DataNode被分配了reconstruct的任务时,会从远程读取一些replica进行重构,这时候如果读取发生问题,就会认为是corrupted replica,然后通过DatanodeProtocol.reportBadBlocks()接口上报NameNode。
- 客户端在读取块的过程中发现块的校验失败,会通过(ClientProtocol.reportBadBlocks()接口)告知NameNode
- DataNode在完成了某个Recovery以后,通过DataNodeProtocol.commitBlockSynchronization()接口告知NameNode,NameNode会在适当情况下将replica标记为corrupt
-
STALESTORAGE:这种状态其实是一种Corner Case。当NameNode发生重启或者Failover(从standby到达active状态)发生,NameNode会将所有的DataNode 的所有的Storage标记为Stale(陈旧)状态,这时候这些storage上的replica也全部为stale状态,直到收到了对应的DataNode发送过来的关于这个Storage的心跳信息,才会解除Stale状态。Stale状态是为了处理在NameNode发生状态转移的时候DataNode和新的NameNode发生的一些不一致状态。在Stale状态的副本的大多数处理都会延迟,因为这是一个中间状态,比如我们发现一个replica的副本数过多,但是其中有一个副本是STALESTORAGE状态,那么这时候我们不可以贸然去删除多余副本,因为这时候有可能对应的 DataNode已经将副本删除,等汇报上来的时候,NameNode也将副本在另外机器上删除,造成副本丢失。
-
REDUNDANT: 只适用于条带布局,某一个internal block的副本数量多余一个。
-
EXCESS : 含义其实于REDUNDANT,只不过EXCESS指的是NameNode已经发现了该replica有多余副本(比如通过fsck,或者通过RedundancyMonitor的定时扫描线程),同时将这个replica的信息放到excessRedundancyMap中去,所有放到excessRedundancyMap中的internal block都会采用响应策略删除一个replica的多余副本。
从上面的状态分析可以看到,副本的状态和一些存储的状态有一部分是用户操作的,比如Decommission和Maintenance,有些是机器自己汇报的,比如CORRUPT, 有些是集群本身的状态发展而成的,比如LIVE, STALESTORAGE, REDUNDANT, EXCESS,
2.2 故障文件块的查找收集
下图显示了与块的生命周期相关的几个重要的队列的管理流程:

主要存在三个不同的队列:
- neededReconstruction队列(重构队列):这是一个由BlockManager维护的LowRedundancyBlocks对象,这个对象存放了已经确认副本数量过低因此需要进行Reconstruction的那些Block。比如,HDFS管理员手动增加了一些块的副本导致现存副本数不足,HDFS管理员decommission了一些节点,导致这些节点上的Block的块的副本数不足,或者其他一些导致块的副本不足的情况。这些Low-Redundancy 的 Block依据其存活副本的数量进行了优先级排序,优先级越高,说明重构的紧急程度越高,重构越需要靠前。随后,RedundancyMonitor会将这些Blocks从neededReconstruction中取出,然后调度对应的BlockReconstructionWork。
- postponedMisreplicatedBlocks队列(延迟队列):这是一个由BlockManager维护的LinkedHashSet对象。 NameNode发现有些Block的副本数超过了预期的副本数,因此需要进行Replica的删除。但是,有可能HDFS系统刚刚才启动,或者,NameNode Failover刚发生(当前的这个Active NameNode是刚刚才从Standby到Active状态的),因此,新的NameNode还没有收到一部分DataNode的第一次block report(Stale Node),但是这些DataNode可能在Failover以前已经执行了删除,因此需要延迟对这个Mis Replicated Block的副本进行删除,避免对一个Block的不同Replica进行两次删除,过度删除导致副本反而不足。
- pendingReconstruction队列(待定队列): 这是一个有BlockManager维护的PendingReconstructionBlocks对象。从PendingReconstructionBlocks的定义可以看到,pendingReconstructions是一个以block作为key、以PendingBlockInfo作为value的map,代表这个block对应的PendingBlockInfo里面的target尚未向NameNode进行汇报。既然是待定,那么就需要监控什么时候解除待定。对于在超时时间范围内收到了副本的正常汇报的Block会从PendingReconstructionBlocks中删除,没有在超时时间范围内收到汇报的Block则进一步移动到超时队列中。随后,RedundancyMonitor线程会进行处理,比如,进行块的重构。
主要存在四个线程:
- BlockManager Daemon线程: 这个线程会对整个BlocksMap进行无差别扫描,根据Blocks的状态,将对应的Blocks放入到postponedMisreplicatedBlocks队列,或者放入到neededReconstruction队列
- DatanodeAdminDefaultMonitor线程:这个线程主要针对用户通过比如-refreshNodes所触发的节点的decommission或者maintenance。通过扫描这些节点上的所有Block,将由于节点的decommission或者maintenance所引发的这些节点上的Replica所对应的Block变成Low-Redundancy状态,将这些Block添加到neededReconstructions中。
- RedundancyMonitor线程:这个线程的功能其实比较复杂,表现在它的下面三个方法中:。
- computeDatanodeWork(); 这是最重要的工作, 从neededReconstruction中取出Block,为他们构建BlockReconstructionWork调度到对应的DataNode上去。
- processPendingReconstructions(), 从pendingReconstructions队列中取出已经Timeout的Block,如果需要reconstruct,加入到neededReconstruction中
- rescanPostponedMisreplicatedBlocks(),从延迟队列中取出Block,如果需要reconstruct,加入到neededReconstruction中
2.2.1 Mis Replica的检测
Mis Replica指的是一个Block的replica的数量处于不正常的状态,比如,有多余的副本,或者低于预期的副本等,都属于副本不正常的情况。注意,副本不正常的情况都是指已经处于COMPLETE状态的副本,即不可变的块。可变的、正在写的块不在重构的处理范围内,而是块恢复(Recover)的职责。
NameNode会通过各种方式不断检测每个副本,确定这个副本是否属于Mis Replica,如果属于Mis Replica,则进行进一步处理。
在NameNode启动的时候,会通过调用initializeReplQueues()来启动一个独立线程(需要将这个独立线程和我们后面讲到的用来生成BlockReconstructionWork的RedundancyMonitor区分开),专门用来扫描并生成对应的MisReplica Block:
java
----------------------------------------- FSNamesystem ----------------------------------------
void startActiveServices() throws IOException {
// Only need to re-process the queue, If not in SafeMode.
if (!isInSafeMode()) {
LOG.info("Reprocessing replication and invalidation queues");
blockManager.initializeReplQueues();
}
java
--------------------------------------- BlockManager ------------------------------------------
public void initializeReplQueues() {
processMisReplicatedBlocks();
initializedReplQueues = true;
}
public void processMisReplicatedBlocks() {
reconstructionQueuesInitializer = new Daemon() {
@Override
public void run() { // 这是一个异步线程
processMisReplicatesAsync();
}
};
}下面的代码就是这个独立线程的核心方法processMisReplicatesAsync():
java
private void processMisReplicatesAsync() throws InterruptedException {
......
Iterator<BlockInfo> blocksItr = blocksMap.getBlocks().iterator();// 处理对象是目前管理的所有的Block
// 这也是一个不断执行的过程
while (namesystem.isRunning() && !Thread.currentThread().isInterrupted()) {
int processed = 0;
namesystem.writeLockInterruptibly();
try {
// 通过numBlocksPerIteration
while (processed < numBlocksPerIteration && blocksItr.hasNext()) {
BlockInfo block = blocksItr.next();
MisReplicationResult res = processMisReplicatedBlock(block);
....
}
}
}从processMisReplicatesAsync()可以看到,它遍历的对象是blocksMap中的所有的Block(而不是某一个节点或者某一类的Block),然后对于每一个Block,其调用processMisReplicatedBlock() 来扫描该Block的replica的位置信息以确认是否有问题(放置不正确,或者缺少replica)。
显然,由于扫描的对象是整个BlocksMap,为了避免长期占用资源,通过dfs.block.misreplication.processing.limit控制每一轮扫描最大处理的块数量,超过该数量则sleep一段时间。
其中,每一个Block的Replica的位置信息的结果用枚举类型MisReplicationResult来表达;
java
enum MisReplicationResult {
/** The block should be invalidated since it belongs to a deleted file. */
INVALID, // 这个块属于一个被删除的文件,副本可以删除了
/** The block is currently under-replicated. */
UNDER_REPLICATED, // 这个块的副本数不足
/** The block is currently over-replicated. */
OVER_REPLICATED,
/** A decision can't currently be made about this block. */
POSTPONE,
/** The block is under construction, so should be ignored. */
UNDER_CONSTRUCTION,
/** The block is properly replicated. */
OK
}但是,processMisReplicatedBlock() 并不一定仅仅在BlockManager的Daemon线程中触发,它会在以下情况下被触发:
- 用户在运行fsck命令的过程中,如果添加了
-replicate参数,那么fsck不仅仅会检查会返回并检查块的状态,并且会将检查到的副本数量不足的块(misReplicatedBlocks)进行进一步处理。 - NameNode启动时,Active NameNode会通过BlockManager启动一个异步独立的Daemon线程,这个线程会周期性扫描当前BlockManager管理的所有的Block,每个block都会检查其replication状态。
- RedundancyMonitor每一轮运行的时候,都会扫描postponedMisreplicatedBlocks并尝试对着里面的超时的block进行处理,如果依然处理失败(返回的结果依然是
MisReplicationResult.POSTPONE),那么会重新加入到postponedMisreplicatedBlocks中。如果发现MisReplicationResult已经正常,那么就不再放回postponedMisreplicatedBlocks中。
2.2.2 延迟队列(postponedMisreplicatedBlocks)的构造和实现
postponedMisreplicatedBlockss是一个LinkedHashSet对象。
BlockManager使用postponedMisreplicatedBlocks保存了一些需要延迟处理的、放置状态不正常(MisReplicationResult中表述的比如UNDER_REPLICATED,OVER_REPLICATED)的Block。
java
private final Set<Block> postponedMisreplicatedBlocks =
new LinkedHashSet<Block>();延迟处理是因为,系统刚刚才启动,或者,Failover刚发生(当前的这个Active NameNode是刚刚才从Standby到Active状态的),因此,还没有收到一部分DataNode的第一次block report,即目前NameNode关于Block中副本的状态是过时(Stale)的,因此需要延迟对这个Mis Replicated Block进行进一步处理,这里的延迟处理在代码中具体指的是删除。
本质上,这是为了解决新的NameNode所看到的集群状态其实并非集群最新状态的特殊情况,因此没有必要立即采取比如Invalidate的行动,选择再等一等。这种特殊情况在HDFS特指需要删除副本数过多的Block的情况:
新的NameNode发现这个Block的副本超过了要求的副本数量(over-replicated),因此需要将某一个或者多个replica 加入到invalidateBlocks中,随后被删掉。但是,NameNode也发现这个Block有一个副本是在Stale DataNode上,这时候问题出现了:由于NameNode当前掌握的某个replica-1的DataNode(DN-1)的状态是过期(Stale)的,很有可能之前的Active NameNode已经发现了这个over-replicated的Block并且已经让这个Stale DataNode删掉了副本,但是当前的新的Active NameNode还不知道。如果这时候Active NameNode直接指示其它DataNode(DN-2)删掉副本,当之前的DN-1汇报说我已经把副本replica-1已经删除,这时候就造成Block的副本数不足。因此最好等待这个Block中位于Stale DataNode的heartbeat上来再对这个Invalidate操作进行处理。
在NameNode刚刚切换到 Active状态的时候,会将所有的DataNodeStorageInfo的状态置为Stale,直到第一次收到这个DataNode对应的heartbeat:
java
// NameNode刚启动,会将所有DataNode标记为Stale
void markStaleAfterFailover() {
heartbeatedSinceFailover = false;
blockContentsStale = true;
}
// 收到heartbeat
void receivedHeartbeat(StorageReport report) {
updateState(report);
heartbeatedSinceFailover = true;
}
//收到heart
void receivedBlockReport() {
if (heartbeatedSinceFailover) { // Failover以后已经收到了heartbeat
blockContentsStale = false; // 将DataNodeStorageInfo置为非Stale状态
}
blockReportCount++;
}向postponedMisreplicatedBlocks中添加Block
向BlockManager所管理的postponedMisreplicatedBlocks队列中添加Block是通过以下方法进行的:
java
@VisibleForTesting
void postponeBlock(Block blk) {
postponedMisreplicatedBlocks.add(blk);
}通过查看该方法的调用者,我们可以看到向postponedMisreplicatedBlocks中添加Block的所有情况:
上面讲过,postponedMisreplicatedBlocks中的所有Block都是那种1) replica数量超过预期值并且 2) 有Replica在stale DataNode上。
大概有下面的这些情况,NameNode会往postponedMisreplicatedBlocks中添加Block:
-
上文提到的BlockManager中的Daemon线程,在扫描BlocksMap中的每一个Block的时候,一旦发现这个Block的Replica数量超过了预期的Replica数量因此需要进行invalidate,但是有一个Replica在Stale DataNode上,那么这个Block的这个Replica就会被标记为StoredReplicaState,这时候
processMisReplicatedBlock()方法就会返回MisReplicationResult.POSTPONED,从而将对应的Block放到postponedMisreplicatedBlocks中;javaprivate void processMisReplicatesAsync() throws InterruptedException { Iterator<BlockInfo> blocksItr = blocksMap.getBlocks().iterator();// 处理对象是目前管理的所有的Block while (namesystem.isRunning() && !Thread.currentThread().isInterrupted()) { int processed = 0; namesystem.writeLockInterruptibly(); try { while (processed < numBlocksPerIteration && blocksItr.hasNext()) { BlockInfo block = blocksItr.next(); MisReplicationResult res = processMisReplicatedBlock(block); switch (res) { .... case POSTPONE: nrPostponed++; // 加入到postponedMisreplicatedBlocks,这个list待会儿会有RedanduncyMonitor.run()去异步读取并处理 postponeBlock(block); ...... } private MisReplicationResult processMisReplicatedBlock(BlockInfo block) { ........ if (shouldProcessExtraRedundancy(num, expectedRedundancy)) { if (num.replicasOnStaleNodes() > 0) { // 如果这个节点over replica,但是有些replica在stale node上,我们 // 判定这个replica的状态MisReplicationResult.POSTPONE, 暂不处理 return MisReplicationResult.POSTPONE; // 推迟 } ..... } } -
RedundancyMonitor线程会通过rescanPostponedMisreplicatedBlocks()对postponedMisreplicatedBlocks中的每一个Block进行重新检查,其实也会调用方法processMisReplicatedBlock(),如果发现这个这个Block的Replica数量超过了预期的Replica数量因此需要进行invalidate,但是有一个Replica在Stale DataNode上,就会返回
MisReplicationResult.POSTPONED,从而将对应的Block重新放到postponedMisreplicatedBlocks中; 对应代码已经贴过。 -
每当收到DataNode的Block Report以后,都会对Block的状态进行一系列的检查,同样的,如果发现这个Block满足上面的条件,就放到postponedMisreplicatedBlocks中;
我们可以可以在BlockManager的addStoredBlock()方法中看到向postponedMisreplicatedBlocks中添加Block的过程,addStoredBlock()方法是NameNode在收到DataNode的IBR以后调用的方法。同时我们也看到了该方法在收到IBR以后,尝试将已经不再处于low-redundancy状态的Block从neededReplication中删除的操作:java/** * 区分addStoredBlock()和addLocatedBlock(). stored block是指 * 已经被dn存储下来的block * 注意,汇报上来的准确来讲是一个replica,这个replica属于BlocksMap中的某一个block, */ private Block addStoredBlock(.....) throws IOException { ....... // handle low redundancy/extra redundancy short fileRedundancy = getExpectedRedundancyNum(storedBlock); if (!isNeededReconstruction(storedBlock, num, pendingNum)) { neededReconstruction.remove(storedBlock, numCurrentReplica, num.readOnlyReplicas(), num.outOfServiceReplicas(), fileRedundancy); } else { updateNeededReconstructions(storedBlock, curReplicaDelta, 0); } if (shouldProcessExtraRedundancy(num, fileRedundancy)) { processExtraRedundancyBlock(storedBlock, fileRedundancy, node, delNodeHint); } ... return storedBlock; } -
当用户进行了手动降副本操作,比如,手动通过setReplica命令将副本从3降低到2,这时候这个Block的副本数量可能会超过预期并且有Replica在Stale DataNode上,就会将这个replica放到postponedMisreplicatedBlocks中,因为加入Stale DataNode上在Failover以前已经收到了删除命令,然后新的NameNode又在其他节点上进行删除,当Stale DataNode将副本成功删除,这个Block就会出现副本不足的情况。
用户的手动降副本将会调用到BlockManager.setReplication()方法,如下所示:java--------------------------------------------------------- BlockManager ------------------------------------------------ public void setReplication( final short oldRepl, final short newRepl, final BlockInfo b) { if (newRepl == oldRepl) { return; } b.setReplication(newRepl); NumberReplicas num = countNodes(b); updateNeededReconstructions(b, 0, newRepl - oldRepl); if (shouldProcessExtraRedundancy(num, newRepl)) { processExtraRedundancyBlock(b, newRepl, null, null); } } -
在尝试处理一个Corrupted Block的时候(markBlockAsCorrupt()方法),也可能将这个Block的某些replica进行invalidate操作(invalidateBlock()操作),如果发现这个corrupt的replica存在上述情况,并且配置的deleteCorruptReplicaImmediately(dfs.namenode.corrupt.block.delete.immediately.enabled配置,默认是true,即发现了corrupt replica执行立刻删除)也会放到postponedMisreplicatedBlocks中:
javaprivate boolean invalidateBlock(BlockToMarkCorrupt b, DatanodeInfo dn, NumberReplicas nr) throws IOException { // 如果在Stale节点上的副本数大于0,并且deleteCorruptReplicaImmediately = false,即配置的dfs.namenode.corrupt.block.delete.immediately.enabled=false if (nr.replicasOnStaleNodes() > 0 && !deleteCorruptReplicaImmediately) { postponeBlock(b.getCorrupted()); return false; } else { // 对这个replica执行立刻删除,前提是这个方法的调用者已经确认这个Block有足够的副本数了,删除不会造成问题 addToInvalidates(b.getCorrupted(), dn); removeStoredBlock(b.getStored(), node); blockLog.debug("BLOCK* invalidateBlocks: {} on {} listed for deletion.", b, dn); return true; } } -
当我们写完一个文件并关闭的时候,会立刻检查这个文件的所有Block的Redundancy。如果有任何Block的Replica数量超过了预期的Replica数量因此需要进行invalidate,但是有Replica在Stale DataNode上,就会将这个Block添加到postponedMisreplicatedBlocks中。这时候对于副本不足的Replica,也会添加到neededReconstruction中。
javapublic void checkRedundancy(BlockCollection bc) { for (BlockInfo block : bc.getBlocks()) { short expected = getExpectedRedundancyNum(block); final NumberReplicas n = countNodes(block); final int pending = pendingReconstruction.getNumReplicas(block); // 这个block还有几个replica没有收到DN的汇报 if (!hasEnoughEffectiveReplicas(block, n, pending)) { neededReconstruction.add(block, n.liveReplicas() + pending, n.readOnlyReplicas(), n.outOfServiceReplicas(), expected); } else if (shouldProcessExtraRedundancy(n, expected)) { processExtraRedundancyBlock(block, expected, null, null); } } }
从postponedMisreplicatedBlocks中移除Block
RedundancyMonitor这个Daemon线程负责重新扫描postponedMisreplicatedBlocks中的每一个Block,用来对这里的Block的状态进行重新的确认。重新扫描的逻辑发生在方法rescanPostponedMisreplicatedBlocks()中:
显然,postponedMisreplicatedBlocks中的Block会发生以下的各种情况:
- 最简单的,这个Block依然是over-replicated的:
- 但是有副本存放在Stale DataNode上,这时候什么也不用做,对这个Block的处理继续延迟
- 没有副本在Stale DataNode上,那么直接通过processExtraRedundancyBlock()进行over-replicated块的处理(比如删除多余replica等)
- 如果块的状态是已经删除,比如,对应文件已经删掉了,则加入到InvalidateBlocks中,这个块将被删除
- 这个块并不是COMPLETE状态,不做任何处理,不是块重构的处理范围。
- 检查发现这个Block需要进行Reconstruction(下文讲pendingReconstruction的时候会将isNeededReconstruction(),判断一个Block是否需要进行重构),那么就将其从postponedMisreplicatedBlocks中移除,转而加入到neededReconstruction
- 如果都不是,那么这个Block的状态完全正常,不需要处理。
2.2.3 待定队列(PendingReconstructionBlock)的构造和实现
pendingReconstruction是一个PendingReconstructionBlocks对象。
BlockManager中维护了PendingReconstructionBlocks pendingReconstruction对象,用来监控那些尚且需要获取更多已经存储的副本的Block:
java
class PendingReconstructionBlocks {
private final Map<BlockInfo, PendingBlockInfo> pendingReconstructions;
java
static class PendingBlockInfo {
private long timeStamp;
private final List<DatanodeStorageInfo> targets; // 这个block需要复制到的位置对pendingReconstruction的添加和删除操作
从PendingReconstructionBlocks的定义可以看到,pendingReconstructions是一个以block作为key、以PendingBlockInfo作为value的map,代表这个block对应的PendingBlockInfo里面的target尚未向NameNode进行汇报。
我们都知道客户端在写数据并且addBlock()的时候,NameNode会通过PlacementPolicy为这个Block寻找合适的target location并且返回给客户端,在这个block commit了以后, NameNode就会把这个block和对应的 target添加到PendingReconstructionBlocks中,意思是:这个block会写入到这些targets,但是我目前还没有收到这些targets对这个block的汇报,所以就把这个Block和它对应的targets 记录下来,当收到了DataNode的汇报以后,就把这个DataNode从这个block的记录里删除,如果这个blocks的所有targets都汇报了这个block,就可以把这个block从pendingReconstructions中彻底删除。
PendingReconstructionBlocks.increment()方法是向PendingReconstructionBlocks对象中添加targets记录的方法,我们跟踪这个方法的调用者,可以看到什么时候NameNode会往pendingReconstruction中添加block -> targets 记录:
- 客户端在addBlock()的时候:往往在创建新的block以前,需要确认当前文件的最后一个block是commit的状态,因此,如果这个block commit成功了,那么会将这当前的最后一个block -> targets 添加到pendingReconstructions中
- 客户端在close()文件的时候: 客户端关闭文件的时候,当所有的Block已经写到DataNode,客户端会向NameNode发起close文件的请求,NameNode收到请求以后,会通过addCommittedBlocksToPending()方法,将Block -> targets对应关系添加到pendingReconstructions中
- DataNode进行块汇报的时候:NameNode收到来自DataNode的block report,会通过addCommittedBlocksToPending()方法将这个block当前还期待的但是没有收到report的block -> targets的关系放到pendingReconstruction中
与PendingReconstructionBlocks.increment()相反,PendingReconstructionBlocks.decrement()会将一个block -> datanode的对应关系从pendingReconstruction中删除,这发生在DataNode在通过DatanodeProtocol.blockReceivedAndDeleted 接口进行增量块汇报的时候,会将这个block -> datanode的对应关系从pendingReconstruction中删除。同时,如果这个block对应的所有targets都已经完成了汇报,就把block从这个 pendingReconstruction中删除。
对pendingReconstruction的超时处理
上面讲过,PendingReconstructionBlocks就像Block的守护者一样,NameNode通过它可以知道目前还有哪些block在等待Datanode向上汇报的信息。正常情况下,一个block存放到在PendingReconstructionBlocks,当所有的targets完成块汇报,很快就会从pendingReconstruction中删除。但是,分布式系统中,任何异常状态都有可能发生,如果pendingReconstruction 中的某个Block所预期的DataNode始终没有全部汇报上来,应该怎么样呢?
原来,为了识别这种很长时间依然没有删除的block, PendingReconstructionBlocks通过一个单独的线程PendingReconstructionMonitor去监控所有添加进来的block并为每个添加进来的block记时,超过指定时间,就会被标记为超时是block:
java
--------------------------------------------- PendingReconstructionBlocks -----------------------------------------
/**
* Iterate through all items and detect timed-out items
*/
void pendingReconstructionCheck() {
synchronized (pendingReconstructions) {
Iterator<Map.Entry<BlockInfo, PendingBlockInfo>> iter =
pendingReconstructions.entrySet().iterator();
long now = monotonicNow();
while (iter.hasNext()) {
Map.Entry<BlockInfo, PendingBlockInfo> entry = iter.next();
PendingBlockInfo pendingBlock = entry.getValue();
if (now > pendingBlock.getTimeStamp() + timeout) {
BlockInfo block = entry.getKey();
timedOutItems.add(block);
....
iter.remove();
}
}
}
}对于已经timeout的Block,随后,在RedundancyMonitor线程的每一轮运行中,都会通过方法processPendingReconstructions()尝试去处理:
java
private class RedundancyMonitor implements Runnable {
@Override
public void run() {
while (namesystem.isRunning()) { // 这是一个无限循环,只要是active namenode,就不断运行
try {
// Process recovery work only when active NN is out of safe mode.
if (isPopulatingReplQueues()) {
computeDatanodeWork(); // 选择并且将需要re-construct的节点发送给对应的Node 去执行
processPendingReconstructions(); // 看看pendingReconstruction 中有哪些block需要加入到neededConstruction 中去
rescanPostponedMisreplicatedBlocks();
/**
* If there were any reconstruction requests that timed out, reap them
* and put them back into the neededReconstruction queue
*/
void processPendingReconstructions() {
// pendingReconstruction主要来自与文件最后close的时候的最后一个block,在这里,如果pendingReconstruction
// 中的block在指定时间内依然没有完成construction,那么就需要放到neededConstruction中去
BlockInfo[] timedOutItems = pendingReconstruction.getTimedOutBlocks();
// .......
for (int i = 0; i < timedOutItems.length; i++) {
BlockInfo bi = blocksMap.getStoredBlock(timedOutItems[i]);
NumberReplicas num = countNodes(timedOutItems[i]);
if (isNeededReconstruction(bi, num)) { //这个pendingReconstruction 中的block的确需要re-construction
neededReconstruction.add(bi, num.liveReplicas(),
num.readOnlyReplicas(), num.outOfServiceReplicas(),
getExpectedRedundancyNum(bi));
}
}
} finally {
namesystem.writeUnlock();如上面代码所示,RedundancyMonitor线程会从pendingReconstruction取出超时的blocks,如果发现这些block需要进行重构,则将这需要重构的block加入到neededReconstruction中。下一轮循环过来,就会通过computeDatanodeWork()对needConstruction中需要重构的block进行处理。而一个block是否需要重构的判断入下代码所示:
我们上文已经讲过isNeededReconstruction()方法的判断逻辑,这里不再赘述。
2.2.4 重构队列(neededReconstruction)的构造和实现
neededReconstruction指的是一个LowRedundancy对象。
BlockManager中有一个LowRedundancyBlocks neededReconstruction对象,记录了当前需要进行reconstruction的所有block。
由于不同情况的恢复优先级不同(比如,3副本情况下丢失1个副本和丢失2个副本的紧急程度显然不同,RS(6,2)的情况下丢失1个replica和丢失2个replica的紧急程度显然不同),LowRedundancyBlocks对象根据紧急程度定义了优先级,每个优先级都有一个对应的block队列,代表了这个block需要进行该优先级的re-construct。
java
class LowRedundancyBlocks implements Iterable<BlockInfo> {
static final int QUEUE_HIGHEST_PRIORITY = 0;
static final int QUEUE_VERY_LOW_REDUNDANCY = 1;
static final int QUEUE_LOW_REDUNDANCY = 2;
static final int QUEUE_REPLICAS_BADLY_DISTRIBUTED = 3;
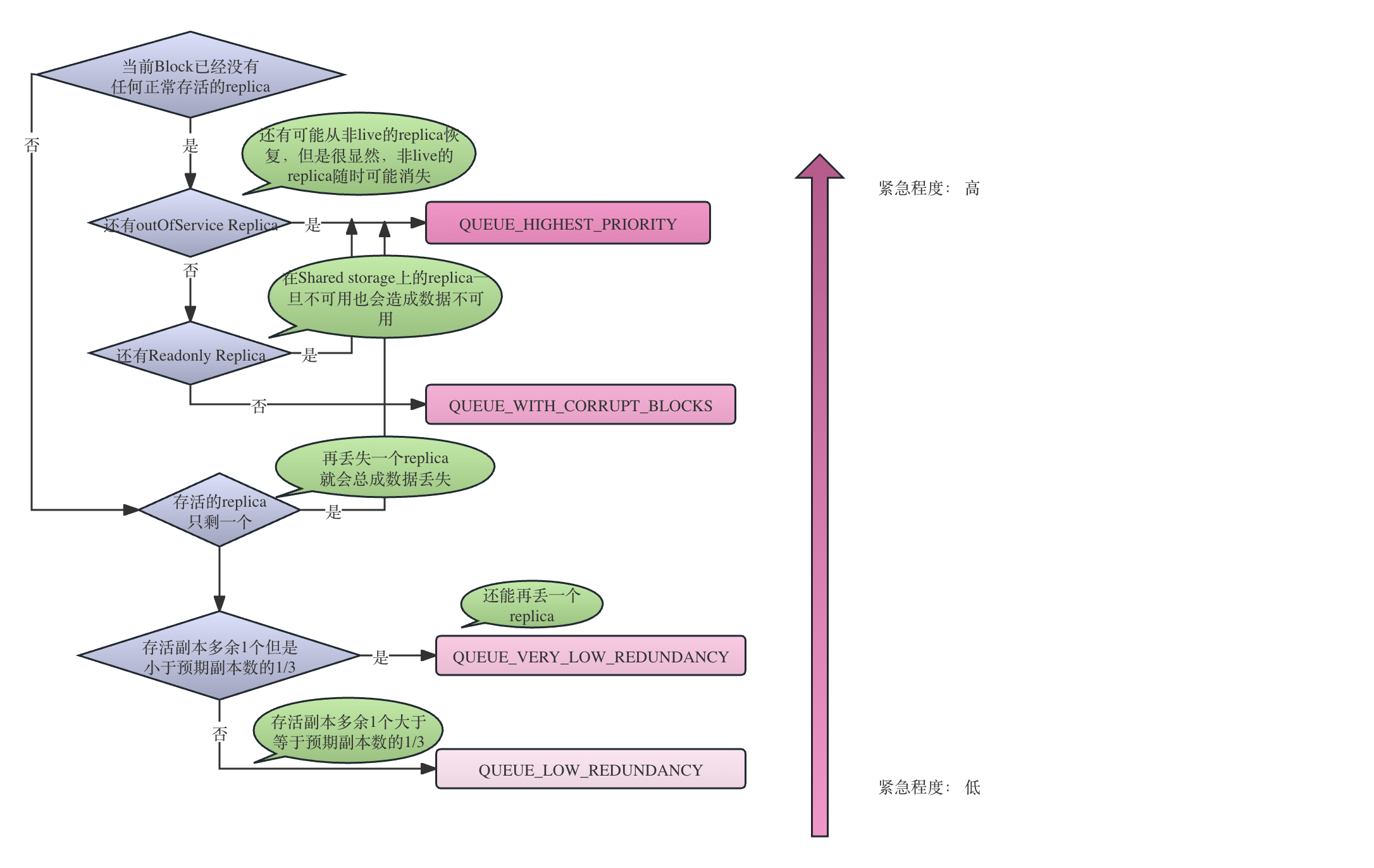
static final int QUEUE_WITH_CORRUPT_BLOCKS = 4;显然,对于连续布局和条带布局,确定优先级的基本思想一致,但是计算方式并不相同。我们通过getPriorityContiguous()方法和getPriorityStriped()方法可以清晰地看到对于两种布局方式确定其优先级的计算逻辑。
先抛开布局方式的差异,一般来讲,各种优先级的含义是:
QUEUE_HIGHEST_PRIORITY的最高优先级指的是这个block再丢失一个replica就会corrupt(无法再通过re-construct恢复),因此情况非常紧急。QUEUE_VERY_LOW_REDUNDANCY指的是这个Block再丢一个replica依然还有恢复的可能,但是丢两个就无法恢复了。QUEUE_LOW_REDUNDANCY则是指这个Block还能容忍两个或者两个以上的Replica的丢失而依然可以通过reconstruct来恢复数据。QUEUE_WITH_CORRUPT_BLOCKS则代表这个Block已经corrupt,不可能通过reconstruct恢复了,因此不用对其构建reconstruction任务。
java
/**
* @param curReplicas 当前live的replica
* @param readOnlyReplicas 处在READONLY状态的replica,
* @param outOfServiceReplicas 指的是状态处在MAINTENANCE_NOT_FOR_READ || MAINTENANCE_FOR_READ || DECOMMISSIONED || DECOMMISSIONING的replica
* @param expectedReplicas 预期的replica数量,比如我们配置的文件副本数量为3
*/
private int getPriorityContiguous(int curReplicas, int readOnlyReplicas,
int outOfServiceReplicas, int expectedReplicas) {
if (curReplicas == 0) {
// If there are zero non-decommissioned replicas but there are
// some out of service replicas, then assign them highest priority
if (outOfServiceReplicas > 0) {
return QUEUE_HIGHEST_PRIORITY;
}
if (readOnlyReplicas > 0) {
// only has read-only replicas, highest risk
// since the read-only replicas may go down all together.
return QUEUE_HIGHEST_PRIORITY;
}
//all we have are corrupt blocks
return QUEUE_WITH_CORRUPT_BLOCKS;
} else if (curReplicas == 1) {
// only one replica, highest risk of loss
// highest priority
return QUEUE_HIGHEST_PRIORITY;
} else if ((curReplicas * 3) < expectedReplicas) {
//can only afford one replica loss 还能再承受一个replica loss,即如果还有两个replica loss,数据就丢失了,block就corrupt了
//this is considered very insufficiently redundant blocks.
return QUEUE_VERY_LOW_REDUNDANCY;
} else {
//add to the normal queue for insufficiently redundant blocks
return QUEUE_LOW_REDUNDANCY;
}
}
/**
* @param curReplicas 当前live的replica的数量
* @param outOfServiceReplicas 指的是状态处在MAINTENANCE_NOT_FOR_READ || MAINTENANCE_FOR_READ || DECOMMISSIONED || DECOMMISSIONING的replica
* @param dataBlkNum 配置的预期的数据块的数量,比如RS(6,2)中,dataBlkNum=6
* @param parityBlkNum 配置的预期的校验块的数量,比如RS(6,2)中,parityBlkNum=2
*/
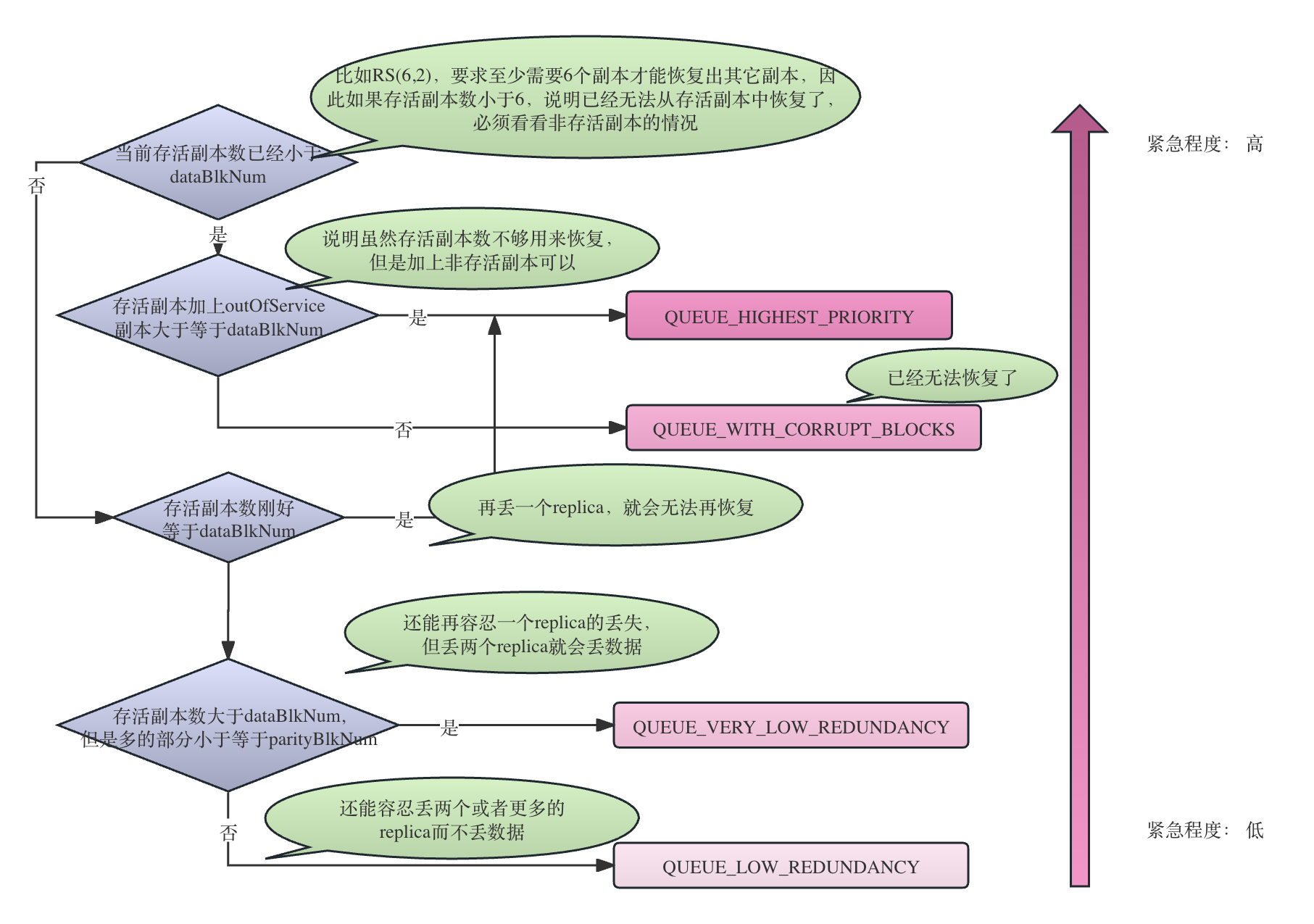
private int getPriorityStriped(int curReplicas, int outOfServiceReplicas,
short dataBlkNum, short parityBlkNum) {
if (curReplicas < dataBlkNum) {
// There are some replicas on decommissioned nodes so it's not corrupted
if (curReplicas + outOfServiceReplicas >= dataBlkNum) { //有一部分replica在decommissiong 节点上,因此它还没有corrupt,但是必须立刻恢复了
return QUEUE_HIGHEST_PRIORITY;
}
return QUEUE_WITH_CORRUPT_BLOCKS; // 已经corrupt了,无法恢复了
} else if (curReplicas == dataBlkNum) { // 再丢失一个replica数据就无法恢复了
// highest risk of loss, highest priority
return QUEUE_HIGHEST_PRIORITY;
} else if ((curReplicas - dataBlkNum) * 3 < parityBlkNum + 1) {
// can only afford one replica loss
// this is considered very insufficiently redundant blocks.
return QUEUE_VERY_LOW_REDUNDANCY; // 再丢失一个replica就corrupt了
} else {
// add to the normal queue for insufficiently redundant blocks.
return QUEUE_LOW_REDUNDANCY;// 一般优先级
}
}条带布局的优先级计算方法如下图所示:
连续布局的优先级计算方法如下图所示:
LowRedundancyBlocks会通过getPriorityContiguous()获取优先级,然后将对应的需要进行reconstruct的block放入到对应的优先级队列中:
java
private boolean add(BlockInfo blockInfo, int priLevel, int expectedReplicas) {
if (priorityQueues.get(priLevel).add(blockInfo)) {
return true;
}
return false;
}向neededReconstruction中添加块
我们查看LowRedundancyBlock.add()方法的调用堆栈,可以看到向neededReconstruction中添加Block的各种情况:
-
在BlockManager中的Daemon Thread对BlocksMap中的所有快进行扫描的时候,会判断这个块是否需要进行Reconstruction,如果需要(isNeededReconstruction()方法返回true),则放到neededReconstruction中:
java------------------------------------------------ BlockManager ---------------------------------------------------- private MisReplicationResult processMisReplicatedBlock(BlockInfo block) { ...... NumberReplicas num = countNodes(block); final int numCurrentReplica = num.liveReplicas(); // add to low redundancy queue if need to be if (isNeededReconstruction(block, num)) { if (neededReconstruction.add(block, numCurrentReplica, num.readOnlyReplicas(), num.outOfServiceReplicas(), expectedRedundancy)) { return MisReplicationResult.UNDER_REPLICATED; } } -
线程DatanodeAdminDefaultMonitor会负责对用户的
-refreshNodes操作导致的需要、需要进入DECOMMISSION或者MAINTENANCE状态的节点进行处理和块扫描,因为一个Node如果要从ENTERING_MAINTENANCE进入IN_MAINTENANCE,或者从DECOMMISSION_IN_PROGRESS进入DECOMMISSIONED,需要确保它们上面的块的副本数量满足特定要求。DatanodeAdminDefaultMonitor会扫描这些机器上的所有快,对于不满足要求的块调度对应的BlockReconstructionWork以增加副本,使得这些机器尽快进入DECOMMISSIONED或者IN_MAINTENANCE状态。java--------------------------------------- DatanodeAdminDefaultMonitor ------------------------------------------- private void processBlocksInternal(......) { // fullscan的时候,pruneReliableBlocks=false while (it.hasNext()) { // 循环遍历每一个Block if (insufficientList == null // 增量剪枝扫描的时候insufficientList == null boolean isDecommission = datanode.isDecommissionInProgress(); boolean isMaintenance = datanode.isEnteringMaintenance(); boolean neededReconstruction = isDecommission ? blockManager.isNeededReconstruction(block, num) : // 有效存活副本(live)并不充足(小于required) blockManager.isNeededReconstructionForMaintenance(block, num); if (neededReconstruction) { if (!blockManager.neededReconstruction.contains(block) && blockManager.pendingReconstruction.getNumReplicas(block) == 0 && blockManager.isPopulatingReplQueues()) { // Process these blocks only when active NN is out of safe mode. blockManager.neededReconstruction.add(block, liveReplicas, num.readOnlyReplicas(), num.outOfServiceReplicas(), blockManager.getExpectedRedundancyNum(block)); } }- 在我的另一篇文章TODO中详细讲解了DECOMMISSION的基本过程和DatanodeAdminDefaultMonitor线程的处理逻辑,有兴趣的读者可以自行阅读,这里不再重复叙述。
-
和上面将的postponedMisreplicatedBlocks一样,当我们写完一个文件并关闭的时候,会立刻检查这个文件的所有Block的Redundancy。如果发现这个Block没有足够的有效副本(hasEnoughEffectiveReplicas()==false),就会将这个Block添加到neededReconstruction中:
javapublic void checkRedundancy(BlockCollection bc) { for (BlockInfo block : bc.getBlocks()) { short expected = getExpectedRedundancyNum(block); final NumberReplicas n = countNodes(block); final int pending = pendingReconstruction.getNumReplicas(block); // 这个block还有几个replica没有收到DN的汇报 if (!hasEnoughEffectiveReplicas(block, n, pending)) { neededReconstruction.add(block, n.liveReplicas() + pending, n.readOnlyReplicas(), n.outOfServiceReplicas(), expected); } else if (shouldProcessExtraRedundancy(n, expected)) { processExtraRedundancyBlock(block, expected, null, null); // 这里可能生成postponedMisreplicatedBlocks } } } -
来自pendingReconstruction的转换。pendingReconstruction主要来自与文件最后close的时候的最后一个block,在这里,如果pendingReconstruction中的block在指定时间内依然没有完成construction,那么就需要放到neededConstruction中去
javavoid processPendingReconstructions() { // pendingReconstruction主要来自与文件最后close的时候的最后一个block,在这里,如果pendingReconstruction // 中的block在指定时间内依然没有完成construction,那么就需要放到neededConstruction中去 BlockInfo[] timedOutItems = pendingReconstruction.getTimedOutBlocks(); if (timedOutItems != null) { namesystem.writeLock(); try { for (int i = 0; i < timedOutItems.length; i++) { BlockInfo bi = blocksMap.getStoredBlock(timedOutItems[i]); // BlockInfo是一个block group if (bi == null || bi.isDeleted()) { continue; } NumberReplicas num = countNodes(timedOutItems[i]); if (isNeededReconstruction(bi, num)) { //这个pendingReconstruction 中的block的确需要re-construction neededReconstruction.add(bi, num.liveReplicas(), num.readOnlyReplicas(), num.outOfServiceReplicas(), getExpectedRedundancyNum(bi)); }
从neededReconstruction中删除块
显然,neededReconstruction中删除块是因为块不再是low-redundancy了,即副本数量从之前的不满足要求变为现在的满足要求。这是来自于DataNode 的块汇报。Block Report中新的Block会通过调用addStoredBlock()添加进来,同时会检查这个新的Block的redundancy的状态,如果已经不再是low-redundancy,尝试将这个Block从neededReconstruction中删除:
java
/**
* 区分addStoredBlock()和addLocatedBlock(). stored block是指
* 已经被dn存储下来的block
* 注意,汇报上来的准确来讲是一个replica,这个replica属于BlocksMap中的某一个block,
*/
private Block addStoredBlock(final BlockInfo block,
final Block reportedBlock,
DatanodeStorageInfo storageInfo,
DatanodeDescriptor delNodeHint,
boolean logEveryBlock)
throws IOException {
// handle low redundancy/extra redundancy
short fileRedundancy = getExpectedRedundancyNum(storedBlock);
if (!isNeededReconstruction(storedBlock, num, pendingNum)) {
neededReconstruction.remove(storedBlock, numCurrentReplica,
num.readOnlyReplicas(), num.outOfServiceReplicas(), fileRedundancy); // 从neededReconstruction中彻底删除
} else { //多了一个replica,但是依然还是neededReconstruction的状态,需要进行更新
updateNeededReconstructions(storedBlock, curReplicaDelta, 0);
}
if (shouldProcessExtraRedundancy(num, fileRedundancy)) {
processExtraRedundancyBlock(storedBlock, fileRedundancy, node,
delNodeHint); // 这里这个Block可能会被添加到postponedMisreplicatedBlocks中
}
.......
}是否需要重构(isNeededReconstruction()方法)的判断逻辑
java
boolean isNeededReconstruction(BlockInfo storedBlock,
NumberReplicas numberReplicas) {
// 不考虑pending的replica,这个block的存活replica的数量大于等于期望的副本数量(块的副本数)
return isNeededReconstruction(storedBlock, numberReplicas, 0);
}可以看到,当且仅当这个块是一个COMPLETE的块 (不是一个正在写入的块或者损坏的块),并且没有足够的有效Replica,那么这个Block就是一个需要Reconstruction的Block:
java
boolean isNeededReconstruction(BlockInfo storedBlock,
NumberReplicas numberReplicas, int pending) {
return storedBlock.isComplete() &&
!hasEnoughEffectiveReplicas(storedBlock, numberReplicas, pending);
}所以,核心方法在于hasEnoughEffectiveReplicas():
java
// 如果 live + pending replicas 的数量不小于所需要的replica数量,并且(还有pending的replica,或者没有pending的并且已经满足放置策略)
// 这里的含义是,如果有pending的,那么我们先不用考虑是否满足placement policy
boolean hasEnoughEffectiveReplicas(BlockInfo block,
NumberReplicas numReplicas, int pendingReplicaNum) {
int required = getExpectedLiveRedundancyNum(block, numReplicas); // 先看看需要多少个live的副本
int numEffectiveReplicas = numReplicas.liveReplicas() + pendingReplicaNum;
return (numEffectiveReplicas >= required) &&
(pendingReplicaNum > 0 || isPlacementPolicySatisfied(block));
}从hasEnoughEffectiveReplicas()方法可以看到,如果一个块的有效replica(Effective Replica)的数量不小于所期望的存活Replica 的数量,并且这个块的放置状态也满足要求,或者尽管放置状态不满足要求但是还有pending的replica(没有来得及汇报的replica,也许这个汇报上来的replica会让放置状态从不满足要求变为满足要求),那么我们认为这个Block有足够的有效replica(Effective Replica)。反之则认为没有足够的有效replica(Effective Replica)。
那么,一个块的所期望的存活Replica 是怎么计算的呢?这是在方法getExpectedLiveRedundancyNum()中计算的:
java
// 期望的最少的live replica的数量
public short getExpectedLiveRedundancyNum(BlockInfo block,
NumberReplicas numberReplicas) {
// 对于striped block,expectedRedundancy 数量指的是data block + parity block的数量,
// 对于replication,expectedRedundancy指的是replication factor
final short expectedRedundancy = getExpectedRedundancyNum(block);
// 假如当前我的block配置的副本是5, 有2个副本是处于maintenance,那么我期待的live 副本数量是5-2=3
return (short)Math.max(expectedRedundancy -
numberReplicas.maintenanceReplicas(), // 处于maintenance中的replica也算是live,这本身就是maintenance的目的,让replica短时间可以容忍丢失,但是处于decommission的不能算live
// 最小的maintenance 副本数量。对于striped block,最小的maintenance副本数量就是data block 的数量,说明对于
// stripe block, 不允许data block丢失
getMinMaintenanceStorageNum(block));
}从上面的getExpectedLiveRedundancyNum()方法可以看到
- 如果一个Block的所有Replica没有任何一个有诸如IN_MAINTENANCE或者DECOMMISSIONED等特殊状态,那么期望的存活副本数就是系统配置的Replication Factor(Erasure Coding又是另外的计算方式,具体可以参考 TODO这篇文章)。
- 如果有节点处于IN_MAINTENANCE状态,那么会进行一些特殊处理。即,如果有的Replica所在的节点处于MAINTENANCE并且节点正常存活,那么期望的节点需要减去处于MAINTENANCE状态的副本数量,或者,等于最小的MAINTENANCE副本数量(
dfs.namenode.maintenance.replication.min所配置,默认是1),两者的较大值。
这里,我们梳理了一下上述方法所涉及到的副本的一些状态和数量定义:
- 什么是待定副本数(Pending Replica): 就是我们讲的PendingReconstructionBlocks对象维护的replica -> targets信息,即一个block写完(COMMITTED或者COMPLETED)但是NameNode还没收到足够的DataNode汇报,那么预期还需要收到多少个DataNode的汇报的数量。比如3副本的Block,NameNode目前只收到1个DataNode的汇报,那么这个Block的pendingReplicaNum是2。
- 什么叫有效副本数量(Effective Replicas) :从方法
hasEnoughEffectiveReplicas()的代码int numEffectiveReplicas = numReplicas.liveReplicas() + pendingReplicaNum;,即存活状态的副本数量再加上待定状态的副本数量。存活状态的副本是有效副本很容易理解,但是为什么待定的副本也算作有效副本呢?因为待定的副本是正常状态下还缺失的待汇报的数量,这种缺失是很正常的,正常情况下只需要再等等就可以,因此,待定的副本也算作有效。 - 什么叫允许进入Maintenance状态的最小存活副本数 :即要想将某一个replica所载的DataNode进入maintenance状态,那么这个DataNode上的每一个Block需要多少个存活的副本?这是为了避免某个节点进入maintenance状态造成了某些数据不可读的状态。从方法
getMinMaintenanceStorageNum()可以看到,对于纠删码,如果进入ENTERING_MAINTENANCE状态以后,依然最少有dataBlockNum个副本存活,那么这个replica就可以进入Maintenance状态。对于3副本,这个默认值是1,即ENTERING_MAINTENANCE的节点中,如果所有的Block都至少有一个存活的副本,那么这个Datanode就可以正式进入MAINTENANCE状态。这就是为什么StoredReplicaState在进入正式的MAINTENANCE状态以前,有一个ENTERING_MAINTENANCE状态,在ENTERING_MAINTENANCE状态时,DataNode会有对应的Monitor确认所有的Block的live replica数量都大于getMinMaintenanceStorageNum(),才会从ENTERING_MAINTENANCE进入到IN_MAINTENANCE状态,避免进入到IN_MAINTENANCE状态(进入IN_MAINTENANCE状态以后的节点很可能出现短时不可服务,比如短暂的关机维修升级等)以后导致数据副本缺失。 - 当前期望的存活副本数量 (Expected Live Redundancy): 从
getExpectedLiveRedundancyNum()方法的return (short)Math.max(expectedRedundancy - numberReplicas.maintenanceReplicas(),getMinMaintenanceStorageNum(block));代码可以看到,不考虑特殊情况,对于连续布局,期望的副本数量就是配置的副本数,对于纠删码,期待的副本数量就是dataBlocksNum + parityBlocksNum, 比如RS(6,2)中等于8。但是,由于有些Block的部分副本有可能处于maintenance状态,这些副本虽然暂时不可用,但是并没有丢失,因此,期待的副本数量应该减去这些处于Maintenance状态的副本。比如RS(6,2)中,有3个副本都处于maintenance状态,那么我期待的存活副本数量是8-3=5。同时期望的存活副本数量应该不小于允许进入maintenance的最小存活副本数量。 - 什么叫足够多的有效Replica : 即当前有效的副本数量不小于期望的副本数量,并且当前还有pending的副本,或者虽然没有pending的副本,但是整个Block的replica分布处于满足PlacementPolicy要求的状态。
- 这意味着如果有效的副本数量不小于期望的副本数量,并且还有pending的副本,这时候即使整个Block的副本不满足 PlacementPolicy要求的状态,也认为有足够多的有效Replica ,这样判定是因为存在pending的副本,所以认为极有可能当pending的副本的DataNode汇报上来以后,
PlacementPolicy就会被满足。
- 这意味着如果有效的副本数量不小于期望的副本数量,并且还有pending的副本,这时候即使整个Block的副本不满足 PlacementPolicy要求的状态,也认为有足够多的有效Replica ,这样判定是因为存在pending的副本,所以认为极有可能当pending的副本的DataNode汇报上来以后,
2.3 RedundancyMonitor的运行
上面介绍了待重构的块的生成过程。下面,就是针对这些块进行具体的重构工作了。块的重构是由一个持续运行的Daemon线程RedundancyMonitor负责调度的,由于待重构的Block信息逗存放在BlockManager.neededReconstruction(重构队列)中,因此RedundancyMonitor主要功能就是从重构队列中取出Block,构造重构任务,调度出去。同时,它还负责从待定队列中取出那些超时的Block,以及从延迟队列中取出已经不需要继续延迟(Stale状态结束)的节点,如果这些节点需要重构,则创建重构任务和调度重构任务。
3. RedundancyMonitor的工作原理
下图显示了块重构的基本流程,从图中我们可以看到:
- 待重构块的发现是由NameNode负责的
- 待重构快的重构策略(从哪里读取,写入到哪里去)是由RedundancyMonitor决定的
- 任务调度出去以后,对应的DataNode会执行对应的重构任务。如果是基于复制(Replication Factor),重构过程相对简单,就是数据的拷贝。如果是基于纠删码(Erasure Coding),整个过程会更加复杂,因为这涉及到向不同的节点读取stripe然后通过计算还原数据的过程。
- DataNode重构完成以后,会向NameNode进行对应的IBR(Incremental Block Report),DataNode进而更新Block的状态以根据需求制定新的策略。
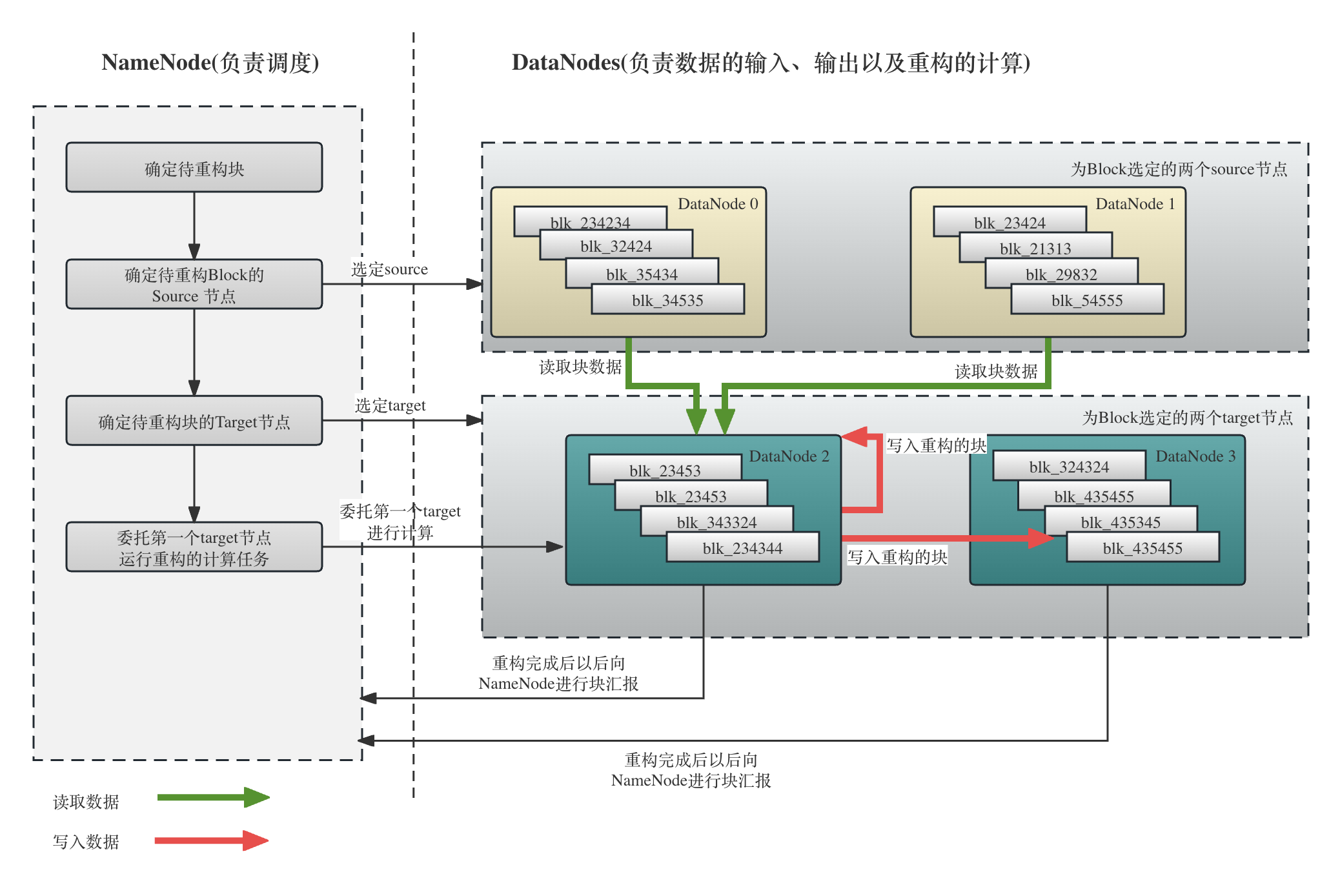
下面是RedundancyMonitor的基本结构代码。可以看到RedundancyMonitor是一个Runnable。这个Runnable是一个独立运行的线程,每一轮运行结束以后都会sleep一段时间(由dfs.namenode.redundancy.interval.seconds配置,默认是3s)然后继续进行:
java
private class RedundancyMonitor implements Runnable {
@Override
public void run() {
while (namesystem.isRunning()) { // 这是一个无限循环,只要是active namenode,就不断运行
try {
// Process recovery work only when active NN is out of safe mode.
if (isPopulatingReplQueues()) {
computeDatanodeWork(); // 从重构队列中取出Block, 选择并且将需要re-construct的节点发送给对应的Node 去执行
processPendingReconstructions(); // 从待定队列中取出Block,,如果需要reconstruct,加入到neededReconstruction中
rescanPostponedMisreplicatedBlocks(); // 从延迟队列中取出Block,如果需要reconstruct,加入到neededReconstruction中
}
TimeUnit.MILLISECONDS.sleep(redundancyRecheckIntervalMs);
.....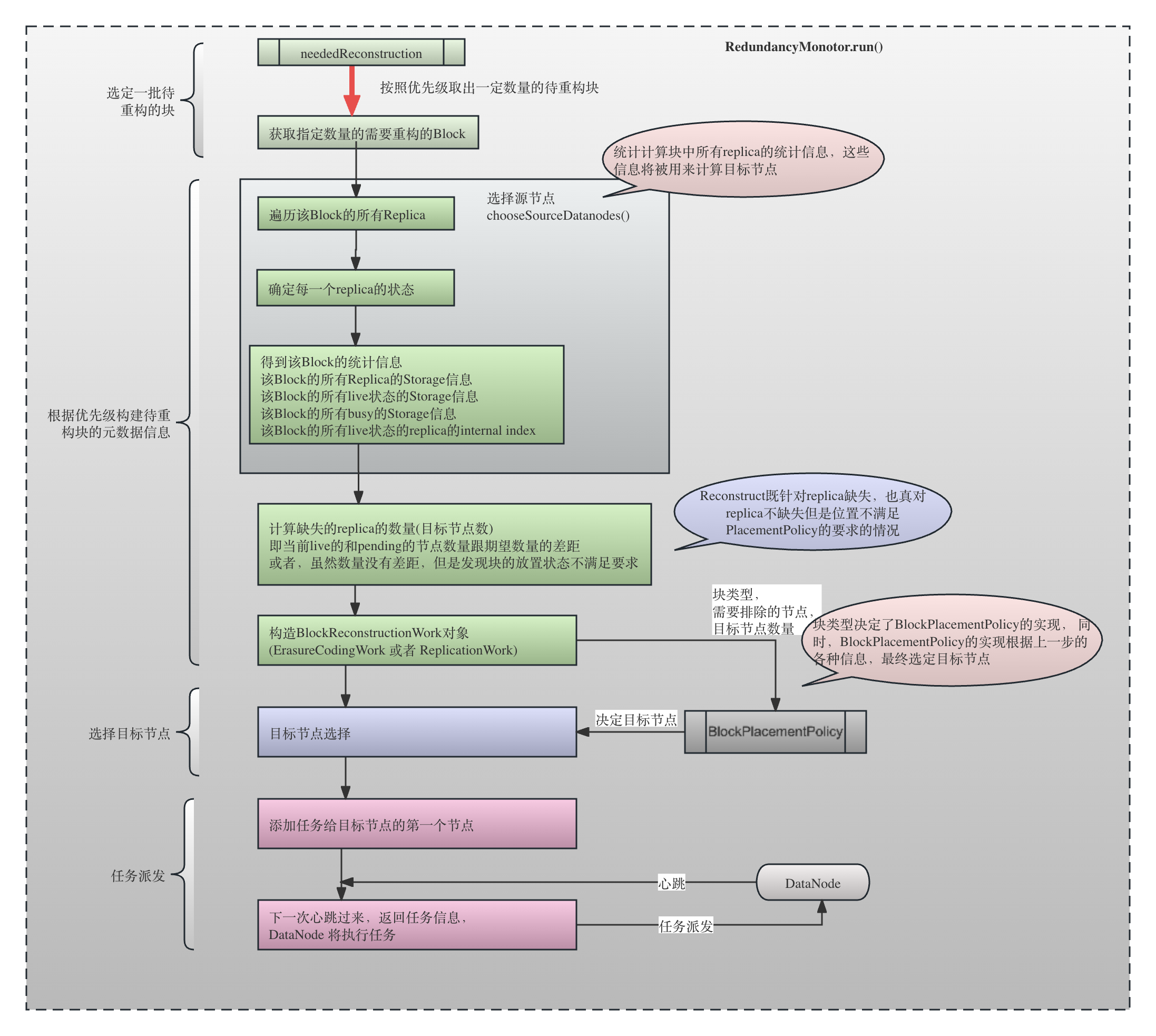
3.1 从优先级队列中选择待重构块
RedundancyMonitor的computeDatanodeWork()负责创建块重建的任务并调度出去。
RedundancyMonitor对应的Daemon 线程会根据LowRedundancyBlocks neededReconstruction中维护的优先级队列,按照优先级选择Block, 构造对应的ReconstructionTask。通过blocksToProcess控制每轮循环最多需要进行re-construct的block的数量,每次循环都通过bookmark的方式从上一轮循环处理的位置接着进行。LowRedundancyBlocks.chooseLowRedundancyBlocks()方法就是负责按照优先级从高到低的顺序取出这些low-redundancy的块,试图构造BlockReconstructionWork:
java
----------------------------------------------- LowRedundancyBlocks ----------------------------------------------
synchronized List<List<BlockInfo>> chooseLowRedundancyBlocks(
int blocksToProcess, boolean resetIterators) {
final List<List<BlockInfo>> blocksToReconstruct = new ArrayList<>(LEVEL);
int count = 0;
int priority = 0;
HashSet<BlockInfo> toRemove = new HashSet<>();
// 依次遍历每一个LEVEL的queue,形成一个需要进行re-construct的List<List>, 外层list就是优先级,内层list就是这个优先级下面的需要进行re-construct的block
for (; count < blocksToProcess && priority < LEVEL; priority++) {
final boolean inCorruptLevel = (QUEUE_WITH_CORRUPT_BLOCKS == priority);
// 这个PriorityQueue的bookmark,每次循环都从上一次循环的位置开始,而不是重新开始
final Iterator<BlockInfo> i = priorityQueues.get(priority).getBookmark();
final List<BlockInfo> blocks = new LinkedList<>();
if (!inCorruptLevel) { // 因为corrupt block已经没有恢复的必要了
blocksToReconstruct.add(blocks);
}
for(; count < blocksToProcess && i.hasNext(); count++) {
BlockInfo block = i.next();
if (block.isDeleted()) { // 这个block在neededReconstruction中,但是其实已经被NN删除了,因此必须要构造re-construct了
toRemove.add(block);
continue;
}
if (!inCorruptLevel) {
blocks.add(block);
}
}
for (BlockInfo bInfo : toRemove) {
remove(bInfo, priority); // 这个Block已经被系统删除了(比如,文件删除了),因此已经不需要reconstruct了
}
toRemove.clear();
}
....
return blocksToReconstruct;
}我们在上文讲解过,重构队列(neededReconstruction)是一个优先级队列,重构任务的创建和调度肯定是按照优先级从高到底进行。在LowRedundancyBlocks.chooseLowRedundancyBlocks()中可以看到基于优先级从重构队列中获取Block的逻辑:
java
int computeBlockReconstructionWork(int blocksToProcess) {
List<List<BlockInfo>> blocksToReconstruct = null;
namesystem.writeLock();
........
// Choose the blocks to be reconstructed
blocksToReconstruct = neededReconstruction // blocksToProcess存储了每次最多可以处理的blocks的数量
.chooseLowRedundancyBlocks(blocksToProcess, reset); // 每次最多处理blocksToProcess个,然后每次都是从上次的bookmark的位置接着进行
......
// 根据挑选的 需要进行reconstruct的block,对他们进行重新构建
return computeReconstructionWorkForBlocks(blocksToReconstruct);
}
// 选择那些处于风险中的块,按照优先级构成一个2层list。注意,这时候只是选出了需要进行重构的Block,至于怎么重构,需要computeReconstructionWorkForBlocks()来确定
synchronized List<List<BlockInfo>> chooseLowRedundancyBlocks(
int blocksToProcess, boolean resetIterators) {
final List<List<BlockInfo>> blocksToReconstruct = new ArrayList<>(LEVEL);
int count = 0;
int priority = 0;
HashSet<BlockInfo> toRemove = new HashSet<>();
// 依次遍历每一个LEVEL的queue,形成一个需要进行re-construct的List<List>, 外层list就是优先级,内层list就是这个优先级下面的需要进行re-construct的block
for (; count < blocksToProcess && priority < LEVEL; priority++) {
// Go through all blocks that need reconstructions with current priority.
// Set the iterator to the first unprocessed block at this priority level
// We do not want to skip QUEUE_WITH_CORRUPT_BLOCKS because we still need
// to look for deleted blocks if any.
final boolean inCorruptLevel = (QUEUE_WITH_CORRUPT_BLOCKS == priority);
// 这个PriorityQueue的bookmark,每次循环都从上一次循环的位置开始,而不是重新开始
final Iterator<BlockInfo> i = priorityQueues.get(priority).getBookmark();
final List<BlockInfo> blocks = new LinkedList<>();
if (!inCorruptLevel) { // 因为corrupt block已经没有恢复的必要了
blocksToReconstruct.add(blocks);
}
.......
return blocksToReconstruct;
}
}可以看到,chooseLowRedundancyBlocks每次都按照优先级从高到低的顺序,最多选取blocksToProcess 个Block进行重构。请注意,整个分布式系统是一个不断变化的系统,从重构队列中取出的Block很可能已经不需要再重构了,比如(文件已经删除,由于DataNode恢复因此块状态已经完全恢复)等,所以从重构队列中取出的块都会时刻进行状态的重新判断,只有确定这个块的确需要重构,才会放入到blocksToReconstruct。
3.2 构建待重构块的统计信息和元数据信息,为选择source节点做准备
在上一节选定了需要进行重构的Block(基于复制或者基于纠删码),下面,就开始对这个块的信息进行分析,比如,这个Block是基于复制还是基于基于纠删码,这个Block的每一个replica在哪里(比如EC编码中每一个Internal Block的Storage信息,或者基于复制的Block的每一个Replica的信息),每一个replica的状态是什么样的(LIVE, DECOMMISSIONGING, MAINTENANCE_FOR_READ...),目前丢失因此需要重构的physical block有几个,是哪些(比如EC编码中用internal block index表示,而在复制方式中则只需要关心还缺几个副本)。
由于重构的读取过程显然会带来对应source节点的负载,假如有多种选择方案(比如,ReplicationWork中,有两个副本可用,只需要选择一个source replica拷贝到第三个节点,选哪个更好?),那么基本原则是选择负载最轻的、对系统运行影响最小的节点。
java
// 为chooseLowRedundancyBlocks()返回的blocks构造BlockReconstructionWork,并调度出去
int computeReconstructionWorkForBlocks(
List<List<BlockInfo>> blocksToReconstruct) { // 按照优先级进行排列的,每一个List<BlockInfo>都是这个对应优先级的block的列表
List<BlockReconstructionWork> reconWork = new ArrayList<>();
....
// 对这些block的重构任务进行分类,构造BlockReconstructionWork的具体实现,ErasureCodingWork或者ReplicationWork
for (int priority = 0; priority < blocksToReconstruct
.size(); priority++) { // 优先级从高到低,0的优先级最高
for (BlockInfo block : blocksToReconstruct.get(priority)) {
// 创建对应的ReconstructionWork,但是还没有到挑选节点的阶段
BlockReconstructionWork rw = scheduleReconstruction(block,
priority);
if (rw != null) {
reconWork.add(rw);
}
......选择Source节点的逻辑在方法chooseSourceDataNodes()中,其基本思路为:
- 一个非正常不可读状态的Replica,肯定不会作为source节点,比如,StoredReplicaState.CORRUPT,StoredReplicaState.EXCESS,StoredReplicaState.MAINTENANCE_NOT_FOR_READ,StoredReplicaState.DECOMMISSIONED
- 考虑一个节点上目前已经分配的replica任务,超过了hard limit(
dfs.namenode.replication.max-streams-hard-limit,默认值为4), 即使是优先级最高的重构任务,也不会将该节点作为source节点 - 对于一个处于正在decommission(DECOMMISSIONING)或者正在准备进入maintenance(MAINTENANCE_FOR_READ),是比普通的正常replica更应该被选为source,因为这种状态的节点的workload往往很低,因此重构过程中对系统影响较小,其具体规则为:
- 如果是最高优先级(
LowRedundancyBlocks.QUEUE_HIGHEST_PRIORITY),不管该节点目前是LIVE,或者DECOMMISSIONING或者MAINTENANCE_FOR_READ, 只要该节点当前正在运行和准备运行的replica任务数量没有超过hard limit(dfs.namenode.replication.max-streams-hard-limit),那么依然会作为source nodes。 - 或者,虽然不是最高优先级,但是这个replica的状态是DECOMMISSIONING或者MAINTENANCE_FOR_READ,即使超过了soft limit(dfs.namenode.replication.max-streams),那么依然会作为source,因为这两个状态的Storage往往负载较低,是优选的对象。
- 或者,虽然优先级不高,并且replica的状态是LIVE状态(不是优选的DECOMMISSIONING或者MAINTENANCE_FOR_READ状态),只要该节点上的任务没有超过soft limit(
dfs.namenode.replication.max-streams),这个节点就可以作为source
下面是chooseSourceDatanodes()的代码,请注意,这些参数比如containingNodes, nodesContainingLiveReplicas,numReplicas,liveBlockIndices,liveBusyBlockIndices都是将这个Block对以的状态信息从方法里面带出方法外,供chooseSourceDatanodes()的调用者scheduleReconstruction()进行重构的下一步调度。
- containingNodes表示包含这个Block的某个replica的节点
- nodesContainingLiveReplicas 表示包含这个Block的某个replica并且状态为LIVE的节点的信息
- numReplicas 就是这个Block的各个replica的在各个StoredReplicaState的统计信息
- liveBlockIndices 只针对条带布局,可以看到liveBlockIndices不仅仅是包含LIVE状态的replica,而是经过chooseSourceDataNodes()的判断,认为可以从上面读取replica的节点的internal block index(比如节点是LIVE的状态,节点是MAINTENANCE_FOR_READ或者DECOMMISSIONING状态等),都放入到liveBlockIndices中。
- liveBusyBlockIndicies 只针对条带布局,所有处于LIVE或者DECOMMISSIONING并且这个节点上目前已经存在的复制任务超过一定数量
java
DatanodeDescriptor[] chooseSourceDatanodes(BlockInfo block,
List<DatanodeDescriptor> containingNodes,
List<DatanodeStorageInfo> nodesContainingLiveReplicas,
NumberReplicas numReplicas, // 传到这里的numReplicas是一个刚刚初始化、空的统计信息
List<Byte> liveBlockIndices,
List<Byte> liveBusyBlockIndices, int priority) {
if (isStriped) {
int blockNum = ((BlockInfoStriped) block).getTotalBlockNum(); // data unit + parity unit
liveBitSet = new BitSet(blockNum);
decommissioningBitSet = new BitSet(blockNum);
}
for (DatanodeStorageInfo storage : blocksMap.getStorages(block)) { // 对于存储这个Block的每一个 DatanodeStorageInfo
final DatanodeDescriptor node = getDatanodeDescriptorFromStorage(storage);//
final StoredReplicaState state = checkReplicaOnStorage(numReplicas, block, // 获取这个节点上的 replica的状态
storage, corruptReplicas.getNodes(block), false);
if (state == StoredReplicaState.LIVE) { //存活状态
if (storage.getStorageType() == StorageType.PROVIDED) {
storage = new DatanodeStorageInfo(node, storage.getStorageID(),
storage.getStorageType(), storage.getState());
}
nodesContainingLiveReplicas.add(storage); // 加入存活列表
}
containingNodes.add(node);
// do not select the replica if it is corrupt or excess
if (state == StoredReplicaState.CORRUPT ||
state == StoredReplicaState.EXCESS) { // CORRUPT和EXCESS状态不考虑
continue;
}
// Never use maintenance node not suitable for read
// or unknown state replicas.
if (state == null
|| state == StoredReplicaState.MAINTENANCE_NOT_FOR_READ) {
continue;// 不可读状态不考虑
}
if (state == StoredReplicaState.DECOMMISSIONED) { // 已经decommissioned,这个replica不考虑
if (decommissionedSrc == null ||
ThreadLocalRandom.current().nextBoolean()) {
decommissionedSrc = node;
}
continue;
}
byte blockIndex = -1;
if (isStriped) {
blockIndex = ((BlockInfoStriped) block)
.getStorageBlockIndex(storage); // 这个节点所存储的internal block的block index
countLiveAndDecommissioningReplicas(numReplicas, state,
liveBitSet, decommissioningBitSet, blockIndex);
}
if (priority != LowRedundancyBlocks.QUEUE_HIGHEST_PRIORITY
&& (!node.isDecommissionInProgress() && !node.isEnteringMaintenance())
&& node.getNumberOfBlocksToBeReplicated() >= maxReplicationStreams) { // maxReplicationStreams默认值是2
if (isStriped && (state == StoredReplicaState.LIVE
|| state == StoredReplicaState.DECOMMISSIONING)) {
liveBusyBlockIndices.add(blockIndex);
}
continue; // already reached replication limit 已经超过限制,查看下一个replica
}
if (node.getNumberOfBlocksToBeReplicated() >= replicationStreamsHardLimit) { // replicationStreamsHardLimit默认值是4
if (isStriped && (state == StoredReplicaState.LIVE
|| state == StoredReplicaState.DECOMMISSIONING)) {
liveBusyBlockIndices.add(blockIndex);
}
continue;
}
if(isStriped || srcNodes.isEmpty()) {
srcNodes.add(node);
if (isStriped) {
liveBlockIndices.add(blockIndex); // 加入到healthy block中
}
continue;
}
.....
} //循环结束
// 对于基于复制的布局方式,如果没有一个存活的节点包含replica,还没有找到一个srcNodes,但是发现了一个已经decommissioned节点包含,那么,依然准备使用这个 decommissioned节点
// Pick a live decommissioned replica, if nothing else is available.
if (!isStriped && nodesContainingLiveReplicas.isEmpty() &&
srcNodes.isEmpty() && decommissionedSrc != null) {
srcNodes.add(decommissionedSrc);
}
// 如果是基于复制,那么srcNodes肯定只有一个元素
return srcNodes.toArray(new DatanodeDescriptor[srcNodes.size()]);
}scheduleReconstruction()通过chooseSourceDatanodes()选定Source节点的同时,生成了对应的Block的source节点的一些统计信息作为引用参数返回,比如containingNodes, nodesContainingLiveReplicas,liveBlockIndices,liveBusyBlockIndices。然后,计算还需要多少个replica需要重构,将这些综合信息封装成BlockReconstructionWork,然后开始进行重构任务的调度。
总的来说,chooseSourceDatanodes()的基本策略是:
- 对于一个Block,会遍历这个Block的所有的Replica,直到找到一个合适的Source;
- 对于DECOMMISSIONING_IN_PROGRESS、ENTERING_MAINTENANCE、MAINTENANCE_LIVE状态的StoredReplicaState,对于它们的处理方式和LIVE状态没有区别, 即就认为它们是处于LIVE状态;
- 对于CORRUPT, EXCESS,MAINTENANCE_NOT_FOR_READ(即处于MAINTENANCE并且不在线了)的StoredReplicaState,这些副本将无法作为source使用;
- 对于依然存活的已经DECOMMISSIONED的节点,如果我们除了这个节点以外找不到其他节点作为source,那么这个节点将会被选作source节点。所以,我们在一个集群中突然decommission多个节点,显然,这个decommission操作会触发这些节点上的Replica的Reconstruction,如果某一个block全部分布在这些DECOMMISSIONING的节点上,NameNode会选择其中一个DECOMMISSIONING为这个Block进行replica的复制,并不会出现replica的丢失。
- 这个方法中有很多针对Erasure Coding的很多corner case的处理。
块的重构细节都被封装在对应的BlockReconstructionWork对象中,根据块布局方式的不同,分为ErasureCodingWork和ReplicationWork两种实现。显然,ReplicationWork不需要block index的这类信息的,但是ErasureCodingWork需要。在方法的,两个子类都重写chooseTargets()方法和addTaskToDataNode()方法,因为在选择目标节点上,不同的块布局有不同的PlacementPolicy,同时,在将任务添加到DataNode的时候,也有不同的逻辑。下文将会详细讲解。

java
class ErasureCodingWork extends BlockReconstructionWork {
private final byte[] liveBlockIndicies;
private final byte[] liveBusyBlockIndicies;
private final String blockPoolId;
public ErasureCodingWork(String blockPoolId,
BlockInfo block,
BlockCollection bc,
DatanodeDescriptor[] srcNodes,// srcNodes.size()和liveBlockIndicies.size()一样,并且liveBlockIndicies相同位置的值就是对应的internal block在group中的位置
List<DatanodeDescriptor> containingNodes, // 包含这个Block的所有的节点,包括DECOMMISSION和MAINTENANCE节点
List<DatanodeStorageInfo> liveReplicaStorages, // 包含这个Block的Live节点,因此不包含DECOMMISSION和MAINTENANCE
int additionalReplRequired, // 还缺少个replica
int priority,
byte[] liveBlockIndicies,// 只针对条带布局,所有live状态的replica的internal block index
byte[] liveBusyBlockIndicies) { // 只针对条带布局,所有处于LIVE或者DECOMMISSIONING并且这个节点上目前已经存在的复制任务超过一定数量
super(block, bc, srcNodes, containingNodes,
liveReplicaStorages, additionalReplRequired, priority);
this.blockPoolId = blockPoolId;
this.liveBlockIndicies = liveBlockIndicies;
this.liveBusyBlockIndicies = liveBusyBlockIndicies;
}
java
class ReplicationWork extends BlockReconstructionWork {
public ReplicationWork(BlockInfo block,
BlockCollection bc,
DatanodeDescriptor[] srcNodes, // 源节点,对于ReplicationWork, srcNodes的大小一定是1
List<DatanodeDescriptor> containingNodes,// 包含这个Block的所有的节点,包括DECOMMISSION和MAINTENANCE节点
List<DatanodeStorageInfo> liveReplicaStorages, // 包含这个Block的Live节点,因此不包含DECOMMISSION和MAINTENANCE
int additionalReplRequired, // 还需要多少个副本
int priority) {
super(block, bc, srcNodes, containingNodes,
liveReplicaStorages, additionalReplRequired, priority);
// 构造ReplicationWork的时候,还没有确定target节点,但是先进行计数
getSrcNodes()[0].incrementPendingReplicationWithoutTargets();scheduleReconstruction()方法的具体代码如下,其基本逻辑为:
-
先通过调用getExpectedLiveRedundancyNum()看看我当前期望这个Block有多少个副本存活。上文在讲
getExpectedLiveRedundancyNum()方法的时候已经详细讲解了期望的存活副本数量(Expected Live Redundancy)的具体含义。 -
基于当前的期望副本数,和这个副本当前的实际情况(有多少replica是正常的LIVE状态,有多少个replica是pending状态(即pendingReconstructions中的副本,pendingReconstructions的含义上文已经讲过)),我还额外需要多少个副本呢?这是通过下面的代码计算的:
javaif (numReplicas.liveReplicas() < requiredRedundancy) { // 当前的live replica还不够requiredRedundancy的数量 additionalReplRequired = requiredRedundancy - numReplicas.liveReplicas() - pendingNum; } -
即使在数量上我看起来不再需要副本(当前Block的实际存活的副本数已经不小于期望的存活副本数量(Expected Live Redundancy)),那有可能副本的位置并不满足PlacementPolicy的需求,这也是需要进行重构的,代码如下:
javaelse { // 尽管副本总数量够了,但是有可能按照Placement policy,副本的位置不符合要求 // Violates placement policy. Needed on a new rack or domain etc. BlockPlacementStatus placementStatus = getBlockPlacementStatus(block); additionalReplRequired = placementStatus.getAdditionalReplicasRequired(); } -
对于条带布局,在确定targets的数量的时候,还去掉了正处在DECOMMISSIONING和处在MAINTENANCE_FOR_READ的Replica,因为这些replica目前算作LIVE的replica(查看chooseSourceDatanodes()在确定liveBusyBlockIndicies的基本逻辑),而这些Replica即将不可读(因为即将进入DECOMMISSIONED和MAINTENANCE_NOT_FOR_READ状态),因此必须尽快利用这些节点上的Replica进行其它Replica的重构。
-
在按照上述逻辑确定了targets的数量以后,构造ErasureCodingWork或者ReplicationWork对象,开始选择目标节点。
java// 虽然创建了ErasureCodingWork但是有可能是进行replica work,具体调度出去的时候会进行具体分析 return new ErasureCodingWork(getBlockPoolId(), block, bc, newSrcNodes, containingNodes, liveReplicaNodes, additionalReplRequired, priority, newIndices, busyIndices); } else { return new ReplicationWork(block, bc, srcNodes, containingNodes, liveReplicaNodes, additionalReplRequired, priority); }
3.3 选择target节点
目标节点是重构的时候需要写入重构数据的节点。显然,这刚好是PlacementPolicy做的事情。代码如下:
java
// 为每一个reconstruction work挑选target节点
for (BlockReconstructionWork rw : reconWork) {
// Exclude all of the containing nodes from being targets.
// This list includes decommissioning or corrupt nodes.
final Set<Node> excludedNodes = new HashSet<>(rw.getContainingNodes());
// Exclude all nodes which already exists as targets for the block
List<DatanodeStorageInfo> targets = // 排除掉这个Block当前所在的targets
pendingReconstruction.getTargets(rw.getBlock());
if (targets != null) {
for (DatanodeStorageInfo dn : targets) {
excludedNodes.add(dn.getDatanodeDescriptor());
}
}
//根据布局方式(连续布局还是条带布局),选择合适的块放置策略
final BlockPlacementPolicy placementPolicy =
placementPolicies.getPolicy(rw.getBlock().getBlockType());
rw.chooseTargets(placementPolicy, storagePolicySuite, excludedNodes);// 最终会调BlockPlacementPolicy.chooseTarget()
}从上面的代码可以看到,选择目标节点是通过调用BlockReconstructionWork.chooseTargets()方法实现的,这个方法在父类BlockReconstructionWork上是抽象方法,需要子类去实现。两个子类对这个方法的实现方式大致一致,都是选择PlacementPolicy.chooseTargets()去调度,这里不贴二者实现的代码。
在上文讲条带布局的写过程时我们说过,连续布局的默认块放置策略BlockPlacementPolicyDefault会将第一个replica放在一个rack的某台机器上,另外两个replica会放在另外一个rack的两台不同机器上。而条带布局的默认块放置策略是BlockPlacementPolicyRackFaultTolerant,倾向于讲所有的internal block放到不同的基架上去。
我们看一下BlockPlacementPolicy接口,就知道它需要哪些信息:
java
public abstract DatanodeStorageInfo[] chooseTarget(String srcPath, // 这个块对应的文件的path
int numOfReplicas, // 额外需要的节点数量
Node writer, // 哪个节点负责写数据,这种情况下,如果这个节点的确是一个DataNode,并且这个DataNode不在excludedNodes里面,那么第一个replica会写到这个节点上去
List<DatanodeStorageInfo> chosen, // 已经被选择作为targets的节点
boolean returnChosenNodes, // 是否返回被选择的节点
Set<Node> excludedNodes, // 需要排除的节点
long blocksize, // 一个group中的data block的大小的总和
BlockStoragePolicy storagePolicy, // 这个节点应该放在哪种类型(StorageType比如SSD,DISK等)的介质上
EnumSet<AddBlockFlag> flags //分配block的时候的一些hint(暗示)的flag信息以修改这个PlacementPolicy的默认行为,比如默认会将第一个replica放到writer所在的DataNode上,但是如果指定了NO_LOCAL_WRITER,就不会把第一个replica放到跟writer在一个host上
);在调用BlockPlacementPolicy.chooseTarget()进行目标节点选择的时候,基本思路是,我告诉你 1) 已经选择作为target的节点(chosen) 2) 需要排除的节点,即不能作为目标的节点,那么,请根据你的BlockPlacementPolicy的实现,为我选择numOfReplicas个节点作为target节点。
- chosen: 在块重构的场景下,已经选择作为target的节点(chosen)是这个Block的处于LIVE状态的replica。为什么需要这个参数,可以参考具体BlockPlacementPolicy的代码,本文不做论述。
- excludedNodes: 而根据上面的代码,我们知道excludedNodes的选择规则,即只要是这个Block的replica所在的节点(存放在containingNodes中,无论节点的状态),以及这个Block还处于pending状态的节点(上文讲过pendingReconstruction,这些节点是写Block完成但是还没有进行Block report的节点,我们assume它过一段时间就会汇报,因此重构块的其它节点的时候,不应该选择它)。
3.4 将任务调度出去
到这一阶段,我们已经构建了BlockReconstructionWork的具体实现,ErasureCodingWork或者ReplicationWork,包含了srcNodes(这个Block的每一个replica所在的并且满足一定条件比如节点状态,当前上面已经有的replication的task的数量),containingNodes(这个Block的每一个replica所在的节点,无论什么状态,无论上面已经有多少replication的task),targets(重构的目标节点),liveBlockIndicies(处于LIVE状态或者其他状态但是满足要求的replica的internal block index,只针对条带布局),liveReplicaStorages(处于LIVE状态的DataNodeStorage),现在可以将任务调度出去了。调度的主要逻辑在方法validateReconstructionWork()中(方法名字似乎跟它做的事情并不一致。。。。)
java
// 将task调度给对应的DN,进行重构
namesystem.writeLock();
try { // 遍历每一个reconstruction work, 然后调度出去
for (BlockReconstructionWork rw : reconWork) {
.......
synchronized (neededReconstruction) {
if (validateReconstructionWork(rw)) { //validateReconstructionWork会将任务调度出去,即attach到对应的DataNode,等待收到心跳,就把attach到DataNode的任务作为response发送给DataNode
....
}
.....
return scheduledWork;validateReconstructionWork()做了以下事情
-
再次判断是否有足够副本,是否真的需要重构
首先再次确认BlockReconstructionWork对应的Block的确没有足够的redundancy,即是否有足够的有效副本数 。如果有效副本数已经足够,则取消任务。关于有效副本数 (hasEnoughEffectiveReplicas()方法)的定义,上文已经讲解。javaNumberReplicas numReplicas = countNodes(block);// 再次统计这个block当前的状态统计信息 final short requiredRedundancy = getExpectedLiveRedundancyNum(block, numReplicas); final int pendingNum = pendingReconstruction.getNumReplicas(block); if (hasEnoughEffectiveReplicas(block, numReplicas, pendingNum)) { // 算上pending的,已经有足够的replica,不需要进行re-construct了 neededReconstruction.remove(block, priority); ....... return false; } -
是副本不够,还是副本够但是机架不够
这里的考虑是,一个重构任务,包括ErasureCodingWork,有可能并不是因为某一个replica的缺失,而是,尽管replica并不缺失,但是位置不对,比如,纠删码要求每个replica都尽量在不同的机架上,但是现在却发现有两个replica在同一机架上,并且有多余的机架可以满足要求,此时依然需要进行重构,只不过,即使是ErasureCodingWork,也是通过复制的方式去实现(将一个replica从一个rack拷贝到另一个rack以)。javaif ((numReplicas.liveReplicas() >= requiredRedundancy) && (!placementStatus.isPlacementPolicySatisfied())) { // 如果replica数量足够,仅仅是分布方式不满足放置策略 BlockPlacementStatus newPlacementStatus = getBlockPlacementStatus(block, targets); // 当添加了targets以后,获取对应的status // 节点添加进来以后,依然没有满足当前的放置策略,并且,即使把target加进来,还需要额外的节点数量大于不加入target的时候还需要的节点数量,那么,加入这些target没有任何价值 // 也就是说,如果这些targets加进来以后,放置策略被满足,或者,虽然依然不满足,但是至少让所需要的节点数量减少了,那么,把这些target加进来就有意义 if (!newPlacementStatus.isPlacementPolicySatisfied() && (newPlacementStatus.getAdditionalReplicasRequired() >= placementStatus.getAdditionalReplicasRequired())) { // 分布不满足分布策略, // If the new targets do not meet the placement policy, or at least // reduce the number of replicas needed, then no use continuing. return false; } // mark that the reconstruction work is to replicate internal block to a // new rack. rw.setNotEnoughRack(); // 仅仅需要把replica放到一个新的rack上 }每一个BlockPlacementPolicy都必须实现
verifyBlockPlacement()方法,它返回一个BlockPlacementStatus对象,封装了当前的副本放置是否满足要求、还需要几个副本等等信息,供调用者进行决策。javapublic abstract BlockPlacementStatus verifyBlockPlacement(DatanodeInfo[] locs, int numOfReplicas);javapublic interface BlockPlacementStatus { public boolean isPlacementPolicySatisfied(); // 当前的放置状态是否满足了放置策略 public String getErrorDescription();// 当前的放置状态没有满足放置策略的一些错误或者描述信息 int getAdditionalReplicasRequired(); // 还需要多少个额外副本才能保证放置策略得到满足 }
可以看到,如果副本数量足够但是verifyBlockPlacement()返回的BlockPlacementStatus显示Block当前的Replica放置不满足要求,那么就会调用BlockReconstructionWork.setNotEnoughRack(),将boolean notEnoughRack置为True,这个变量将会影响到向DataNode添加任务的逻辑,因为如果notEnoughRack=True,那么即使是ErasureCodingWork,这个任务也不再是进行encode/decode类型的计算,而是通过将某个internal block进行拷贝来买满足PlacementPolicy的要求。下文会详细介绍向DataNode添加任务的流程。
- 将任务Attach到DataNode
在BlockReconstructionWorkd的类图中可以看到,addTaskToDataNode()方法是一个抽象方法,因此ErasureCodingWork和ReplicationWork对这个方法都有自己的实现。
- ErasureCodingWork的任务分配
请注意,ErasureCodingWork实际分配出去的任务不一定就是纠删码的encode/decode任务,也可能也是复制任务。其基本逻辑是:- 是否是不缺副本但是缺少机架。在纠删码场景下,缺少rack的意思是,有rack上的存放了这个Block的多个副本。在这种情况下,通过chooseSource4SimpleReplication(),选择一个Replica的DataNode,将任务调度给这个DataNode,任务是:将你上面的这个replica 挪到target上面去。选择这个DataNode的原则也很直观:看看这个Block在哪个Rack上存放了多个replica,那么就选择这个Rack上的某个DataNode,让这个DataNode自己负责把自己的Replica挪走。
- 是否整个副本数量足够(无需通过encode/decode进行internal block的重算),但是当前有的Replica的状态是DECOMMISSIONING或者MAINTENANCE_FOR_READ的状态。这种情况下,会给每一个处在DECOMMISSIONING或者MAINTENANCE_FOR_READ状态的DataNode分发任务,任务的内容是:将你上面这个Block的replica立刻拷贝到远程的targets机器上去。
- 既不是缺少机架,同时也不是有节点即将进行decommioning或者maintenance,而是的确缺少internal block。这种情况下,的确需要调度纠删码的encode/decode任务。调度的基本逻辑是,将任务调度给选定的targets节点中的第一个节点,显然,这个节点将会负责从source节点上读取internal block,通过encode或者decode,让生成的一个或者多个internal block,发送到targets上去。由于它自己本身就是一个target,显然有一个internal block是给分配给自己的。
- ReplicationWork的任务分配
ReplicationWork的任务就很简单了,都是基于拷贝的多副本情况下副本数量不够,因此将任务调度给source节点的第一个节点,这个节点负责将自己存放的这个replica拷贝到target节点上去。
将任务attach到DataNode是通过DatanodeDescriptor.addBlockToBeReplicated()和DatanodeDescriptor.addBlockToBeErasureCoded()方法进行的。我们从下面的DatanodeDescriptor的类图可以看到,DatanodeDescriptor上保存了NameNode即将发送给该DataNode的各种类型的副本操作信息,这些信息将会在下一次DataNode到来的时候作为repsonse发送给DataNode.

从下面的代码可以看到,addBlockToBeReplicated()和addBlockToBeErasureCoded()就是将对应的任务添加到该DatanodeDescriptor的对应的任务队列replicaBlocks和erasurecodeBlocks中去。
java
---------------------------------------------DatanodeDescriptor----------------------------------------------------
public void addBlockToBeReplicated(Block block, // 这个block是internal block
DatanodeStorageInfo[] targets) {
assert(block != null && targets != null && targets.length > 0);
replicateBlocks.offer(new BlockTargetPair(block, targets));
}
/**
* Store block erasure coding work.
*/
void addBlockToBeErasureCoded(ExtendedBlock block,
DatanodeDescriptor[] sources, DatanodeStorageInfo[] targets,
byte[] liveBlockIndices, ErasureCodingPolicy ecPolicy) {
assert (block != null && sources != null && sources.length > 0);
// 构造这个BlockECReconstructionInfo的block是一个block group,即我还不知道需要对哪个internal block进行重算
BlockECReconstructionInfo task = new BlockECReconstructionInfo(block,
sources, targets, liveBlockIndices, ecPolicy);
erasurecodeBlocks.offer(task);
}- 任务的派发
NameNode从来不会主动向DataNode发送信息(你清高行了吧?),只会在收到DataNode发送过来的心跳信息的时候,将任务通过心跳的响应返回给DataNode。
当NameNode 收到了DataNode发过来的信息,会在handleHeartbeat()方法中查看当前需要回复给这个DataNode的命令,其中就包括需要该DataNode复制replica到别的节点的命令,或者进行纠删码的encode/decode以恢复纠删码内部块的命令。
所有的命令封装在DatanodeCommand中的对应具体实现类中,比如,对Block进行基于复制的重构new BlockCommand(DatanodeProtocol.DNA_TRANSFER, blockPoolId, pendingList), 对Block进行基于纠删码编解码的重构new BlockECReconstructionCommand( DNA_ERASURE_CODING_RECONSTRUCTION, pendingECList), 删除一个Block的Replica的命令new BlockCommand(DatanodeProtocol.DNA_INVALIDATE, blockPoolId, blks)等等。几个重要的DatanodeProtocol:
java
final static int DNA_TRANSFER = 1; // 将副本从一个节点传输到另一个节点
final static int DNA_INVALIDATE = 2; // 删除一个replica
final static int DNA_SHUTDOWN = 3; // 关闭节点
final static int DNA_REGISTER = 4; // 重新注册
final static int DNA_RECOVERBLOCK = 6; // 恢复一个eblock
final static int DNA_ACCESSKEYUPDATE = 7; // update access key
final static int DNA_BALANCERBANDWIDTHUPDATE = 8; // 更新balancer的带宽
final static int DNA_CACHE = 9; // 缓存一个block
final static int DNA_UNCACHE = 10; // 将一个block从缓存中拿掉
final static int DNA_ERASURE_CODING_RECONSTRUCTION = 11; // 基于纠删码的重构命令3.5 DataNode对重构任务的处理
在DataNode端,DataNode会为每一个NameNode(每一个NameService的每一个NameNode,Active或者Standby)构建一个BPOfferService,用来处理这个NameNode发过来的命令。最终,会在BPOfferService.processCommandFromActive()处理来自Active NameNode的命令
java
----------------------------------------------BPOfferService------------------------------------------------
boolean processCommandFromActor(DatanodeCommand cmd,
BPServiceActor actor) throws IOException {
.......
try {
if (actor == bpServiceToActive) {
return processCommandFromActive(cmd, actor);
} else {
return processCommandFromStandby(cmd, actor);
}
private boolean processCommandFromActive(DatanodeCommand cmd,
BPServiceActor actor) throws IOException {
.......
switch(cmd.getAction()) {
case DatanodeProtocol.DNA_TRANSFER: // 处理replica复制任务非常简单,就是根据副本信息,将副本复制到指定的远程节点
// Send a copy of a block to another datanode
dn.transferBlocks(bcmd.getBlockPoolId(), bcmd.getBlocks(),
bcmd.getTargets(), bcmd.getTargetStorageTypes(),
bcmd.getTargetStorageIDs());
break;
case DatanodeProtocol.DNA_INVALIDATE:
......
case DatanodeProtocol.DNA_CACHE:
.....
case DatanodeProtocol.DNA_UNCACHE:
.......
case DatanodeProtocol.DNA_SHUTDOWN:
......
case DatanodeProtocol.DNA_FINALIZE:
......
case DatanodeProtocol.DNA_RECOVERBLOCK:
.......
case DatanodeProtocol.DNA_BALANCERBANDWIDTHUPDATE:
.......
// 对于continuous block的恢复,参考DatanodeProtocol.DNA_TRANSFER
case DatanodeProtocol.DNA_ERASURE_CODING_RECONSTRUCTION:
LOG.info("DatanodeCommand action: DNA_ERASURE_CODING_RECOVERY");
Collection<BlockECReconstructionInfo> ecTasks =
((BlockECReconstructionCommand) cmd).getECTasks();
dn.getErasureCodingWorker().processErasureCodingTasks(ecTasks);
.......
}
return true;
}与NameNode对应,DatanodeProtocol.DNA_TRANSFER用来进行副本的复制,而DatanodeProtocol.DNA_ERASURE_CODING_RECONSTRUCTION用来进行纠删码的块重构。基于副本复制的重构方式很简单,我们不做赘述。主要讲解纠删码的块重构。
DataNode会构造一个全局的叫做ErasureCodingWorker的对象负责进行纠删码的块重构任务(注意和NameNode端的ErasureCodingWork类区分开)。DataNode启动的时候会初始化ErasureCodingWorker,在ErasureCodingWorker构造时,会用一个线程池专门执行块的重构任务
java
public ErasureCodingWorker(Configuration conf, DataNode datanode) {
......
initializeStripedBlkReconstructionThreadPool(conf.getInt(
DFSConfigKeys.DFS_DN_EC_RECONSTRUCTION_THREADS_KEY,
DFSConfigKeys.DFS_DN_EC_RECONSTRUCTION_THREADS_DEFAULT));
}
private void initializeStripedBlkReconstructionThreadPool(int numThreads) {
LOG.debug("Using striped block reconstruction; pool threads={}",
numThreads);
stripedReconstructionPool = DFSUtilClient.getThreadPoolExecutor(numThreads,
numThreads, 60, new LinkedBlockingQueue<>(),
"StripedBlockReconstruction-", false);
stripedReconstructionPool.allowCoreThreadTimeOut(true);
}其实就是创建了一个corePoolSize=8, maxPoolSize=8, keepAliveTime=60s, 任务队列是一个阻塞 的无界 队列LinkedBlockingQueue的线程池。我们都知道,这个在线程池的划分上叫做叫做固定线程数量的线程池(可以参考文章《Java的5中线程池》)。线程池中的每一个线程负责一个Block(注意不是replica)的重构。
java
------------------------------------------------ErasureCodingWorker---------------------------------------------------
public void processErasureCodingTasks(
Collection<BlockECReconstructionInfo> ecTasks) {
// 对于每一个重构的task
for (BlockECReconstructionInfo reconInfo : ecTasks) {
try {
StripedReconstructionInfo stripedReconInfo =
new StripedReconstructionInfo(
reconInfo.getExtendedBlock(), reconInfo.getErasureCodingPolicy(),
reconInfo.getLiveBlockIndices(), reconInfo.getSourceDnInfos(),
reconInfo.getTargetDnInfos(), reconInfo.getTargetStorageTypes(),
reconInfo.getTargetStorageIDs());
final StripedBlockReconstructor task =
new StripedBlockReconstructor(this, stripedReconInfo);
if (task.hasValidTargets()) {
stripedReconstructionPool.submit(task);可以看到,ErasureCodingWorker将块的重构信息封装到StripedReconstructionInfo中,然后封装为一个StripedBlockReconstructor,提交给ErasureCodingWorker在初始化的时候构造的固定线程数的线程池stripedReconstructionPool。由此可见,StripedBlockReconstructor肯定是一个Runnable,它的run()方法结构非常清晰,做的事情一目了然:
java
--------------------------------------------StripedBlockReconstructor----------------------------------------------
class StripedBlockReconstructor extends StripedReconstructor
implements Runnable {
private StripedWriter stripedWriter;
......
@Override
public void run() {
try {
initDecoderIfNecessary(); // 根据ECPolicy创建对应的decoder
initDecodingValidatorIfNecessary(); // 根据ECPolicy创建对应的decoder的validator
getStripedReader().init();//初始化条带块的读取
stripedWriter.init(); //初始化条带块的写入
reconstruct(); // 重构
stripedWriter.endTargetBlocks(); // 结束目标块的写入,重构完成
.....从上面的代码可以看到,StripedBlockReconstructor会首先初始化Decoder和DecodingValidator,然后初始化了Reader(getStripedReader().init())和Writer(stripedWriter.init()),然后进行重构,最后进行一些关闭操作。
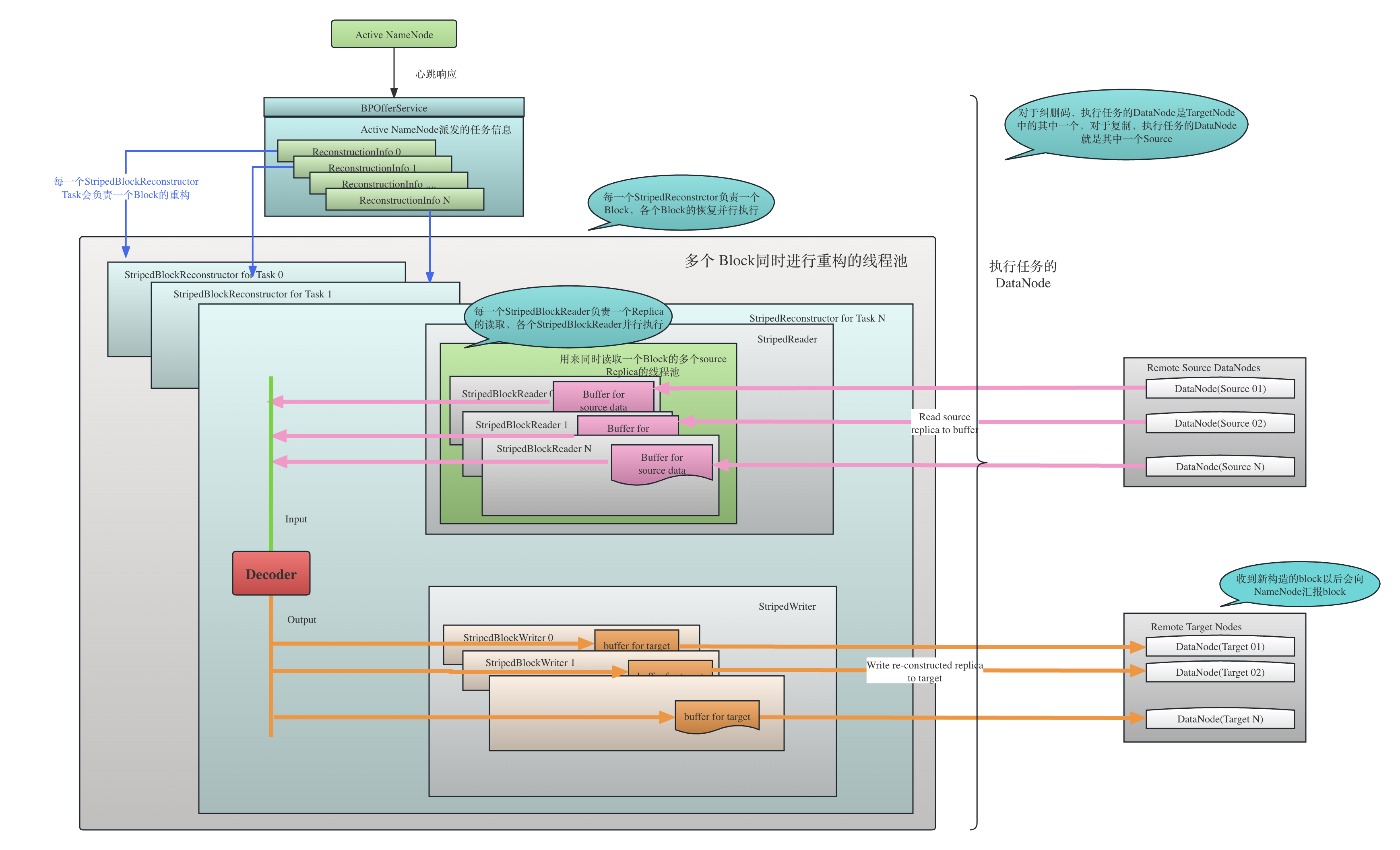
具体架构如下图所示:
关于Decoder和DecodingValidator:
-
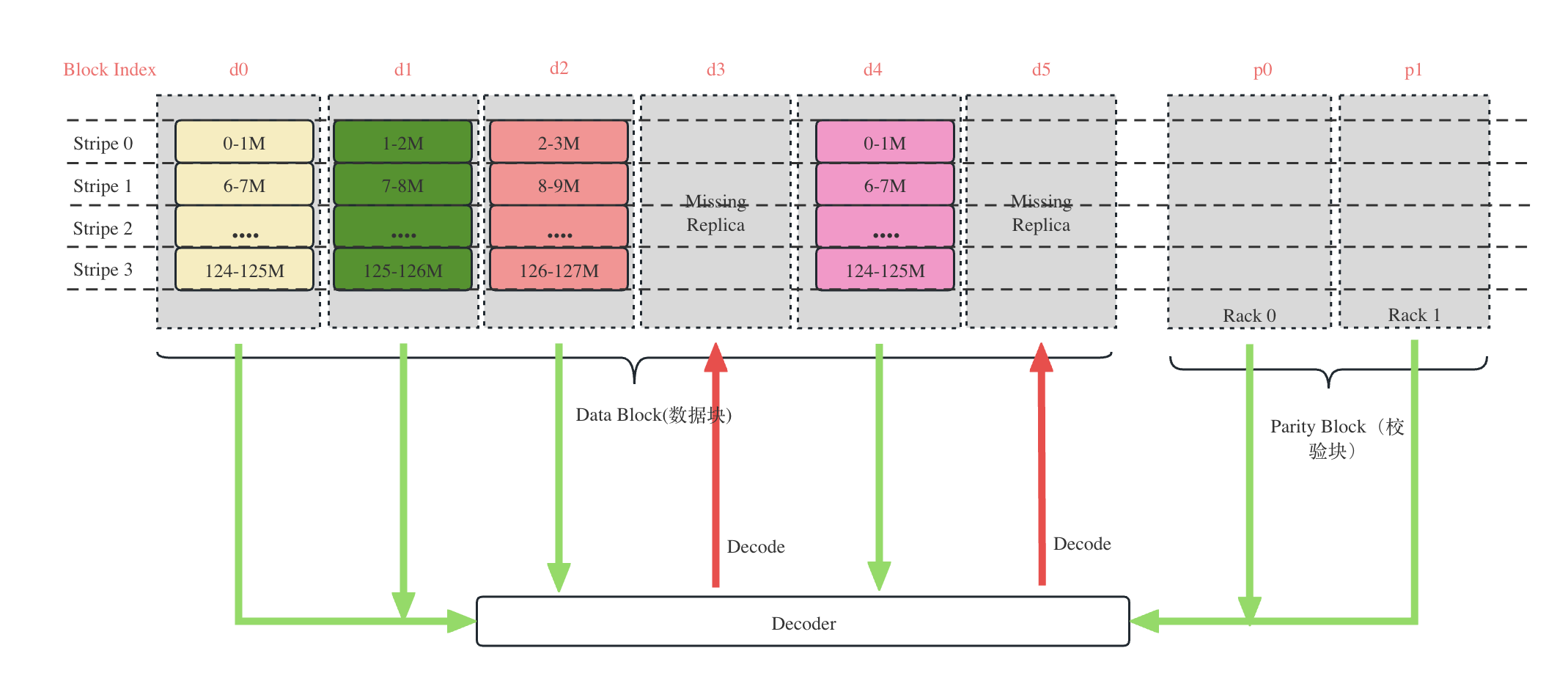
关于Decoder和DecodingValidator
Decoder就是通过已有的replica计算出缺失的block,比如RS(6,2),index=(3,6)的块丢失,因此需要通过Decode的方式重算丢失块。DecodingValidator的过程就是将已经Decode的结果重新作为Input进行Decode,看看生成的块与当前的块是否匹配。
比如,通过decode(d0,d1,d2,d4,p0,p1) 恢复出 (d0, d5), 然后校验过程就可以是decode(d1, d2, d3,d4,d5, p0) 计算出d0',然后对比d0'和d0,如果一致则校验成功。
-
关于Reader
3.5.1 StripedReader的构造
显然,纠删码的重构需要从多个Source读取internal block,才能进行重构。比如RS(6,2),应该至少需要从6台DataNode上读取6个internal block(待会儿会讲到文件最后的一个Group可能不需要读这么多的block),才能重构丢失的internal block,和每一个DataNode的通信都需要建立独立的连接,需要多个reader。StripedBlockReconstructor将这些reader的管理交付给StripedReader负责,它管理了StripedBlockReader的List, 每一个StripedBlockReader负责一个DataNode上Replica的读取。
StripeReader的构造方法如下:
java
StripedReader(StripedReconstructor reconstructor, DataNode datanode,
Configuration conf, StripedReconstructionInfo stripedReconInfo) {
......
dataBlkNum = stripedReconInfo.getEcPolicy().getNumDataUnits();
parityBlkNum = stripedReconInfo.getEcPolicy().getNumParityUnits();
int cellsNum = (int) ((stripedReconInfo.getBlockGroup().getNumBytes() - 1)
/ stripedReconInfo.getEcPolicy().getCellSize() + 1);
minRequiredSources = Math.min(cellsNum, dataBlkNum); // minRequiredSources可能等于data block的数量,有可能等于当前这个stripe的cell数量
if (minRequiredSources < dataBlkNum) { // cellNum小于dataBlkNum,说明这个block group的总的数据量甚至都没有一个stripe那么多,这往往是一个文件的最后一个Block Group
int zeroStripNum = dataBlkNum - minRequiredSources;
zeroStripeBuffers = new ByteBuffer[zeroStripNum];
zeroStripeIndices = new short[zeroStripNum];
}
......
readers = new ArrayList<>(sources.length);
readService = reconstructor.createReadService(); //用来进行并发读取的StripedBlockReader的线程池
}
```
```java
CompletionService<BlockReadStats> createReadService() {
return new ExecutorCompletionService<>(stripedReadPool);
}
// StripedReader的初始化
void init() throws IOException {
initReaders();
initBufferSize();
initZeroStrip();
}从刚上面的代码可以看到,在构造的时候主要做了以下3件事情:
- 确定最少需要从多少个Source读取数据
-
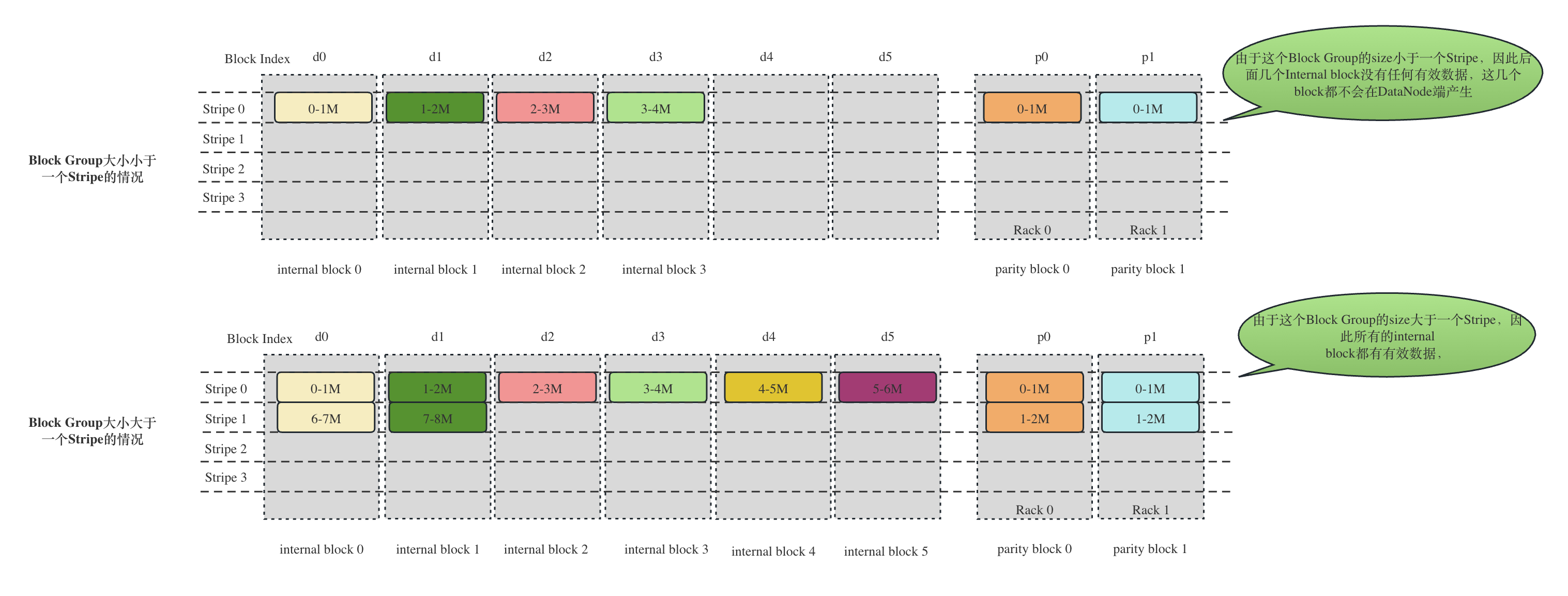
以RS(6,2),cell大小为1MB为例,为了重构内部物理块,难道不都是需要至少6个内部块吗?答案是不一定。特殊情况发生在文件的最后一个Block Group,假如这个Block Group的大小小于等于(6 - 1) * 1M = 6M,那么就至少有一个internla block是全0的,HDFS对于这种小文件,尽管NameNode会照常分配6+2=8个物理块,但是客户端也只会写有有效数据的块,根本不会写没有任何有效数据的块。这个结果我们在本文的实验验证部分已经验证了。下面的StripedReader的构造方法就是确定最少需要多少个source,即需要构造多少个实际读取数据的reader。剩下的空的 internalblock 也会构建对应的Buffer,但是数据全是0。
根据上面的计算方式,我们以
RS-6-2-1024k为例:如果这个BlockGroup的大小是3.5 * 1024k = 1536kB,由于一个cell大小为1024KB, 那么这个Block Group只会有 (3584 - 1)/1024 + 1 = 4个internal block,剩下两个internal Block不会生成。
如果这个BlockGroup的大小是8 * 1024 = 8192KB,由于一个cell大小为1024KB,那么(8192 - 1)/1024 + 1 = 8,与最多的6取最小值,因此是需要6个internal block。
两种情况的纠删码的条带布局如下图所示:
-
- 按照source的数量,构造Reader的数组
- 构造Reader的线程池readService
可以看到,这里是构造了一个线程池stripedReadPool,corePoolSize=0, maxPoolSize=Integet.MAX_VALUE, keepAliveTime=60s, 任务队列是一个阻塞 的无界 队列SynchronousQueue的线程池。我们都知道,这个在线程池的划分上叫做叫做缓存线程池(Cached Thread Pool,可以参考文章《Java的5中线程池》。SynchronousQueue一般用在无界的缓存线程池中,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
请把这个线程池与上文提到的ErasureCodingWorker中构造的线程池stripedReconstructionPool区分开,stripedReconstructionPool中的每一个task是一个StripedBlockReconstructor,每一个task负责一个Block的reconstruction,这里的线程池stripedReadPool的每一个task则负责一个Block下的Replica的读取。
java
// 构造线程池
private void initializeStripedReadThreadPool() {
// Essentially, this is a cachedThreadPool.
stripedReadPool = new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60, TimeUnit.SECONDS,
new SynchronousQueue<>(),
new Daemon.DaemonFactory() {
.....
},
new ThreadPoolExecutor.CallerRunsPolicy() {
.......
});
stripedReadPool.allowCoreThreadTimeOut(true);
}
// 将线程池封装为ExecutorCompletionService
CompletionService<BlockReadStats> createReadService() {
return new ExecutorCompletionService<>(stripedReadPool);
}3.5.2 StripedReader的初始化
刚刚说过,在StripedBlockReconstructor.run()中,会通过调用getStripedReader().init()来初始化Reader。
我们可以看到,StripedReader初始化主要是初始化每一个Replica的StripedBlockReader,以及初始化buffer和zeroStripe(上面讲到的空的internal block,这些block没有有效数据,decode运算的时候需要假设上面的数据是0)。
从下面的代码可以看到,一共初始化了minRequiredSources个reader,每一个reader会负责与一个DataNode通信拉去对应的replica,所有的reader放在一个readers数组中。
java
void init() throws IOException {
initReaders();
initBufferSize();
initZeroStrip();
}
private void initReaders() throws IOException {
// 初始化一个success list, 代表可以进行internal block读取的DN,由于每次读取的过程中可能发现有些DN不好用,
// 因此会更新这个list
successList = new int[minRequiredSources];
StripedBlockReader reader;
int nSuccess = 0; // 我们有sources.length个reader,但是实际上我们只需要minRequiredSources个reader
for (int i = 0; i < sources.length && nSuccess < minRequiredSources; i++) {
reader = createReader(i, 0); // offset都是0,因为每一个reader都是从自己负责的replica的0的位置开始读取
readers.add(reader);
if (reader.getBlockReader() != null) { // 连接已经建立好了
initOrVerifyChecksum(reader);
successList[nSuccess++] = i; //successList[nSuccess++]存放了readers数组的索引
}
}
}
/**
* 注意,idxInSources只是在liveIndices数组中的索引,而liveIndices[idxInSources]才是internal block在block group中的索引
*/
StripedBlockReader createReader(int idxInSources, long offsetInBlock) {
return new StripedBlockReader(this, datanode,
conf, liveIndices[idxInSources], // liveIndices[idxInSources] 存的是internal block在group中的index
reconstructor.getBlock(liveIndices[idxInSources]),
sources[idxInSources], offsetInBlock);
}initBufferSize()的代码如下,buffer的大小通过dfs.datanode.ec.reconstruction.stripedread.buffer.size配置,默认64KB。每次构造的时候,minRequiredSources中的每一个StripedBlockReader都会读取bufferSize的数据,进行decode操作,然后写入到target中。
java
private void initBufferSize() {
int bytesPerChecksum = checksum.getBytesPerChecksum(); // 默认一个chunk是512B,算上4B的checksum,是516B
// The bufferSize is flat to divide bytesPerChecksum
int readBufferSize = stripedReadBufferSize; // 默认64kb
// 假如用户配置的stripedReadBufferSize是9KB, bytesPerChecksum是4KB,那么真正的bufferSize只需要8KB就行,不需要9KB
bufferSize = readBufferSize < bytesPerChecksum ? bytesPerChecksum :
readBufferSize - readBufferSize % bytesPerChecksum;
}initZeroStrip()方法主要是为上文讲的空block构造buffer。空的internal block中虽然没有有效数据,却需要置0来进行统一decode运算。这里不做详细讲解。
3.5.3 StripedWriter的构造
同StripedReader在逻辑上相似,StripedWriter也是封装了一个或者多个StripedBlockWriter,每一个StripedBlockWriter负责一个target replica的写操作。
java
StripedWriter(StripedReconstructor reconstructor, DataNode datanode,
Configuration conf, StripedReconstructionInfo stripedReconInfo) {
........
/**
* 有多个writer,可以看到一个StripedWriter负责一个BlockGroup 的一个或者多个internal block的恢复
* 一个StripedBlockWriter负责一个 replica的生成操作
*/
writers = new StripedBlockWriter[targets.length];
targetIndices = new short[targets.length];//targetIndices数组中的每一个元素的值代表了这个target在Block Index中的索引
Preconditions.checkArgument(targetIndices.length <= parityBlkNum,
"Too much missed striped blocks.");
initTargetIndices();
long maxTargetLength = 0L;
for (short targetIndex : targetIndices) { // 遍历每一个internal block,获取最大的internal block的长度
maxTargetLength = Math.max(maxTargetLength,
reconstructor.getBlockLen(targetIndex));
}
reconstructor.setMaxTargetLength(maxTargetLength);
}
// 初始化targetIndices数组,targetIndices数组的每一个元素代表了需要恢复的block在Block Group中的index
private void initTargetIndices() {
BitSet bitset = reconstructor.getLiveBitSet(); // 从StripedReconstructor构造函数可以看到,liveBitSet中存放了liveIndices中的每一个value,即每一个存活的(也包含decommissioning和maintenance_for_read,参考chooseSourceDataNodes()方法)的internal block的index
int m = 0;
hasValidTargets = false;
for (int i = 0; i < dataBlkNum + parityBlkNum; i++) {
if (!bitset.get(i)) { // 缺数据
if (reconstructor.getBlockLen(i) > 0) { // 的确需要数据
if (m < targets.length) { // 最多构造m个target
targetIndices[m++] = (short)i;
hasValidTargets = true;
}
.......
}StripedWriter的构造方法主要做了以下几件事情:
- 根据targets的数量,初始化StripedBlockWriter\[\]数组
- 设置targetIndices数组。数组中的每一个元素保存了需要进行恢复的internal block在Block Group中的索引。
- 设置最大的目标长度
这里指的是最长的internal block的长度。对于一个小文件,或者一个大文件的最后一个BlockGroup,由于没有将Block Group写满,不一定每一个Internal Block的大小都是满载的128MB,很有可能这个Block Group的所有的Internal Block都很小,因此我们先计算这个Block Group的所有 internal block的最大size,只要写满这个size,就结束了,不用再写了。比如下图,一个文件8MB,最大的internal block也就2MB:
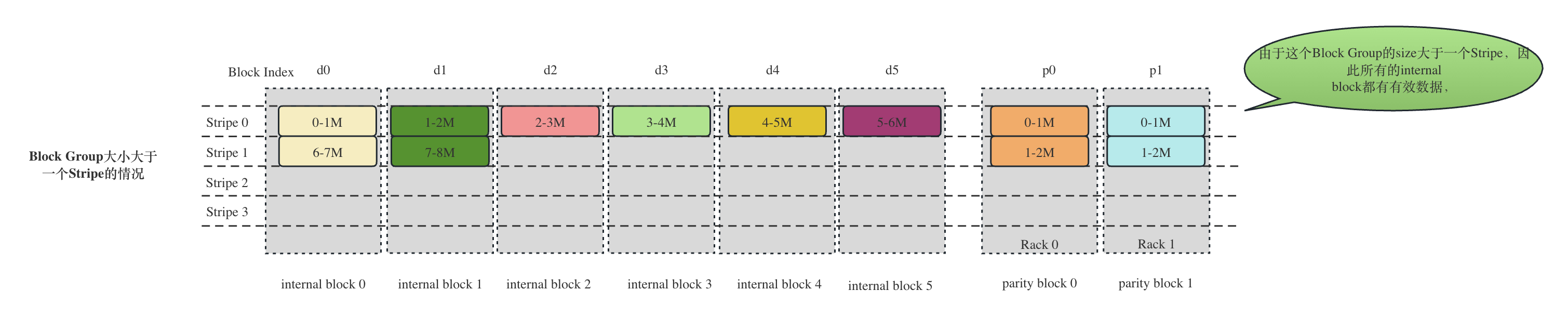
3.5.4 StripedWriter的初始化
刚刚说过,在StripedBlockReconstructor.run()中,会通过调用stripedWriter.init()来初始化writer。
StripedWriter的初始化主要是初始化了写数据过程中的data buffer和checksum buffer。一个data buffer用来存放一个packet,一个packet是有头部信息和多个chunk组成。这里不做赘述
java
void init() throws IOException {
DataChecksum checksum = reconstructor.getChecksum();
checksumSize = checksum.getChecksumSize();// 4B
bytesPerChecksum = checksum.getBytesPerChecksum(); // 512B
int chunkSize = bytesPerChecksum + checksumSize; // 516B
maxChunksPerPacket = Math.max( // WRITE_PACKET_SIZE是64KB,需要包含PKT_MAX_HEADER_LEN的header
(WRITE_PACKET_SIZE - PacketHeader.PKT_MAX_HEADER_LEN) / chunkSize, 1);
int maxPacketSize = chunkSize * maxChunksPerPacket
+ PacketHeader.PKT_MAX_HEADER_LEN; // 最大的packet的大小
packetBuf = new byte[maxPacketSize]; // 数据的buffer
int tmpLen = checksumSize *
(reconstructor.getBufferSize() / bytesPerChecksum);
checksumBuf = new byte[tmpLen]; // checksum的buffer的长度
}3.5.5 开始重构
上面讲过,方法reconstruct()是重构的具体过程。抛开细节,整个重构是一轮一轮进行,一轮重构是指读取一个Stripe中的source的数据(通过上面的线程池stripedReadPool并发进行,但是显然,在进行decode之前必须等所有task成功结束),进行decode,然后发送给一个或者多个targets (注意,多个targets的发送并没有使用线程池的方式并发进行,为什么?)
java
void reconstruct() throws IOException {
// 在internal block中的位置依然小于最大的target internal block的长度, 意味着还需要接着读数据
while (getPositionInBlock() < getMaxTargetLength()) { // 当前的position还小于最大的internal block的长度
DataNodeFaultInjector.get().stripedBlockReconstruction();
long remaining = getMaxTargetLength() - getPositionInBlock();
final int toReconstructLen = // 最多只能读取buffer size大小的数据(从StripedReader的构造函数可以看到,buffer size肯定是chunk的整数倍)
(int) Math.min(getStripedReader().getBufferSize(), remaining);
// step1: read from minimum source DNs required for reconstruction.
// The returned success list is the source DNs we do real read from
getStripedReader().readMinimumSources(toReconstructLen);// 从远程最多读取toReconstructLen byte的数据
// step2: decode to reconstruct targets
reconstructTargets(toReconstructLen); // 重算,构造数据
// step3: transfer data
// 把数据发送给target
if (stripedWriter.transferData2Targets() == 0) { // 将数据发送给 target
String error = "Transfer failed for all targets.";
throw new IOException(error);
}
updatePositionInBlock(toReconstructLen);
clearBuffers();
}读取
读取的逻辑很简单,根据需要读取的reconstructLength,并发提交minRequiredSources个任务进行读取操作,每一个任务是一个StripedBlockReader,负责和远程的DataNode通信以读取一个Internal Block,每一个submit都会返回一个Future句柄,供调用者查询结果。提交以后,开始轮询所有的Future。
正常情况下,minRequiredSources个reader都成功,则这一轮读取结束,所有读取的结果都存放在各自的StripedBlockReader的缓存中,供待会儿Decode使用。
如果失败或者超市,则会尝试更换另外一个DataNode读取。显然,只有在minRequiredSources小于liveSources的时候,还有可以更换的DataNode,否则,重构失败。
java
int[] doReadMinimumSources(int reconstructLength,
CorruptedBlocks corruptedBlocks)
throws IOException {
int nSuccess = 0;
int[] newSuccess = new int[minRequiredSources];
BitSet usedFlag = new BitSet(sources.length);
/*
* Read from minimum source DNs required, the success list contains
* source DNs which we think best.
*/
// 只需要真正的从minRequiredSources个reader中读取数据,剩下的则直接向buffer中填充0
for (int i = 0; i < minRequiredSources; i++) { // 最小的reader数量中的每一个reader都要去读数据
StripedBlockReader reader = readers.get(successList[i]);// successList[i]代表对应的需要从中拉取数据的block,readers.get将获取这个block对应的StripedBlockReader
int toRead = getReadLength(liveIndices[successList[i]],
reconstructLength);
.....
Callable<BlockReadStats> readCallable =
reader.readFromBlock(toRead, corruptedBlocks);
Future<BlockReadStats> f = readService.submit(readCallable);
futures.put(f, successList[i]);
.....
}
while (!futures.isEmpty()) { // 一直循环等待futures清空
try {
StripingChunkReadResult result =
StripedBlockUtil.getNextCompletedStripedRead(
readService, futures, stripedReadTimeoutInMills); // 每次取出一个成功的Future,即一个Replica的读取结果,这个结果有可能是成功,有可能是超时,有可能是失败
int resultIndex = -1;
if (result.state == StripingChunkReadResult.SUCCESSFUL) {
resultIndex = result.index;
} else if (result.state == StripingChunkReadResult.FAILED) { // 和下面的Timeout的处理策略一样,换一个DataNode读取(因为有可能minRequiredSources小于sources的数量,即还有剩余的DataNode可以尝试 )
StripedBlockReader failedReader = readers.get(result.index);
failedReader.closeBlockReader();
resultIndex = scheduleNewRead(usedFlag,
reconstructLength, corruptedBlocks);
} else if (result.state == StripingChunkReadResult.TIMEOUT) {
resultIndex = scheduleNewRead(usedFlag,
reconstructLength, corruptedBlocks); // 和上面的Failed的处理策略一样,换一个DataNode读取(因为有可能minRequiredSources小于sources的数量,即还有剩余的DataNode可以尝试 )
}
if (resultIndex >= 0) {
newSuccess[nSuccess++] = resultIndex; // 记录这个成功的读取,如果成功数量足够了,则这一轮结束
if (nSuccess >= minRequiredSources) { // 足够了,剩下的不用再读了
cancelReads(futures.keySet());
clearFuturesAndService();
break; // 成功数量足够了,这一轮读取结束
......
}Decode
在minRequiredSources个StripedBlockReader都完成了一轮读取,可以进行这一轮的Decode了。这是通过方法reconstructTargets()进行的:
java
private void reconstructTargets(int toReconstructLen) throws IOException {
// 收集所有的StripedBlockReader刚刚读取的数据
ByteBuffer[] inputs = getStripedReader().getInputBuffers(toReconstructLen);
int[] erasedIndices = stripedWriter.getRealTargetIndices();
ByteBuffer[] outputs = stripedWriter.getRealTargetBuffers(toReconstructLen);
markBuffers(inputs); // 记录当前的position
decode(inputs, erasedIndices, outputs); // 在这里进行解码,将解码以后的数据写入到outputs中,outputs其实就是StripedBlockWriter中的buf
resetBuffers(inputs); // 还原position
....
getValidator().validate(inputs, erasedIndices, outputs);
}
......
stripedWriter.updateRealTargetBuffers(toReconstructLen);
}
private void decode(ByteBuffer[] inputs, int[] erasedIndices,
ByteBuffer[] outputs) throws IOException {
long start = System.nanoTime();
getDecoder().decode(inputs, erasedIndices, outputs);
long end = System.nanoTime();
this.getDatanode().getMetrics().incrECDecodingTime(end - start);
}可以看到,reconstructTargets的任务就是从所有的StripedBlockReader的Buffer中拿到刚刚读取的数据,调用decode(),将数据写入到StripedBlockWriter的Buffer中去。写入完成,并且校验成功,剩下的任务就交给StripedBlockWriter将自己的buffer数据发送给远程的targets。
decode的具体算法我们不做讨论,从其参数可以看到,inputs\[\]就是所有的StripedBlockReader读取的数据,erasedIndices就是Decode以后生成的internal block的index,outputs就是decode生成的数据即StripedBlockWriter的buffer。可以看到,decode()方法可以在一轮生成多个丢失的targets。
传输到目标target
如上文所讲,此时计算好的internal block的数据已经存放到了对应的index的StripedBlockWriter的buffer 中去,StripedBlockWriter会通过调用调用transferData2Target()将数据发送到对应的target node上去。
上文已经说个,一个StripedBlockWriter和一个待恢复的internal block以及存放这个internal block的target DataNode是一一对应的关系,并且在StripedBlockWriter初始化的时候,已经构建好了和这个远程的DataNode的socket连接。
这个发送的过程根客户端写数据的过程是一模一样的。从原始数据、到以chunk为单位计算checksum、到组装成packet、到将数据通过socket发送给DataNode的过程都放在方法transferData2Target()中:
java
-------------------------------------------------StripedBlockWriter----------------------------------------------------
void transferData2Target(byte[] packetBuf) throws IOException {
// 现在数据已经存放在targetBuffer中(有可能是direct,有可能不是direct),如果targetBuffer是direct,那么计算
// checksum的时候存放checksum的ByteBuffer也得是direct,如果不是direct(在heap中),那么checksum也存放在heap中
if (targetBuffer.isDirect()) {
ByteBuffer directCheckSumBuf =
BUFFER_POOL.getBuffer(true, stripedWriter.getChecksumBuf().length);
stripedWriter.getChecksum().calculateChunkedSums(
targetBuffer, directCheckSumBuf); // 对targetBuffer的数据做校验,写入directCheckSumBuf
directCheckSumBuf.get(stripedWriter.getChecksumBuf()); // directCheckSumBuf写入到stripedWriter的buf中去
BUFFER_POOL.putBuffer(directCheckSumBuf); // 归还directCheckSumBuf到BUFFER_POOL中
} else { // 如果targetBuffer不是direct,那么直接基于数组进行计算
stripedWriter.getChecksum().calculateChunkedSums( // 只有在非direct(即存放在heap中)的情况下array()方法才会有返回值
targetBuffer.array(), 0, targetBuffer.remaining(),
stripedWriter.getChecksumBuf(), 0);
}
int ckOff = 0;
while (targetBuffer.remaining() > 0) { // 一个packet可能装不下这么多数据,因此会分多个packet进行发送
DFSPacket packet = new DFSPacket(packetBuf,
stripedWriter.getMaxChunksPerPacket(),
blockOffset4Target, seqNo4Target++,
stripedWriter.getChecksumSize(), false);
int maxBytesToPacket = stripedWriter.getMaxChunksPerPacket() // 单个packet中的chunk数量 * chunk的长度
* stripedWriter.getBytesPerChecksum();
int toWrite = targetBuffer.remaining() > maxBytesToPacket ?
maxBytesToPacket : targetBuffer.remaining(); // 实际发送的数据长度(不包含checksum,checksum此时是单独存放在checksumBuf中的)
int ckLen = ((toWrite - 1) / stripedWriter.getBytesPerChecksum() + 1)
* stripedWriter.getChecksumSize();// checksum的总长度,比如,我们需要10个checkum,每个checksum是4B,那么ckLen就是40Byte
packet.writeChecksum(stripedWriter.getChecksumBuf(), ckOff, ckLen); // 把checksum中的数据存入packet中
ckOff += ckLen;
// 把inBuffer中的数据写入到Packet中去(注意并不是发送,只是写入到Packet对应的buf中)
packet.writeData(targetBuffer, toWrite); // 把存放在targetBuffer中的长度为toWrite的数据存放到packet中
packet.writeTo(targetOutputStream); // 把packet中的数据发送到targetOutputStream绑定的远程 DN中去
......
}Target节点接收数据
Target接收写入的internal block的过程和普通客户端写入block的过程完全相同,接收完成以后会将块信息汇报给NameNode,然后NameNode的BlockManager会更新对应的块信息。这个过程本文不做详细讲解。有兴趣的读者可以自行查找资料学习。
4. 结束
本文主要讲解整个块的重构过程,包括:
- NameNode端待重构块的生成过程(包含了各种待重构的情况),
- NameeNode端基于生成的待重构块进行重构工作的调度,
- DataNode端对于重构任务的处理。由于基于副本复制的冗余策略基本上就是数据的拷贝,比较简单,因此,本文偏向于讲解基于纠删码的冗余策略的DataNode端的处理过程。
如果读者对Erasure Coding的整个过程感兴趣,可以参考我的另一篇文章HDFS的EC(Erasure Coding, 纠删码)和块管理。