六、数据可视化---Wordcloud词云(爬虫及数据可视化)
也是一个应用程序
http://amueller.github.io/word_cloud/
Wordcloud词云,在一些知乎,论坛等有这样一些东西,要么做封面,要么做讲解,进行分析,看起来有极客风的
分享一些可用于的词云的图标如下
https://blog.csdn.net/zhuxiao5/article/details/107096681
https://fontawesome.dashgame.com/
有遮罩的词云,可以通过文字与轮廓合成一个有图像的词云,也可以根据图片自身的私彩,生成词云的
还可以使用图标穿插
使用定制颜色
可以使用中文,形成分布
自己精简,通过图片的遮罩,形成自己词云的效果
需要安装jieba库,当使用中文的时候,中文分词工具
matplotlib库
Wordcloud 库可能装不上,安装失败,使用另外的方法进行安装,离线安装
使用校园网,发现可以安装Wordcloud,若安不上,可以使用离线模式
先升级pip 再离线安装
http://www.lfd.uci.edu/\~gohlke/pythonlibs/#wordcloud
在下方的连接上,有非常多的关于python的扩展包
http://www.lfd.uci.edu/\~gohlke/pythonlibs/
至此Wordcloud安装完成后
#-*- codeing = utf-8 -*-
#@Time : 2020/11/27 14:17
#@Author : 招财进宝
#@File : testCloud.py
#@Software: PyCharm
import jieba #分词(将一个句子分成很多个词语)
from matplotlib import pyplot as plt #绘图,数据可视化,点状图、柱状图等科学绘图,和echarts不同,不是直接用于网站,而是生成图片
from wordcloud import WordCloud #词云,形成有遮罩效果的
from PIL import Image #用来做图像处理的(官方默认)
import numpy as np #矩阵运算
import sqlite3 #数据库
#准备词云所需的文字(值准备了字)
#先有词,即从数据库中得到词
con = sqlite3.connect('movie.db')
cur = con.cursor()
#看要做那个词云,字太多,估计也显示不出来多少
sql = 'select instroduction from movie250' #注意拼写是否有误
data = cur.execute(sql)
text = ''
for item in data:
text = text +item[0] #此处是将其连接成一个字符串
#print(item[0])
#print(text) #此处是一个字符串了希望让人自由风华绝代一部美国近现代史怪蜀黍和小萝莉不得不说的故事失去的才是永恒的 最美的谎言最好的宫崎骏,最好的久石让 拯救一个人,就是拯救整个世界诺兰给了我们一场无法盗取的梦永远都不能忘记你所爱的人每个人都要走一条自己坚定了的路,就算是粉身碎骨 爱是一种力量,让我们超越时空感知它的存在如果再也不能见到你,祝你早安,午安,晚安英俊版憨豆,高情商版谢耳朵小瓦力,大人生天籁
#关闭
cur.close()
con.close()
#词云是按照词来进行统计的,这个使用jieba自动进行词频统计
cut = jieba.cut(text) #将一个字符串进行分割
#print(cut) #返回cut是一个对象<generator object Tokenizer.cut at 0x000002644AAECF48>
#' '.join(cut) 以指定字符串空格' '作为分隔符,将 cut 中所有的元素(的字符串表示)合并为一个新的字符串
string = ' '.join(cut) #此处将其对象cut变成字符串,可在下方显示
print(string) #此时可以打印如下希望 让 人 自由 风华绝代 一部 美国 近现代史 怪 蜀黍 和 小萝莉 不得不 说 的 故事 失去 的 才 是 永恒 的 最美 的 谎言 最好 的 宫崎骏 , 最好 的 久 石 让 拯救 一个 人 , 就是 拯救 整个 世界 诺兰 给 了 我们 一场 无法 盗取 的 梦 永远 都 不能 ...
#可以自己找图建议轮廓清晰,后面要是白色背景

img = Image.open(r'.\static\assets\img\tree.jpg') #打开遮罩图片
img_arry = np.array(img) #将图片转换为数组,有了数组即可做词云的封装了
wc = WordCloud(
background_color='white', #背景必须是白色
mask = img_arry, #传入遮罩的图片,必须是数组
font_path = "STXINGKA.TTF" #设置字体,(字体如何找,可以在C:/windows/Fonts中找到名字)
)
#
wc.generate_from_text(string) #从哪个文本生成wc,这个文本必须是切好的词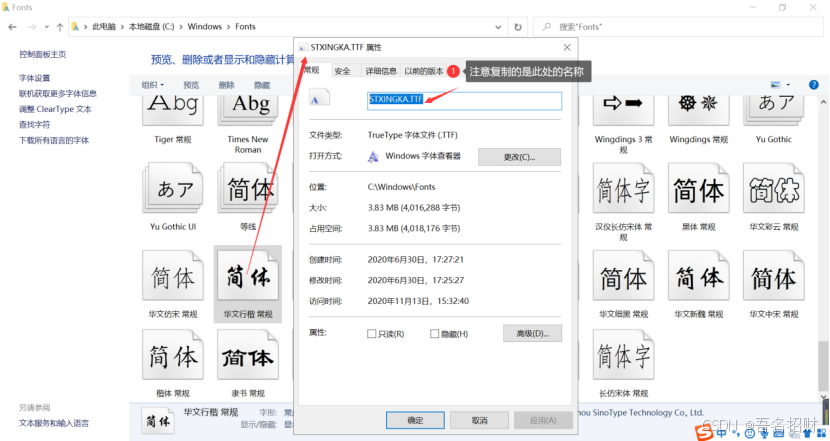
注意要使用中文的字体,否则下方显示图片上,会显示不出中文
#绘制图片
fig = plt.figure(1) #1表示第一个位置绘制
plt.imshow(wc) #按照wc词云的规格显示
plt.axis('off') #是否显示坐标轴,不显示(单一图片)
plt.show() #显示生成的词云图片显示结果如下

#plt.show() #显示生成的词云图片(在保存的时候,此处要注释)
plt.savefig(r'.\static\assets\img\treeWord.jpg',dpi=500) #输出词云图片到文件,默认清晰度是400,这里设置500可能有点高保存的图片如下:

所有的源代码如下
#-*- codeing = utf-8 -*-
#@Time : 2020/11/27 14:17
#@Author : 招财进宝
#@File : testCloud.py
#@Software: PyCharm
import jieba #分词(将一个句子分成很多个词语)
from matplotlib import pyplot as plt #绘图,数据可视化,点状图、柱状图等科学绘图,和echarts不同,不是直接用于网站,而是生成图片
from wordcloud import WordCloud #词云,形成有遮罩效果的
from PIL import Image #用来做图像处理的(官方默认)
import numpy as np #矩阵运算
import sqlite3 #数据库
#准备词云所需的文字(值准备了字)
#先有词,即从数据库中得到词
con = sqlite3.connect('movie.db')
cur = con.cursor()
#看要做那个词云,字太多,估计也显示不出来多少
sql = 'select instroduction from movie250' #注意拼写是否有误
data = cur.execute(sql)
text = ''
for item in data:
text = text +item[0] #此处是将其连接成一个字符串
#print(item[0])
#print(text) #此处是一个字符串了
#关闭
cur.close()
con.close()
#分词
#词云是按照词来进行统计的,这个使用jieba自动进行词频统计
cut = jieba.cut(text) #将一个字符串进行分割
#print(cut) #返回cut是一个对象<generator object Tokenizer.cut at 0x000002644AAECF48>
string = ' '.join(cut) #此处将其对象cut变成字符串,可在下方显示,#' '.join(cut) 以指定字符串空格' '作为分隔符,将 cut 中所有的元素(的字符串表示)合并为一个新的字符串
#print(string) #此时可以打印如下
print(len(string)) #5589个词,要对这些词进行统计
#可以自己找图建议轮廓清晰
img = Image.open(r'.\static\assets\img\tree.jpg') #打开遮罩图片
img_arry = np.array(img) #将图片转换为数组,有了数组即可做词云的封装了
wc = WordCloud(
background_color='white', #背景必须是白色
mask = img_arry, #传入遮罩的图片,必须是数组
font_path = "STXINGKA.TTF" #设置字体,(字体如何找,可以在C:/windows/Fonts中找到名字)
)
#
wc.generate_from_text(string) #从哪个文本生成wc,这个文本必须是切好的词
#绘制图片
fig = plt.figure(1) #1表示第一个位置绘制
plt.imshow(wc) #按照wc词云的规格显示
plt.axis('off') #是否显示坐标轴,不显示(单一图片)
#plt.show() #显示生成的词云图片
plt.savefig(r'.\static\assets\img\treeWord.jpg',dpi=400) #输出词云图片到文件,默认清晰度是400,这里设置500可能有点高有关WordCloud的配置如下,具体可以看相关课件
WordCloud个参数的含义:
font_path : string #字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path
= '黑体.ttf'
width : int (default=400) #输出的画布宽度,默认为400像素
height : int (default=200) #输出的画布高度,默认为200像素
prefer_horizontal : flfloat (default=0.90) #词语水平方向排版出现的频率,默认 0.9 (所以词语垂
直方向排版出现频率为 0.1 )
mask : nd-array or None (default=None) #如果参数为空,则使用二维遮罩绘制词云。如果
mask 非空,设置的宽高值将被忽略,遮罩形状被 mask 取代。除全白(#FFFFFF)的部分将不会
绘制,其余部分会用于绘制词云。如:bg_pic = imread('读取一张图片.png'),背景图片的画布一
定要设置为白色(#FFFFFF),然后显示的形状为不是白色的其他颜色。可以用ps工具将自己要
显示的形状复制到一个纯白色的画布上再保存,就ok了。
scale : flfloat (default=1) #按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍
min_font_size : int (default=4) #显示的最小的字体大小
font_step : int (default=1) #字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大
的误差
max_words : number (default=200) #要显示的词的最大个数
stopwords : set of strings or None #设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default="black") #背景颜色,如background_color='white',背
景颜色为白色
max_font_size : int or None (default=None) #显示的最大的字体大小
mode : string (default="RGB") #当参数为"RGBA"并且background_color不为空时,背景为透明
relative_scaling : flfloat (default=.5) #词频和字体大小的关联性
color_func : callable, default=None #生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) #使用正则表达式分隔输入的文本
collocations : bool, default=True #是否包括两个词的搭配
colormap : string or matplotlib colormap, default="viridis" #给每个单词随机分配颜色,若指定
color_func,则忽略该方法
random_state : int or None #为每个单词返回一个PIL颜色
fig = plt.figure(1) #新建一个名叫 Figure1的画图窗口
plt.imshow(wc) #显示图片,同时也显示其格式
plt.axis('off') # 是否显示x轴、y轴下标
#plt.show() #显示生成合成图片
plt.savefig(path+'\\new.png',dpi=500) #保存合成图片,dpi是设定分辨率,默认为400
fifit_words(frequencies) #根据词频生成词云
generate(text) #根据文本生成词云
generate_from_frequencies(frequencies[, ...]) #根据词频生成词云
generate_from_text(text) #根据文本生成词云
process_text(text) #将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库
先行实现,使用上面的 fifit_words(frequencies) )
recolor([random_state, color_func, colormap]) #对现有输出重新着色。重新上色会比重新生成
整个词云快很多
to_array() #转化为 numpy array
to_fifile(fifilename) #输出到文件