《Kafka 高性能架构设计 7 大秘诀》专栏第 6 章。
压缩,是一种用时间换空间的 trade-off 思想,用 CPU 的时间去换磁盘或者网络 I/O 传输量,用较小的 CPU 开销来换取更具性价比的磁盘占用和更少的网络 I/O 传输。
Kafka 是一个高吞吐量、可扩展的分布式消息系统,深入掌握 Kafka 的数据压缩和批量数据处理机制,对于优化系统性能和资源使用至关重要。
Kafka 数据压缩机制
数据压缩在 Kafka 中有助于减少磁盘空间的使用和网络带宽的消耗,从而提升整体性能。
通过减少消息的大小,压缩可以显著降低生产者和消费者之间的数据传输时间。
Chaya:Kafka 支持的压缩算法有哪些?
在 Kafka 2.1.0 版本之前,Kafka 支持 3 种压缩算法:GZIP、Snappy 和 LZ4。从 2.1.0 开始,Kafka 正式支持 Zstandard 算法(简写为 zstd)。
Chaya:这么多压缩算法,我如何选择?
一个压缩算法的优劣,有两个重要的指标:压缩比,文件压缩前的大小与压缩后的大小之比,比如源文件占用 1000 M 内存,经过压缩后变成了 200 M,压缩比 = 1000 /200 = 5,压缩比越高越高;另一个指标是压缩/解压缩吞吐量,比如每秒能压缩或者解压缩多少 M 数据,吞吐量越高越好。
如下图是 Facebook Zstandard 官网提供的一份压缩算法 benchmark 比较结果:
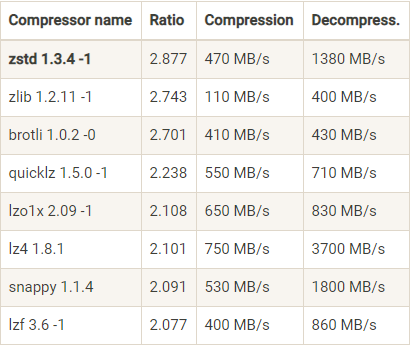
从图中可以看到,ZSTD 压缩比最高,但是吞吐量中规中矩。LZ4 在吞吐量方面属于王者。
-
GZIP:压缩比高,但压缩和解压缩速度相对较慢。适用于对传输带宽要求较高的场景。
-
Snappy:由 Google 开发,压缩和解压缩速度快,但压缩比相对较低。适用于对性能要求较高的场景。
-
LZ4:在压缩和解压缩速度以及压缩比之间取得良好平衡。适用于对性能和压缩比有综合需求的场景。
-
ZSTD:由 Facebook 开发,提供高压缩比和较快的压缩解压速度。适用于对高效压缩和快速处理都有需求的场景。
在 Kafka 的性能测试结果中,不同压缩算法的两个指标有以下排序特点。
-
吞吐量方面:LZ4 > Snappy > zstd 和 GZIP;
-
压缩比方面:zstd > LZ4 > GZIP > Snappy。
何时压缩
Chaya:我觉得可以在生产者和 Broker 端进行压缩,对么?
在生产者端压缩是很自然的想法,大部分情况下 Broker 收到 Producer 端的消息后是原封不动的保存,并不会进行压缩。
生产者压缩
Kafka 的数据压缩主要在生产者端进行。具体步骤如下:
-
生产者配置压缩方式 :在 KafkaProducer 配置中设置
compression.type参数,可以选择gzip、snappy、lz4或zstd。 -
消息压缩 :生产者将消息批量收集到一个
batch中,然后对整个batch进行压缩。这种批量压缩方式可以获得更高的压缩率。 -
压缩消息存储 :压缩后的
batch以压缩格式存储在 Kafka 的主题(Topic)分区中。 -
消费者解压缩 :消费者从 Kafka 主题中获取消息时,首先对接收到的
batch进行解压缩,然后处理其中的每一条消息。