参考自;c编译教程 | All about X-Wrt
需要详细了解的小伙伴还请参看原文 ^-^
概念:
x-wrt(基于openwrt深度定制的发行版本)
编译系统: ubuntu22.04
注意:
特别注意的是,整个编译过程,都是用 普通用户 操作,不要用 root用户 操作。
安装编译所需要的软件包:
sudo apt install build-essential ecj fastjar file flex g++ gcc-multilib g++-multilib gawk gettext git git-core java-propose-classpath libelf-dev libncurses5-dev libncursesw5-dev libssl-dev swig python3 python3-dev python3-distutils python3-pyelftools subversion unzip wget zlib1g-dev rsync qemu-utils
安装结果如下:
下载源码:
从github上clone源码:
git clone https://github.com/x-wrt/x-wrt.git
进入上面拉取过来的文件夹
cd x-wrt
#更新代码tag:
git fetch origin
git fetch origin --tag
#列出可以使用的版本tag:
git tag
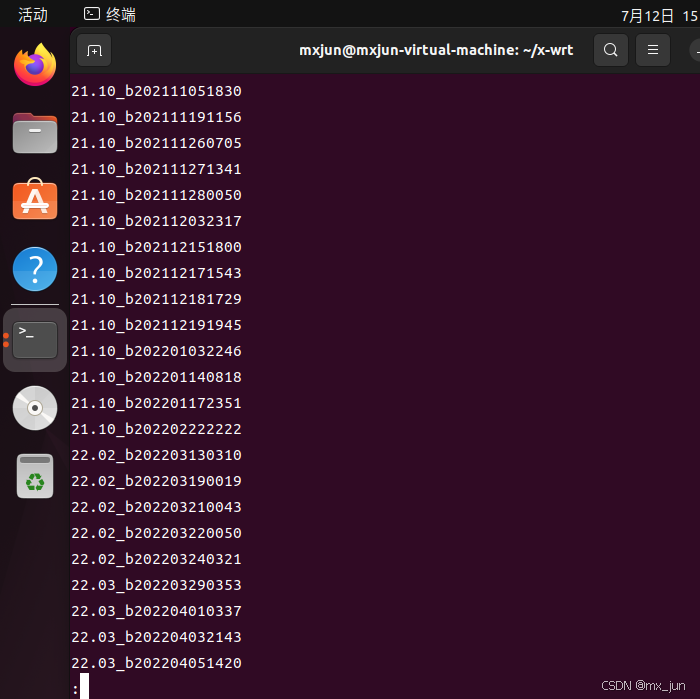
#注意摁 q 键结束
#或者直接获取最新发布版本
git describe --tags $(git rev-list --tags --max-count=1)
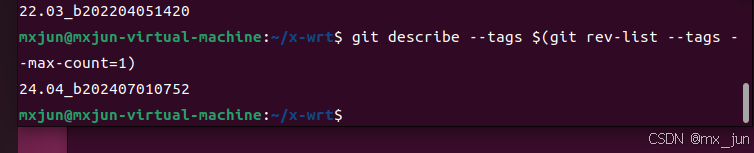
#选择并切换到指定的版本tag:
git checkout -f <tag-name>
在 Git 中,"tag"(标签)是一种用于标记特定提交点的机制,它给该提交点一个易于记忆和引用的名字。
例如
git checkout -f 22.03_b202204051420
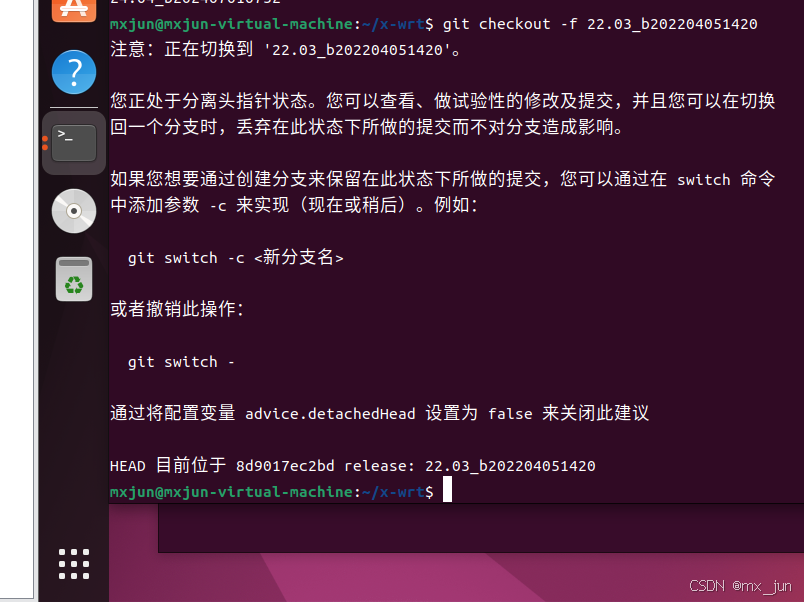
#或者 直接切换到最新版本额度tag
git checkout -f (git describe --tags (git rev-list --tags --max-count=1))
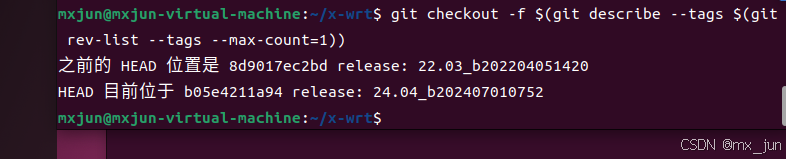
#更新代码:
./scripts/feeds update -a
./scripts/feeds install -a

配置固件
配置步骤
配置固件的命令make menuconfig 但是我们可以从配置模版开始会更轻松一些。
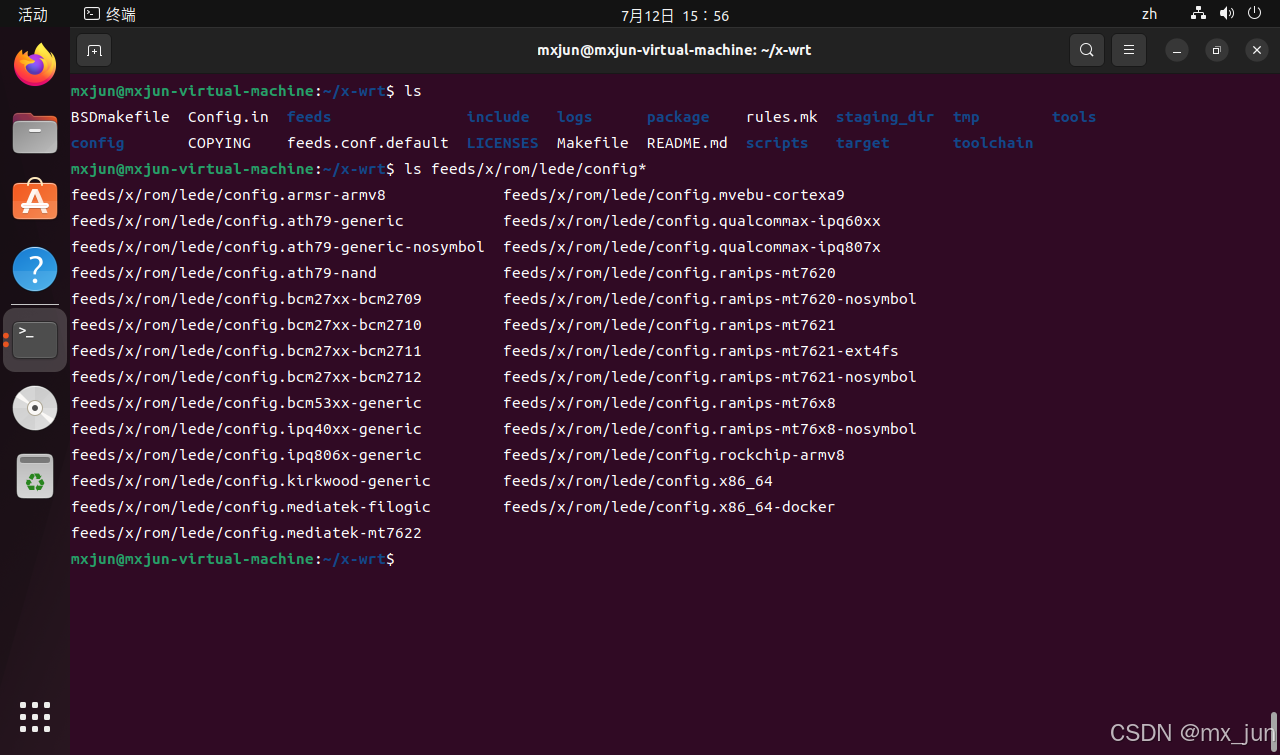
比如ramips-mt7621的设备可以用拷贝这个模版feeds/x/rom/lede/config.ramips-mt7621 内核分区限制小的设备,选用 -nosymbol 结尾的config配置模版
cp feeds/x/rom/lede/config.ramips-mt7621 .config

上面已经cp 拷贝了模版配置到 .config # 例如
cp feeds/x/rom/lede/config.ramips-mt7621 .config # 下面继续操作和修改
#1 执行 make menuconfig
#2 进入 Target Profile 选择需要编译打包的设备型号,选择型号后立刻退出,保存
#3 执行下面的命令修复 .config
sh feeds/x/rom/lede/fix-config.sh
#4 再次执行 make menuconfig 然后立刻退出保存
#5 最后一次 执行 make menuconfig 自定义选择你需要的软件包
更多配置

配置目标
在上述准备好的模版配置文件的基础上,执行make menuconfig命令进行个性化定制,增删应用。
定位到各个子菜单,选择对应的软件包
执行编译
命令:
make或者
make -j1 V=s生成的包在bin/targets/下面
如果需要再次修改配置编译,只要不是换设备 ,都可以直接**make menuconfig**修改后就编译,如果需要修改设备,请从拷贝模版配置的地方重新开始配置。
在使用 make 命令时,-l 和 V=s 是两个不同的选项,它们各自有不同的作用:
-
-l:这个选项告诉make在执行时不要超过指定的负载(load)。如果系统同时运行的make实例太多,make将等待直到负载降低到这个阈值以下。这有助于避免在构建过程中过度使用系统资源。 -
V=s:这里的V选项设置make的详细程度(verbosity)。s通常代表 "silent"(静默),意味着make将尽可能少地显示信息,通常只显示错误和警告。这有助于减少输出的噪音,特别是在日志文件中。
将这两个选项结合起来使用 make -l V=s 可能不是一个有效的命令,因为 -l 选项后面通常需要跟一个数字来指定负载限制,例如 make -l1。如果您的意图是设置详细程度为静默,并且限制系统负载,您应该分开写这两个选项,或者在 -l 后面提供一个具体的数字
总结
我们编译固件的时候一定要看编译出来的调试信息,缺少什么就去下载什么。
编译make menuconfig的时候我们很多时候不用手动的去 一个个在菜单里面去选,可以直接 cp 前人配置好的 config配置文件到 .config 里面,再执行
sh feeds/x/rom/lede/fix-config.sh
修复一下,即可配置成功,这个时候再次进去到make menuconfig 即可看到我们的配置结果,保存退出即可。
的以后如果我们有新的方案,要更新新的东西,我们修改config 文件即可,也没必要直接打开页面去配置。
我们在进行 编译前,如果有之前配置好的库文件,可以在当前目录下建立一个软链接,比如
ln -s /work/dl dl
这样编译的时候,下载库和工具的时候,会优先查找本地路劲,如果找不到再到云端去找,这样我们把库和工具放在本地路径了,就省略了编译的时候去云端下载拉取的时间。