在了解kettle血缘之前,咱们先来了解下什么是数据血缘?
1、数据血缘定义(来自gpt)
数据血缘(Data Lineage)是指在数据管理和数据分析中追踪数据的源头、流向和处理过程的能力。具体来说,数据血缘描述了数据如何被创建、变换和移动,以及这些过程中数据的路径和影响。它有助于理解数据的可靠性、完整性和可信度,是数据治理和合规性的重要组成部分。
在数据血缘中,常见的元素包括:
- 数据起源和输入:数据的来源,即数据是从何处获取的,可以是数据库、文件、API等。
- 数据转换和处理:数据如何被修改、转换、整合或聚合,包括数据清洗、计算和推断过程。
- 数据输出和消费:经过处理后的数据被用于何种用途,可能是生成报表、支持决策、供给其他系统等。
2、阿里数据血缘定义
数据血缘可以用于查看表和表、字段和字段之间的血缘关系,从而辅助业务进行数据的溯源和管理,在作业异常时也可以帮助业务分析上下游作业影响。
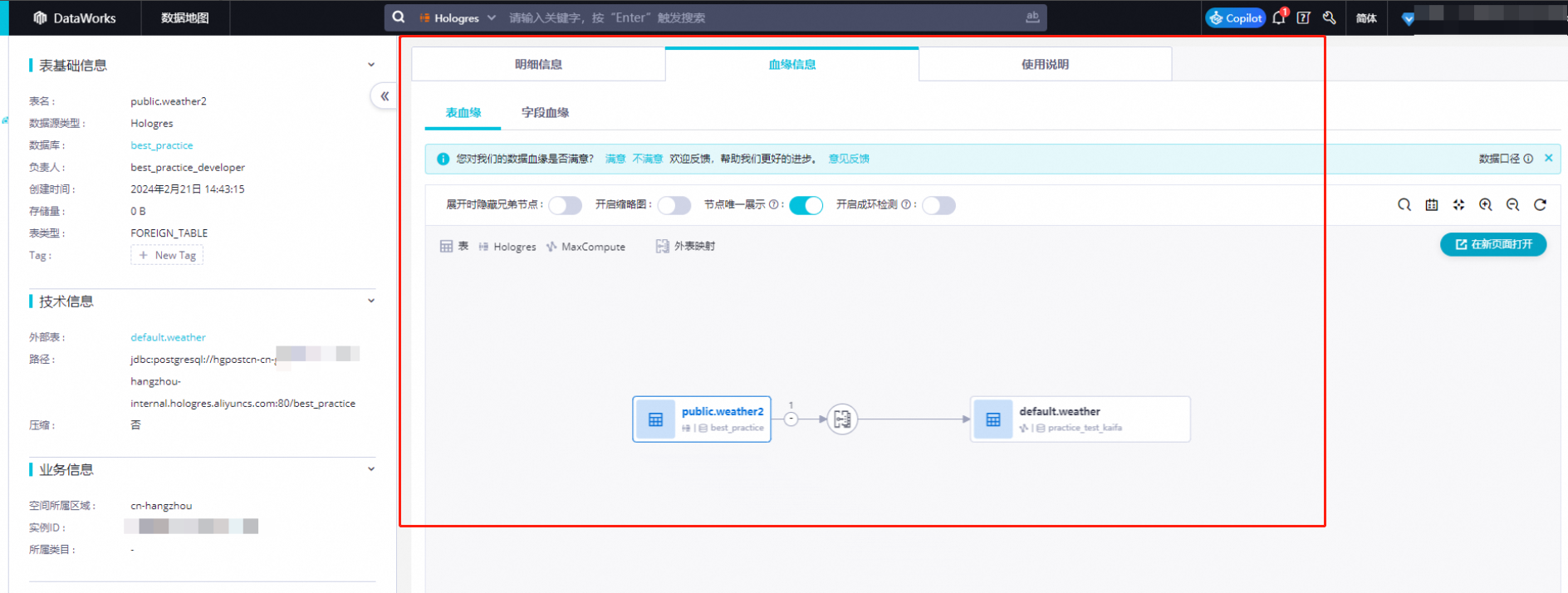
3、数据血缘管理
1)数据血缘基于数据流动,基于etl,假如没有中场景,也就不需要数据血缘。
2)数据血缘分为表级别血缘和字段级别血缘,一般情况下做到表级别血缘就可以了。这里说的表包含表和视图。
4、什么是kettle血缘
kettle是etl工具,所以kettle血缘的意思就是通过kettle的转换文件将血缘关系解析出来,通过页面呈现处理,方便排查问题。
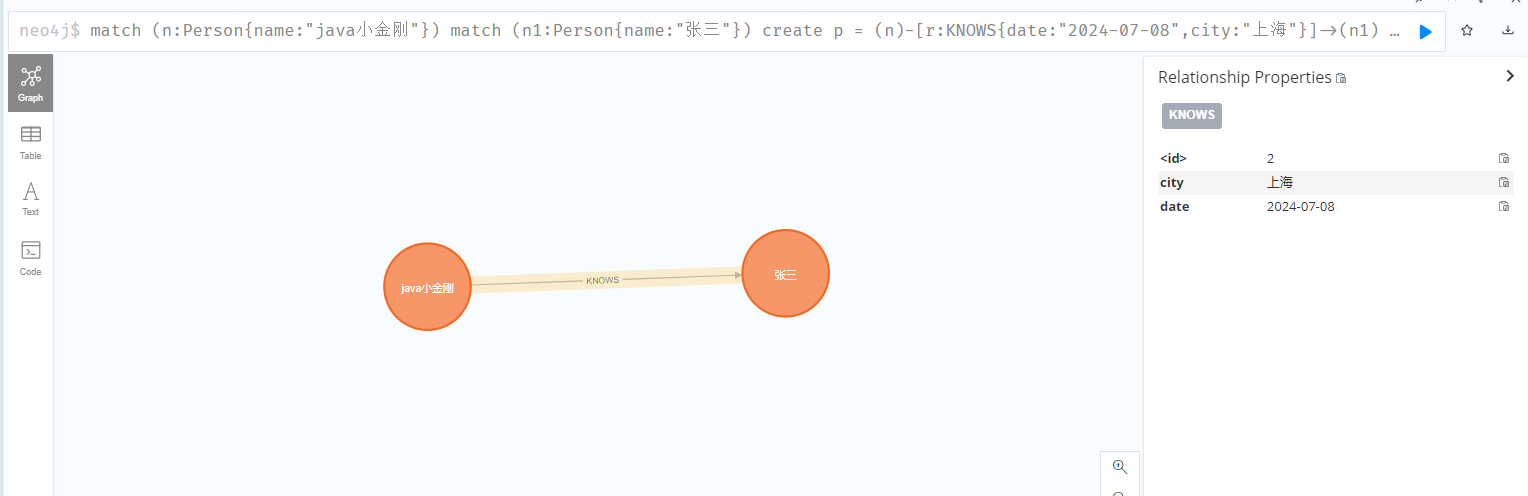
4、血缘存储工具
推荐neo4j图数据库,下图基于neo4j创建两个节点,然后建立关系的一个截图。后续会整理介绍下neo4j的相关知识。