This relatively easier post will be the opportunity to warm up by getting back to the basics of the Transformer architecture and text generation using Transformer-based decoders. Most importantly, I will establish the vocabulary I will use throughout the series. I highlight in bold the terms I personally favor. You will in particular learn about the two phases of text generation: the initiation phase and the generation (or decoding) phase.
First, a little Transformer refresher. For simplicity, let's assume that we process a single sequence at a time (i.e. batch size is 1). In the figure below I pictured the main layers of a vanilla Transformer-based decoder (Figure 1) used to generate an output token from a sequence of input tokens.

Figure 1 ---Outline of a Transformer decoder model
Notice that the decoder itself does not output tokens but logits (as many as the vocabulary size). By the way, the last layer outputting the logits is often called the language model head or LM head . Deriving the token from the logits is the job of a heuristic called (token) search strategy, generation strategy or decoding strategy. Common decoding strategies include:
- Greedy decoding which simply consists of picking the token with the largest logit, possibly after altering the logits using transformations such as a repetition penalty.
- Sampling decoding which consists of using the logits as a multinomial distribution to sample from. In other words, we pick a token from the vocabulary by sampling. The distribution we sample from can first be warped using simple transformations such as temperature scaling, top-k and top-p to mention the most well known.
- More complex heuristics such as beam search, contrastive decoding¹, etc.
For the sake of simplicity, we will assume the decoding strategy to be part of the model (Figure 2). This mental model is actually useful in the context of LLM serving solutions where such entities that take a sequence of tokens as input and return a corresponding output token are usually called an execution engine or an inference engine.
Figure 2 --- An overly simplified Transformer decoder model
And what about generating more than one token? Generating text (commonly named completion ) from an input text sequence (commonly named prompt) using a Transformer-based decoder basically consists of the following steps:
-
Loading the model weights to GPU
-
Tokenizing the prompt on CPU and transferring the token tensor to GPU (Figure 3)
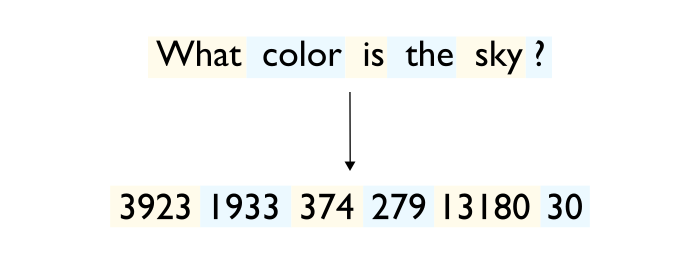
Figure 3 --- Tokenization step
- Generating the first token of the completion by running the tokenized prompt through the network.
This single-step phase is typically called the initiation phase . In the next post, we will see that it is also often called the pre-fill phase.
- Appending the generated token to the sequence of input tokens and using it as a new input to generate the second token of the completion. Then, repeat this process until either a stop sequence has been generated (e.g. a single end-of-sequence (EOS) token) or the configured maximum sequence length has been reached (Figure 4).
This multi-step phase is usually called the generation phase , the decoding phase , the auto-regressive phase or even the incremental phase.
Both step 3 and 4 are illustrated in the figure below (Figure 4).
Figure 4 --- Initiation and decoding phases of the token generation process
- Fetching the the completion's tokens to CPU and detokenize them to get your generated text (Figure 5).

Figure 5 --- Detokenization step
Notice: Recent and more advanced techniques aiming at achieving lower latency such as speculative sampling² or lookahead decoding³ don't exactly follow the simple algorithm described above.
At that point you should be either disappointed, confused or both. You could ask me: so what is the actual difference between the initiation phase and the decoding phase? It seems artificial at best at this point. The initiation phase feels indeed as special as the initialization step of a while loop and we essentially do the same in both phases: on each iteration we apply a forward pass to a sequence of tokens which gets one token larger every time.
You would actually be right. At that point, there is indeed no difference on how the computations are run on the hardware and therefore nothing special about either phase in that regard. However, and as we will see in the next post, this setup involves expensive computations (scaling quadratically in the total sequence length), a lot of which being actually and fortunately redundant. An obvious way to alleviate this is to cache what we could spare recomputing. This optimization is known as KV caching and introduces this critical difference I keep hinting at. See you on the next post!
1: A Contrastive Framework for Neural Text Generation (Su et al., 2022)
2: Fast Inference from Transformers via Speculative Decoding (Leviathan et al., 2022)
3: Breaking the Sequential Dependency of LLM Inference Using Lookahead Decoding (Fu et al. 2023)