场景:kettle调用存储过程,存储过程中通过select * from table 方式返回结果集,kettle接收结果集。
解决方案:1)借助临时表。2)表输入步骤。今天主要讲解表输入。
1、创建一个无参存储过程,脚本中通过select * from t1 返回数据集。脚本如下:
sql
use test;
drop procedure if exists sp_without_param1;
delimiter //
create procedure sp_without_param1()
begin
-- 查询数据集
select * from t1;
end //
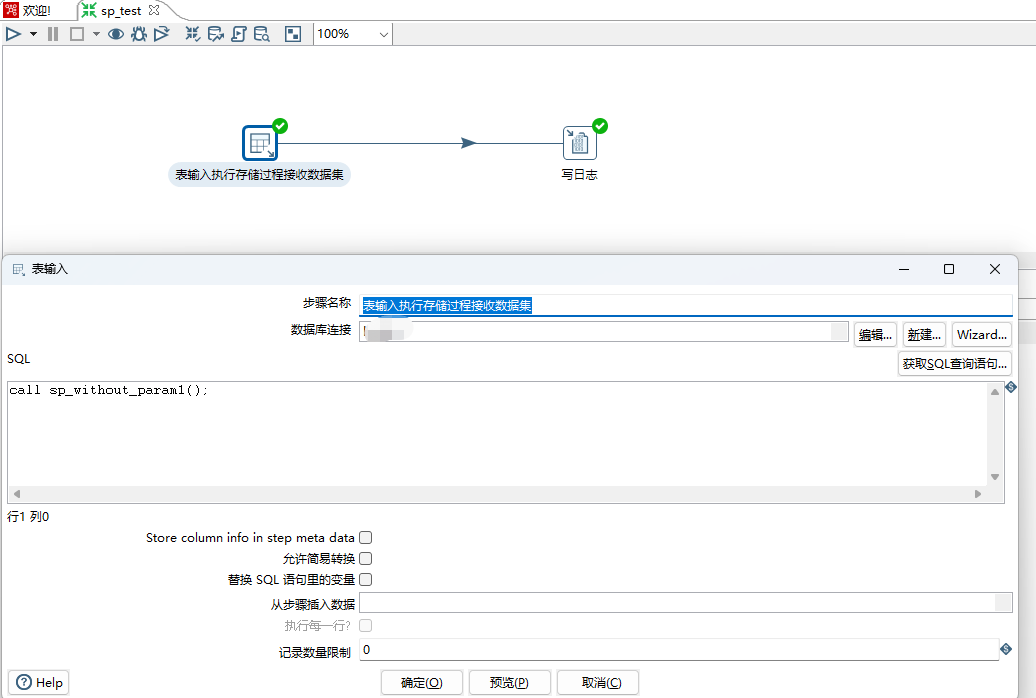
delimiter ;拖动取表输入步骤、写日志步骤到画布,表输入步骤sql填写call sp_without_param1,如下图所示:
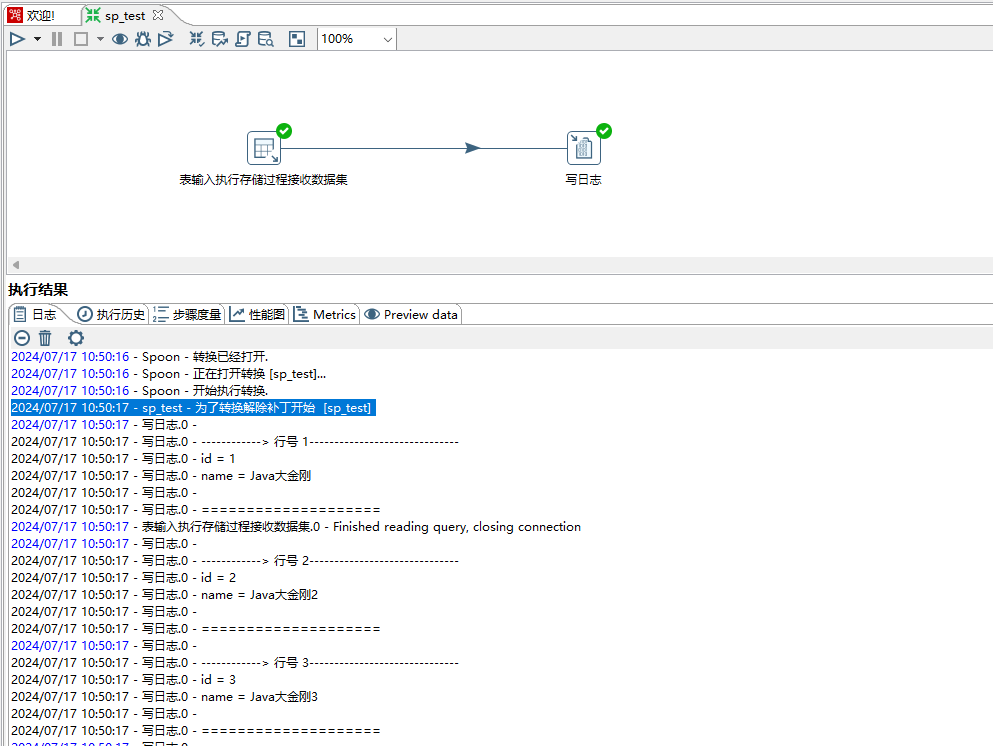
保存,然后点击运行按钮,存储过程中的数据集被正常打印出来,如下图所示:
2、创建一个只有入参的存储过程,脚本中通过select * from t1 where id=pId;返回数据集。脚本如下:
sql
use test;
drop procedure if exists sp_with_param2;
delimiter //
create procedure sp_with_param2(IN pId VARCHAR(255))
begin
-- 查询数据集
select * from t1 where id=pId;
end //
delimiter ;表输入步骤sql填写call sp_without_param2("1"),保存&点击运行按钮,数据集正常打印。如下图所示:
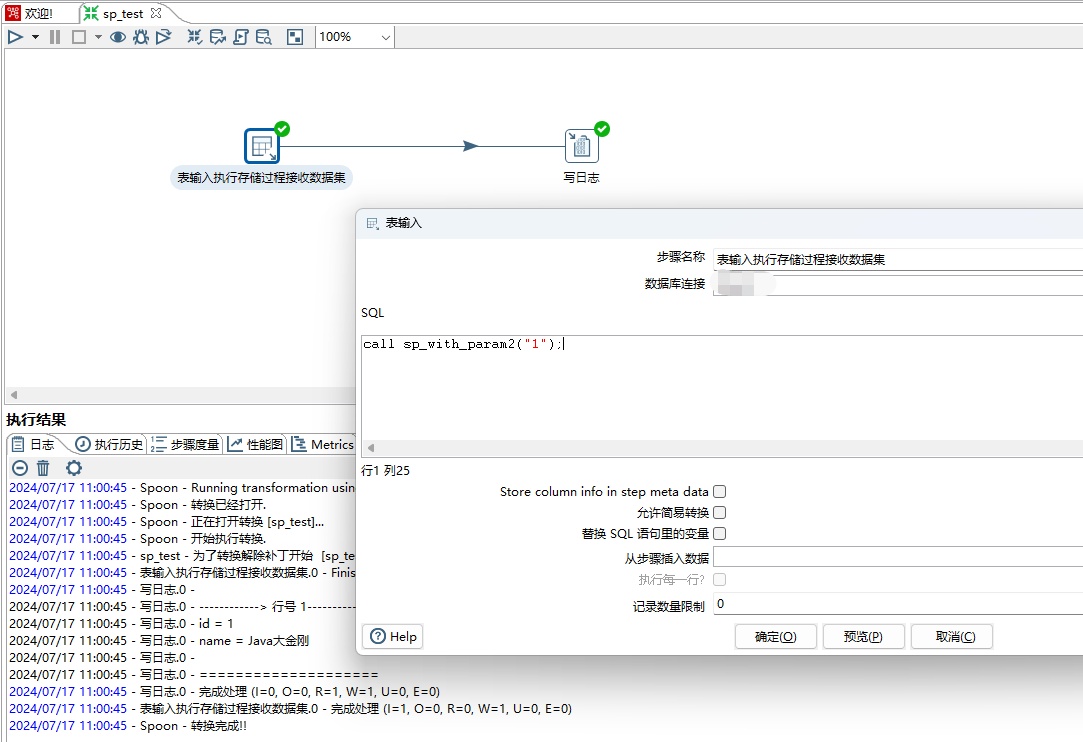
3、创建一个有入参和出参的存储过程,脚本中通过select * from t1 where id=pId;返回数据集。脚本如下:
sql
use test;
drop procedure if exists sp_with_param3;
delimiter //
create procedure sp_with_param3(IN pId VARCHAR(255) ,OUT result VARCHAR(255))
begin
-- 查询数据集
select * from t1 where id=pId;
set result="done";
end //
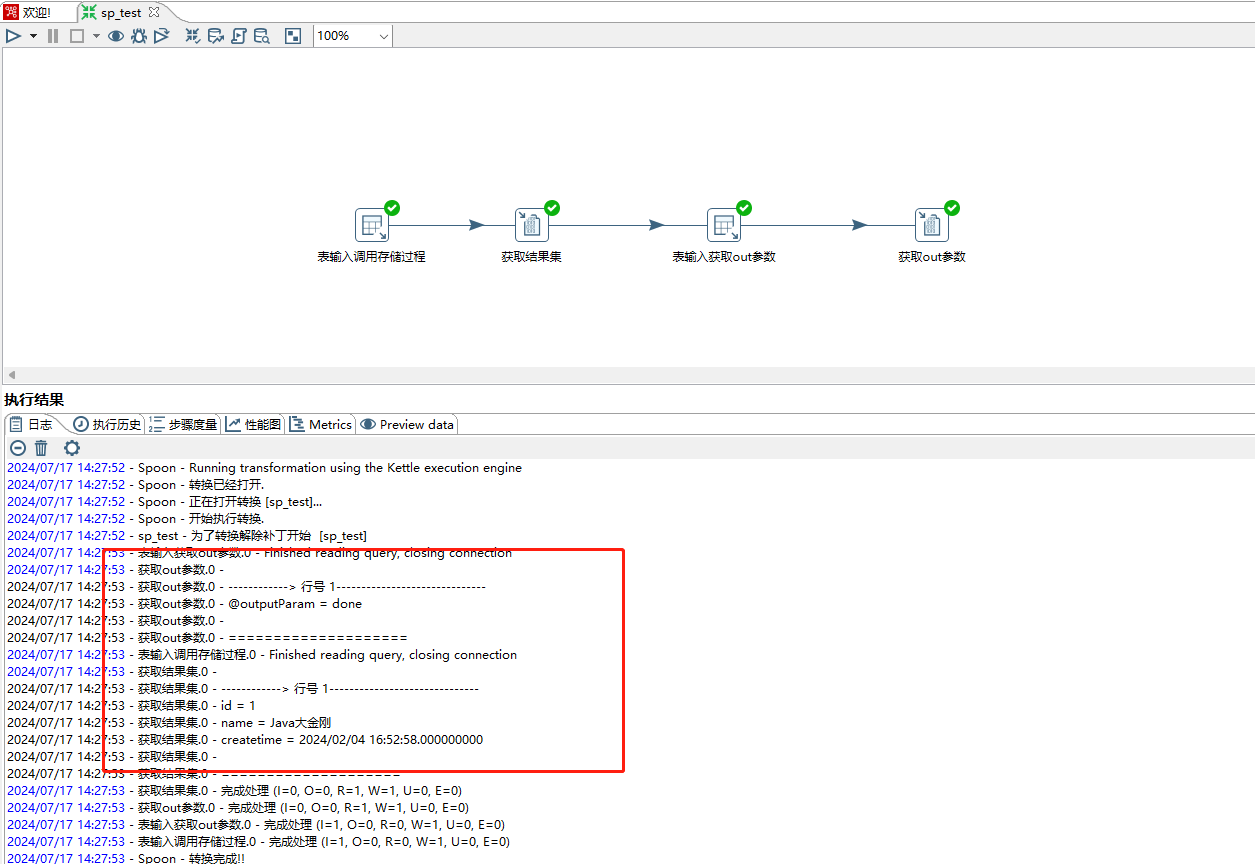
delimiter ;表输入步骤sql填写call sp_without_param3("1",@outputParm)。如下图所示:
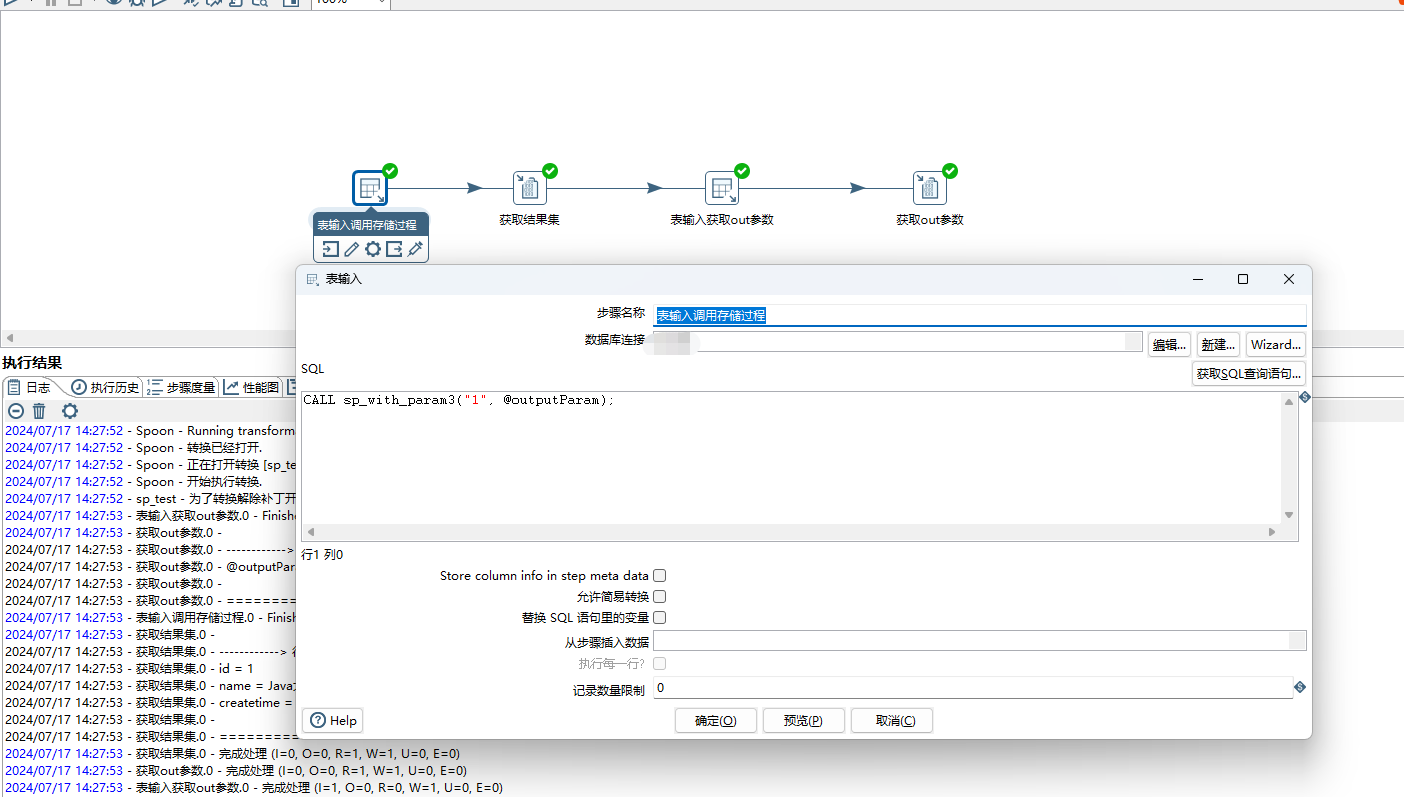
使用表输入步骤单独获取out参数,sql为select @outputParam;,如下图所示
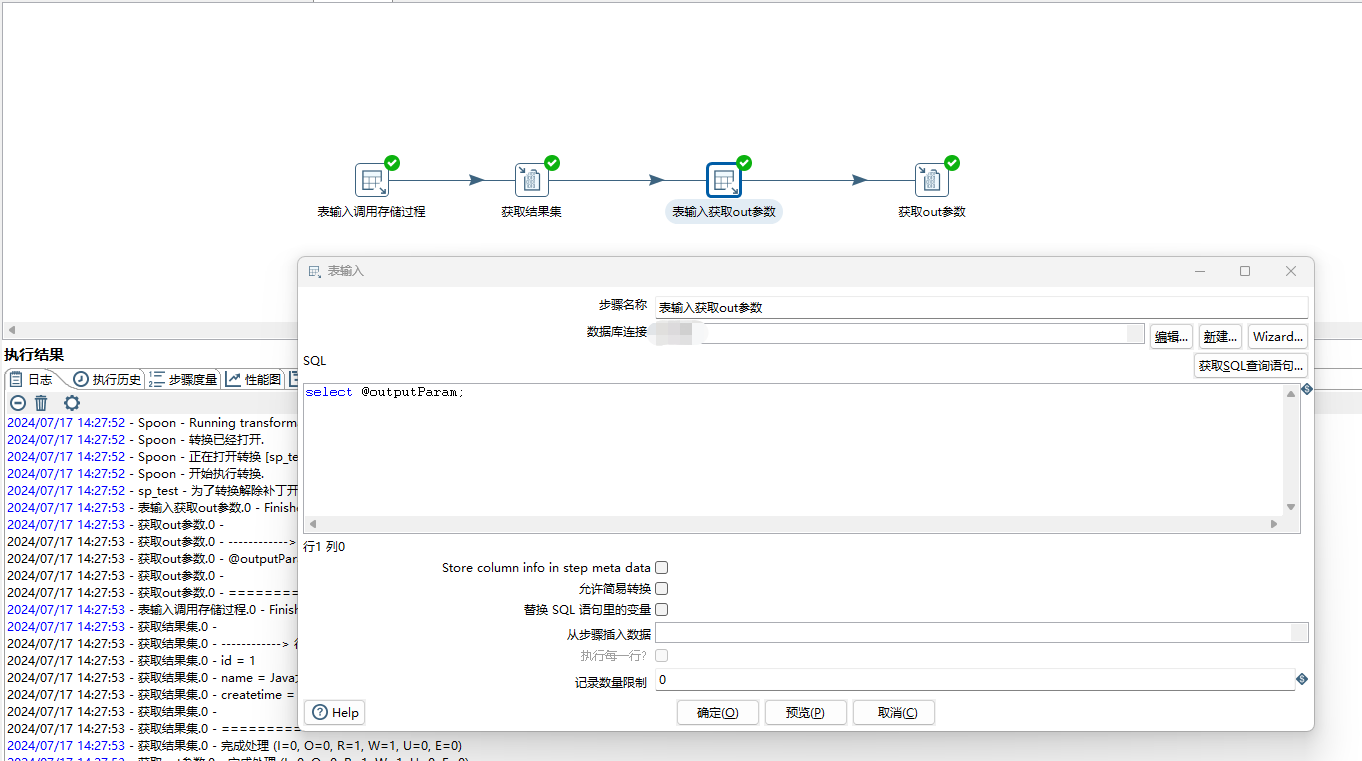
保存&点击运行,结果集和out参数正常打印。