一、前言
本系列旨在介绍通用图形处理器设计GPGPU的基础与架构,因此在介绍GPGPU具体架构之前,需要了解GPGPU的编程模型,了解软件层面是怎么做到并行的,硬件层面又要怎么配合软件,乃至定出合适的架构来实现软硬件协同。
二、通用编程背景
为了满足人们对GPU进行通用编程的需求,NVIDIA 公司于2007年发布了CUDA(Compute Unified Device Architecture, 计算统一设备体系结构),支持编程人员利用更为通用的方式对GPU进行编程,更好地发挥底层硬件强大的计算能力,从而高效地解决各领域中的计算问题和任务。随后,苹果、AMD和 IBM 等公司也推出了OpenCL(Open Computing Language, **开放运算语言)**标准。该标准成为第一个面向异构系统通用并行编程的免费标准,适用于多核CPU 、GPGPU等多种异构并行系统。
三、GPGPU计算模型
本主要以CUDA并行编程中的一些架构概念来展示GPGPU的计算和存储模型。作为首个GPGPU编程模型,CUDA 定义了以主从方式结合单指令多线程(Single Instruction Multiple Threads,SIMT)硬件的多线程计算方式。

以上图的矩阵乘法为例,矩阵C中每个元素都可以由一个输入矩阵A的行向量和另一个输入矩阵B的列向量 进行点积运算得到。C中每个元素的计算过程都可以独立进行,不存在依赖关系,因此具有良好的数据并行性。
在GPGPU中,承担并行计算中每个计算任务的计算单元称为线程(Thread),每个线程在一次计算任务过程中会执行相同的指令。在上例矩阵乘法中,每个线程会从矩阵A和B读取对应的行或列构成向量a和b, 然后执行向量点积运算,最后将结果c存到结果矩阵C的对应位置。
虽然每个线程输入数据不同,输出的结果也不同,但是每个线程需要执行的指令完全相同。++也就是说,++++一条指令被多个线程同时执行++ ,这就是GPGPU 中的单指令多线程(Single Instruction Multiple Threads,SIMT)计算模型。
为了针对复杂的大规模通用计算场景将不方便处理,CUDA 引入了线程网格(thread grid)、线程块(thread block)、线程(thread)。Thread Block由多个Thread组成,而Grid又由多个Thread Block组成。因此,它们的关系就是Grid > Block > Thread。
在CUDA编程模型中,通常将代码划分为主机端(**host) 代码和设备端(**device) 代码,分别运行在CPU和GPGPU上。CPU硬件执行主机端代码,GPGPU硬件将根据编程人员给定的线程网格组织方式将设备端代码分发到线程中。
主机端代码通常分为三个步骤。①数据复制:CPU将主存中的数据复制到GPGPU中。②GPGPU启动:CPU 唤醒GPGPU线程进行运算。③数据写回:GPGPU运算完毕将计算结果写回主机端存储器中。
设备端代码常常由多个函数组成,这些函数被称为内核函数(kernel)。内核函数会被分配到每个GPGPU的线程中执行,而线程层次则由编程人员根据算法和数据的维度显式指定,如下图所示。

基于上面的线程层次,编程人员需要知道线程在网格中的具体位置,才能读取合适的数据执行相应的计算。因此,CUDA引入了为每个线程指明其在线程网格中哪个线程块的 blockIdx(线程块索引号)和线程块中哪个位置的threadIdx(线程索引号)。blockIdx有三个属性,x、y、z描述了该线程块所处线程网格结构中的位置。threadIdx 也有三个属性,x、y、z 描述了每个线程所处线程块中的位置。在一个Grid中:根据blockIdx和threadIdx,我们就能唯一锁定到某个线程,进而编程让其做具体计算。例如下面这段代码,调用线程进行了矩阵加法。
// Kernel定义
__global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}矩阵加法计算时,数据之间没有依赖性,每个线程都是并行独立地操作数据。
到此,可能会有个疑问,既然通用计算追根到底是索引到单个thread再做计算,那么假设没有block,我纯靠threadidx也能唯一索引到某个线程,block存在的意义到底是什么?。这就要引入共享存储器和全局存储器的概念了
首先,共享存储器 的访问比全局存储器 更快,++共享存储器作用于一个线程块(thread block)内部,++++可以为同一个线程块内部的线程++ ++提供更快的数据访问++。因此,通过合理划分块(block)的大小,可以充分利用数据的局部性原理减少对设备端全局存储器的访问,从而提高运算性能。此外,线程之间由于应用的特点可能不能完全独立。比如归约(reduction)操作需要邻近的线程之间频繁地交互数据 ,以协作的方式产生最终的结果,多个线程之间还可能需要相互同步,block的存在提高了线程之间的协作能力。
四、自线程到硬件结构
为了实现对大量线程的分配,GPGPU 对硬件功能单元进行了层次化的组织,如图所示。

它主要由流多处理器(Streaming MultiProcessor,SM)阵列和存储系统组成,两者由片上网络连接到L2高速缓存和设备端存储器上。每个流多处理器内部有多个流处理器(Streaming Processor,SP)单元,构成一套完整的指令流水线,包含取指、译码、寄存器文件及数据加载/存储(load/store)单元等,并以SIMT 架构的方式进行组织。++GPGP++++U的整体结构、SM 硬件 和SP++ ++硬件对应了线程网格、线程块和线程的概念++,实现了线程到硬件的对应分配规则。
五、存储模型
GPGPU利用大量的线程来提高运算的并行度,这些线程需要到全局存储器中索引相应的数据。为了减少对全局存储器的访问,GPGPU架构提供了多种存储器类型和多样的存储层次关系来提高kernel函数的执行效率,如下表所示。
|--------------------------|------------------|
| Memory Description | CUDA Memory Name |
| 所有的线程(或所有work-items)均可访问 | global memory |
| 只读存储器 | constant memory |
| 线程块(或work-group)内部线程访问 | shared memory |
| 单个线程(或work-item)可以访问 | local memory |
CUDA 支持多种存储器类型,线程代码可以从不同的存储空间访问数据,提高内核函数的执行性能。每个线程都拥有自己独立的存储空间,包括寄存器文件(Register File) 和局部存储器(Local Memory) ,这些存储空间只有本线程才能访问。每个线程块允许内部线程访问共享存储器(Shared Memory),在块内进行线程间通信。线程网格内部的所有线程都能访问全局存储器(Global Memory) ,也可以访问纹理****存储器(Texture Memory) 和**常量存储器(Constant Memory)**中的数据。

① 寄存器文件(Register File)是 SM 片上存储器中最为重要的一个部分,它提供了与计算内核相匹配的数据访问速度。大容量的寄存器文件能够让更多的线程同时保持在活跃状态。这样当流水线遇到一些长延时的操作时,GPGPU可以在多个线程束之间快速地切换来保持流水线始终处于工作状态。这种特性在GPGPU中被称为零开销线程束切换(zero-cost warp switching),可以有效地掩藏长延时操作,避免流水线的停顿。
② 局部存储器(Local Memory)是每个线程自己独立的存储空间,局部存储器是私有的,只有本线程才能进行读写。
③ 共享存储器(Shared Memory)也是SM 片内的高速存储资源,它由一个线程块内部的所有线程共享。相比于全局存储器,共享存储器能够以类似于寄存器的访问速度读写其中的内容。
④ 全局存储器(Global Memory)位于设备端。GPGPU内核函数的所有线程都可对其进行访问,但其访存时间开销较大。
⑤ 常量存储器(Constant Memory)位于设备端存储器中,其中的数据还可以缓存在SM内部的常量缓存(Constant Cache)中,所以从常量存储器读取相同的数据可以节约带宽,对相同地址的连续读操作将不会产生额外的存储器通信开销。
⑥ 纹理存储器(Texture Memory)位于设备端存储器上,其读出的数据可以由纹理缓存(Texture Cache)进行缓存,也属于只读存储器。
六、同步机制
在SIMT 计算模型中,每个线程的执行都是相互独立的。然而在实际的应用和算法中,除向量加这种可完全并行的计算之外,并行的线程之间或多或少都需要某种方式进行协同和通信,例如:
① 某个任务依赖于另一个任务产生的结果,例如生产者-消费者关系;
② 若干任务的中间结果需要汇集后再进行处理,例如归约操作。
这就需要引入某种形式的同步操作,以Thread Block中的线程同步为例:
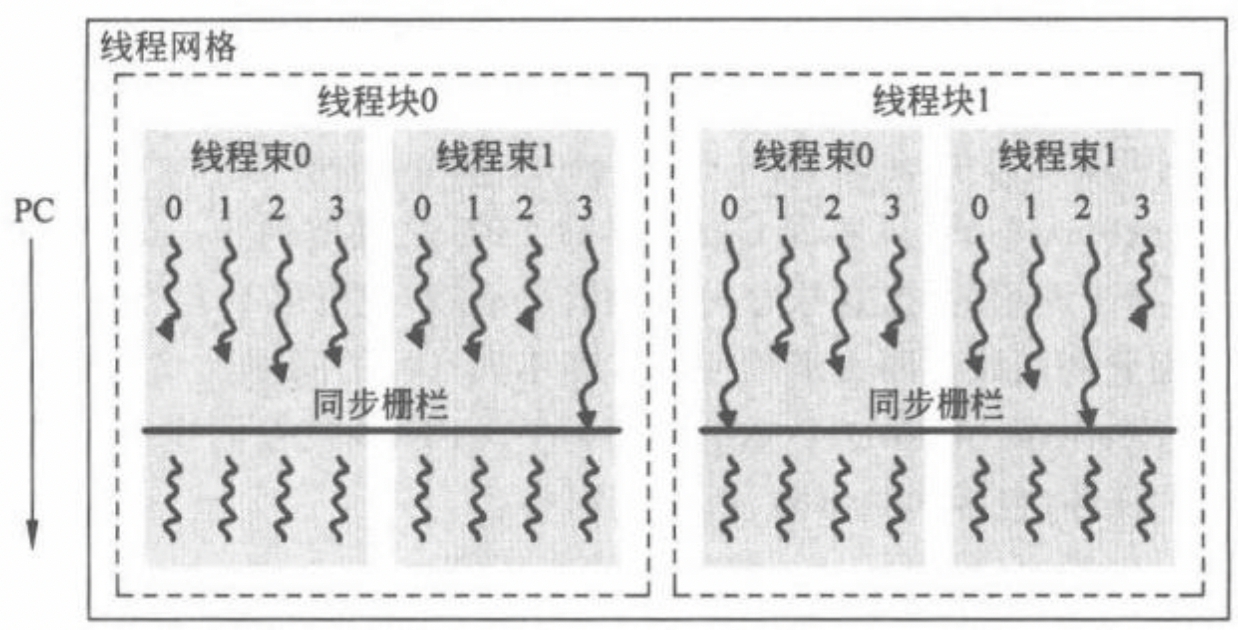
在CUDA 编程模型中,__**syncthreads() 可用于同一线程块内线程的同步操作,它对应的PTX 指令为bar 指令。该指令会在其所在程序计数器(Programe Counter,PC)位置产生一个同步栅栏(barrier),并要求线程块内所有的线程都到达这一栅栏位置才能继续执行,这可以通过监控线程的****PC** 来实现。在线程同步的要求下,即便有些线程运行比较快而先到达bar指令处也要暂停,直到整个线程块的所有线程都达到bar指令才能整体继续执行。
七、总结
本文介绍了GPGPU编程的背景、CUDA编程实现步骤、软件到硬件的过度以及存储模型等内容,为后续介绍GPGPU架构提供理论基础。