在企业中通常存在两类数据处理场景,一类是在线事务处理场景(OLTP),例如交易系统,另一类是在线分析处理场景(OLAP),例如业务报表。
OLTP 数据库擅长处理数据的增、删、改,以及小数据量的查询,更侧重数据的实时响应、高吞吐和事务性等要求。OLAP 则以大数据量的复杂查询为主,更侧重数据容量的扩展性、复杂计算能力等要求。
为了满足这两类业务场景,企业通常会采用 OLTP + OLAP 的组合方案或者分布式HTAP 数据库的产品方案。
- 使用 OLTP + OLAP 的组合方案。他是采用分而治之的设计思路,不同的业务场景跑在各自擅长的数据库上,再通过 ETL 进行数据的异步同步。该方案能满足复杂的业务场景,但需要企业具有较强的 IT 能力。
- 使用具备 HTAP 能力的分布式数据库。这类方案通过 zeroETL 屏蔽了 OLTP 和 OLAP 之间数据同步的复杂性,达到了简化业务架构效果,可以满足一些「重 TP 轻 AP」的场景。不过,这个方案涉及业务全面支持分布式改造。
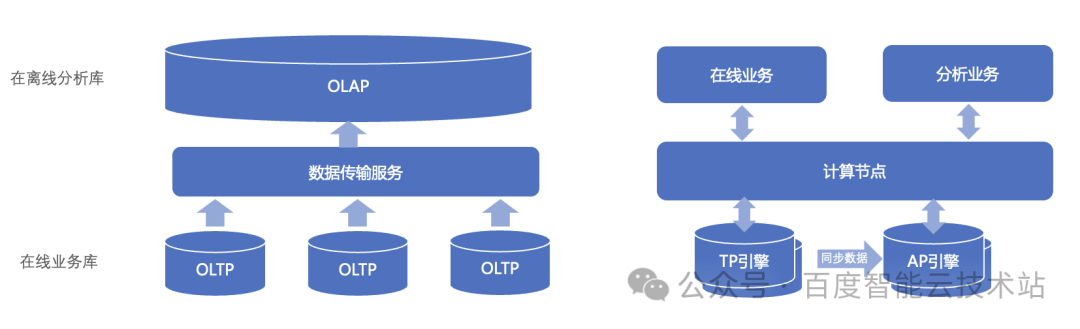
除了以上两种方案,是否有更加轻量化的解决方案,用一套数据库同时满足 TP(事务处理) 和 AP(复杂分析处理)业务呢?
很多企业用户由于找不到更加低成本、轻改造、易上手的解决方案,业务不得不勉强使用 TP 类型的数据库 MySQL 来承载 AP 业务。
GaiaDB 4.0 新增并行查询能力
大家最早认识云原生数据库 GaiaDB 是作为「MySQL Plus」的替代品,100% 兼容 MySQL,扩展性和性能又远超于开源 MySQL,所以 GaiaDB 在海量数据、高吞吐的场景,可以平滑替代 MySQL。
在 GaiaDB 4.0 之前,GaiaDB 像 MySQL 一样,无法很好支持复杂的分析处理需求,一条复杂的查询通常要处理几十秒甚至更长时间。
为了解决这个问题,GaiaDB 4.0 针对在线实时的分析业务发布了并行查询能力,使得业务在同一套集群上,无需任何改造即可满足复杂分析的需求。
众所周知,软件性能的提升一方面源于 CPU 硬件能力的增强,另一方面也得益于软件设计能够充分利用 CPU 的计算资源。
在 MySQL 的各个版本中,单个查询的执行通常是在一个独立的线程中完成,即对应一个 CPU 核。然而,在多核 CPU 下,仅依赖单个线程来执行查询无法充分利用硬件资源,特别是当涉及到 I/O 密集型操作或复杂查询时。
故 MySQL 在处理复杂查询时会有性能瓶颈,并且无法单纯通过提高资源配置解决这个问题。因此,简单的解决方案是充分利用 CPU 的多核计算资源,让多个核参与到计算任务中,这样才能大幅度提升查询计算的处理能力。
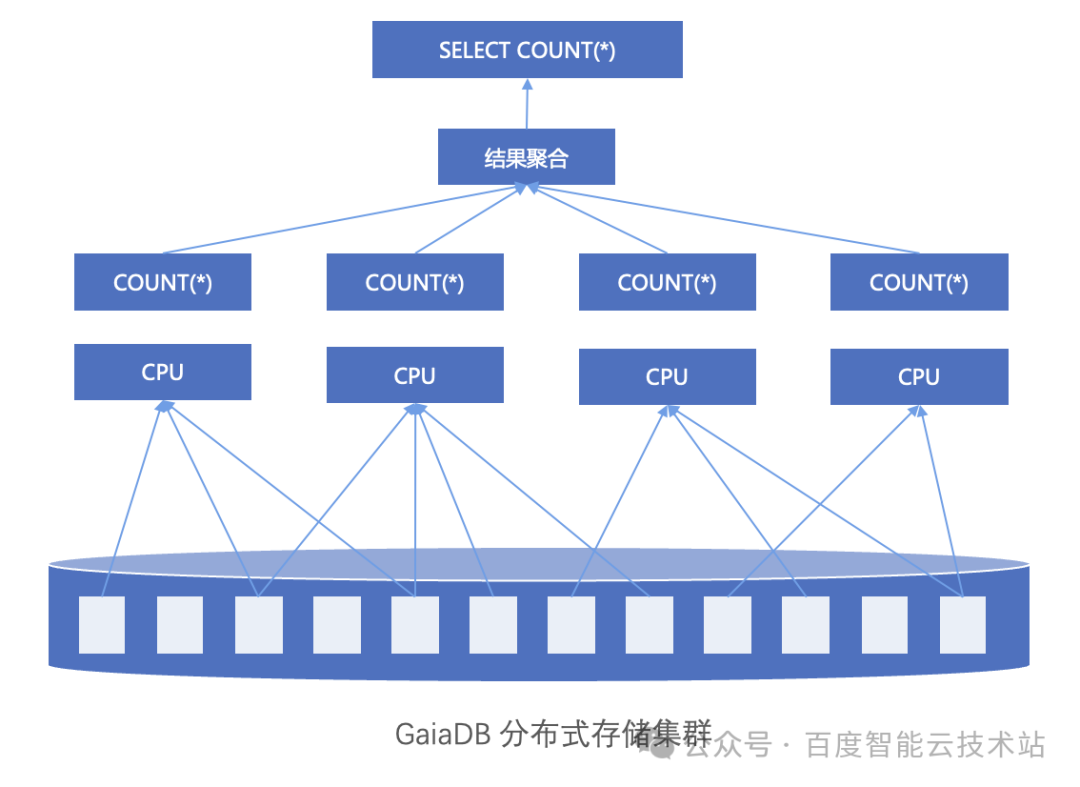
下图是 GaiaDB 利用多核资源并行计算一个表的 count(*) 过程的例子:表数据进行切块后,分发给多个 CPU 核进行并行计算,每个核计算部分数据得到一个中间 count(*) 结果,并在最后阶段将所有中间结果进行聚合得到最终结果。相比单线程处理的计算方式,GaiaDB 处理复杂查询任务的性能提升 1 到 2 个量级。
技术实现思路
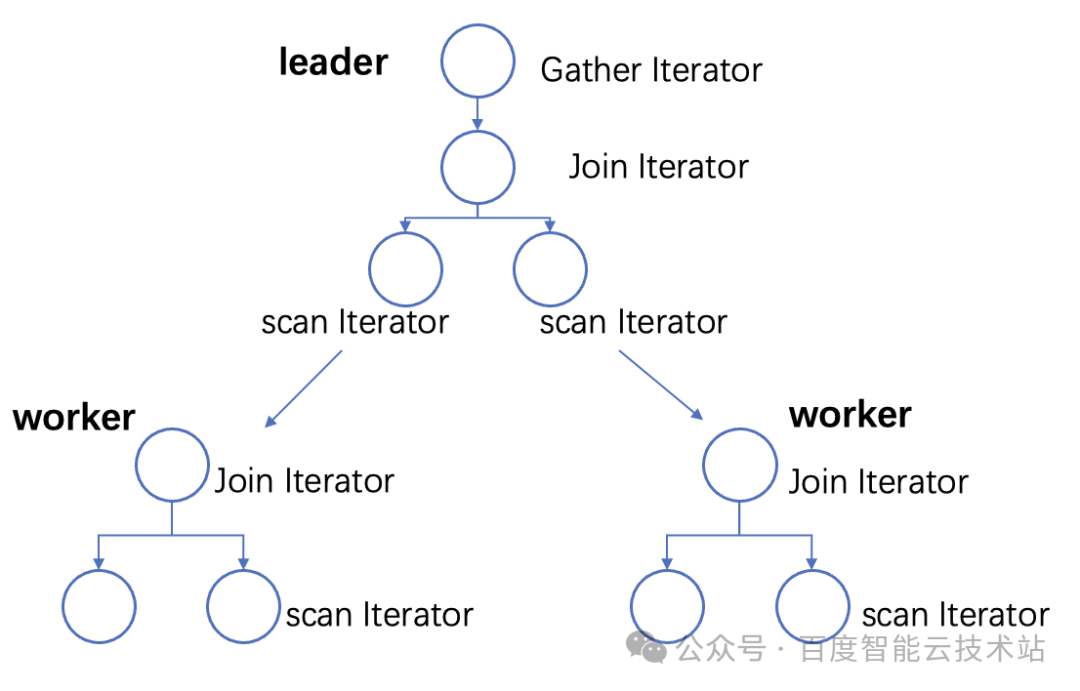
GaiaDB 并行查询技术的整体实现思想是对能够并行的查询算子(scan、gather等)进行并行化,在执行查询任务时将数据分片并启动若干个工作线程分别计算,最后将结果汇总返回给客户端。同时 GaiaDB 并行执行增加数据交互算子(stream),实现多个工作线程之间的数据交互,确保查询的正确性,完成整体的查询。
如下图,通过对算子进行线程拆分,将完整数据分区下推到不同的 worker 线程上,利用多个线程进行并行计算,并将结果汇总到 leader 线程上,leader 对返回的数据进行汇总处理并返回给用户。
scan 算子并行化
在火山模型中,每个算子除了包括基础的构造函数外,都包含 Init 和 Read 函数,Init 函数做执行前的一些准备工作,Read 函数向下层算子发送命令并返回数据到上层算子。
Init 接口实现:并行扫描算子需要在扫描前将需要扫描的表提前切分成 partition,并放入 Ctx(execution context) 中。
并行扫描算子 Read接口设计:Read 接口中需要实现从 Ctx 中 dequeue 当前的 Ctx,并标记为 m_cur_ctx。根据 m_cur_ctx 中的 scan_ctx,拿到 execution context 信息,返回当前 m_cur_ctx 的第一个 record,并记录下一个 record 的位置,待下一次读取。m_cur_ctx 扫描完成后,从 m_ctxs 中取得下一个 ctx,重复读取以取完所有的数据。
ParallelTblScanIterator 与 TableScanIterator 的区别在于,并行扫描算子 ParallelTblScanIterator 将一个全表扫描任务划分成多个ctx 的子任务,便于多个线程协作,而 TableScanIterator 无法将任务拆分成多个子任务,导致无法并行执行。
scan 算子的示例说明,我们可以看到如下执行计划,表的整个扫描是串行进行的。

当开启并行查询后,启动了多个 worker 线程进行并行执行,然后在 gather 阶段将每个线程查询的结果进行聚合并返回。

gather 算子并行化
gather 算子是承上启下的算子,其主要功能是将上下文等执行相关信息传递给 worker 线程,同时将返回的数据经过处理后返回给 client。
gather 算子将原来执行 query 的单个线程,拆分成一对多的线程模型。gather 算子在 read 时创建新的线程,并拷贝执行所需要的所有变量,转由另外的线程执行,leader 线程在 message queue 中等待数据返回。ParallelWorkerArray 包括所有的 worker 信息,由 gather 算子维护清理。
gather 算子除了完成简单的数据转发功能外,还需要完成简单的计算。举例来说,假设每个 worker 线程的结果是 sum 函数结果,那么 gather 算子需要将各个 worker 线程的结果加起来。假设 query 最后需要排序,则 leader 线程需要将各个 worker 线程的结果重新排序后返回。
更多算子并行化
GaiaDB 支持多种类型的并行查询算子,以满足客户各种不同复杂查询场景。已经支持的并行查询算子包括:
- 并行过滤(Filter)算子:where/having 等;
- 并行扫描(Scan)算子:Projection 等;
- 并行连接(Join)算子:HashJoin、NestLoopJoin、SemiJoin 等;
- 并行聚合(Agg)算子:SUM/AVG/COUNT/BIT_AND/BIT_OR/BIT_XOR 等;
- 并行排序(Sort)算子:order by;
- 并行分组(group by)算子:group by;
- 其他并行算子:limit(Limit/Offset),UNION 等。
GaiaDB 并行性能测试
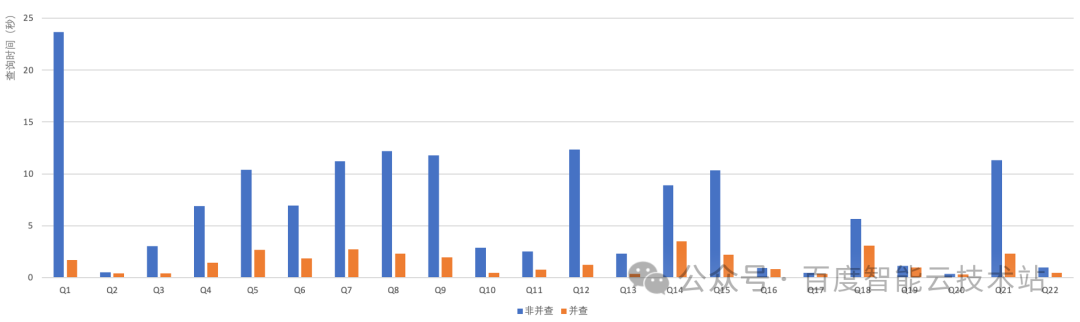
下图是 GaiaDB 针对 TPC-H 查询场景的性能测试结果。与传统 MySQL 单线程相比,在 32 线程并行执行下,GaiaDB 单表复杂查询性能最高提升 14 倍,平均提升 8+ 倍。
测试环境:32 核,2 个 numa node,Intel(R) Xeon(R) Silver 4110 CPU @ 2.10 GHz,内存 128 GB,测试数据量 100 GB,并发线程数据 32。
如图,32 核 CPU 利用率最高提升到 100%。

开启 GaiaDB 并行查询
GaiaDB 提供 2 种启动并行查询的方法:
例如:采用默认的参数配置,同时指定并发度为 8:SELECT /*+ PQ(8) */ ... FROM ...
- 通过修改 GaiaDB 集群的全局参数开启并行查询能力。参数如下:
-
SET force_parallel_execute=ON 开启并行查询;
parallel_default_dop=4 控制使用多少线程并行执行,默认并发度为 4;
parallel_cost_threshold=1000 控制执行代价多大时,开启并行执行,默认是 1000;
-
- 通过使用 HINT 方式,在指定的 SQL 语句上开启并行查询能力。语法:SELECT /*+ PQ(并发度) */ ... FROM ...
另外一个提升复杂查询性能的方法
通过并行查询的方式,GaiaDB 将 CPU 资源和存储 I/O 充分利用起来,大幅提升复杂查询的处理性能。
除此之外,云原生数据库 GaiaDB 4.0 还推出了另外一个性能提升利器 --- 列存索引技术,通过在数据表上为指定列创建列存索引,能够进一步加速查询性能。