目录
一、增删查改
1.添加数据
c
insert into 表名(字段名1,字段名2...) values(值1,值2...);2.修改数据
c
update 表名 set 字段名1=值1, 字段名2=值2 where ...;3.删除数据
c
delete from 表名 where...4.查询数据
4.1 条件查询
c
select [distinct] 字段名1,字段名2 from 表名 where...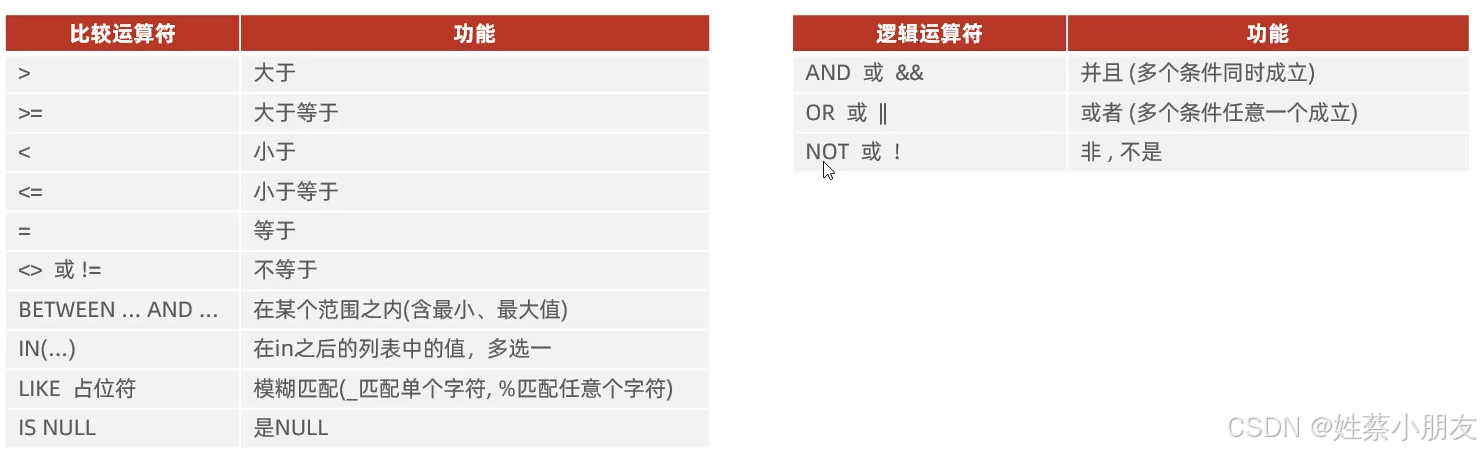
4.2 聚合函数
c
select 聚合函数(字段列表) from 表名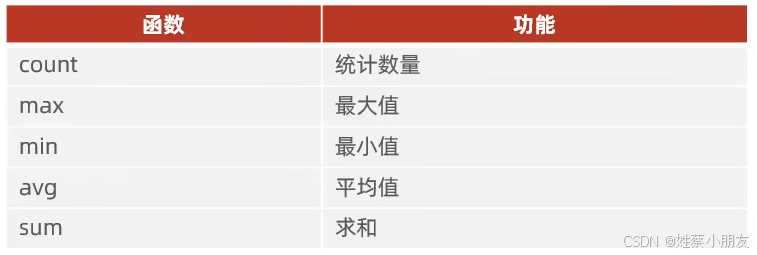
4.3 分组查询
c
select 字段列表 from 表名 [where 条件] group by 分组字段 [having 分组后过滤条件]其中having是分组之后进行过滤的,所以相较于where在分组之前进行过滤,having可以对聚合函数过滤。
c
select gender, avg(age) from emp where age>18 group by gender having avg(age)>204.4 排序查询
c
select 字段列表 from 表名 [where 条件] order by 字段1 排序方式1, 字段2 排序方式2;ASC:升序(默认值)DESC:降序
多字段排序时,先对第一个字段排序,第一个字段相同时再对第二个字段排序。
4.5 分页查询
c
select 字段列表 from 表名 [where 条件] limit 起始索引, 查询行数;起始索引从0开始,起始索引=(查询页码-1)×每页的行数
如果查询的是第一页数据,起始索引可以省略,简写为limit 查询行数
二、多表查询
1.笛卡尔积
多表查询时如果没有指定条件那么查询结果就是笛卡尔积。例如A表有2条数据,B表有4条数据,那么笛卡尔积就是2×4=8条数据。
c
select * from a,b;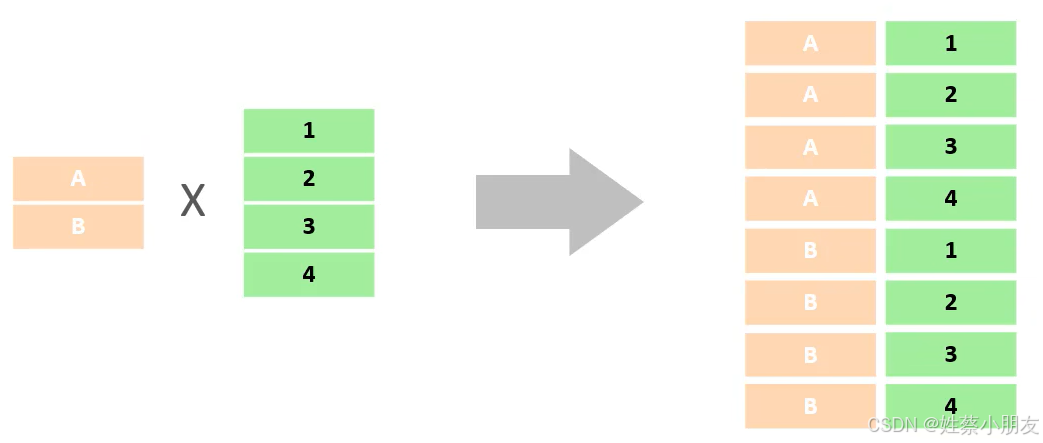
2.内连接
内连接查询的是两张表的交集部分。也就是说当表A/表B中的数据在表B/表A中没有匹配项时不会输出。
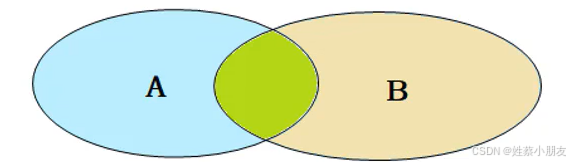
隐式内连接:select a.name, b.name from a, b where a.b_name=b.name;
显式内连接:select a.name, b.name from a inner join b on a.b_name=b.name;
3.外连接
左外连接查询的是左表所有数据+两张表的交集 。右外连接查询的是右表所有数据+两张表的交集。也就是说当表A中的数据在表B中没有匹配项时使用左外连接也会输出,当表B中的数据在表A中没有匹配项时使用右外连接也会输出。
左外连接:select a.name, b.name from a left join b on a.b_name=b.name;
右外连接:select a.name, b.name from a right join b on a.b_name=b.name;
在实际开发中,想要哪张表的所有信息就以该表作为主表。
4.自连接
自连接查询的是同一张表,例如同一张表记录了id和领导id,那么查询所有员工的信息及其领导信息就需要用自连接。自连接可以用内连接也可以用外连接,具体看需求。自连接需要对表起别名,因为需要看成两张表。
c
select * from emp a, emp b left join on a.manager_id=b.id;5.联合查询
联合查询可以把多次查询的结果在行上合并起来,形成一个新的结果集。
c
select * from emp where salary>5000
union all
select * from emp where age>50union还会将查询结果合并之后去重。
6.子查询
6.1 列子查询
子查询返回的是1列n行数据,常用操作符:
in:在子查询集合内满足其一not inany: 在子查询集合内满足其一,一般配合>号使用all:子查询集合内满足所有,一般配合>号使用
6.2 行子查询
子查询返回的是1行n列数据,常用操作符:
=<>:不等于in:在子查询集合内满足其一not in
6.3 表子查询
子查询返回的是n行n列数据,常用操作符:
in:在子查询集合内满足其一
select * from emp where (job, salary) in (子查询select job, salary from ...)